自动驾驶已从模块化迈向统一端到端,视觉-语言-动作(VLA)模型正是这一历程在视觉-动作(VA)基础上的延伸。但在实际表现中,VLA的规划质量却常常落后于VA,给模型加上语言理解能力之后,驾驶水平反而下降了。
问题的核心并不在于模型规模,而在于设计思路:大多数VLA只是把语言和动作当成两个独立的子任务各自优化,无法整合出连贯的驾驶能力。
近日,香港中文大学MMLab李鸿升教授团队联合理想汽车、清华大学发布首个自动驾驶统一流式VLA模型MindVLA-U1,旨在从根本上解决上述问题。
该模型采用统一共享骨干网络,统一场景理解和轨迹生成,并通过全流式设计对驾驶视频逐帧处理,取代了传统VLA中冗余的时序建模,显著降低计算开销。同时,模型中的“流式记忆通道”能够持续更新历史场景信息,使长程规划保持连贯。
实验结果表明,MindVLA-U1仅用2个扩散步骤,便在规划质量上超越经验丰富的人类驾驶员,在规划平均位移误差(ADE)上领先其他VA/VLA方法,同时保留了用于人车交互的自然语言界面。
链接:https://arxiv.org/abs/2605.12624
主页:https://mind-omni.github.io/
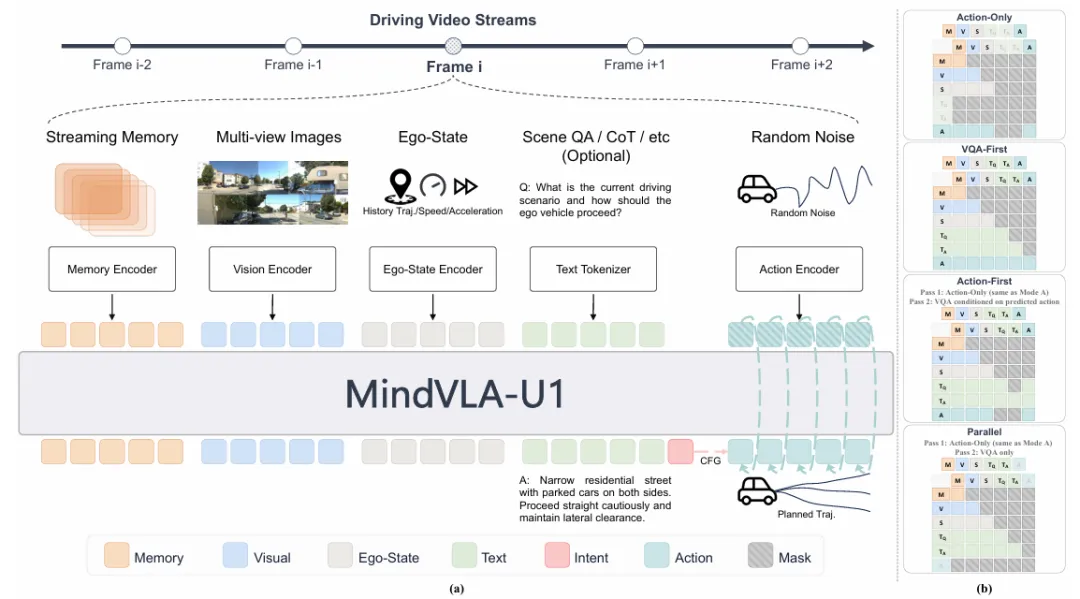
MindVLA-U1将统一共享骨干网络与流式记忆(Streaming Memory)两种范式融为一体,如图2。共享骨干网络在单一表征上通过单次前向传播,同时完成场景理解与连续的轨迹生成;流式记忆则通过一条记忆通道,在整个驾驶会话中跨帧传递上下文。
图2:MindVLA-U1概述
一个大脑,同时完成理解和决策
在传统方案中,语言模型与动作模型通常各自为政——前者负责理解场景,后者负责规划轨迹,两边参数独立、信息传递有限。MindVLA-U1打破了这一分割。
MindVLA-U1采用单个VLM骨干网络,在每一层中以相同的自注意力和FFN权重统一处理视觉、自车状态、语言、记忆及带噪动作词元。所有模态共享同一套参数,没有独立的计算分支。语言头以自回归方式解码语言词元,动作头通过流匹配MLP生成连续动作轨迹,二者在单次前向传播中同步完成。
这种设计的核心价值在于,它构建了一条可度量的语言-动作通路。语言头同步预测当前场景的驾驶意图词元,并通过无分类器引导机制将其注入动作头的扩散过程。这意味着语言预测出的驾驶意图(如“变道”)能够直接介入轨迹生成过程,而不是仅作为背景信息。这也是VLA研究中首次在架构层面建立这种显式连接。
另一个实用价值在于灵活部署。仅依靠注意力掩码组合,同一个模型即可在同一组权重下切换三种运行模式:先理解场景再规划轨迹、先规划轨迹再生成解释、或跳过语言直接输出动作。走第三种快速路径时,模型的处理速度可以追平不带语言模块的纯视觉VA。
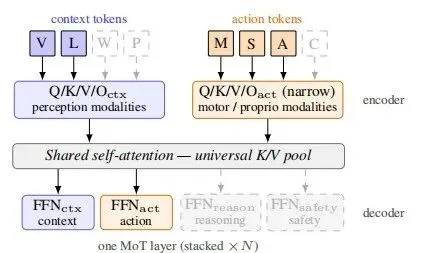
此外,该骨干还可扩展为MoT变体,将上下文组与动作组拆分为并行专家,通过共享自注意力实现跨组信息融合。
图3:基于稀疏 MoT 的快/慢系统
流式记忆机制:持续更新,过时即忘
人类驾驶员不需要每隔几秒就回看一遍过去半分钟的路况录像,而是靠大脑中持续更新的即时记忆。传统VLA的做法恰恰相反,把视频切成固定长度的片段反复做注意力计算,既冗余又拖慢了响应速度。
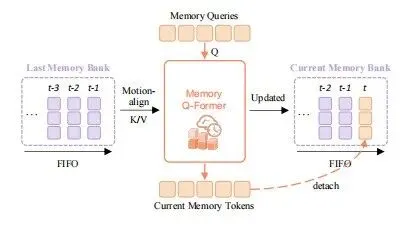
MindVLA-U1采用了不同的思路,如图4所示。将驾驶视为逐帧流进行处理:每帧仅输入当前视图和一组从记忆通道中读取的紧凑记忆词元,这种记忆词元是过去帧的压缩,读取时运动对齐到当前的自车坐标系。
对齐后的记忆词元与当前帧的其他输入一起送进共享骨干网络;骨干输出后,由类似Q-Former的传播Transformer生成新的压缩记忆词元并写入FIFO通道,同时淘汰最早的一组记忆,以完成更新。
图4:流式记忆
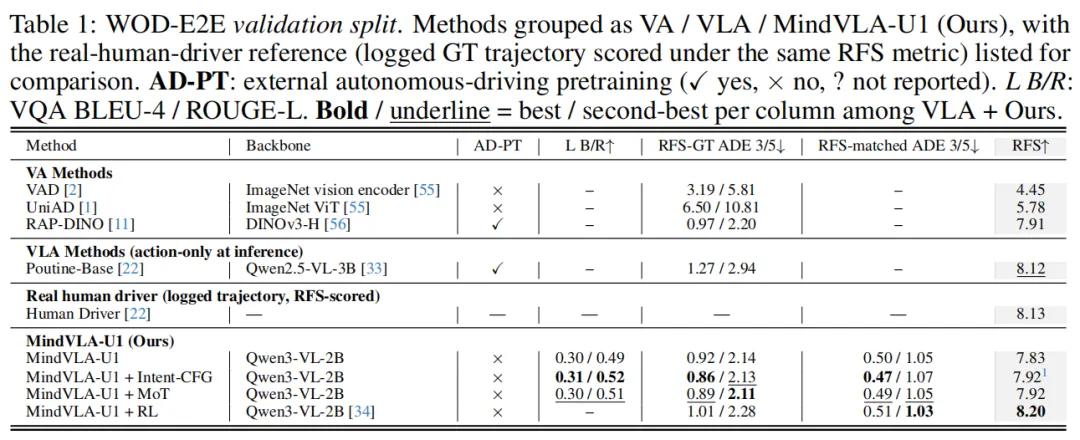
研究人员在Waymo开放数据集端到端基准(WOD-E2E)上进行了训练与评估。MindVLA-U1架构与具体VLM无关,统一共享骨干、流式记忆及意图引导机制Intent-CFG均建立在通用的VLM前向传播之上,因此现有的VLM(如InternVL、Qwen2.5/3/3.5-VL、DeepSeek-R1)均可作为骨干替换。
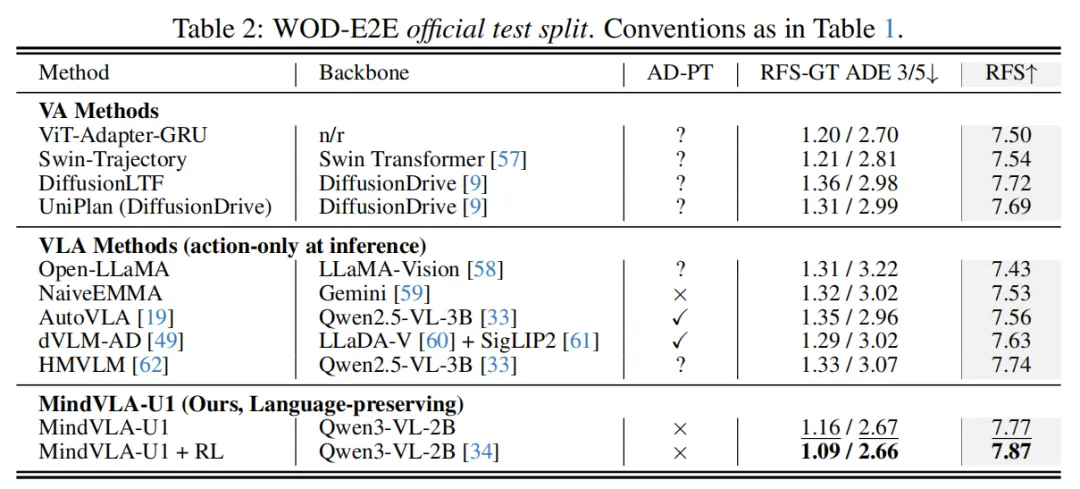
在WOD-E2E基准上,MindVLA-U1消除了此前驾驶VLA模型在规划质量上一直落后于纯VA模型的差距。在官方测试集上,MindVLA-U1 + RL取得了目前最高 RFS 分数(7.87)和最低的 RFS-GT ADE(1.09/2.66 米),超过了此前表现最好的VLA模型 dVLM-AD。
这一优势来源于架构本身,而不是强化学习。即便不使用RL和任何外部数据预训练,仅依靠Intent-CFG机制,MindVLA-U1在验证集上就达到RFS 7.92,与最强的纯VA RAP-DINO(7.91)基本持平。而不加RL的MindVLA-U1在测试集上排名第二(7.77, 1.16/2.67米),在3秒和5秒的ADE指标上均超过所有之前的VLA和VA方法。取得这些结果的同时,MindVLA-U1在推理时仍保留了自然语言交互能力。
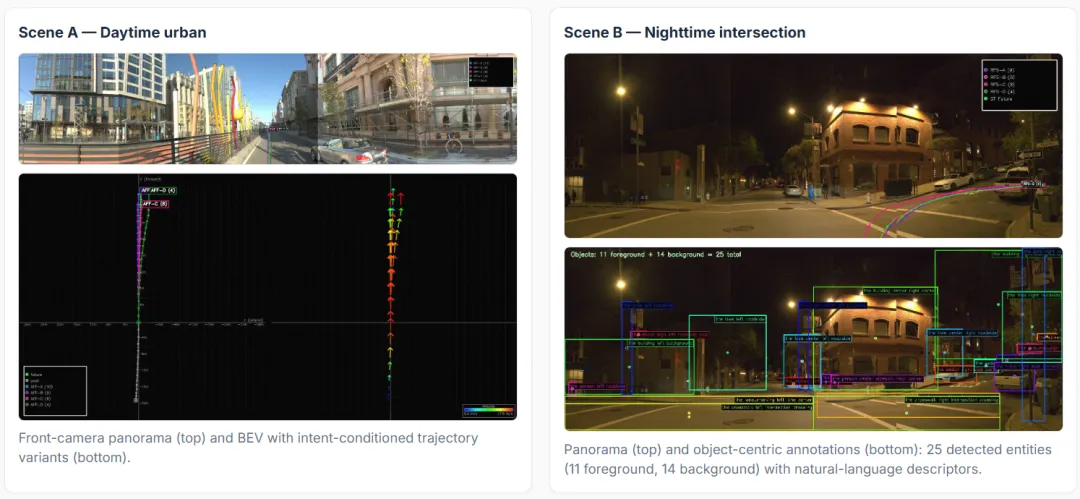
长尾场景。WOD-E2E针对的是发生率低于0.003%的长尾场景。无论是日间城区还是夜间路口,MindVLA-U1 始终将决策建立在对具体场景的感知之上:同一个骨干网络既能生成鸟瞰视角下的行驶轨迹,也生成周围车辆和行人的自然语言描述。
香港中文大学MMLab李鸿升教授团队联合理想汽车、清华大学发布MindVLA-U1,是首个自动驾驶统一流式VLA模型,其核心设计包括:
采用统一共享骨干,在单次前向传播中基于同一表征同时输出语言与连续动作;
流式记忆通道以轻量级传播取代冗余的多帧VLM建模和固定的动作分块,计算开销不再随驾驶时长线性增长;
通过Intent-CFG在语言与动作之间建立一条可度量的因果通路,让语言推理结果直接参与驾驶决策;
快/慢两种执行模式共用同一套权重,快执行时跳过语言解码,处理速度追平纯VA系。
实验结果表明,在WOD-E2E官方测试集上仅用两次扩散步数就取得了最高RFS分数,并且在RL后训练之后超越人类驾驶水平。
EAI 100(聚合智能产业委员会)由车百会研究院联合智能领域多位专家及领军企业共同发起成立,是国内首个聚合智能跨产业协同创新平台。平台重点聚焦智能汽车、具身机器人、低空经济、“双智”协同等前沿领域,致力于打通跨产业协同壁垒,依托汽车产业链现有优势,加速具身机器人、低空经济等产业规模化应用,系统性推动智能汽车与智慧城市协同发展。目前,EAI 100汇聚的专家及企业成员数量突破130家,已实现聚合智能领域全方位、全链条覆盖。
合作咨询:
联系人:苏先生 13051866118
电子邮箱:eai@chinaev100.org
香港业务咨询:
联系人:刘先生 18682446747
电子邮箱:liuyi@chinaev100.org
* 入群可获取行业资讯、研报
分享,参与研究研讨等;
* 入群需注明姓名+单位名称。