从模块化到端到端,从VLA到世界模型,自动驾驶的技术路线之争从未如此激烈。上海交大团队最新综述,用“广义端到端”一统江湖。
汽车在自动驾驶的过程当中,它的工作流程或许是:像传统流水线那样分步作业?像人类一样端到端地学习驾驶?或是先理解场景再做出决策?
这不仅是技术之争,更是一场关乎未来话语权的暗战。
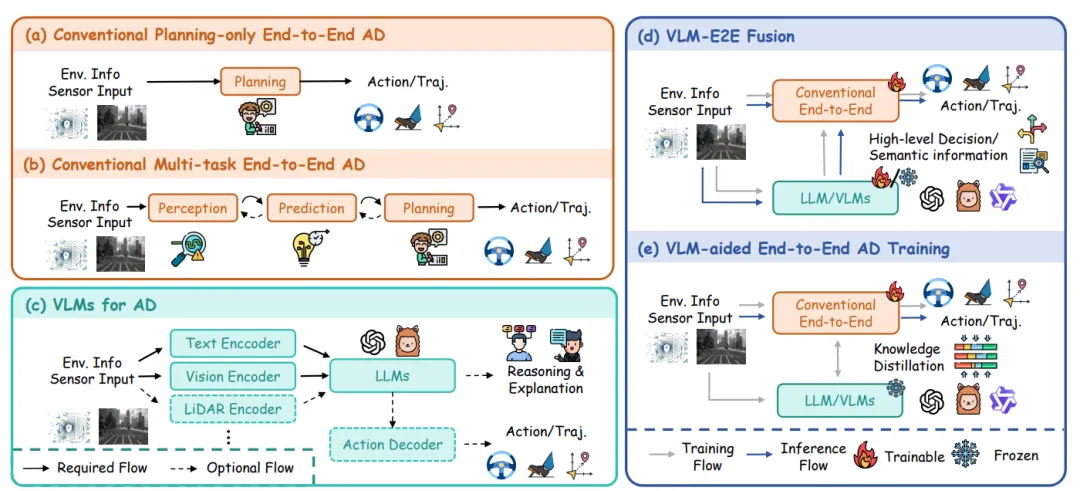
传统模块化方案将驾驶拆解为感知、预测、规划、控制四个独立模块。每个模块各司其职,像流水线上的工人——一个识别障碍物,一个预测轨迹,一个规划路线,最后一个负责踩油门打方向盘。
很大的问题:信息在传递中不断丢失,误差在接力中持续累积。
就好比传话游戏,第一个人说“前方有障碍物”,传到第四个人那里可能变成了“前方有冰淇淋”——结果车子一个急刹,后面的司机一脸懵。
更要命的是,各模块优化目标不一致,遇到复杂场景就容易“各说各话”。这就像一支乐队各弹各的调,听起来就是灾难。
因此,行业掀起了一场从模块化到端到端的范式革命。
就在各路玩家吵得不可开交时,上海交通大学AutoLab团队联合滴滴,翻阅了200多篇论文,扔出了一枚重磅炸弹。
他们提出了一个石破天惊的概念—— “广义端到端”(General End-to-End, GE2E)。
GE2E的定义简单粗暴:任何能通过整体模型将原始传感器输入直接转化为规划轨迹或控制动作的模式,都算端到端——不管你里面有没有大模型。
这相当于说:甭管你是用筷子吃饭还是用刀叉,只要能把饭送进嘴里,都叫“吃饭”。
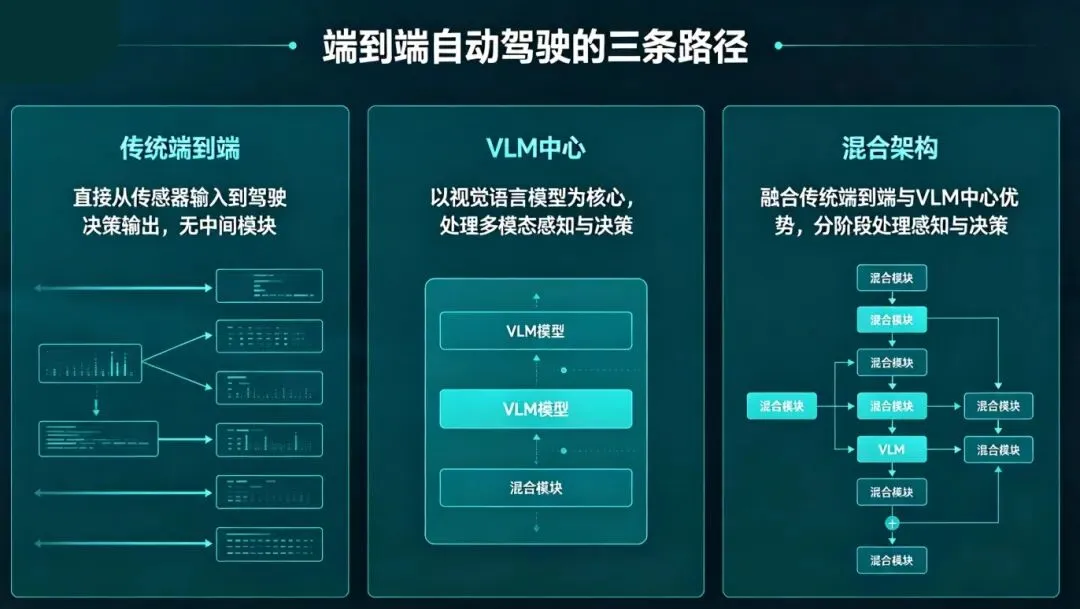
基于这一定义,论文将看似散乱的技术路径归纳为三大主流范式。
流派一:传统端到端——稳扎稳打的实干派
传统端到端是最早探索端到端路线的“老大哥”。它基于3D场景表征(比如BEV鸟瞰图或Occupancy占用网格),用结构化的方式理解物理世界。
内部又分为两派:
优势:统一训练目标能有效减少模块间的信息丢失和误差累积;系统集成度高,执行效率快。
短板:依然是“黑箱”操作,出了问题很难追溯原因;训练成本高,需要海量数据和算力。
代表玩家:特斯拉FSD V12。
流派二:VLM为中心的端到端——先看懂再开车的学霸
VLM,全称Vision-Language-Action(视觉-语言-动作)。
它不直接控制车辆,而是先把路况转化为“语义信息”——比如把看到的车道、障碍物、红绿灯全部翻译成文本描述+视觉关联,然后再让动作生成器综合这些信息做出决策。
通俗地说:传统端到端是“凭感觉开车”,VLM是“看清楚再开车”。
优势:
更容易理解和调试,出错能定位问题出在哪
可以和现有感知系统搭配,不需要推倒重建
安全性更好,容易通过工程验证
短板:
代表玩家:小鹏、理想。
流派三:混合端到端——取长补短的整合大师
混合端到端试图融合前两者的优势——既保留传统端到端在规控精度上的“快思考”,又吸纳VLM在常识理解上的“慢思考”。
如果说传统端到端是“直觉”,VLM是“理性”,那混合端到端就是既靠直觉又靠理性的“老司机” 。
目前还在探索中,但被认为是通往通用自动驾驶最有希望的方向。
麦肯锡的未来移动中心做了一项调查,结果出人意料:绝大多数专家预测,未来的主流将是 “混合架构” ——同时采用端到端AI模型处理复杂场景,并结合传统算法来验证安全边界。
换句话说,没有哪个单一方案能通吃全局。
就像人类开车,既靠直觉(经验)也靠理性(交规),未来的自动驾驶大概率也是“混搭风”。
端到端赋予了算法更强的场景适应力与长尾应对能力,使得城市NOA、高速NOA等复杂功能加速量产上车。这不仅是技术的迭代,更是产业从试验走向规模化商用的临界点。
但端到端并非万能。目前行业中仅22%的专家认为端到端会成为绝对主流。可解释性差、算力要求高、极端场景处理能力不足,都是亟待攻克的难题。
从模块化到端到端,从VLA到世界模型,技术路线看似纷繁复杂,但剥开层层术语外壳,底层逻辑始终如一:实现“传感器信息输入,驾驶动作输出”的纯数据驱动范式。
上海交大的这篇综述最大的贡献,不是告诉你哪条路是对的,而是告诉你:这些路最终通向同一个目的地。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
