LVDrive:自动驾驶模型不只是“看见当下”,还要学会在脑中预演未来
- 2026-05-31 17:47:58

点击下方卡片关注我们,点亮星标⭐,优质好文第一时间送达^_^
Click on the card below to follow US

>>>戳我一下,加入智驾机器人学习交流群✨
自动驾驶里有一个看似朴素、其实很难的问题:车到底应该怎样“理解”眼前的世界?
如果只是识别红绿灯、车道线、行人和车辆,很多感知模型已经做得相当成熟。但真正上路时,车需要的并不只是把当前画面说清楚。它还要判断:前方事故车会不会挡住道路?旁边车辆会不会切入?路口转弯之后会不会突然出现骑车人?如果现在这条轨迹继续走下去,几秒之后会发生什么?
这篇论文提出的 LVDrive,正是围绕这个问题展开。它没有把重点放在生成一张“未来照片”上,而是让自动驾驶模型在一个更高层、更抽象的视觉潜空间里,提前形成对未来场景的理解,并把这种理解直接用于轨迹规划。
换句话说,它想做的不是让车“画出未来”,而是让车在行动之前,先在脑中预演一遍未来。

近两年,自动驾驶领域开始大量引入 Vision-Language-Action(VLA,视觉-语言-动作)模型。这类模型的思路很自然:输入多视角图像和语言指令,输出未来行驶轨迹或控制动作。它继承了多模态大模型的场景理解能力,也试图把语言推理能力迁移到驾驶任务中。
但论文指出,现有 VLA 自动驾驶模型有一个关键短板:它们大多依赖稀疏的动作监督。
所谓稀疏动作监督,可以简单理解为:模型训练时主要看最终应该怎么开,比如未来轨迹应该在哪里、车辆应该往哪走。这当然重要,但它对“为什么要这样开”的空间理解约束不够。一个模型可能学到了某些动作模式,却没有真正充分利用多模态大模型原本擅长的场景理解与推理能力。
论文把几类范式放在一起比较:
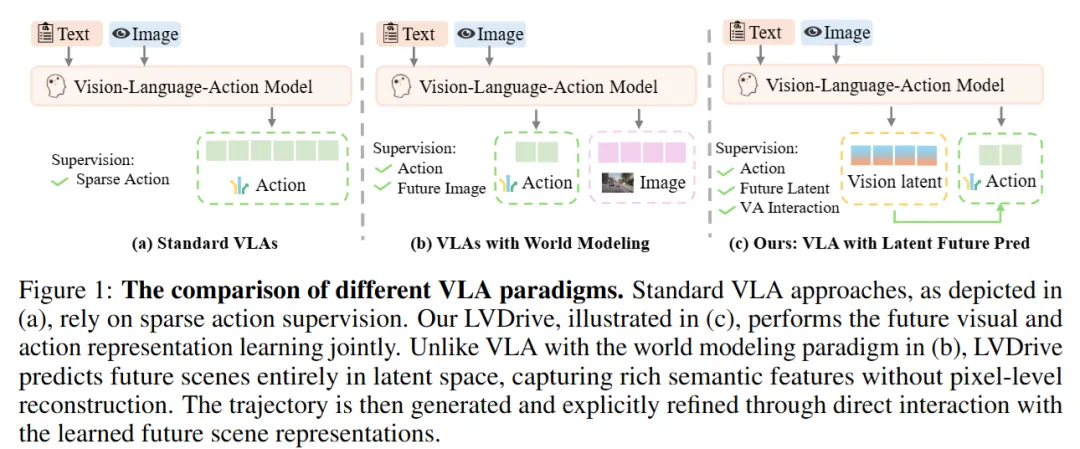
传统 VLA 的训练信号主要来自动作;一些引入世界模型的方法,会让模型预测未来图像;而 LVDrive 的选择更克制:它预测未来场景的潜在视觉表示,不执着于像素级复原。
这个差别很重要。对自动驾驶来说,最有价值的不是未来画面里每一块纹理是否逼真,而是模型是否抓住了真正影响驾驶决策的东西:车辆位置、道路结构、障碍物关系、交通参与者的动态变化,以及这些因素在短时间内怎样演化。

世界模型在自动驾驶中并不是新概念。许多方法尝试让模型预测未来图像,通过“想象未来”来帮助规划。但论文认为,如果把精力过多放在像素级图像重建上,模型可能会被纹理、颜色、光照等细枝末节牵着走。
一辆自动驾驶车在路口决策时,并不需要知道远处墙面的纹理会不会变化;它真正需要知道的是,前方车辆是否停住,旁边车道是否可借,转弯后是否有动态障碍,当前轨迹会不会把自己带进危险区域。
因此,LVDrive 把未来预测放在 latent space(潜空间) 里完成。这个潜空间不是原始图像空间,而是经过预训练视觉模型整理过的高层表示空间。它更像一份压缩过、语义更浓的场景笔记,而不是一张高清照片。

LVDrive 的整体结构如下图所示:
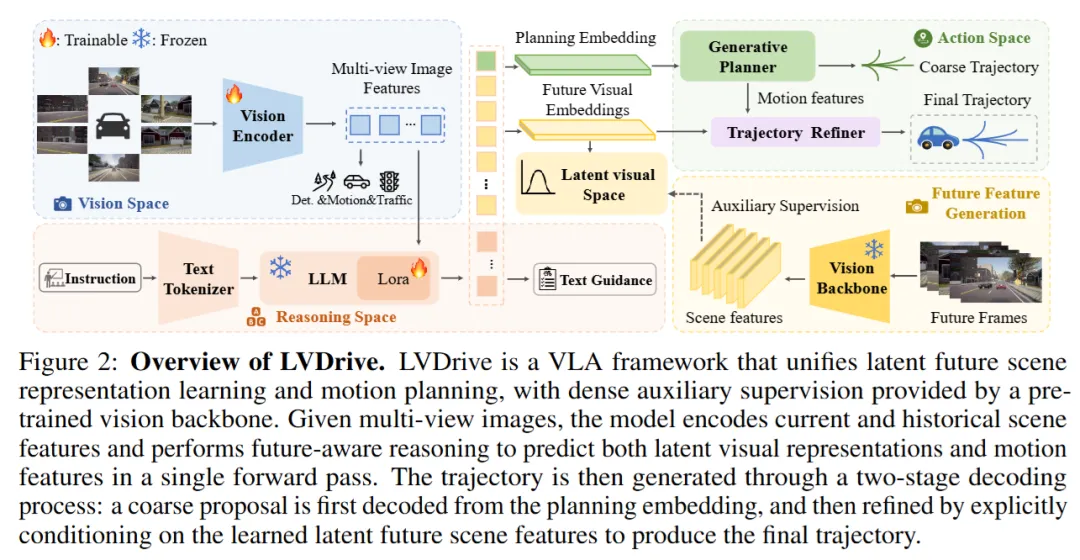
从图中可以看到,LVDrive 仍然保留 VLA 框架的基本骨架:多视角图像经过视觉编码器提取特征,文本指令经过 tokenizer 进入语言模型,核心 LLM 负责在统一的表示空间中进行理解和推理。
不同之处在于,它在规划任务旁边加入了一个新的任务:预测未来前视场景的潜在视觉表示。
这个设计可以分成三层理解。
第一层,是输入侧。模型接收当前和历史多视角图像特征,同时接收文本导航指令。多视角图像并不是原封不动地塞进大模型,而是先由视觉编码器和 QT-Former 压缩成结构化视觉表示。
第二层,是推理侧。模型在 LLM 的隐藏空间中安排了一组特殊的未来视觉占位符,例如 <img_i>,并用 <img_start> 和 <img_end> 标记每一帧未来图像表示的边界。模型不生成真实图像,而是在这些占位符位置上学习未来视觉嵌入。
第三层,是规划侧。模型在未来视觉占位符之后放置 <waypoint_ego> 这样的规划 token。由于语言模型的因果注意力机制,规划 token 可以吸收前面未来视觉表示中的信息。这样,未来场景理解就不只是一个辅助任务,而会进入实际轨迹生成过程。
论文把这个联合任务写成:
这里的 (V_{t+1:t+F}) 是未来若干时刻的潜在视觉表示,(s) 是用于规划的特殊 token,(x_s)、(x_h)、(x_q) 分别代表结构化视觉特征、历史视觉特征和文本指令。
这条公式的意思并不复杂:给定现在和过去看到的东西,再结合导航指令,模型要同时形成对未来场景的表示,并给出后续规划所需的动作表征。

LVDrive 预测的是未来前视图的潜在特征,而不是所有环视视角的未来特征。论文给出的理由是,人类驾驶时主要注意前方视角,前视预测已经能提供较强的未来感知能力。
这个取舍有好处,也埋下了后面的局限。
好处是计算更轻,监督更集中,模型不必在所有方向上都做复杂预测。对于大多数道路前进、变道、转弯、避障任务,前方场景确实承载了主要决策信息。
但坏处也很清楚:如果关键交互来自后方,比如急救车从后方接近,模型可能会因为未来预测任务主要关注前方,而降低对后方交互的敏感度。论文后面的 Give Way 失败案例,正好说明了这一点。

LVDrive 不是让模型自己凭空构造未来视觉特征。它使用一个冻结的预训练视觉模型作为教师,为未来前视图生成监督信号。
论文采用的是 VQGAN-ImageNet。具体做法是,把未来 6 个时间步的前视图像送入 VQGAN-ImageNet,得到形状为 (16 \times 16 \times 256) 的潜在视觉特征。也就是说,每一帧未来图像被压缩成 256 个视觉 token,每个 token 维度为 256。
训练时,LVDrive 的 LLM 会在对应的未来视觉占位符位置输出隐藏状态,再通过一个轻量视觉解码器映射到同样的潜在视觉维度。模型的预测结果会和预训练视觉模型给出的未来潜特征对齐。
这里的监督不是离散图像 token,也不是像素图。它更接近高层语义空间的“未来场景提示”。这样一来,模型既利用了未来图像带来的密集监督,又避免把大量能力消耗在纹理级重建上。

这篇论文最关键的另一个设计,是 two-stage trajectory decoding(两阶段轨迹解码)。
第一阶段,模型根据规划嵌入生成一个粗轨迹 proposal。论文沿用了 VAE-based generative planner 的思路,把规划嵌入映射为高斯分布,再采样潜变量,通过 GRU 状态解码器生成未来 ego motion states,最后得到多模态粗轨迹。
这一阶段的作用很像“先画出大致路线”:车辆大概往哪里走,能不能绕开前方障碍,是否能完成变道或转弯。
第二阶段,模型再用轨迹 refiner 对粗轨迹进行细化。这个 refiner 由 Transformer block 组成,通过 cross-attention 显式读取未来视觉嵌入。换句话说,粗轨迹不是最终答案,它还要再回头看一眼模型预测到的未来场景语义,再做更细的调整。
这个设计很有意思。它避免了一个常见问题:未来视觉预测只是训练时的辅助任务,推理时并没有真正进入规划决策。LVDrive 让未来视觉表示在第二阶段直接参与轨迹优化,因此它不是旁观者,而是规划过程中的条件信息。
论文的消融实验也证明,两阶段解码并不是可有可无的小修小补,而是性能跃升的关键。

LVDrive 的训练并没有采用复杂的多阶段流程,而是端到端训练 6 个 epoch。整体损失包含五部分:
其中,(L_{vis}) 用于未来潜在视觉表示预测,结合 cosine similarity loss 和 L1 loss;(L_{plan}) 和 (L_{plan_r}) 分别约束粗轨迹和细化轨迹;(L_{qt}) 来自结构化多视角特征抽取;(L_{ce}) 用于 LLM 生成固定的特殊占位符序列。
实现细节上,论文使用 EVA-02-L 和 QT-Former 作为视觉编码部分,核心 LLM 使用 Vicuna v1.5,并通过 LoRA 微调。实验在 32 张 NVIDIA H20 GPU 上完成。

论文在 Bench2Drive benchmark 上评估。Bench2Drive 是基于 CARLA v2 的闭环端到端自动驾驶评测基准,包含多种天气、城镇、交互场景和驾驶技能。论文采用官方 base training split:1000 个 clips,其中 950 个用于训练,50 个用于 open-loop 验证;闭环评估覆盖 220 条短路线。
主结果如下:
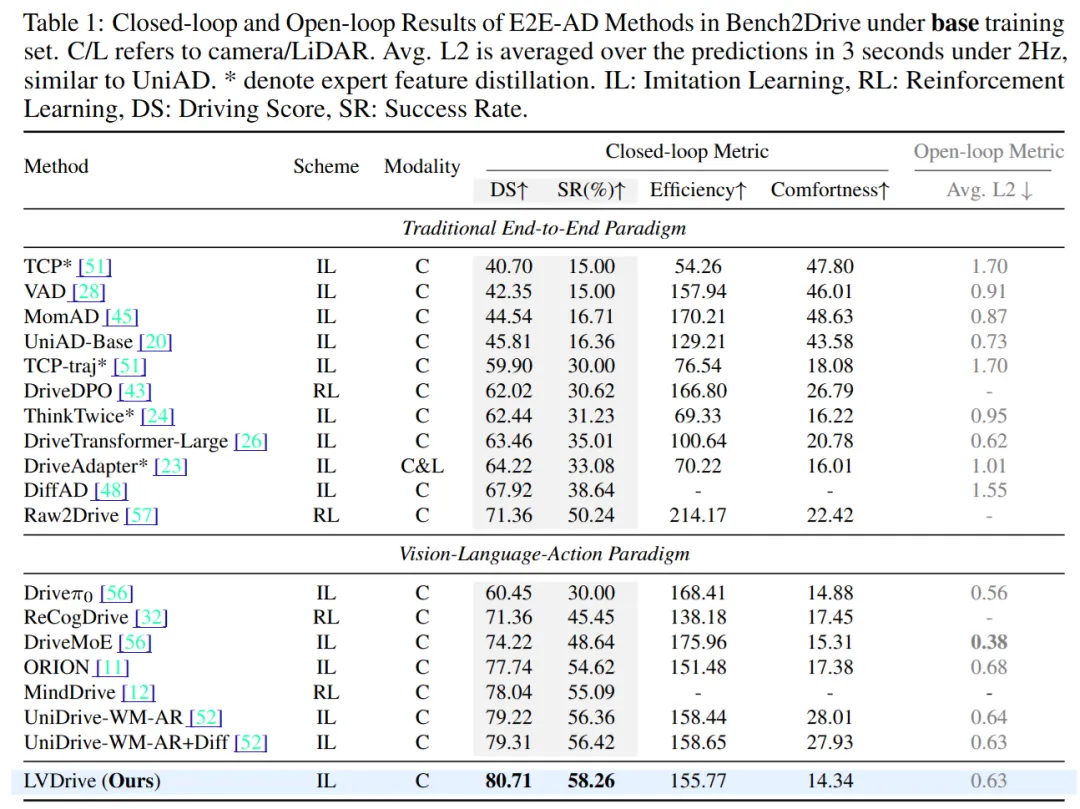
在闭环指标上,LVDrive 达到:
Driving Score:80.71 Success Rate:58.26% Efficiency:155.77 Comfortness:14.34 Avg. L2:0.63
对比同属 VLA 范式的 ORION,LVDrive 的 Driving Score 从 77.74 提升到 80.71,Success Rate 从 54.62% 提升到 58.26%。对比引入图像重建式世界模型的 UniDrive-WM-AR+Diff,LVDrive 的 Driving Score 也从 79.31 提升到 80.71,Success Rate 从 56.42% 提升到 58.26%。
这个提升并不只是数值上的小幅前进。它说明,在自动驾驶规划中,潜空间未来表示可能比像素级未来重建更贴近任务本身。模型不一定要画出未来世界的样子,但必须理解未来世界里哪些东西会影响自己怎么走。

Bench2Drive 还提供多能力拆分评估,包括 Merging、Overtaking、Emergency Brake、Give Way、Traffic Sign 等能力。
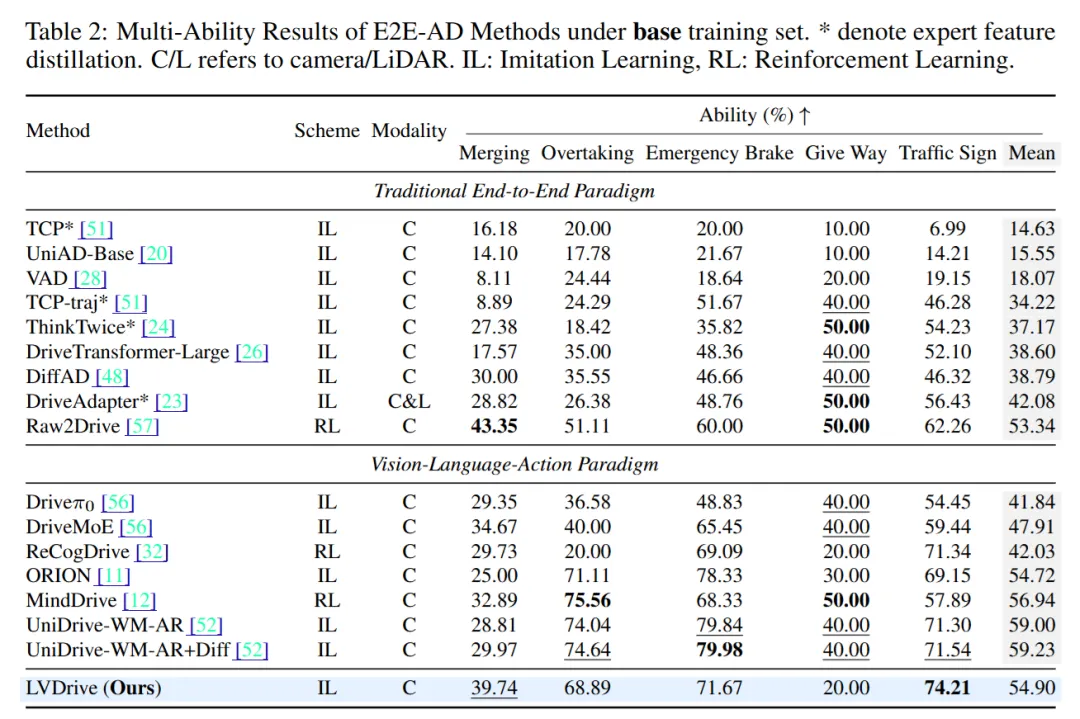
LVDrive 的表现有明显特点:
它在 Traffic Sign 上达到 74.21%,是表中最高;在 Merging 上达到 39.74%,也是非常靠前的结果。Overtaking 和 Emergency Brake 也保持竞争力。
但 Give Way 只有 20.00%,不算好。论文解释,Give Way 场景往往要求 ego vehicle 对后方接近的急救车做出让行动作。LVDrive 的未来预测主要围绕前视图展开,因此模型更容易把注意力放在前方,忽略后向交互。
这恰好提醒我们:一个模型的优势常常和它的偏置来自同一处。前视未来预测让 LVDrive 在多数前方道路理解任务中更强,但在后向动态交互中,它也可能显得迟钝。

论文的消融实验很值得细看。因为它回答了一个重要问题:未来视觉预测到底是锦上添花,还是规划能力提升的真正来源?
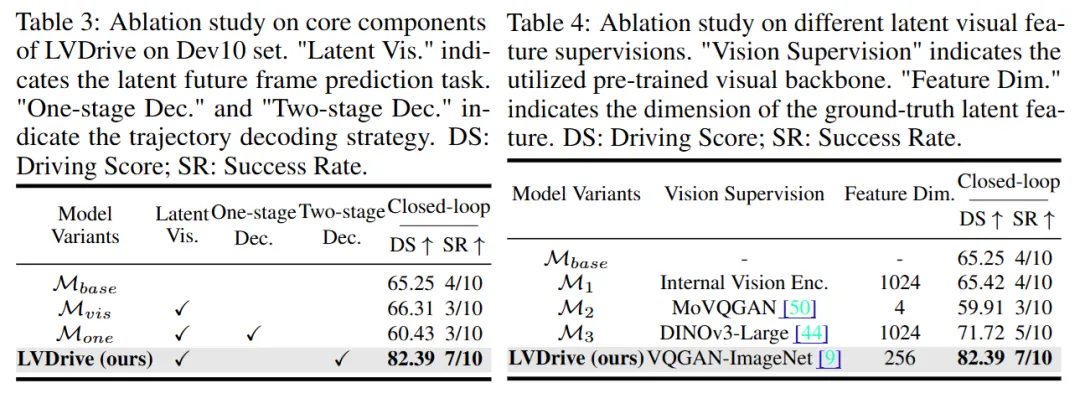
在 Dev10 子集上,基础模型 (M_{base}) 的 Driving Score 是 65.25,Success Rate 是 4/10。只加入 latent future visual prediction 后,Driving Score 小幅升到 66.31,但 Success Rate 反而降到 3/10。
这说明,简单加一个视觉预测任务并不够。视觉空间和动作空间如果没有合适的对齐机制,可能带来优化冲突。
一阶段解码版本 (M_{one}) 更差,Driving Score 降到 60.43。这说明,如果过早、过直接地把未来视觉特征塞进动作解码,反而会干扰运动特征学习。
真正有效的是 LVDrive 的两阶段方案:先用动作监督稳定生成粗轨迹,再通过未来视觉表示做细化。最终 Driving Score 达到 82.39,Success Rate 达到 7/10。
表4 则比较了不同视觉监督来源。内部视觉编码器提升有限,MoVQGAN 甚至下降,DINOv3-Large 有明显提升,但仍不如 VQGAN-ImageNet。论文认为,DINOv3-Large 的特征太丰富,可能把冗余信息带入共享空间;而 VQGAN-ImageNet 的 256 维潜特征在语义密度和信息压缩之间取得了更合适的平衡。

论文还专门比较了两阶段轨迹解码和推理时间:
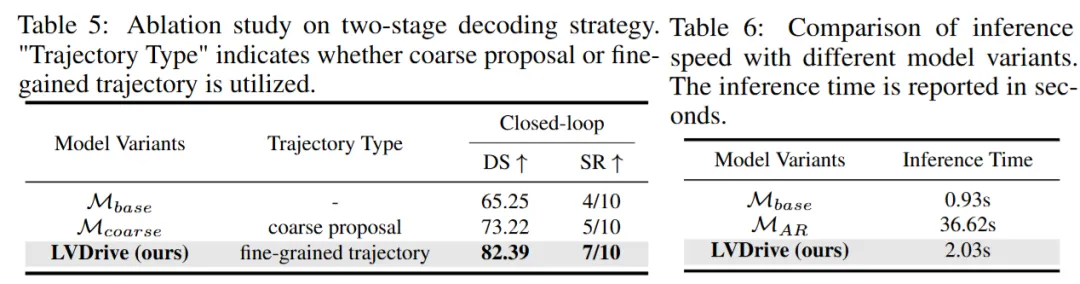
如果只看 coarse proposal,Driving Score 是 73.22,Success Rate 是 5/10;经过第二阶段细化之后,Driving Score 达到 82.39,Success Rate 达到 7/10。这个差距说明,未来视觉表示在轨迹 refinement 中确实发挥了实质作用。
推理效率方面,基础模型 (M_{base}) 约 0.93 秒,LVDrive 约 2.03 秒。由于加入未来视觉预测和轨迹细化,它确实比基础模型慢。但和自回归生成版本 (M_{AR}) 的 36.62 秒相比,LVDrive 仍然快了一个数量级以上。
这也是论文的方法选择里很现实的一点:自动驾驶不是离线生成任务,不能为了预测未来画面而付出过高的推理成本。LVDrive 用预填充视觉占位符和单次前向推理,避开了自回归逐 token 生成的高成本。

论文给出的一个超车案例很直观。场景中,ego vehicle 前方遇到事故车辆,原本车道被阻挡,旁边车道又有持续来车。基础模型停在事故车后,无法规划可行路径;LVDrive 则能在安全条件下绕过事故车辆。

这个案例有助于理解 LVDrive 的价值。
如果模型只是根据当前图像输出轨迹,它可能倾向于保守停车,因为眼前车道确实被挡住了。但驾驶决策需要的不是静态识别,而是动态推演:旁边车道是否有空隙?继续等待还是尝试借道?借道之后能不能回到原车道?对向车辆会不会造成冲突?
未来场景表示在这里像一种“短时预演”。它帮助模型把当前观察和未来可能状态联系起来,于是轨迹不再只是对当前画面的反应,而更接近一种经过预测的行动选择。

论文附录中还给出多个定性例子。它们从不同角度展示了 LVDrive 的能力边界。
在 Emergency Brake 场景中,ego vehicle 需要先完成无保护左转,随后立即对横穿自行车急刹。基础模型在左转阶段就与车辆碰撞,而 LVDrive 完成转弯、刹停、等待自行车通过,并恢复行驶。
在 Merging 场景中,车辆需要从高速出口并入窄路。基础模型对道路边界理解不准,轨迹出现横向偏移,最终撞上护栏;LVDrive 则能更准确地把握匝道几何和可通行空间。
在 Traffic Sign 场景中,车辆要在非信号灯路口右转,同时避开周围车辆和交通标志。基础模型轨迹偏离并撞上标志,LVDrive 则更谨慎地完成转弯。
在另一个 Overtaking 场景中,前方相邻车道车辆突然开门,车门侵入 ego 车道。基础模型停住后无法继续规划,LVDrive 能识别这个细粒度语义变化,并规划绕行。
当然,LVDrive 也不是没有失败。Give Way 场景里,急救车从后方接近,ego vehicle 应该让行,但 LVDrive 继续直行,没有完成让行动作。
这个失败很有启发。它说明“预测未来”本身并不足够,还要看模型预测的是哪个方向、哪个视角、哪类交互。如果未来预测主要集中在前视图,那么它自然更擅长处理前方空间关系,也更可能忽视后向关键事件。

LVDrive 的贡献可以概括为三点。
第一,它把 VLA 自动驾驶从单纯动作监督推进到更密集的未来视觉表示学习。模型不再只是模仿专家轨迹,而是在训练中学习未来场景如何演化。
第二,它避开了像素级未来图像重建的负担。自动驾驶需要的是可用于规划的语义,而不是一张逼真的未来图。潜空间预测更符合规划任务的实际需要。
第三,它通过两阶段轨迹解码,把未来视觉表示显式引入最终轨迹生成。很多辅助任务在训练时看起来有帮助,但推理时只留下间接影响;LVDrive 让未来视觉特征直接参与 refinement,因此信息链条更短,也更可解释。
当然,论文也留下了值得继续追问的问题。
比如,前视预测是否足够?在后方急救车、侧后方加塞、复杂环岛等场景中,多视角未来表示可能更加必要。再比如,预训练视觉 backbone 如果换成自动驾驶大规模数据上训练的视觉基础模型,是否还能进一步提升?此外,语言监督在视觉和动作表示学习中能否发挥更主动的作用,也还没有被充分展开。

LVDrive 给人的启发,不只是某个指标提升了多少。它更像是在提醒我们:自动驾驶中的理解,不应停留在对当前画面的命名上。
真正的驾驶理解,带有时间性。它关心一个物体接下来会怎样移动,一段道路接下来是否可通行,一个看似静止的场景是否马上会变成危险状态。
从这个角度看,LVDrive 的“latent future representation”并不是一个花哨的模块,而是一种更接近驾驶本质的建模方式:让模型在行动之前,先形成一个简洁、语义化、面向规划的未来世界。
车不能只看见当下。它必须在有限时间里,对未来做出足够好的判断。LVDrive 做的,正是把这种判断能力向模型内部推进了一步。
参考资料
论文标题:LVDrive: Latent Visual Representation Enhanced Vision-Language-Action Autonomous Driving Model 中文题名参考:LVDrive:潜在视觉表征增强的视觉-语言-动作自动驾驶模型 作者:Xiaodong Mei、Diankun Zhang、Hongwei Xie、Guang Chen、Hangjun Ye、Dan Xu


智驾 & 机器人学习交流圈

学
起
来



收藏

点赞

在看

收藏

点赞

在看
(1)自动驾驶可指导方向:CUDA编程,高性能计算HPC,CV/感知算法,端到端自动驾驶,决策规划,显著性分析,图像分割,LLM,自动驾驶,雷达感知,自动驾驶感知,毫米波雷达,深度学习,滤波算法,预期功能安全,自动驾驶基础共性技术研究,自动驾驶模拟仿真技术研究,自动驾驶安全性设计及验证,仿真与测试,场景生成,强化学习,预期功能安全,自动驾驶点云处理,行为识别,目标检测,视觉感知,BEV感知,边缘计算,数据处理,驾驶行为研究,点云,多模态,自动驾驶决策规划,英伟达平台模型部署优化,自动驾驶安全方向等。
(2)机器人可指导方向:机器人路径规划及算法,AI 集中在ROS机器人和CV NLP,计算机视觉,机器学习,机器人,三维视觉, 图像融合 ,图像理解 ,机器人算法,SLAM,点云处理,信号处理,具身智能,智能控制,机器人柔顺控制,分数阶控制,自适应反步,产业机器人,电力检测机器人,海洋机器人,进化计算,移动机器人定位导航,位姿估计,轮式机器人,仿生足式机器人,机器人感知,语义分割,深度学习,机器视觉,工业机器人,移动机器人,机器人模仿学习,控制算法设计,多模态智能等。
我们专注自动驾驶和机器人等前沿领域,提供选题创新性评估、实验设计、论文写作与顶级会议/期刊投稿指导。团队源自全球顶尖实验室及企业研究院,强化创新点与工程实现,不仅保证论文产出,更传授科研思维与方法,助你掌握独立发表高水平论文的能力。提供专利挖掘、技术交底书撰写、国内外专利申请(发明专利/实用新型)全流程服务。结合产业需求,强化权利要求的保护范围与商业价值,助力成果转化与竞争力提升。




随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 同天上市 地球最强SUV vs 科技行政旗舰SUV
- 20万能买什么SUV?
- 11.78万,五菱大6座SUV,开启预售
- 9万级轿跑SUV还敢做机甲脸?捷途大圣优惠1.5万再叠置换1.5万,年轻人要颜值要快感,博越L和CS75还香吗?
- 15万级纯电SUV卷王再进化?第三代元PLUS闪充版,这性价比我先冲了!
- 15万级家用SUV“卷王”!长安启源Q07凭啥成为十万家庭的共同选择?
- 理想SUV乱变道害死摩托车手,行车记录仪拍下全过程!
- 思皓X8:江淮大众联合出品,这台三排SUV值得认真看一眼
- Jeep指挥官发展史:那个年代美系七座SUV最后的方盒子,赢在纯粹,也输在纯粹
- 定位大五座SUV,乐道L80上市,售价24.28万起
