北京时间6月4日凌晨,CVPR 2026在美国丹佛开幕。特斯拉自动驾驶与Optimus双线负责人Ashok Elluswamy登上了“具身智能基础模型部署”专题工作坊的讲台,演讲标题简洁到只有一句话:*Building Foundational Models for Robotics at Tesla*。
标题是老的,slides里不少内容也似曾相识。但在今年的版本里,Elluswamy给出了几组此前未曾公开的数据,并首次系统性地拆解了特斯拉端到端模型面临的“三道关卡”及其解法。整场演讲的内核可以用一句话概括——特斯拉不认为自己是在做“自动驾驶”,而是在为所有机器人构建一个统一的基础模型。车,只是第一个身体。
三条线,一个大脑
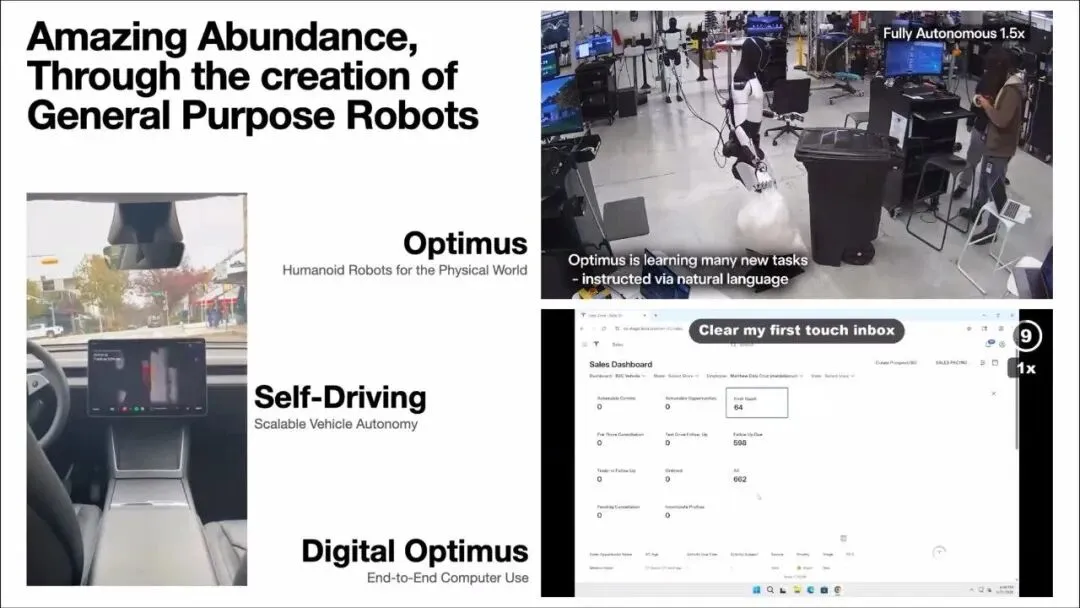
演讲开场,Elluswamy把特斯拉的AI版图摊在一页幻灯片上:三条产品线,共享同一套基础模型内核。
第一条是Self-Driving,可规模化的车辆自治。第二条是Optimus,面向物理世界的人形机器人。第三条被称作Digital Optimus,一个端到端的电脑操作智能体——现场演示里,它直接听懂“帮我清空first touch收件箱”,然后自己完成了所有点击操作。
Elluswamy强调,这三件事看起来是三个产品,本质上却是同一个基础模型在不同“身体”上的投影。他给整场演讲定的使命只有一句:通过通用机器人把人类从重复性体力劳动中解放出来,创造“极度丰裕”。
130万辆车,108亿英里
这次更新的一个重要数据是部署规模。
截至演讲时,全球已有约130万辆具备监督式自动驾驶能力的特斯拉在路上。FSD累计行驶里程超过108亿英里,其中城市道路约40.7亿英里。交付区域覆盖北美、欧洲部分国家和亚太多个市场,中国位列已交付区域之中。
这组数字是理解特斯拉技术路线的基础。后面所有的论证——为什么端到端、为什么强调数据规模、为什么走神经模拟路线——都建立在这个百万级车队持续回传真实数据的假设之上。
安全性数据也被拿来作为佐证。按照“发生一次重大碰撞前能开多少英里”的口径,FSD(监督版)在高速场景下每890万英里才发生一次重大碰撞,城市道路为290万英里,均远高于全美平均水平(高速150万英里、城市50.5万英里)。北美全路况综合口径下,FSD的成绩是510万英里,对比全美平均的69.9万英里。
硬件:自研AI4,车与机器人共用
一个容易被忽略但很重要的细节:目前FSD和Optimus都跑在特斯拉自研的AI4推理芯片上,采用双计算机并行运行、互相校验的冗余架构——一台出问题,另一台瞬间接管。
这意味着特斯拉在车端部署的算力平台,与机器人端的算力平台是同一套硬件体系。从工程角度看,这是“一套基础模型覆盖多种平台”的前提条件。芯片架构师可能会对这套设计的功耗、带宽和故障切换机制感兴趣,但从产品层面看,核心信息就是:特斯拉已经在底层打通了车与机器人之间的硬件壁垒。
把自动驾驶压缩成“2个token”
整场演讲最核心的部分,是Elluswamy对端到端架构的系统性阐述。
特斯拉的端到端模型结构并不复杂:多模态输入(摄像头视频、导航指令、车辆运动学、音频)喂进一个大网络,36Hz运行,直接吐出下一步控制动作。没有手写规则,没有中间表示的硬切分。
但他现场算了一笔此前鲜少被公开的数据账。输入端:7路摄像头×36帧/秒×500万像素×30秒历史缓冲,再除以5×5像素块——仅视频输入的上下文就达到约20亿个token。再加上导航地图、100Hz运动数据、48kHz音频。
而输出端只有2个token:下一步的转向角度和加速度。
“学会从20亿个token中正确映射到2个token”,这就是Elluswamy眼中自动驾驶的本质问题。他称之为“维度灾难”,并给出了判断:应对维度灾难的唯一解,是规模化的车队数据。
这引出了特斯拉对数据的两个核心诉求:一是极强的泛化能力,二是“主动安全”——模型必须在罕见、危险的长尾场景里提前做出预判。现场播放了一段视频:城市道路上,一个骑车的孩子突然摔倒滚向车道,系统提前减速避让。Elluswamy点了一句:“这种场景人工根本造不全,只能靠真实车队捞回来。”
三道关卡:可解释性、评估与闭环模拟
端到端模型最大的质疑是“黑箱”。Elluswamy对此的回应是用思维链和过程验证来破解。
特斯拉的模型在输出动作的同时,会同步预测一组“可被人读懂”的中间结果:3D占据与流、物体检测(车辆/行人/骑行者)、交通管制状态、道路边界与车道语义、各交通参与者的交互概率,以及——用自然语言表达的决策理由。
现场演示了一个长尾场景:车辆遇到前方施工封闭加改道标志。系统用一问一答的链条自我推理:“能直行走导航路线吗?→不行,前方有改道牌和施工护栏。→那该怎么走?→在这个路口左转。→为什么不右转绕?→因为改道牌指示向左。”每一步都标注了对错。
第三道关卡——评估——被Elluswamy称为“三道关卡里最难的一道”。原因是开环做得好不保证闭环也好,避免一次事故有多种正确解法,指标必须能容纳这种“多模态”。好的数据集和loss值,不足以代表真实性能。
特斯拉的解法是训练一个神经网络世界模拟器。它接收“当前状态+动作”,预测“下一时刻状态”(摄像头画面、导航、运动学、音频),再喂给策略网络产生下一步动作——形成一个完全在神经网络内运转的闭环。这个模拟器可以用便宜易得的状态-动作数据训练,能做策略评估、回归测试,甚至主动注入对抗场景;压缩算力后还能实时运行。
更重要的是,这套神经模拟方法可以直接从FSD迁移到Optimus,把工厂、室内等场景一并生成出来。
回头看:特斯拉自动驾驶近两年的主要突破
CVPR 2026的这场演讲,放在特斯拉近两年的自动驾驶演进脉络中看,是一个阶段性的总结节点。
2024年下半年到2025年初,FSD完成了从V12到V13的迭代。V12是特斯拉首个全端到端的量产版本,用神经网络替代了此前三十多万行C++手写规则代码。这是一个架构级别的切换——从“感知用神经网络、规划用代码”变成了“感知和规划都在同一个网络里完成”。V13在此基础上大幅提升了城市复杂路口的通过率和变道时机判断,引入车位到车位的端到端能力,用户从停车场出发到目的地停车,中间基本没有断点。
2025年,FSD的累计行驶里程突破100亿英里。这个数字本身或许只是宣传口径,但其对应的数据飞轮效应是实质性的:里程越多→长尾场景采样越密→模型训练越充分→体验越好→用户使用频率越高→里程更多。特斯拉没有对外公开过具体的训练算力规模,但行业普遍估算其训练集群在数万张H100级别以上,且仍在扩张。
2025年下半年到2026年初,几个标志性事件值得注意。一是FSD监督版在中国落地,作为首个进入中国市场的海外智驾方案,其在本土路况下的适应速度和表现受到了相当程度的行业关注。二是Optimus与FSD在底层模型和芯片上正式打通,形成了从“感知-规划-控制”到“任务理解-动作生成”的统一架构。三是特斯拉首次明确提出了Robotaxi的时间表,而支撑Robotaxi商业化的技术前提——去安全员、远程接管、车队调度——都离不开一个足够可靠的端到端模型。
CVPR 2026的演讲,本质上是在给上述这些进展做一个技术层面的“交底”:端到端为什么是必须的、难点在哪、特斯拉是怎么解的、下一步往哪走。
对中国玩家意味着什么
这场演讲给国内智驾行业传递的信息,不是“特斯拉有多强”,而是它正在把自动驾驶重新定义为“具身智能的一个子集”——车只是第一个身体,Optimus是第二个,数字智能体是第三个。三者共享同一套基础模型。
这意味着竞争维度正在发生迁移。算法本身的差距会逐渐收敛,算力可以采购,真正的分水岭在于数据飞轮的效率和闭环评估体系的可信度。谁能更便宜、更快地搭建从数据采集到神经模拟到闭环评测的完整工具链,谁就能在迭代速度上跑赢对手。
这恰好是国内拥有海量真实路况数据的玩家最有机会发力的方向,但也是最容易被忽视的环节——因为它不如跑分、不如Demo视频、不如“城市NOA开城数量”那样有传播性。但特斯拉正在用整个演讲表明:那些看不见的工程基建,才是决定终局的东西。