揭示大语言模型与人类在自动驾驶重型货车接管决策中的分歧
- 2026-06-23 16:39:03

小编导读
L3级自动驾驶在商用重型货车(HGV)领域的落地,始终绕不开一个核心难题:当系统发出接管请求时,人类司机究竟该不该接?怎么接?接了反而更安全吗?中南大学、交通运输部公路科学研究院及澳大利亚皇家墨尔本理工大学联合团队近期在交通安全顶刊 *Accident Analysis & Prevention* 发表研究,在国际上首次系统比较了大语言模型(LLM)智能体与真实卡车司机在自动驾驶货车接管决策中的行为差异。研究发现:LLM控制的重型货车事故率仅为人类驾驶员的 1/4,而经验最丰富的老司机反而是最不守规矩、风险最高的一群人。

基本信息
标题:Revealing the divergences between LLM-simulated and human takeover decision-making in ADS-equipped HGV operations「揭示大语言模型与人类在自动驾驶重型货车接管决策中的分歧」作者:Xu Zheng, Xi Yinfei, Hua Jun, Cen Xuekai, Zheng Nan机构:中南大学交通运输工程学院;交通运输部公路科学研究院智能交通技术国家重点实验室;澳大利亚皇家墨尔本理工大学土木与环境工程系期刊:Accident Analysis & Prevention(2026)链接:10.1016/j.aap.2026.108594
研究亮点
LLM事故率仅为人类1/4:在108个测试场景中,人类驾驶员事故率高达12.0%(13次碰撞),而GPT、Opus、Gemini控制的LLM智能体事故率仅为2.8%–4.6%,最高不超过人类的40%。 老司机最不信任自动驾驶:驾龄6–20年的职业司机对ADS系统的服从率不足50%,频繁提前抢夺方向盘;而驾龄不足5年的新手反而服从率更高,表明经验积累形成了强烈的「经验依赖型风险直觉」,导致信任失调。 人类「本能踩油门」是最大危险源:LLM智能体100%采用减速+转向应对危险,而人类在紧急情况下会本能地猛踩油门「逃跑」。这种加速干预策略在仿真中被证实是引发碰撞的重要原因之一。 30×30 km²真实交通仿真验证:研究在CARLA平台构建了包含30×30 km²真实路网的高保真仿真环境,覆盖高速汇入、高速巡航、城市驾驶三类场景,共测试18名职业驾驶员和108个LLM决策场景,数据规模国际领先。
论文摘要
全球L3级自动驾驶系统(ADS)在商用重型货车(HGV)上的推广仍然有限,对可靠性和安全性的担忧造成了信任失调,并强化了基于驾驶经验的风险启发式判断。本研究考察了自动驾驶HGV运营中的人机交互问题,并探讨大语言模型(LLM)能否生成与人类行为相似的接管决策。人在环路实验在配备大规模路网环境(30×30 km²)和真实背景交通流动态的CARLA仿真平台中开展,系统检验了人类在ADS运营过程中的接管行为,分析维度涵盖合规率、决策延迟、干预策略及碰撞结果,场景覆盖高速公路汇入、高速公路巡航和城市驾驶。同一场景随后呈现给配备LLM智能体的HGV,智能体以可扩展的「卡车司机」替代品角色进行提示与情境化配置,其表现与人类进行对比。结果显示:(i)事故率从人类参与者的12.0%大幅下降至LLM智能体控制ADS的2.8%–4.6%;(ii)LLM智能体在安全响应中仅依赖减速和转向,而人类参与者还频繁使用加速作为首选干预策略;(iii)驾龄6–20年的参与者干预更为超前,ADS运营服从率低于50%。这些发现表明,人类接管决策受经验依赖型风险启发式影响,驾驶员间存在显著异质性;当前LLM尚不能作为自动驾驶期间人类监督行为的可靠替代。
1. 研究动机
重型货车承担着全球大量的货运任务,但其事故造成的人员伤亡往往远超普通乘用车。将L3级自动驾驶系统(ADS)引入商用HGV,被视为提升货运安全性的重要路径——然而,L3级系统的核心挑战恰恰在于「人机共驾」这一灰色地带:系统在条件允许时自动驾驶,但在超出能力边界时须请求人类接管。
这一接管机制面临的现实困境是:
信任失调:职业司机积累了数年乃至数十年的驾驶经验,往往对自动驾驶系统抱有天然怀疑,导致「过度干预」。 接管行为难以标准化:不同经验水平、不同性格的驾驶员,面对同一危险情境的接管时机和方式差异极大。 评估成本极高:在真实货车上测试接管行为既昂贵又危险,传统方法难以系统性地覆盖多种场景。
与此同时,大语言模型(LLM)近年来在推理、规划和情景理解方面表现出色,理论上具备成为「虚拟卡车司机」的潜力——但它们的决策模式是否真的接近人类?是否比人类更安全?在自动驾驶货车的接管场景中,这些问题至今缺乏系统性的实证研究。
2. 研究方法
研究构建了一套完整的「人在环路 vs. LLM在环路」对比实验框架,在国际上首次将真实职业驾驶员与多款主流LLM置于完全相同的自动驾驶货车接管场景中进行对比评估。
高保真仿真环境构建
实验在开源自动驾驶仿真平台 CARLA 上运行,构建了覆盖 30×30 km² 的大规模真实路网,并植入动态背景交通流,真实还原高速公路、城市道路的复杂交通环境。测试场景分为三类:高速公路汇入(Freeway Merging)、高速公路巡航(Freeway Navigating)和城市驾驶(Urban Driving),每类场景下均包含中低两种交通密度条件。
ADS基线系统标定
研究首先开发并标定了一套 L3级ADS基线系统,集成了对象检测(ODD感知)、语义分割、运动规划等模块,并经过50×10³次迭代的系统性参数调优,确保车辆在各场景中满足对象检测精度、距离估算精度、速度调节能力和车道保持能力的运营要求。
LLM智能体设计(Chain-of-Thought推理框架)
每个LLM智能体被赋予「自动驾驶卡车决策者」的角色提示词,配备关于HGV操作规范、交通法规和驾驶原则的知识库。智能体通过 思维链(Chain-of-Thought)五步推理框架 进行决策:场景分析→未来行为预测→操控选项评估→决策理由说明→动作指令输出。实验共测试了三款主流LLM:GPT(OpenAI)、Opus(Anthropic)和 Gemini(Google)。
人在环路实验
共招募 18名参与者(9名职业卡车司机、9名乘用车驾驶员),驾龄从不足1年到20年以上不等。参与者通过 NVIDIA RTX 5090 驱动的三屏环绕显示系统和 Logitech G923 方向盘踏板进行驾驶,系统完整记录合规率、决策延迟、干预策略(减速/转向/加速)及最终碰撞结果。
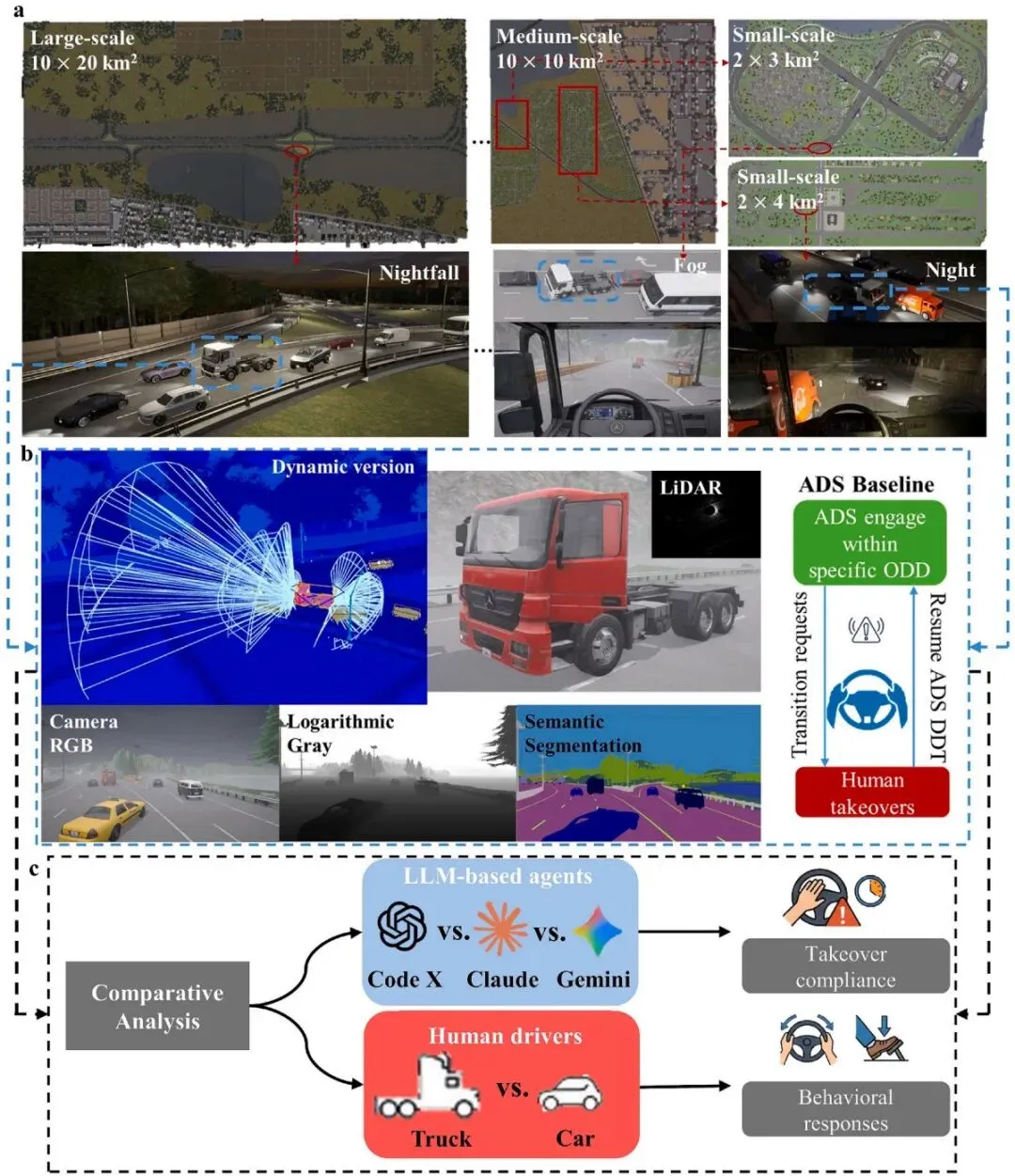
图1 | 研究框架总览:CARLA仿真平台配置、L3级ADS基线系统搭建与LLM智能体对比分析流程

图2 | LLM决策智能体的通用开发工作流,涵盖知识库构建、情境感知输入与思维链五步推理框架
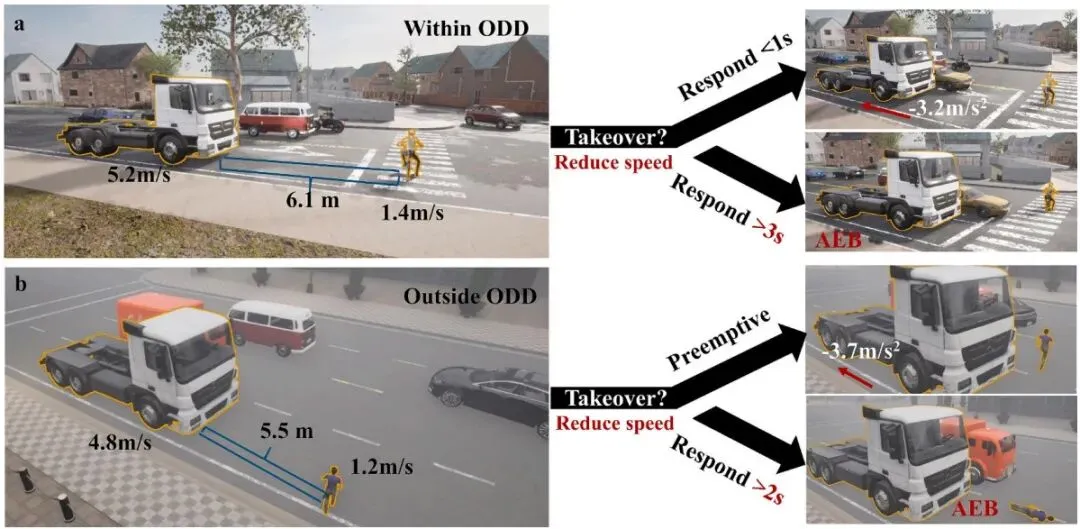
图3 | 实验中两类不同交通密度的运营条件示意,以及ADS系统接管过渡期间的行为模式图解
3. 核心结论
实验在108个测试场景(3类场景×2种交通密度×18名参与者)中采集了全量数据,同等场景下完成三款LLM智能体共计108次决策记录,主要结论如下。
LLM全面碾压人类安全纪录。 人类驾驶员在所有场景中共发生 13次碰撞(事故率12.0%),而GPT、Opus、Gemini分别产生5次(4.6%)、3次(2.8%)和4次(3.7%)碰撞。最优LLM(Opus)的事故率仅为人类的 1/4,差距悬殊。
城市驾驶是人类最脆弱的场景。 13次人类碰撞中,城市驾驶场景事故最集中,原因在于城市环境的高度动态性(行人、横向切入车辆、信号灯)超出了驾驶员依赖经验判断的能力边界;而LLM在三类场景中的事故率相对均衡,展现出更强的泛化能力。
「加速逃跑」是人类独有的危险本能。 LLM智能体的干预策略 100%为减速或转向;而人类参与者在部分危急场景下会本能踩油门试图加速规避,这一策略在多次事故回放中被确认为碰撞的直接诱因。
老司机最危险:经验越丰富越不服从。 驾龄 6–20年 的参与者ADS服从率不足50%,且倾向于在系统判断安全的时间窗口内过早接管,干预时机偏早、干预动作激进。相比之下,新手驾驶员(驾龄<5年)的服从率更高,碰撞率反而更低,印证了「经验悖论」——在人机协同场景中,强烈的经验自信可能适得其反。
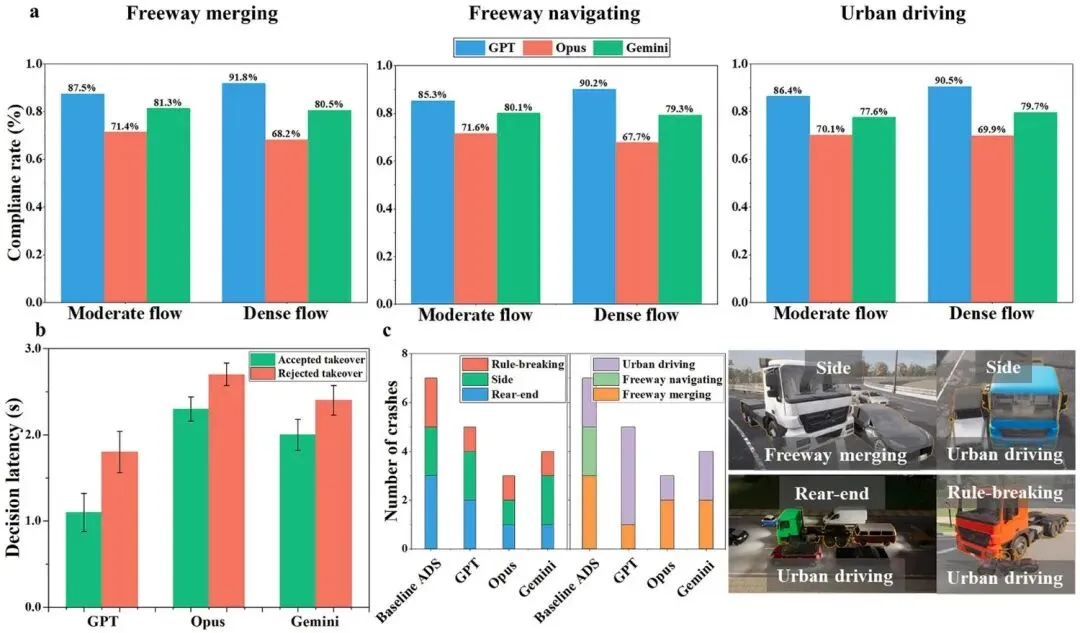
图4 | LLM决策表现与安全结果:三类场景下GPT、Opus、Gemini的接管合规率、决策延迟分布及碰撞事件统计
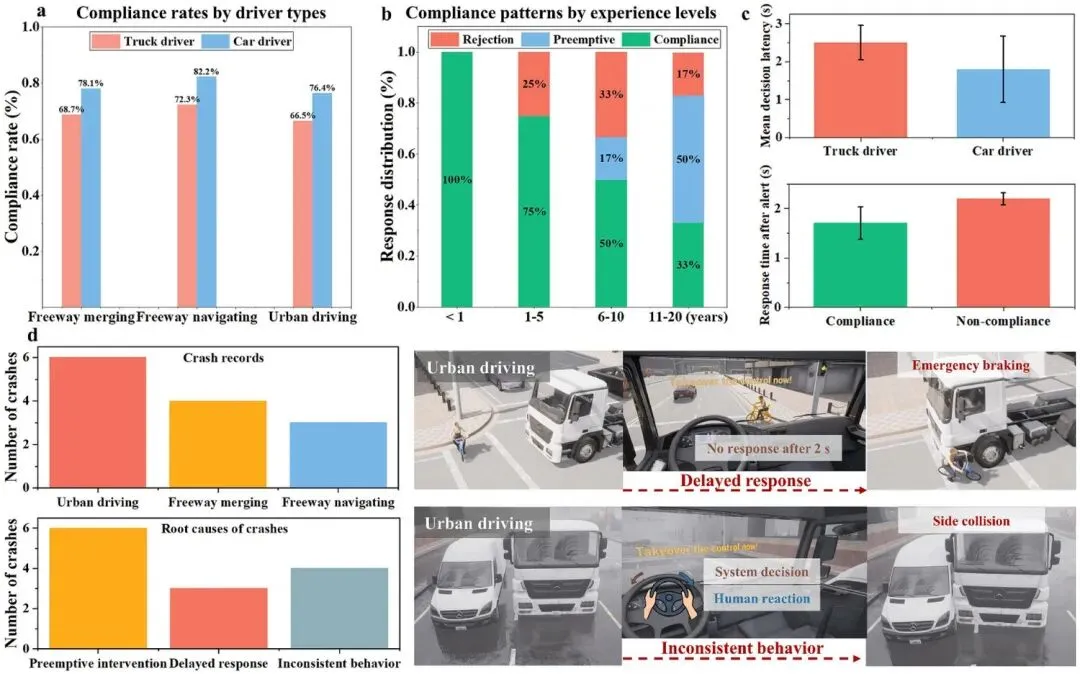
图5 | 人在环路实验结果:按驾驶员类型/经验水平分层的ADS合规率、碰撞空间分布地图及典型事故案例回放
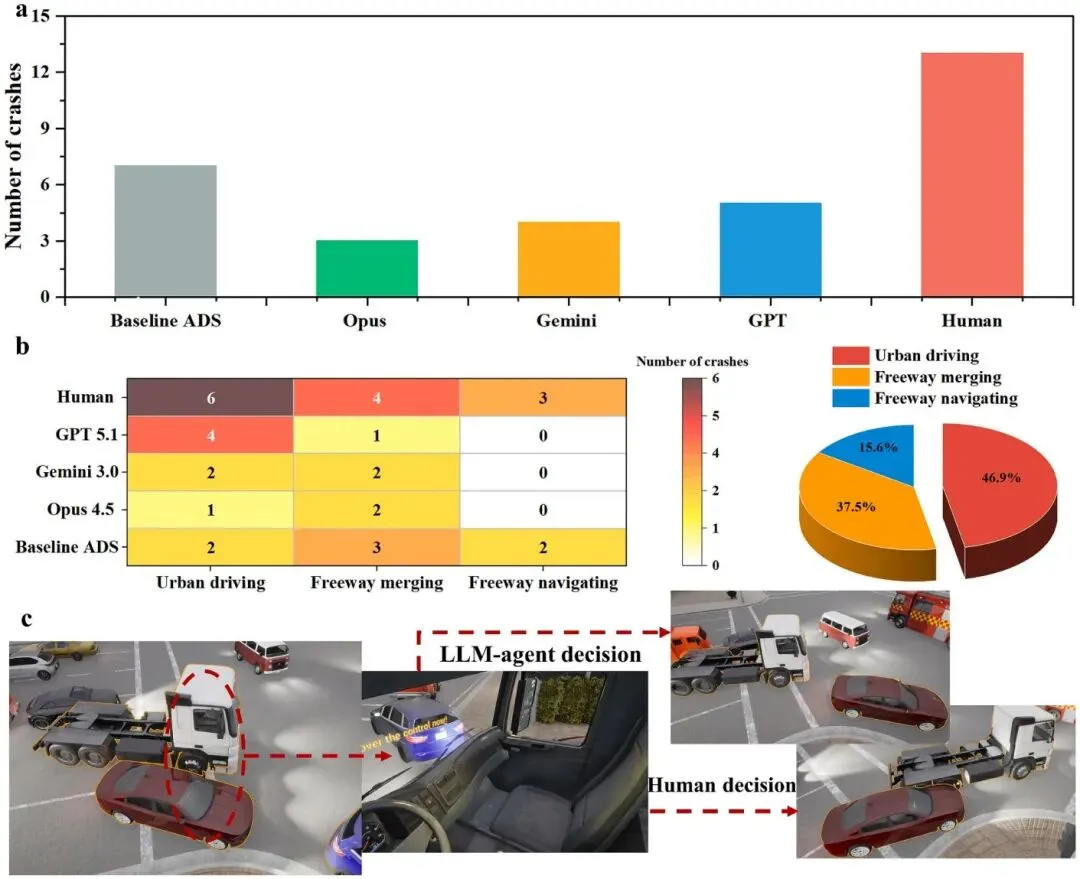
图6 | LLM与人类驾驶员跨场景决策策略全面对比:减速/转向/加速干预比例及其对应的安全结果关联分析
4. 研究展望
研究的局限性同样值得正视。首先,实验在仿真环境中完成,真实货车上的振动、噪音、疲劳等生理因素尚未纳入;其次,本研究仅评估了接管决策行为,未能深入量化不同接管策略对整体交通流的系统性影响。
尽管如此,这一研究的意义远不止于数据对比。它揭示了三个对行业影响深远的结论:第一,当前LLM尚不能替代人类对L3级ADS的监督职责,其决策模式与真实人类存在本质差异;第二,职业司机的ADS培训体系亟待重构——不能简单灌输「信任系统」,而需要针对不同经验群体设计差异化的接管行为规范;第三,LLM辅助安全评估是有前途的研究方向,但必须明确其边界:作为压力测试工具可行,作为人类行为代理则尚需谨慎。
< Fin >
交通顶刊Transport Policy 2026年7月刊 交通安全论文导读

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2026年这两款SUV,速度与激情全都有!能飙也能野,奶爸们别错过
- 宾利添越:从全网群嘲到超豪华SUV开山鼻祖,它凭什么翻身?
- 男子驾车追尾小轿车,致前车冲破护栏驶入对向车道……警方通报→
- 小米首款增程式 SUV 惊艳曝光,车顶很赞!
- 豪华SUV那么多,凭什么宝马X5称得上公路之王?
- 月销15000台,50万买国产SUV?问界M9到底值不值你一分钱?
- 2026年男人喜欢的三款美系性能SUV!不仅快还够大,奶爸实测告诉你值不值
- 【好消息!】海洋旗舰轿车海豹08 展车已到店 欢迎进店品鉴
- 问界 M9:五十万级纯电SUV很强,但先别急着把生活交出去
- 试驾完这台电动轿车,我说句良心话:这才是普通家庭该有的样子
