自动驾驶 | LingBot-Map 深度解析:为什么单目 RGB 也开始具备稳定的流式 3D 重建能力
- 2026-06-19 21:42:27
自动驾驶 | LingBot-Map 深度解析:为什么单目 RGB 也开始具备稳定的流式 3D 重建能力
0. 导读
如果把问题说得更直接一些,LingBot-Map 想解决的并不是“如何把一组图片重建成 3D”,而是如何让一个只看单目 RGB 视频流的系统,在不知道未来帧的前提下,一边接收画面,一边持续估计位姿、恢复深度、维护三维地图,而且序列拉长后还不明显漂移。这比离线多视图重建难得多,因为它同时受制于三个条件:没有未来信息、历史上下文会不断膨胀、系统还必须维持实时性。
如果只记住一句话,那么对 LingBot-Map 更准确的概括不是“又一个 3D 重建模型”,而是一个把经典 SLAM 的空间记忆结构重新写进 Transformer 的流式三维重建基础模型。它的关键贡献也可以压缩成三点。第一,它没有沿用“保存全部历史”或“把历史极度压缩成单状态”这两种常见路线,而是把流式上下文拆成 Anchor、Pose-reference Window 和 Trajectory Memory 三层几何记忆。第二,它把这种结构直接落实到可运行的推理系统里,通过分页 KV cache、FlashInfer 和 keyframe 策略把万帧长序列推理做到了工程可用。第三,它在多项公开基准上证明,这套设计不仅速度够快,而且长程稳定性确实比现有多数流式方法更强。
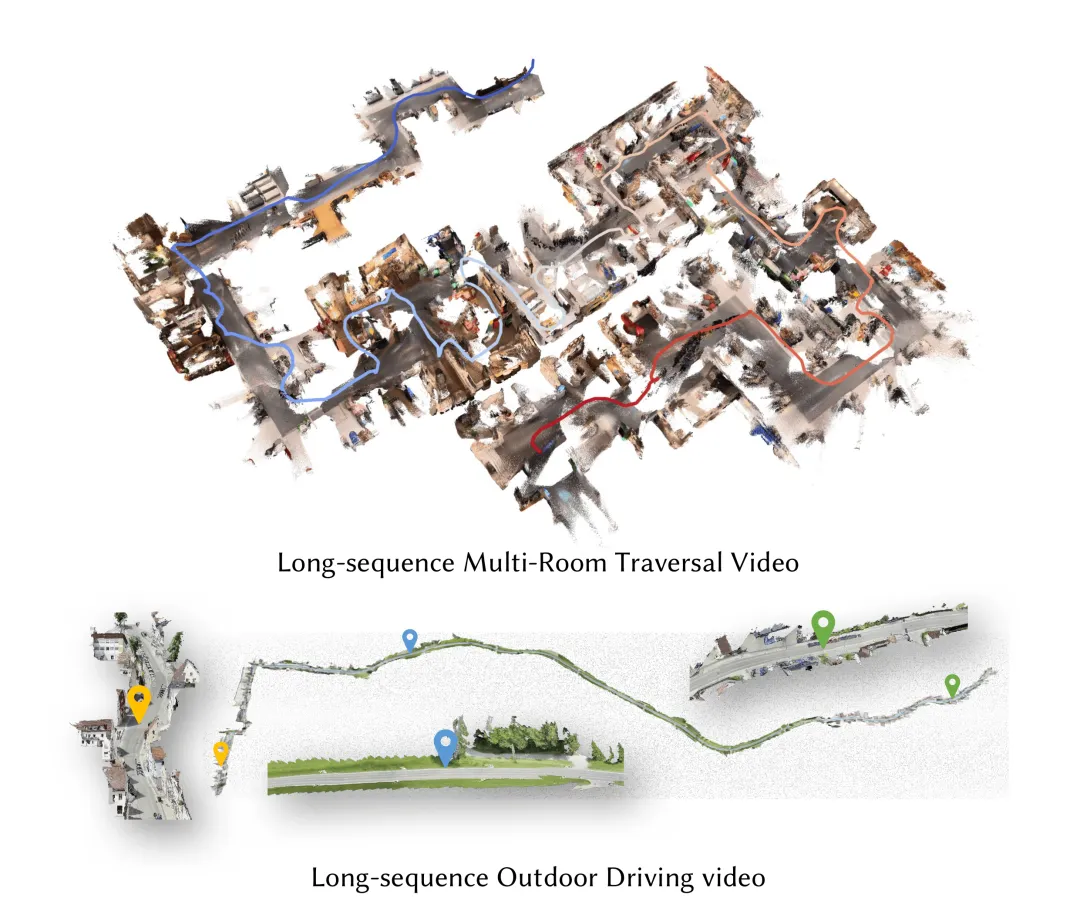
1. 问题与定义
最近两年,3D 视觉领域最显眼的进展,大多来自离线多视图基础模型,例如 VGGT、DUSt3R、Depth Anything 3 这一类方案。它们的共同优点是,只要把一组图像整体送进去,就能在一个前向过程中恢复相机姿态、深度图和点云,结果通常非常漂亮。但这类方法有一个在机器人场景里很现实的问题:它们默认可以看到全部图像,也就是“先拿到完整输入,再做全局推理”。现实世界中的机器人并没有这个条件,它只能一边移动一边接收新画面,必须在不知道未来会发生什么的前提下持续定位和建图。这就把问题从“重建得准不准”变成了 “能不能边看边建、边建边记、边记还不爆内存”。
从这个角度看,LingBot-Map 值得关注,不是因为它把某个 benchmark 的分数再往上抬了一点,而是因为它正面对准了流式三维重建里最核心的三难困境:几何精度、时序一致性和计算效率很难同时兼顾。传统方法通常要么偏向局部精度,结果长程漂移严重;要么 保留过多历史信息,结果序列一长内存和时延都迅速恶化;要么又把深度模型和传统优化式 SLAM 后端硬拼在一起,虽然效果尚可,但工程复杂、实时性有限。LingBot-Map 的路线是,把经典 SLAM 中“空间上下文分层管理”的思路直接变成可学习的注意力结构,于是模型不再只是记住更多,而是开始学会 “该保留什么、该压缩什么、该遗忘什么”。
按照论文定义,LingBot-Map 是一个面向流式 3D reconstruction 的 feed-forward foundation model,它接收连续视频流,只使用当前帧和过去帧,在不访问未来帧的前提下,输出相机位姿、深度图以及可用于点云恢复的世界坐标信息。官方论文,GitHub、Hugging Face 同步上线。目前官方已经公开 lingbot-map-long、lingbot-map 和 lingbot-map-stage1 三类权重,其中 lingbot-map-long 明确标注为更适合长序列和大场景的推荐版本。更重要的是,LingBot-Map 不是单纯把离线模型“改造成因果模式”这么简单。论文强调,它的架构核心叫 Geometric Context Transformer,而真正使之成立的关键机制是 Geometric Context Attention(GCA)。这个注意力机制不再让当前帧对全部历史帧做一视同仁的因果注意力,也不再简单地用一个 RNN 式状态去硬压缩整个过去,而是把历史上下文拆成三种作用完全不同的记忆层次:锚点上下文、位姿参考窗口和轨迹记忆。换句话说,它把“历史”从一个笼统的概念拆成了三种不同职责的几何记忆,这也是 LingBot-Map 能在长视频上维持稳定表现的根本原因。
论文地址:https://arxiv.org/html/2604.14141v2GitHub仓库:https://github.com/robbyant/lingbot-mapHugging Face仓库:https://huggingface.co/robbyant/lingbot-map
1.1 真正困难的地方
很多第一次接触这类工作的读者,会天然地把“流式三维重建”理解成“把普通多视图重建改成逐帧推理”。这其实低估了问题的难度。离线重建允许模型回看全局,必要时还可以重新排列视图关系,甚至通过优化在全序列层面一起修正误差;流式重建却必须在每一帧到来时立刻给出当前结论,并把这个结论作为后续所有推理的基础。只要前面某一段轻微漂移,后面就可能越走越偏。再加上单目 RGB 本身存在尺度歧义、遮挡、光照剧变、低纹理、室内外切换和动态干扰等问题,系统如果没有长期稳定的几何记忆,就很容易在长任务里变成“前面会走,后面迷路”。
更麻烦的是,内存问题和这个几何问题是绑在一起的。最直接的办法当然是保留所有历史帧的全部 token,让当前帧去看完整过去,但这样做的代价是,随着序列长度增长,KV cache 和计算量几乎线性甚至接近平方级上升,很快就不再具备工程可用性。另一种办法是把历史压成很小的状态,但压得太狠又会导致有用的几何线索被遗忘,尤其在回到旧位置、跨房间穿行、进入低光环境、或者经过大尺度户外场景时,漂移会被迅速放大。LingBot-Map 之所以值得看,就在于它不是在这两个极端之间取一个经验折中,而是给出了一种带结构先验的“选择性记忆”方案。
2. 核心方法与复杂度
论文里最重要的概念,是 GCA 把流式上下文拆成了三层。第一层是 anchor context,也就是锚点上下文,用来回答“坐标系从哪里起、尺度怎么定”这个问题。单目重建天然缺绝对尺度,如果系统一开始没有一个稳定的参考系,后面每一帧的位姿和深度都会受到影响。LingBot-Map 通过把最开始的少量帧指定为 anchor frames,并在训练时用这些 anchor frames 派生出规范化尺度,让之后所有帧都能围绕同一个坐标系工作。你可以把它理解成,在真正开始长程流式推理之前,模型先给自己打一颗“定位钉子”,避免后面越跑越虚。
第二层是 pose-reference window,也就是位姿参考窗口。这个部分负责记住“我附近到底有什么”,它保留最近若干帧的完整视觉 token,用来支持当前帧与邻近帧之间的精细几何对齐。之所以不能只保留 anchor,是因为 anchor 虽然能解决坐标和尺度基准,却不足以为当前帧提供密集的局部重叠信息。机器人转个弯、走进另一个房间、贴着桌边移动时,真正决定当下位姿估计精度的,往往不是很早之前的第一帧,而是刚刚看过的那几十帧邻域信息。论文还专门为这个局部窗口加入了相对位姿损失,让模型不仅知道“我整体在世界里的位置”,也知道“我和邻近帧之间的相对几何关系”。
第三层是 trajectory memory,也就是轨迹记忆。它解决的是“我走过哪些地方,哪些历史线索不能完全丢掉”这个问题。LingBot-Map 不会像全注意力那样把每一帧的全部图像 token 永久保留,而是当一帧离开局部窗口后,只为它保留一个极小的压缩表示。论文里给出的数字非常关键:离开窗口的历史帧只保留 6 个上下文 token,而不是继续保留约 500 个完整 token。这样一来,系统仍然拥有整条轨迹的稀疏几何摘要,足以做长期漂移纠正,却不必背着完整历史图像一路前行。这个思路其实非常接近人类导航经验:你不会记住每一秒看到的全部像素,但你会记住“起点在哪里、刚刚经过了什么、很久以前拐过哪几个关键弯”。
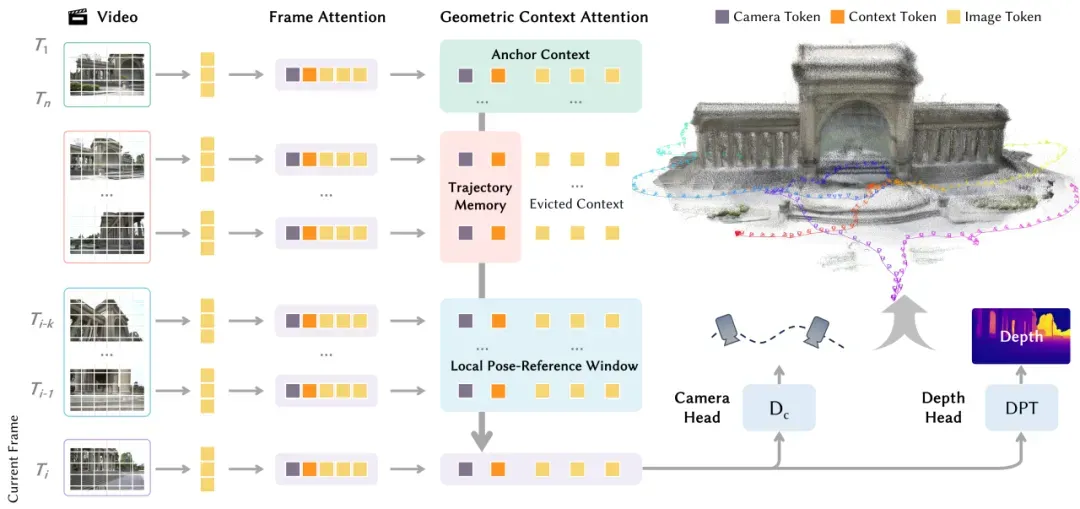
论文给出了一组非常有说服力的复杂度对比。典型的因果注意力方案,每新增一帧,大约要把当前帧的全部 token 都加进缓存,增长量接近每帧 500 个 token;而在 GCA 里,当一帧离开局部窗口后,只留下 6 个压缩 token,增长量从 500 直接降到 6。论文给出的示例是,在 n=3 个锚点帧、k=16 个局部窗口帧、序列长度 T=10000 的情况下,普通因果注意力需要缓存大约 5×10^6 个 token,而 GCA 只需要大约 7×10^4 个 token。换句话说,LingBot-Map 的历史上下文不是完全不增长,但增长速度被压得极低,这就是它为什么能把万帧级别的视频流拉进一个仍可运行的推理系统里。
这组数字的意义不只是“更省显存”,而是它重新定义了流式 3D 模型可工作的时序范围。很多早期方法在几百帧时还算正常,拉到几千帧就开始严重漂移,或者只能靠测试时训练、后优化、回环修正等额外机制勉强维持。LingBot-Map 则把主要问题放在前向结构里解决,也就是先把 memory growth 压下来,再去争取全局一致性。这种顺序非常重要,因为如果内存和计算本身不受控,后面的任何算法改进都很难真正落地。对机器人系统而言,能连续稳定运行通常比单次最优精度更重要,LingBot-Map 恰好在这两者之间做出了比较平衡的取舍。
3. 公开代码与实现流程
官方仓库公开的是一个相对完整的推理包,而不是全量训练框架。仓库顶层包括 demo.py、gct_profile.py、pyproject.toml 和 lingbot_map/ 包,其中 lingbot_map/models/gct_base.py 定义了统一的基础模型外壳,lingbot_map/models/gct_stream.py 对应流式推理主实现,lingbot_map/models/gct_stream_window.py 对应长序列窗口化推理,lingbot_map/aggregator/stream.py 是带 KV cache 的流式聚合器,lingbot_map/heads/camera_head.py 和 lingbot_map/heads/dpt_head.py 则分别负责位姿头与深度/点云头。这个结构透露出一个很值得注意的信息:官方更强调 “能跑起来的 streaming inference system”,而不是只给一个 checkpoint 文件让用户自己摸索。
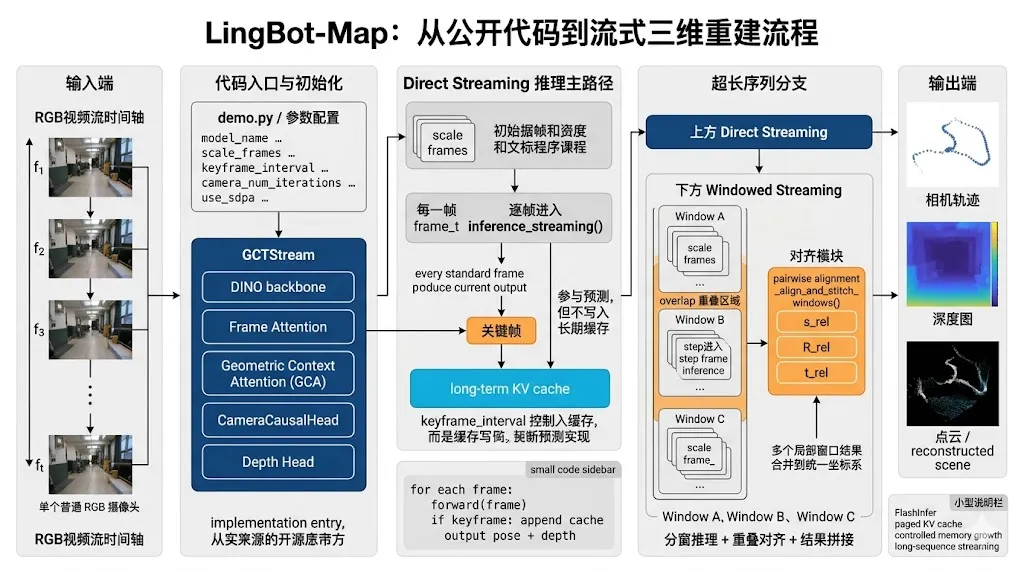
GCTBase 负责把聚合器和各类预测头拼起来,统一输出 pose_enc、depth、world_points 等结果;GCTStream 负责流式模式下的 scale frame 初始化与逐帧前向;AggregatorStream 负责真正的因果聚合与分页 KV cache;CameraCausalHead 负责迭代式位姿细化;DPTHead 则把聚合后的 patch token 恢复成深度图和点云。换句话说,论文中“GCT + GCA + pose/depth prediction heads”的抽象,在仓库里并不是一个不可见的大黑盒,而是已经被拆成了比较清晰的工程模块,这对理解实现流程非常重要。
demo.py | ||
lingbot_map/models/gct_base.py | ||
lingbot_map/models/gct_stream.py | ||
lingbot_map/models/gct_stream_window.py | ||
lingbot_map/aggregator/stream.py | ||
lingbot_map/heads/camera_head.py | ||
lingbot_map/heads/dpt_head.py | ||
gct_profile.py |
3.1. 模型初始化
从公开代码看,官方 demo.py 在加载模型时,并没有隐藏太多工程细节,而是直接暴露了几组最关键的推理超参数。下面这段代码来自官方仓库,它说明 GCTStream 初始化时就把图像分辨率、3D RoPE、最大帧数、KV cache 滑窗大小、scale frame 数量以及相机头迭代次数全部当作一等配置项。也就是说,LingBot-Map 不是“固定结构 + 固定推理模板”的封闭产品,而是一个允许用户根据显存、序列长度和速度需求去调节的流式系统。
model = GCTStream( img_size=args.image_size, patch_size=args.patch_size, enable_3d_rope=args.enable_3d_rope, max_frame_num=args.max_frame_num, kv_cache_sliding_window=args.kv_cache_sliding_window, kv_cache_scale_frames=args.num_scale_frames, kv_cache_cross_frame_special=True, kv_cache_include_scale_frames=True, use_sdpa=args.use_sdpa, camera_num_iterations=args.camera_num_iterations,)这段初始化代码透露出三个工程层面的重点。第一,kv_cache_sliding_window 和 kv_cache_scale_frames 明确对应论文中的局部窗口与尺度参考帧概念,说明论文中的上下文分层并不是只存在于文字叙述里,而是真正进入了推理代码的参数接口。第二,use_sdpa 说明官方默认推荐 FlashInfer,但仍保留了纯 PyTorch 原生注意力的回退路径,这种设计很务实,因为它兼顾了最快性能和最低依赖门槛。第三,camera_num_iterations 表明位姿头不是一次性输出,而是迭代细化的,这一点也和论文中的 relative pose consistency 与稳定长序列位姿估计目标相吻合。
3.2 流式主循环
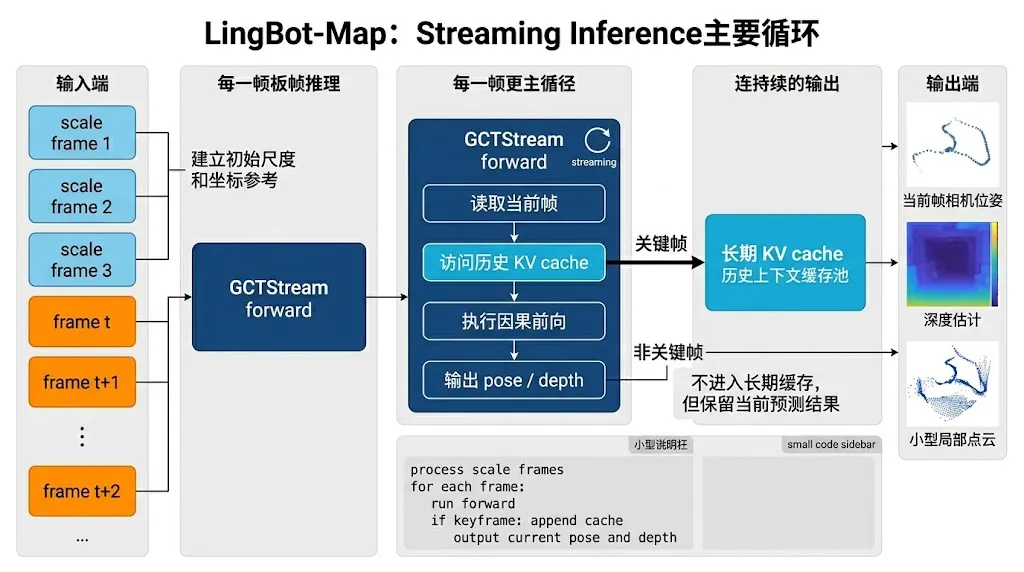
如果继续沿着 gct_stream.py 往下看,官方公开的 inference_streaming() 函数几乎就是论文“Direct Output Mode”的代码版说明书。它先把序列最开始的若干帧作为 scale frames 统一处理,这些帧之间 允许更强的内部信息交换,用来建立可靠的初始尺度和坐标参考;然后从后续帧开始,一帧一帧地执行因果前向,每一步都读当前帧、访问历史 KV cache,并立刻输出位姿和深度结果。更关键的是,它在代码里明确实现了 keyframe_interval 逻辑,让非关键帧也能参与预测,但不必把自己的 KV 永久塞进缓存,这就是论文中“保留全部预测、但不保留全部历史”的工程落点。
scale_output = self.forward( scale_images, num_frame_for_scale=scale_frames, num_frame_per_block=scale_frames, causal_inference=True,)for i in range(scale_frames, S): frame_image = images[:, i:i+1] is_keyframe = (keyframe_interval <= 1) or ((i - scale_frames) % keyframe_interval == 0) if not is_keyframe: self._set_skip_append(True) frame_output = self.forward( frame_image, num_frame_for_scale=scale_frames, num_frame_per_block=1, causal_inference=True, ) if not is_keyframe: self._set_skip_append(False)这段代码最值得注意的,不是 Python 语法本身,而是它体现的推理思想。官方没有把“关键帧”理解成“只对关键帧做预测”,而是理解成 “只让关键帧进入长期缓存”,这样做可以同时保住实时输出能力和长期显存可控性。对实际部署来说,这比很多传统视觉 SLAM 方案更适合模型化系统,因为它既保留了每一帧的连续感知结果,又不会像全缓存那样让历史状态无限膨胀。仓库 README 也进一步给出建议:当序列超过 320 帧时,可以显式设置 --keyframe_interval 来限制缓存长度,从而在训练视角范围之外尽量维持稳定推理。
3.3 长序列窗口化推理
论文和仓库都没有回避一个事实:即使 GCA 极大压缩了状态增长,Direct 模式也不是无限制稳定的。论文给出的经验结论是,Direct 模式在大约 3000 帧以内通常更准确,因为它避免了跨窗对齐误差;但当序列长度显著超过这个范围,VO/Windowed 模式会更实用。官方仓库中的 gct_stream_window.py 正是这个思想的实现版本。它不是把整段视频一次性送入模型,而是按窗口切开,每个窗口都先做一段 scale frame 初始化,再做局部流式推理,最后通过重叠区域进行跨窗对齐与拼接。
代码文档写得很清楚:window_size 统计的是 “进入 KV cache 的关键帧数”,不是实际视频总帧数;当 keyframe_interval > 1 时,一个窗口覆盖的真实帧数会大于 window_size。这件事的工程含义非常重要,因为它说明官方已经把“时间长度”和“缓存长度”区分开了。长视频本身不可怕,可怕的是缓存状态无限变长。只要把关键帧和窗口设计好,系统就可以在相对稳定的内存上处理更长的物理时间跨度。对机器人巡检、室内多房间穿行或城市级视频感知来说,这是一种很实用的折中。
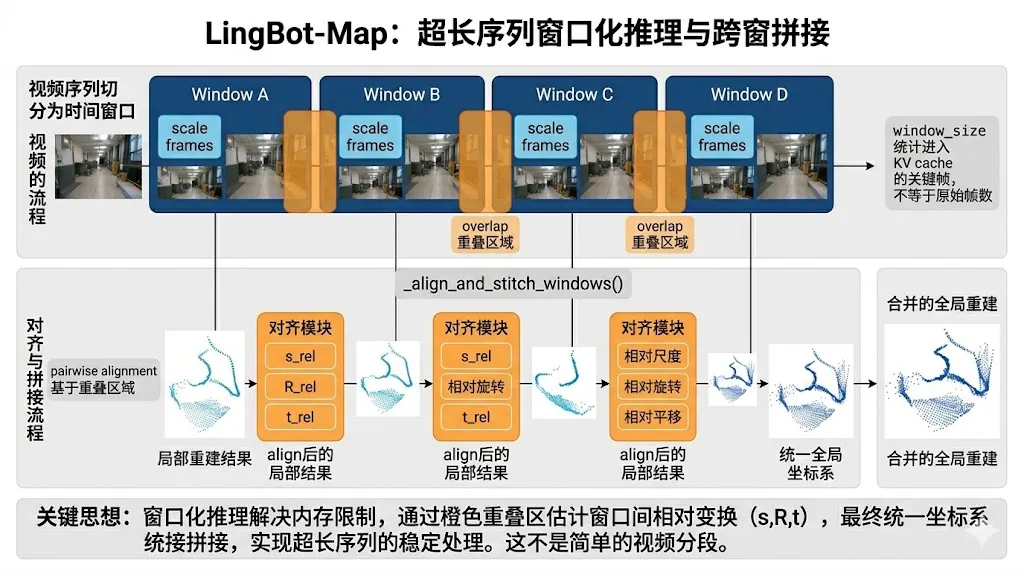
从代码实现上看,窗口化推理并不是简单切片,而是“分窗推理 + 重叠区对齐 + 结果拼接”三步。官方在 _align_and_stitch_windows() 中显式保存每个窗口的缩放、旋转和平移变换,并在最终输出里附带 chunk_scales 和 chunk_transforms。这意味着 windowed 模式不是黑盒后处理,而是一个带坐标对齐元数据的显式拼接过程,后续如果你想做可视化或误差分析,这些信息都可以直接继续利用。
def _align_and_stitch_windows(self, windows, scale_mode='median'): for idx, raw in enumerate(windows): if idx == 0: s_rel = torch.ones(nb, device=dev, dtype=dt) R_rel = torch.eye(3, device=dev, dtype=dt).unsqueeze(0).expand(nb, -1, -1).clone() t_rel = torch.zeros(nb, 3, device=dev, dtype=dt) else: s_rel, R_rel, t_rel = self._pairwise_alignment( warped_windows[-1], raw, overlap, nb, dev, dt, ) warped_windows.append( self._warp_predictions(raw, R_rel, t_rel, s_rel, nb) ) merged = self._stitch_windows(warped_windows, win_sz, overlap)这段代码对应论文里 VO 模式最关键的思想:窗口内部尽量保持局部精度,窗口之间通过重叠区估计相对变换,再把所有局部结果拉回同一个全局坐标系。它的代价当然是边界处会引入额外拼接误差,但换来的是内存上界被严格控制,因此适合几千帧以上的超长序列。
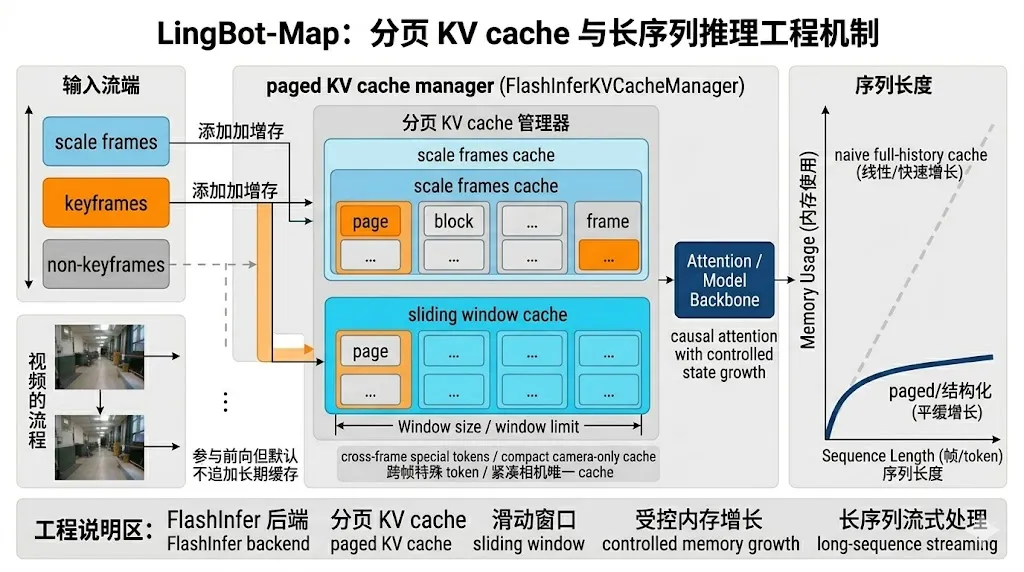
3.4 分页 KV cache 与后端
如果只看论文,很容易把 LingBot-Map 的创新全部归结为 GCA 的几何记忆设计;但从公开仓库看,真正让它在工程上能跑到大约 20 FPS 的,还有一整套推理侧优化。aggregator/stream.py 里明确写到,默认后端是 FlashInfer,同时保留 SDPA 回退模式。它并不是简单调用一个标准 Transformer block,而是针对流式场景专门维护 kv_cache_sliding_window、kv_cache_scale_frames、kv_cache_cross_frame_special 和 kv_cache_camera_only 等控制项,必要时甚至支持只保留 camera token 的极限压缩模式。这些名字看起来像工程细节,其实恰恰说明论文里的“上下文分层”和“缓存结构化管理”已经被编码成真实的推理逻辑。
更值得一提的是,仓库里还单独提供了 gct_profile.py,它的目标不是做模块级炫技 profiling,而是直接测量顶层 model.forward() 的 GPU 时间,并比较不同后端、不同精度、不同 camera_num_iterations 设置下的整体吞吐。这个脚本甚至会在 profiling 时显式移除 point_head 来观察速度变化,说明官方团队在公开代码层面非常清楚地把“研究指标”和“部署速度”区分开了。对于一篇强调实时性的 3D 论文来说,这种开放式工程验证比单纯写一句“我们大约 20 FPS”更有说服力,因为它把速度问题真正落实到了可复现的脚本和参数开关上。
更具体地说,分页 KV cache 的价值在于它不是每来一帧就重分配整段缓存,而是按页管理历史 token,只增量维护新进入缓存的内容。这和普通 contiguous KV cache 的差别,在长序列 streaming 场景里会被放大,因为 LingBot-Map 的推理不是“一次大前向”,而是成千上万次小前向。缓存管理如果设计不好,额外开销会直接吞掉模型本身省下来的那部分计算。
def _get_flashinfer_manager(self, device, dtype, tokens_per_frame=None): if self.kv_cache_manager is None: max_num_frames = self.kv_cache_scale_frames + self.kv_cache_sliding_window + 16 self.kv_cache_manager = FlashInferKVCacheManager( num_blocks=self.depth, max_num_frames=max_num_frames, tokens_per_frame=tokens_per_frame, num_heads=num_heads, head_dim=head_dim, dtype=dtype, device=device, num_special_tokens=self.num_special_tokens, scale_frames=self.kv_cache_scale_frames, sliding_window=self.kv_cache_sliding_window, )这段代码说明,缓存管理器初始化时就显式知道“多少帧属于 scale frames、多少帧属于 sliding window、每帧多少 token、每层多少 block”,也就是说,GCA 并不是只在注意力 mask 层面发挥作用,它直接渗透进了缓存布局本身。这也是为什么论文能把“选择性记忆”同时讲成一个几何问题和一个系统问题。
3.5 相机位姿的迭代细化
论文里“相机位姿预测”听起来像一个结果项,但在公开代码里它其实是一个带内部循环的子系统,而不是简单的线性头。camera_head.py 里的 CameraCausalHead 不会一次性吐出最终位姿,而是从一个 learnable empty pose token 开始,迭代若干轮,每一轮都把上一次的位姿编码重新嵌入,再通过 trunk 和 pose_branch 产生一个增量更新。仓库默认 camera_num_iterations=4,这也正是 README 会提醒用户“把它改成 1 可以换速度”的原因。
这件事的技术含义在于,位姿估计在 LingBot-Map 里被当成“逐步逼近”的问题,而不是“一步分类或回归到位”的问题。对长序列流式模型来说,这个设计非常合理,因为当前帧的位姿并不是孤立量,它会受到历史轨迹、局部窗口对齐关系以及尺度参考的共同影响。先给一个粗位姿,再不断修正,通常比一次性给出绝对答案更稳。
for i in range(num_iterations): if pred_pose_enc is None: module_input = self.embed_pose(self.empty_pose_tokens.expand(B, S, -1)) else: pred_pose_enc = pred_pose_enc.detach() module_input = self.embed_pose(pred_pose_enc) shift_msa, scale_msa, gate_msa = self.poseLN_modulation(module_input).chunk(3, dim=-1) pose_tokens_modulated = gate_msa * modulate(self.adaln_norm(pose_tokens), shift_msa, scale_msa) pose_tokens_modulated = pose_tokens_modulated + pose_tokens for idx in range(self.trunk_depth): pose_tokens_modulated = self.trunk[idx](...) pred_pose_enc_delta = self.pose_branch(self.trunk_norm(pose_tokens_modulated)) pred_pose_enc = pred_pose_enc_delta if pred_pose_enc is None else pred_pose_enc + pred_pose_enc_delta这段代码里还有两个容易被忽略的细节。第一,上一轮预测会被 detach(),也就是当前轮修正不会反向穿透前一轮整条链路,这有助于控制训练稳定性。第二,位姿修正不是直接对原 token 做线性映射,而是经过带调制的归一化与 trunk block,再做 delta update,这使得“当前观测”和“上一轮位姿猜测”能够以更结构化的方式融合。对论文中强调的 long-sequence stability 来说,这种设计显然不是配角。
4. 训练策略与落地接口
这篇工作还有一个很容易被忽略的点,就是它并没有试图从零直接训练一个能处理长视频的流式模型。论文采用的是两阶段训练策略。第一阶段先用多达 29 个数据集训练一个短时序基础模型,目的是建立普适的几何先验;第二阶段再引入 GCA,把训练视角数从 24 逐步拉长到 320,同时加入相对位姿损失,让模型在更长的轨迹上保持稳定。这个策略很合理,因为如果一开始就让模型面对几百帧长序列,早期位姿误差会沿时间轴不断放大,训练极其容易不稳定。
论文还披露了相当多具有现实意义的训练成本信息。第一阶段大约需要 21500 GPU 小时,第二阶段大约需要 15360 GPU 小时,并使用 context parallelism 去分摊长序列注意力的显存压力。这些数字提醒我们,LingBot-Map 在推理端确实让普通 RGB 摄像头的价值大幅上升,但它省下的主要是传感器成本和部署复杂度,并不是训练成本。也就是说,这类模型的产业意义更像“把昂贵硬件前移为昂贵训练”,而不是“所有成本都消失了”。这恰恰是基础模型路线的一般规律:训练阶段重,部署阶段轻,规模化之后才能体现单次模型训练换来大量终端设备受益的价值。
公开仓库能直接做什么。
对工程用户来说,官方 README 提供的信息其实非常实用。安装层面,项目要求 Python 3.10、PyTorch 2.9.1,默认推荐 CUDA 12.8,并建议额外安装 FlashInfer 以获得分页 KV cache 带来的更高吞吐。如果没有 FlashInfer,也可以通过 --use_sdpa 回退到 PyTorch 原生注意力。可视化部分则使用 viser,默认在 http://localhost:8080 打开交互式点云查看器。换句话说,官方提供的不是只会吐出一堆张量的研究脚本,而是一个更接近**“你把图像丢进去,就能看到 3D 结果”**的演示入口,这对理解模型行为非常友好。
README 里还给出了一些非常具体的推理建议。比如长序列可以用 --keyframe_interval 让非关键帧不进入 KV cache;超长序列可以切换到 --mode windowed --window_size 128;如果室外场景里天空点过多,会影响可视化质量,可以打开 --mask_sky,系统会自动下载 skyseg.onnx 对天空区域做分割并缓存结果;如果显存紧张,可以继续使用 --offload_to_cpu 或把 --num_scale_frames 从默认值进一步减小;如果更看重速度而非极致位姿精度,可以把 --camera_num_iterations 从默认的 4 降到 1。这些都不是论文层面的抽象概念,而是你真正跑仓库时会直接用到的参数。
# 典型安装流程conda create -n lingbot-map python=3.10 -yconda activate lingbot-mappip install torch==2.9.1 torchvision==0.24.1 --index-url <https://download.pytorch.org/whl/cu128>pip install -e .pip install flashinfer-python -i <https://flashinfer.ai/whl/cu128/torch2.9/># 典型示例:文件夹图像流python demo.py --model_path /path/to/lingbot-map-long.pt \\ --image_folder example/oxford --mask_sky# 典型示例:超长视频窗口化推理python demo.py --model_path /path/to/lingbot-map-long.pt \\ --video_path video.mp4 --fps 10 \\ --mode windowed --window_size 1285. 行业意义、开源边界与局限
从媒体传播角度,LingBot-Map 很容易被概括成“便宜 RGB 摄像头对昂贵激光雷达的替代方案”。这个说法并不完全错,但如果把它理解成“从此 LiDAR 不重要了”,就会明显过度简化。更准确的说法应该是:在一些对成本、体积和部署复杂度敏感的应用里,LingBot-Map 提供了一条用视觉基础模型替代部分高成本三维感知硬件的可能路径。家用服务机器人、室内巡检机器人、低速配送、视觉导航小车、AR 眼镜等场景,过去很难把“实时 3D 感知”做得又便宜又稳定,而 LingBot-Map 让这件事开始出现更合理的工程解法。
但它的价值并不只是“省硬件”,更重要的是“让连续空间理解成为可学习的基础能力”。在具身智能栈里,单帧深度估计回答的是“这一刻每个像素离我有多远”,导航与操作真正还需要的是“我现在在三维世界的什么位置、这个世界在时间上如何延续、接下来应该怎么把动作规划嵌进这个连续空间里”。LingBot-Map 补上的恰恰是这层“实时理解三维空间”的能力。把它和 LingBot-Depth、LingBot-World、LingBot-VLA 这类模块放在一起看,就会发现蚂蚁灵波的路线不是零散开源几个模型,而是在逐步拼出从空间感知到世界模拟再到决策执行的一条完整链路。
开源边界。
这一点值得专门提醒。很多人看到 GitHub 开源后,会自然地以为已经拿到了完整复现实验的一切条件。但从公开仓库内容判断,LingBot-Map 当前更接近“高质量推理与演示实现”,而不是完全对等的训练复现平台。仓库里有 demo.py、模型包、profiling 脚本和依赖配置,却没有论文附录中那样完整的数据处理工具、29 数据集统一流水线、分布式训练代码和大规模采样器实现。换句话说,你今天可以很方便地跑通官方推理、理解其架构和参数,但如果想一比一复现实验论文中的训练过程,仍然需要大量未公开的训练基础设施。
这不是缺点,而是一种需要被准确理解的开源边界。对于使用者来说,它意味着两个结论。第一,如果你的目标是评估模型推理能力、测试自己的视频数据、接入自己的机器人感知链路,那么官方仓库已经足够有价值。第二,如果你的目标是复刻完整训练、替换部分模块并重训到论文水准,那么光靠当前公开仓库还远远不够。这种边界在很多大型视觉基础模型项目里都存在,关键不是抱怨它不完整,而是要清楚自己打算从开源里获得什么。
它还没有解决什么。
论文最后的限制与展望部分写得相当诚实。第一,LingBot-Map 目前没有显式的回环检测机制,也就是当相机长时间走出去、之后又回到旧位置时,它虽然可以依靠轨迹记忆缓解漂移,但并没有像经典 SLAM 那样明确做 loop closure。第二,轨迹记忆对每一帧只保留固定数量的紧凑 token,这当然极大提升了效率,但也意味着在极长序列、极复杂场景里,某些细粒度几何信息可能会被压缩掉。第三,它仍然是纯前向推理模型,不做 test-time optimization,因此在某些极端难例上,后验优化类方法仍可能有补救空间。
除此之外,还有一个更现实但论文没有刻意渲染的问题:LingBot-Map 对动态场景的处理仍然不是它的主战场。论文的主要评价对象依然以静态场景或近似静态场景为主,而现实世界中的人、车、宠物、可变形物体和强反射物会给单目流式重建带来额外挑战。换句话说,LingBot-Map 解决的是“长期稳定、实时、在线”的核心难题,但它并没有把“世界中一切都在动”的问题一并解决。真正面向开放现实环境的空间智能系统,未来还需要把动态建模、回环检测、多模态传感以及可能的后验校正更深入地整合进来。
我的判断。
我认为,LingBot-Map 最值得记住的,不是“它把几个指标刷到了第一”,而是它把流式 3D 重建这个长期被工程细节和算法折中反复困住的问题,重新变成了一个可以由基础模型统一处理的结构化学习问题。它没有照搬传统 SLAM,也没有盲目迷信端到端 Transformer,而是把两边真正有效的部分融合起来:SLAM 提供了关于空间记忆分层的结构洞察,Transformer 提供了端到端可学习的上下文利用方式,分页 KV cache 和 FlashInfer 则把这种结构真正推到了可运行的在线系统上。这种组合并不花哨,但非常扎实。
如果用一句更克制的话来总结,LingBot-Map 代表的不是“单目 RGB 已经完全取代其他感知方案”,而是“低成本视觉流在实时三维理解上的上限被显著抬高了”。它让人看到,机器人持续理解物理空间这件事,开始出现 foundation model 级别的解法,而不是永远停留在“传统 SLAM 加若干手工规则”的工程修修补补阶段。对于具身智能、自动驾驶和 AR 来说,这种变化的长期意义,可能比一次媒体传播中的热度更值得重视。
6. 结语
对于第一次接触这篇工作的读者,最好的理解路径不是记住一长串 benchmark 名字,而是抓住四个关键词。第一,LingBot-Map 是为“流式”而不是“离线”设计的;第二,它最核心的创新不是单个模块,而是 Anchor、Pose-reference Window 和 Trajectory Memory 这三层几何记忆;第三,官方仓库已经把这种设计落成了可运行的推理系统,关键参数和脚本都公开可见;第四,它的意义不只是更准的三维重建,而是让连续空间理解开始具备基础模型式的统一能力。把这四点连起来,LingBot-Map 的整体意思、技术核心和实现流程就基本清楚了。
参考资料
1. 论文主页:https://arxiv.org/abs/2604.14141 2. 项目主页:https://technology.robbyant.com/lingbot-map 3. GitHub 仓库:https://github.com/Robbyant/lingbot-map 4. Hugging Face 模型卡:https://huggingface.co/robbyant/lingbot-map 5. ModelScope 模型页:https://www.modelscope.cn/models/Robbyant/lingbot-map 6. GitHub 入口脚本 demo.py:https://github.com/Robbyant/lingbot-map/blob/main/demo.py7. 流式模型实现 gct_stream.py:https://github.com/Robbyant/lingbot-map/blob/main/lingbot_map/models/gct_stream.py8. 长序列窗口实现 gct_stream_window.py:https://github.com/Robbyant/lingbot-map/blob/main/lingbot_map/models/gct_stream_window.py9. 流式聚合器 aggregator/stream.py:https://github.com/Robbyant/lingbot-map/blob/main/lingbot_map/aggregator/stream.py10. 基础模型骨架 gct_base.py:https://github.com/Robbyant/lingbot-map/blob/main/lingbot_map/models/gct_base.py11. 相机头实现 camera_head.py:https://github.com/Robbyant/lingbot-map/blob/main/lingbot_map/heads/camera_head.py12. 深度头实现 dpt_head.py:https://github.com/Robbyant/lingbot-map/blob/main/lingbot_map/heads/dpt_head.py
更多ROS、具身智能相关内容,请关注古月居
👉 关注我们,发现更多有深度的自动驾驶/具身智能/GitHub 内容!
🚀 往期内容回顾 👀
🔥 十分钟读论文 | WildOS:让机器人在野外环境中自主寻找目标🔥 Jetson Thor开发指南 | 基于ROS2的OriginMan人形机器人智能控制系统设计与实现🔥 十分钟实用教程 | RK3588 与 Jetson Orin 交叉编译 Docker 工程化实践:从工具链、Sysroot 到可复现构建
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 被严重低估的豪华运动轿车!凯迪拉克CT5凭什么敢硬刚BBA?
- 6款方盒子SUV排队上市,硬派越野还是城市潮玩,总有一款让你上头
- 魏建军这招太狠了!高山7 SUV版正式登场,限时到手27.08万,MPV改跨赛道,30万家用车直接乱卷
- 自动驾驶安全新突破:故障可运行架构与自动化依赖性分析
- 奇瑞瑞虎8系列卖到八九万起,家用SUV先别只盯着动力猛
- 鸿蒙智行:首款科技豪华硬派 SUV 享界 G9 官宣!
- 灼识咨询:自动驾驶行业蓝皮书——城市NOA自动驾驶商业化的转折点 2026
- 岚图泰山这气场,谁还敢说国产SUV没排面?
- 保值的燃油轿车推荐,选车不纠结!
- 华为全新豪华硬派 SUV 享界 G9 来袭,三季度正式发布
