前不久,清华大学联合滴滴自动驾驶,以及香港中文大学多媒体实验室,发布了无人驾驶视觉大模型ColaVLA,文章是《ColaVLA: Leveraging Cognitive Latent Reasoning for Hierarchical Parallel Trajectory Planning in Autonomous Driving》,主要内容摘要如下,

1️⃣ 背景:
无人驾驶需要基于复杂的多模态输入生成安全可靠的轨迹。
传统的基于规则的系统会分割成感知、预测、规划多个模块;而端到端会联合学习感知、预测、和规划。
而VLM通过引入跨模态的先验知识和常识推理,使端到端更成为很多自动驾驶的架构选择。

2️⃣ 然而目前基于VLM的规划系统面对几个关键挑战,
1)离散的文本推理与连续的控制间的对齐问题。
2)基于chain-of-thought的大模型自回归编码的较高的时延。
3)低效满足不了实时性的要求,而无法部署到实车上。
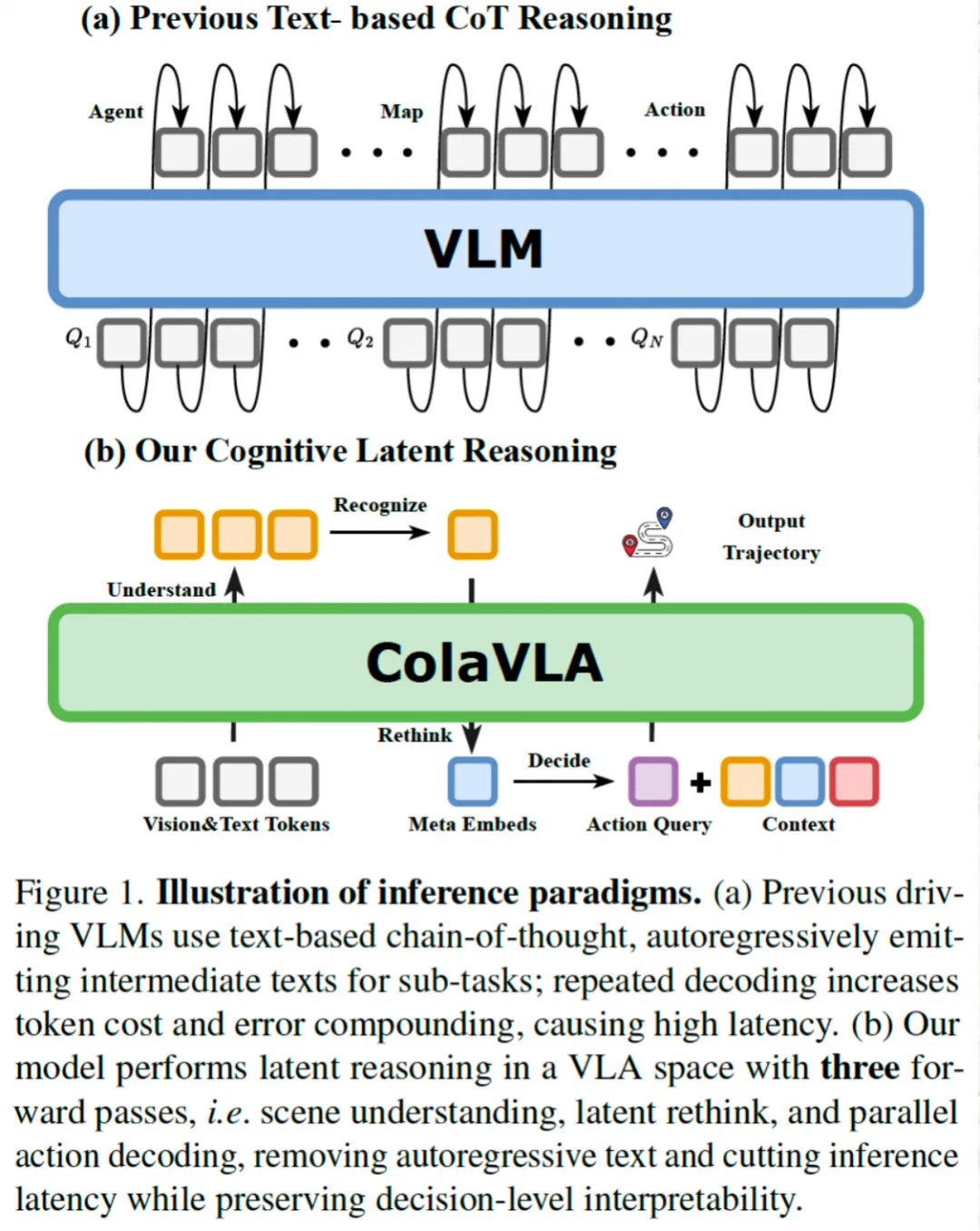
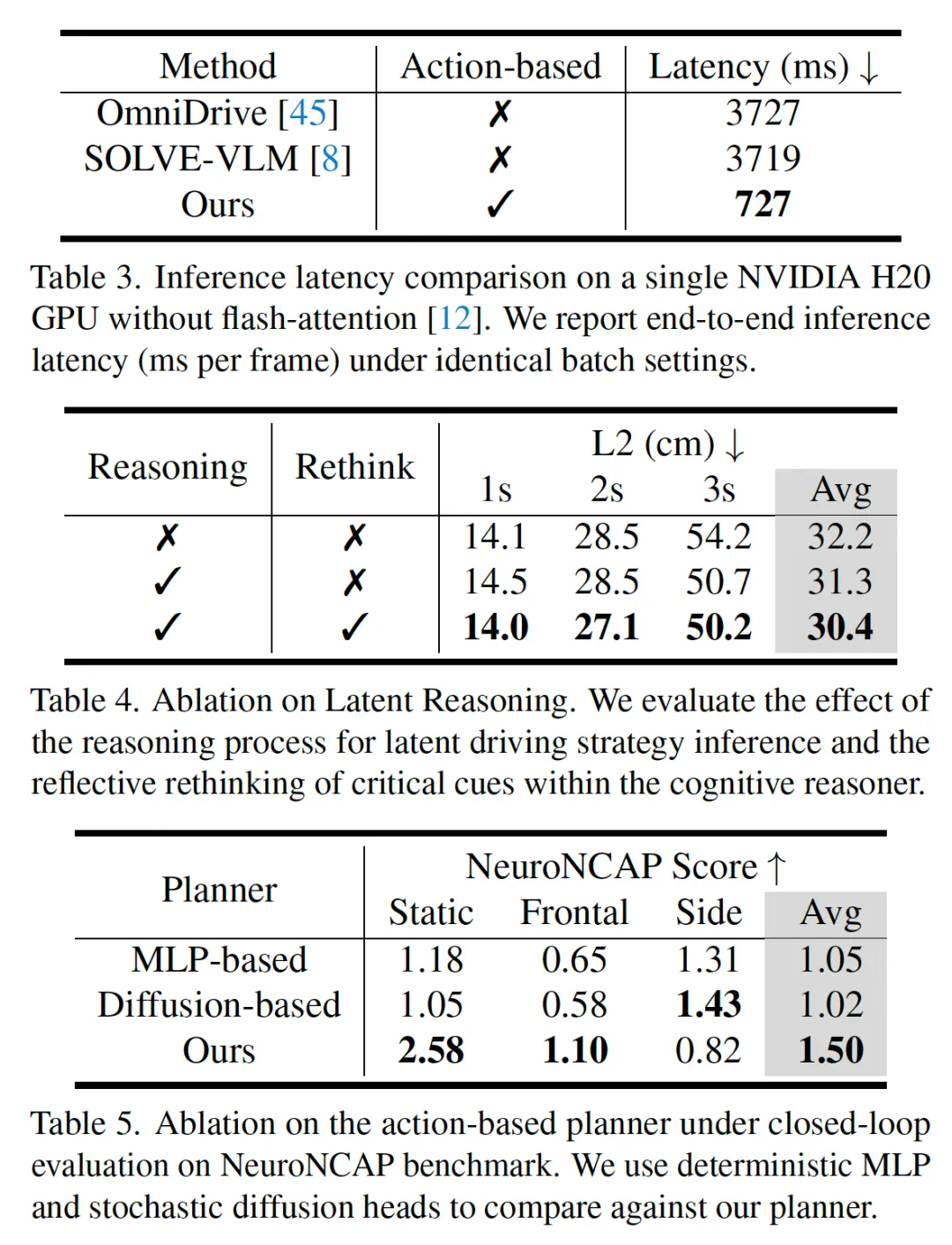
3️⃣ 模型主要分为两大部分,
1)Cognitive Latent Reasoner:通过视觉推理,基于上下文以及自车状态,筛选出最重要的K个关键视觉元素Token,并生成多个粗略的驾驶决策maneuver(直行,左转,制动等)。
2)Hierarchical Parallel Planner:为每个maneuver并行生成多scale的轨迹。
4️⃣ Cognitive Latent Reasoner主要涉及如下
(a)视觉场景理解:将视觉&文本&车辆状态拼接起来丢给大模型,进行视觉推理,输出理解后的视觉token。
(b)关键实体识别:基于Ego Token筛选出最重要的K个视觉token,以表征车道线、边界、动态交通参与者、静态障碍物等对自车决策比较重要的视觉元素。
(c)粗粒度驾驶策略规划:基于核心输入,生成粗略的的规划决策,用Meta Query来表达,可以将每个Meta Query近似为一个maneuver,比如直行、左转、右转、掉头、刹车等等
(d)maneuver选择:计算每个maneuver的概率,并筛选出概率最高的N=3种(比如左转、直行、刹车)

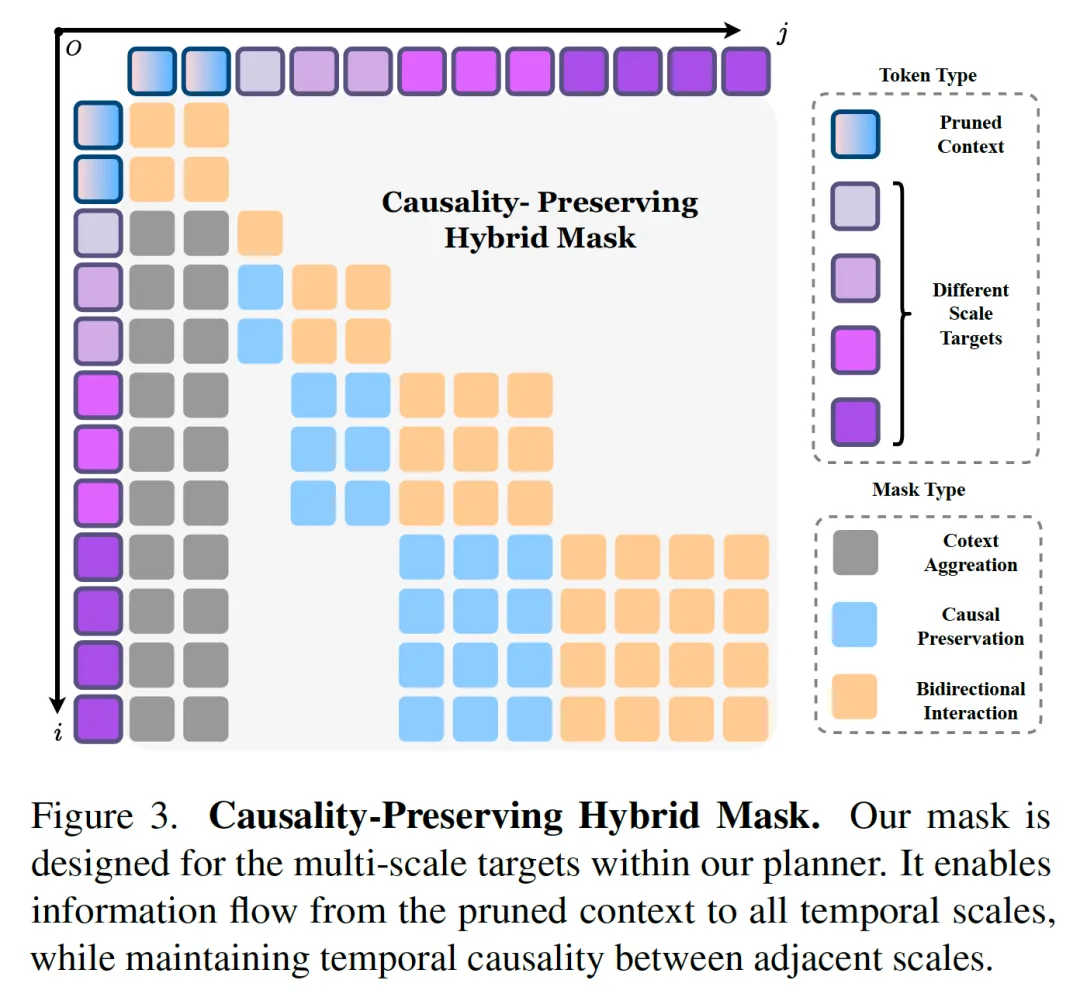
5️⃣ Hierarchical Parallel Planner的主要涉及如下
1)根据不同maneuver,转化成对应的Multi-Scale Target。
2)并行计算三种maneuver(比如左转、直行、刹车)对应的Multi-Scale 的轨迹。
6️⃣ 三阶段训练策略,
第一阶段:通过OmniDrive nuScenes QA pairs数据来训练VLM模型骨架。
第二阶段:通过k-mean,从nuScenes轨迹数据聚类出meta-action 类型,比如直行,换道,左转,制动等等。
冻结VLM,主要训练meta-action分类器,以及轨迹预测head,来将latent meta-actions与典型的驾驶maneuver(e.g., straight, lane change, turn, braking)对齐,这为后续的下游的分层次planing提供结构化的和稳定的先验知识
第三阶段,通过nuScenes planning supervision进行端到端微调,依然冻结VLM,主要训练其他参数。
7️⃣ 文章的模型的backbone是(LLaMA-7B),
图像的Image encoder是EVA-02-L
视觉推理模块SQ-Former
核心训练数据集:nuScenes

8️⃣ 文章在nuScenes数据集上做了仿真测试,取得了state-of-the-art水平,
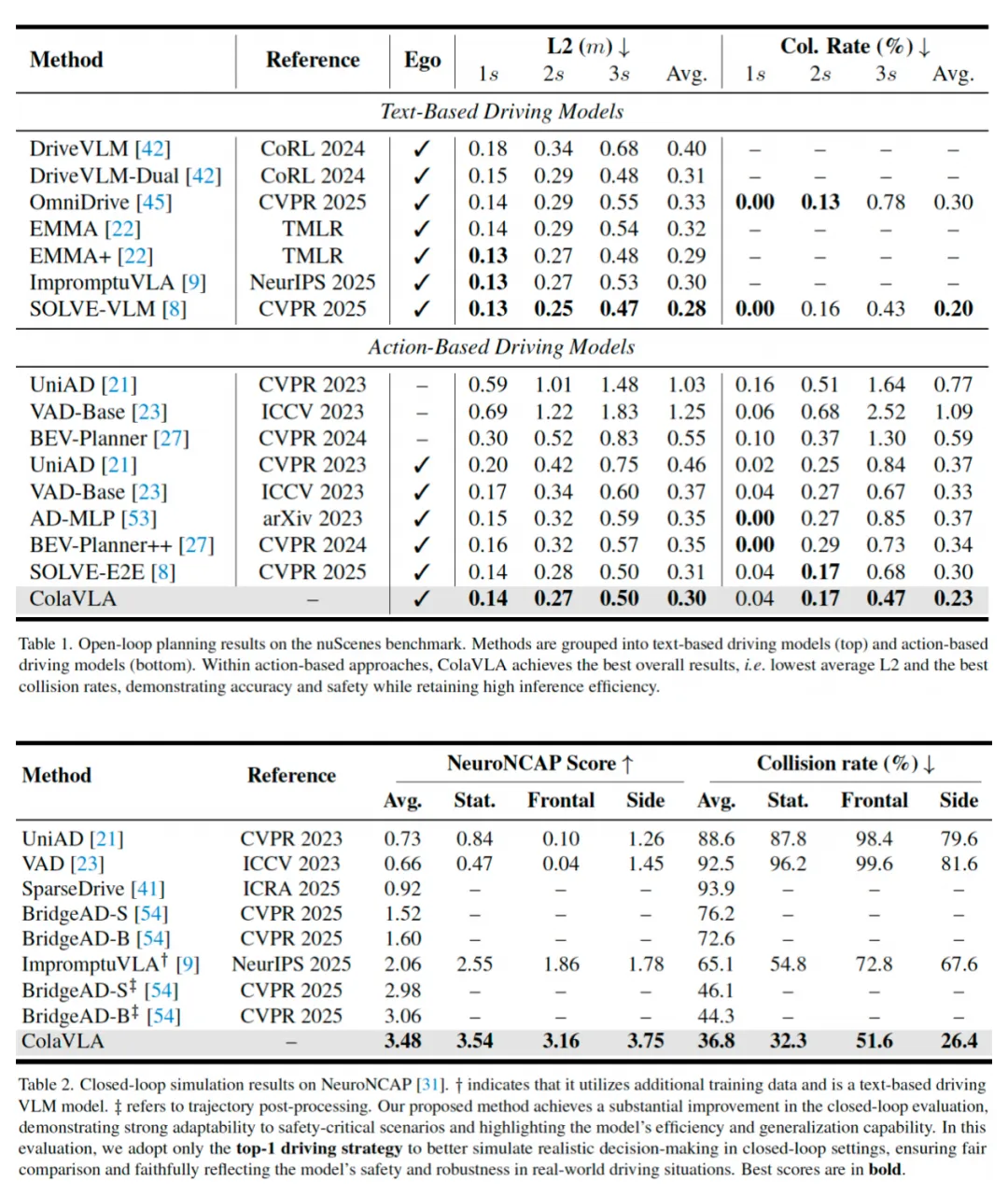
9️⃣ 几个点评
1)通过强制生成多个决策,尽量避免模型坍塌。
2)Multi-Scale设计以及训练可以缓解驾驶场景真值不唯一带来的模型收敛性问题。