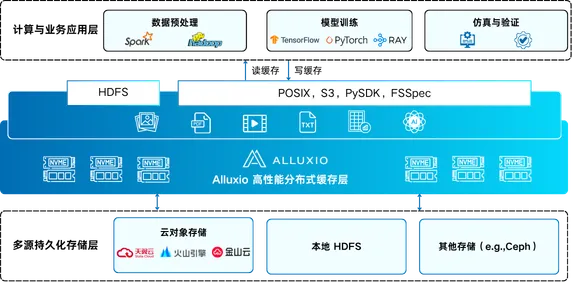
在 L4 重卡自动驾驶量产前夜,数据规模决定算法迭代速度,数据吞吐定义研发竞争力。一辆自动驾驶重卡日均产生 TB 级传感器数据,PB 级数据湖成为标配,多云混合架构成为行业常态。但算力持续增长,数据却在 “爬行”—— 如何解决对象存储 I/O 瓶颈、统一多云数据管理、最大化释放 GPU 算力价值,是业内智驾企业在规模化运营阶段普遍需要面对的技术课题。
全球领先商用车自动驾驶企业智加科技,通过引入 Alluxio 分布式数据编排层,构建多云统一缓存架构,将云端训练数据吞吐从 700MiB/s 峰值提升至 8GB/s,实现 10 倍 + 性能飞跃;在 mmdet 目标检测、点云训练等真实场景中,训练性能完全对齐本地 NVMe,GPU 利用率突破 99.57%,为 L4 重卡大规模量产筑牢数据底座。
智驾行业共性痛点:
PB 级数据下,多云训练的三重困境
随着端到端大模型成为智驾主流路线,自动驾驶研发进入数据密集型时代:重卡激光雷达、摄像头、毫米波雷达等传感器,每秒产生海量点云与图像数据,单日采集量达 TB 级,训练数据湖快速突破 PB 级。智加科技作为前装量产智能重卡的先行者,其基础设施横跨本地机房、天翼云、火山云、金山云等多计算环境,面临所有多云智驾公司的共性难题:
对象存储 I/O 瓶颈,GPU 陷入 “算力空转”
传统架构下,训练数据集中存储于多云对象存储,GPU 集群直接拉取数据训练。数据量较小时可正常运行,但进入 PB 级规模后,海量小文件随机读取性能急剧下滑,I/O 延迟居高不下,GPU 频繁等待数据,高价值算力利用率不足 50%,迭代周期被迫拉长。
数据清洗、标注、ETL 挖掘阶段,需高频写入海量小文件至对象存储。而对象存储原生不适配小文件高并发写入,直写模式下延迟达秒级,数据处理链路严重阻塞,“数据喂得快才算快” 成为空谈。
本地 + 多公有云混合架构下,计算集群分布分散,若数据分散存储或手动同步,极易出现数据版本漂移、训练结果不可复现、集群间数据不一致等问题,直接触碰自动驾驶训练的底线,无法支撑规模化、标准化研发。
智加科技的核心诉求清晰:在不重构现有训练框架、不迁移数据、不增加复杂运维的前提下,构建无侵入缓存方案,实现多云数据统一访问、对象存储性能逼近本地 NVMe、数据挖掘与训练全链路加速。
Alluxio:构建对象存储与 GPU 间的 “数据高速公路”
针对智加科技的多云混合架构痛点,Alluxio 提供分层缓存 + 统一命名空间 + 读写分离的分布式数据编排方案,在后端多云对象存储与前端 GPU 训练集群之间,搭建高性能缓存层,架构如下:
读缓存集群:部署于 GPU 训练集群侧,利用计算节点本地 SSD 构建分布式缓存池。训练任务启动时,Alluxio 自动从本地缓存读取热数据,避免反复访问远端对象存储;冷数据首次读取后自动缓存,后续访问直接命中本地。在 mmdet 目标检测、3D 点云训练等场景中,训练耗时与本地 NVMe 完全一致,实现云端存储本地性能。
写缓存集群:专门优化高频小文件写入,数据先写入 Alluxio 缓存层,异步批量刷新至后端对象存储,将小文件写入延迟从秒级降至毫秒级,彻底打通数据挖掘链路瓶颈。
Alluxio 提供全局统一数据视图,屏蔽多云存储差异,本地、天翼云、火山云、金山云等所有计算集群,通过同一逻辑入口访问数据。数据仅需写入一次,所有环境均可一致读取,彻底消除多云数据同步、版本混乱问题,实现 “单一事实来源”,保障模型训练可复现。
整套方案无需修改智加科技现有 PyTorch/TensorFlow 训练框架、业务代码,通过标准 POSIX/S3 API 接入,快速部署上线,大幅降低迁移与适配成本。
部署 Alluxio 后,智加科技训练数据引擎核心指标实现跨越式提升,直接支撑算法迭代加速:
吞吐能力:峰值带宽 10 倍 +,加载时间从小时级降至分钟级
核心架构是 Alluxio 加速层和 asset-api 编排层的配合设计:
直连对象存储:峰值 700MiB/s,平均 500MB/s;
Alluxio 加速后:峰值 8GB/s,提升超 10 倍;
mmdet 目标检测、3D 点云模型训练、仿真验证等真实场景实测,Alluxio 缓存加速后的训练时长,与数据直接存储在本地 NVMe SSD 完全一致,低成本对象存储替代昂贵全闪 NAS,兼顾性能与成本。
算力释放:GPU 利用率突破 99.57%,算力价值最大化
I/O 瓶颈彻底消除,GPU 不再空转等待数据,算力利用率从不足 50% 提升至 99.57%,高价值 GPU 资源充分释放,算法迭代周期显著缩短。
统一命名空间实现多云数据全局一致,无需跨云手动同步数据,工程师在任意环境均可获得一致性能,数据漂移风险清零,运维成本大幅降低。
行业启示:存算分离最后一公里打通,分布式缓存成智驾数据基础设施标配
智加科技的实践,为 L4 自动驾驶行业提供可复用的数据基础设施建设路径:对象存储凭借低成本、高弹性,已成为智驾企业 PB 级数据湖的主流选择,但必须通过分布式缓存补齐性能短板,才能支撑大模型时代的训练需求。
传统 “对象存储 + 全闪 NAS 热备” 模式,成本高昂、扩展受限;而 Alluxio + 多云对象存储的组合,实现 “低成本存储 + 本地级性能 + 多云统一”,打通存算分离最后一公里。目前,千里智驾、造父科技、九识智能等头部企业均已采用 Alluxio 构建数据底座,分布式缓存正成为智驾行业数据基础设施的标准组件。
当重卡自动驾驶车队规模突破千台、商业运营里程迈过亿级门槛,数据基础设施的竞争力,直接决定算法迭代速度与量产落地节奏。智加科技通过 Alluxio 构建多云统一缓存架构,将数据吞吐提升 10 倍,实现云端训练性能对齐本地 NVMe,为 L4 重卡商业化试点提供坚实数据支撑。