Nature 正刊|自动驾驶安全验证别再傻跑里程了!D2RL 让危险场景测试加速 10³–10⁵ 倍
- 2026-06-24 12:32:55
🔥Nature 正刊|自动驾驶安全验证别再傻跑里程了!D2RL 让危险场景测试加速 10³–10⁵ 倍
文章介绍
今天解读的是一篇 Nature 正刊文章:

Dense reinforcement learning for safety validation of autonomous vehicles
这篇文章的方向是 自动驾驶安全验证,属于车辆工程、交通工程和人工智能交叉领域。
它讨论的不是“怎么让自动驾驶车开得更智能”,而是一个更底层、更现实的问题:
“自动驾驶到底要怎么证明自己足够安全?
过去谈自动驾驶安全,最常见的思路是:
让车上路跑。 跑更多里程。 积累更多测试数据。 看它会不会出事故。
但这个思路有一个致命问题:
“真正危险的场景太少了。
绝大多数道路测试都是普通驾驶场景。正常跟车、正常变道、正常巡航,占据了车辆测试的大部分时间。真正可能导致事故的极端场景、边界场景、corner case,本来就是低频事件。
所以,如果只靠自然道路测试来验证自动驾驶安全,成本会高到夸张,时间会长到离谱。
这篇 Nature 的核心就是解决这个问题:
“不要被动等待危险发生,而是让 AI 主动制造高价值危险场景。
一句话概括:
“自动驾驶安全验证,不应该只是“跑够里程”,而应该更快、更密集地遇到真正有测试价值的危险场景。
1. 自动驾驶安全验证为什么这么难?
自动驾驶的安全验证,有一个非常经典的矛盾。
如果只看普通道路测试,自动驾驶车可能跑了很多公里,但绝大多数里程都很普通。
前车正常行驶。 旁车正常变道。 行人正常过街。 交通流正常变化。
这些场景当然也要测试,但它们对安全验证的价值有限。
真正有价值的是那些稀有场景:
前车突然急刹。 旁车突然切入。 目标车辆被迫极限避让。 多车交互导致冲突。 自动驾驶系统处在即将碰撞的边界状态。
但这些场景在自然交通中出现概率极低。
这就导致一个问题:
“你跑了很多里程,但真正测试到系统极限的次数可能很少。
这也是自动驾驶行业长期头疼的问题。
安全验证不是简单堆里程。 因为里程多,不代表危险场景多。 危险场景少,就很难真正暴露系统缺陷。
所以,自动驾驶安全测试真正需要的不是“更多普通场景”,而是:
“更多高价值、安全关键场景。
2. 这篇文章的核心思路:让背景车辆学会“找麻烦”
这篇 Nature 的方法很有意思。
它不是直接训练自动驾驶车,而是训练测试环境里的 背景车辆智能体。
所谓背景车辆,就是自动驾驶测试车周围的其他交通参与者。
传统仿真测试中,背景车辆通常按照自然驾驶分布行动。它们大部分时候都很正常,因此很难频繁触发危险场景。
而这篇文章的思路是:
“让背景车辆变聪明,主动生成更容易暴露自动驾驶风险的场景。
换句话说,测试环境不再是被动复现自然交通,而是主动构造安全关键事件。
比如,背景车辆可以学习什么时候变道、什么时候减速、什么时候制造交互冲突,才能更有效地测试自动驾驶系统的反应能力。
这就像考试不再只出简单题,而是专门挑能区分能力上限的难题。
自动驾驶安全验证也是如此。
真正有价值的测试,不是让车辆重复跑一万次普通跟车,而是让它更高频地遇到关键风险场景。
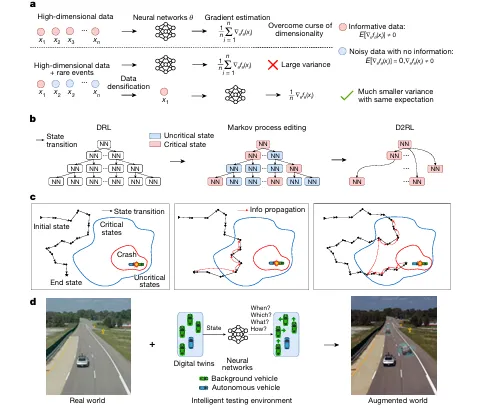
3. D2RL 是什么?把稀有危险事件“变密”
文章提出的方法叫 Dense Deep Reinforcement Learning,简称 D2RL。
这个名字里的关键词是 Dense,也就是“稠密”。
为什么要稠密?
因为安全关键事件太稀有了。
普通强化学习在这种问题上很难训练,因为奖励太稀疏。智能体跑很久,也不一定遇到一次真正有价值的危险事件。没有足够反馈,模型就学不出有效策略。
这篇文章的做法是:
“把马尔可夫决策过程重新编辑,删除大量非安全关键状态,再把关键状态重新连接起来。
通俗理解就是:
原来的数据里,大部分都是普通驾驶片段。 这些片段对安全验证帮助不大,却占用了大量训练空间。
于是作者把大量“不关键”的状态删掉,把真正接近危险事件的状态重新串联起来,让训练数据中的安全关键信息变得更密集。
这就是 D2RL 的核心:
“不是盲目增加数据,而是提高数据里危险信息的浓度。
这一步非常关键。
因为自动驾驶安全验证最缺的不是普通驾驶数据,而是高质量的安全关键数据。
4. 为什么普通 DRL 不够用?
普通深度强化学习在很多任务上表现很好,但在自动驾驶安全验证里会遇到一个问题:
“安全关键事件太少,智能体学不到重点。
如果让普通 DRL 去自然交通环境里训练,它可能花大量时间学习普通驾驶模式,却很难学会如何高效触发危险场景。
这就像让一个学生在一堆简单题里找难题,找半天也不一定遇到一道真正能训练能力的题。
D2RL 的优势就在于,它改变了训练数据结构。
它让智能体更频繁地接触到关键状态,让学习过程更集中、更高效。
所以这篇文章真正厉害的地方不是简单用了强化学习,而是:
“它让强化学习从低频危险事件中学到了高价值测试策略。
这对自动驾驶安全验证非常重要。
因为测试的目标不是还原所有普通交通,而是高效发现系统风险。
5. 方法框架:自然驾驶数据 + AI 背景车 + 增强现实测试
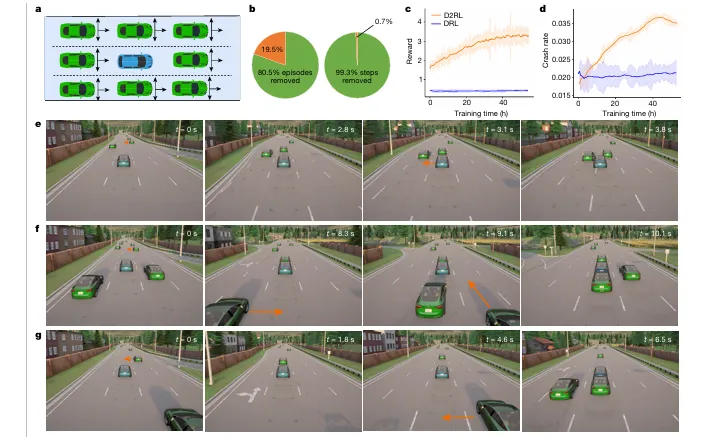
这篇文章的框架可以分成三步。
第一步,从自然驾驶数据中学习交通参与者行为。
作者并不是凭空设计危险场景,而是从真实自然驾驶数据出发,让背景车辆智能体学习真实交通行为基础。
第二步,通过 D2RL 训练背景车辆智能体。
背景智能体不是随便乱撞,而是学习如何在不破坏统计合理性的前提下,更高效地触发安全关键事件。
第三步,在增强现实测试环境中验证真实自动驾驶车辆。
这点非常重要。
文章不是只在纯仿真里做实验,而是在高速和城市测试场中,结合了:
真实道路基础设施; 真实自动驾驶测试车; 仿真的背景车辆; 增强现实环境。
也就是说,真实测试车在真实场地里运行,但周围的交通交互可以通过增强现实方式构造出来。
这就兼顾了两点:
“真实车辆闭环测试的可信度。仿真场景生成的灵活性和安全性。
这比单纯仿真更接近工程验证,也比完全道路实测更可控。
6. 结果最炸裂:安全验证加速 10³–10⁵ 倍
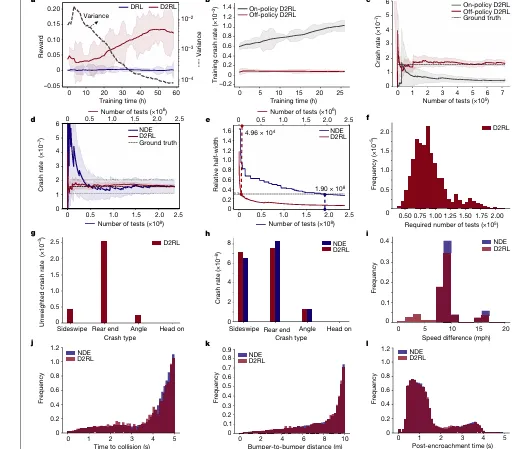
结果,就是:
“D2RL 可以让自动驾驶安全评估加速 10³ 到 10⁵ 倍。
这是什么概念?
如果原本需要非常长时间才能自然遇到一次危险场景,那么 D2RL 可以通过智能背景车辆大幅提高安全关键事件出现频率。
这不是简单“仿真跑得更快”,而是:
“单位测试时间内,危险场景密度更高。
也就是说,测试不再是等风险自然发生,而是主动把风险场景推到自动驾驶系统面前。
这对自动驾驶行业非常关键。
因为自动驾驶系统要真正部署,不能只说“我们跑了很多公里”。更重要的是:
“这些测试里,有多少真正触碰到了系统边界? 有多少暴露了潜在安全风险? 有多少覆盖了罕见但危险的 corner case?
D2RL 的价值就在这里。
它让安全验证从“靠运气遇到危险”,变成“主动生成危险”。
7. 这篇文章为什么是车辆工程问题,而不只是 AI 问题?
表面上看,这篇文章用了强化学习,容易被理解成 AI 论文。
但它本质上是一个非常典型的车辆工程问题:
“如何高效、可信、可控地验证自动驾驶系统安全性?
自动驾驶车辆不是一个普通 AI 模型。
它是安全关键系统。 它会在真实道路上和人、车、交通环境交互。 它的错误不是识别错一个标签,而可能导致事故。
所以它的验证标准必须非常严格。
这篇文章的工程意义在于:
它提出了一种新的测试环境构造方法。 它提升了安全关键事件出现频率。 它减少了自然道路测试的时间和成本。 它还把仿真背景车辆、真实测试场和真实自动驾驶车结合起来。
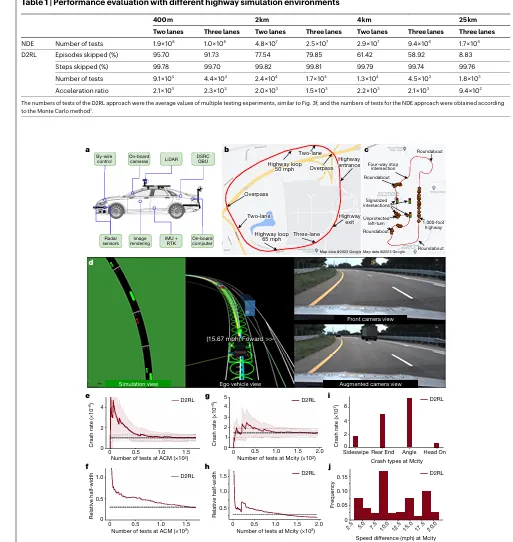
这就是车辆工程的核心问题:
“不是只让算法看起来聪明,而是让系统在真实测试流程中更可信。
8. 为什么“跑够里程”不是最终答案?
自动驾驶行业曾经很喜欢讲测试里程。
某某公司测试多少万公里。 某某系统累计多少亿公里。 某某车队完成多少道路测试。
但这篇文章提醒我们:
“测试里程不是安全性的充分证明。
因为 100 万公里普通场景,可能不如 1 万公里高密度安全关键场景有价值。
安全验证真正关心的是系统在危险边界处的表现。
比如:
当旁车突然切入时,系统能不能正确减速? 当前车急刹时,系统能不能保持安全距离? 当多个交通参与者同时产生冲突时,系统能不能做出合理决策? 当场景接近碰撞临界点时,系统是否仍然稳定?
这些问题,普通里程很难高效回答。
所以这篇文章的意义是:
“自动驾驶测试不能只卷里程,更要卷测试场景的危险密度和信息价值。
这句话非常适合做公众号爆点。
9. 这篇文章和传统场景库测试有什么不同?
传统自动驾驶测试也会构建场景库。
比如变道场景、跟车场景、交叉口场景、行人横穿场景等。
但场景库方法有一个问题:
“场景怎么选?参数怎么调?危险程度怎么控制?
如果人工设计场景,很容易依赖经验,也很难覆盖复杂交互。
这篇文章的思路更智能:
“让 AI 背景车辆自己学习怎样生成高价值测试场景。
这不是简单列一个场景清单,而是让测试环境具备主动搜索能力。
背景车辆可以根据自动驾驶系统的反应,动态生成更具挑战性的交互行为。
所以它不是静态场景库,而是智能测试环境。
这也是 D2RL 的重要价值:
“不是人工挑危险场景,而是让测试环境自己学会制造危险场景。
10. 对自动驾驶研发的启示
这篇 Nature 给自动驾驶研发带来的启示非常直接。
第一,安全验证不能只靠自然道路测试。
自然道路测试当然必要,但它太低效。未来必须结合仿真、增强现实和智能场景生成。
第二,测试场景的质量比里程数量更重要。
如果测试数据里没有足够安全关键事件,里程再多也很难说明系统边界表现。
第三,背景交通参与者建模很关键。
自动驾驶系统不是在真空中运行,它面对的是其他车辆、行人和复杂交通环境。因此,如何构造逼真的背景交通行为,是安全验证的核心。
第四,AI 不仅可以用于驾驶,也可以用于测试。
过去 AI 更多用于自动驾驶感知、规划、控制。这篇文章说明,AI 也可以用来做“考官”,专门测试自动驾驶系统。
第五,增强现实测试可能成为自动驾驶验证的重要路线。
纯仿真可控但真实性不足,真实道路测试真实但风险和成本高。增强现实测试正好在两者之间找到平衡。
11. 可以延展的科研 idea
Idea 1:面向中国复杂交通场景的 D2RL 测试环境
可以基于中国城市道路数据,构建更符合本土交通习惯的安全关键场景生成系统,例如电动车穿插、外卖骑手横穿、非机动车混行、复杂路口博弈等。
Idea 2:大模型辅助自动驾驶场景生成
可以用大模型从交通事故报告、交警案例、道路监控文本描述中抽取危险场景,再结合 D2RL 生成可仿真的高风险测试用例。
Idea 3:D2RL + 数字孪生测试场
将 D2RL 生成的安全关键场景接入城市级数字孪生交通环境,用于测试自动驾驶系统在区域交通网络中的安全表现。
Idea 4:面向 V2X 的协同安全验证
未来自动驾驶不只是单车智能,还会接入车路协同。可以用 D2RL 生成车车、车路、车人交互中的危险场景,验证 V2X 系统的协同安全性。
Idea 5:多模态危险场景生成
除了车辆运动轨迹,还可以加入天气、光照、遮挡、传感器噪声、道路施工等多模态因素,让安全验证更接近真实复杂环境。
Idea 6:自动驾驶算法的“红队测试”
可以把 D2RL 看成自动驾驶系统的红队,让 AI 专门寻找自动驾驶策略漏洞,形成自动化安全攻防测试框架。
一句话总结
这篇 Nature 正刊文章真正厉害的地方,不是简单用了强化学习,而是重新定义了自动驾驶安全测试的思路。
它告诉我们:
“自动驾驶安全验证不能只靠跑里程,更要让系统高频遇到真正危险的关键场景。
D2RL 的核心价值是把稀有危险事件变得更“密集”,让 AI 背景车辆主动制造高价值测试场景,从而把自动驾驶安全评估加速 10³–10⁵ 倍。
传统测试像是在路上等危险发生。 这篇文章的方法像是让 AI 专门把危险场景送到自动驾驶车面前。
这才是自动驾驶安全验证真正需要的下一步:
“不是跑得更多,而是测得更准。
#Nature正刊 #自动驾驶 #安全验证 #强化学习 #D2RL #智能测试环境 #车辆工程 #增强现实测试 #无人驾驶 #科研干货
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2026年性价比最高的5款家用SUV,奶爸实测告诉你哪款最“接地气”!
- 老王谈腾势N9:这台6座大块头SUV,奶爸用车真香!
- 专业轿车维修保养,底盘维修
- Momenta过聆讯:自动驾驶里的中国AI在长大
- 又一大批六座SUV即将上市,但这几款热门SUV却在偷偷降价!六月末买车千万别着急下手
- 25万买中型SUV,丰田汉兰达值不值得入手?老刘来详细掰扯掰扯
- 全球首试!小米 YU7 GT 自动驾驶跑浙赛,到底有多强?
- L4自动驾驶强标(报批稿)征求意见,必须能够按照交警现场指挥通行.
- 奥迪Q7:豪华SUV老大哥依旧硬核,但年轻人却不买账?
- 15万级SUV如何选?老司机聊聊瑞虎9到底值不值!
