⚡ 2025重磅!SpaceDrive:给VLM注入空间感知,破解自动驾驶端到端规划的3D推理难题
📖 导读
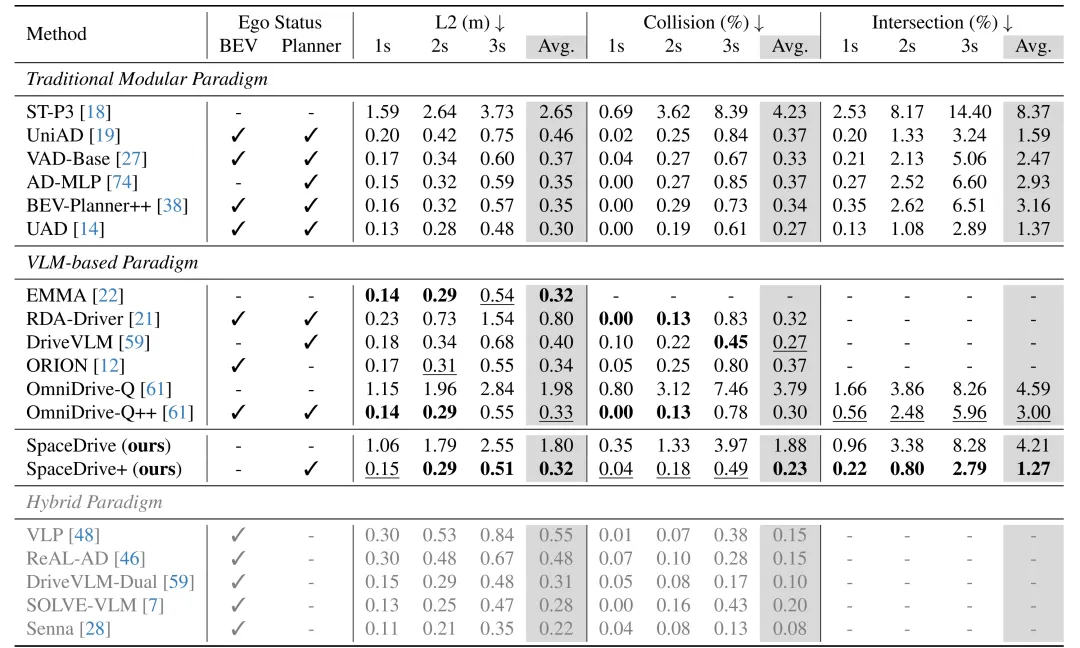
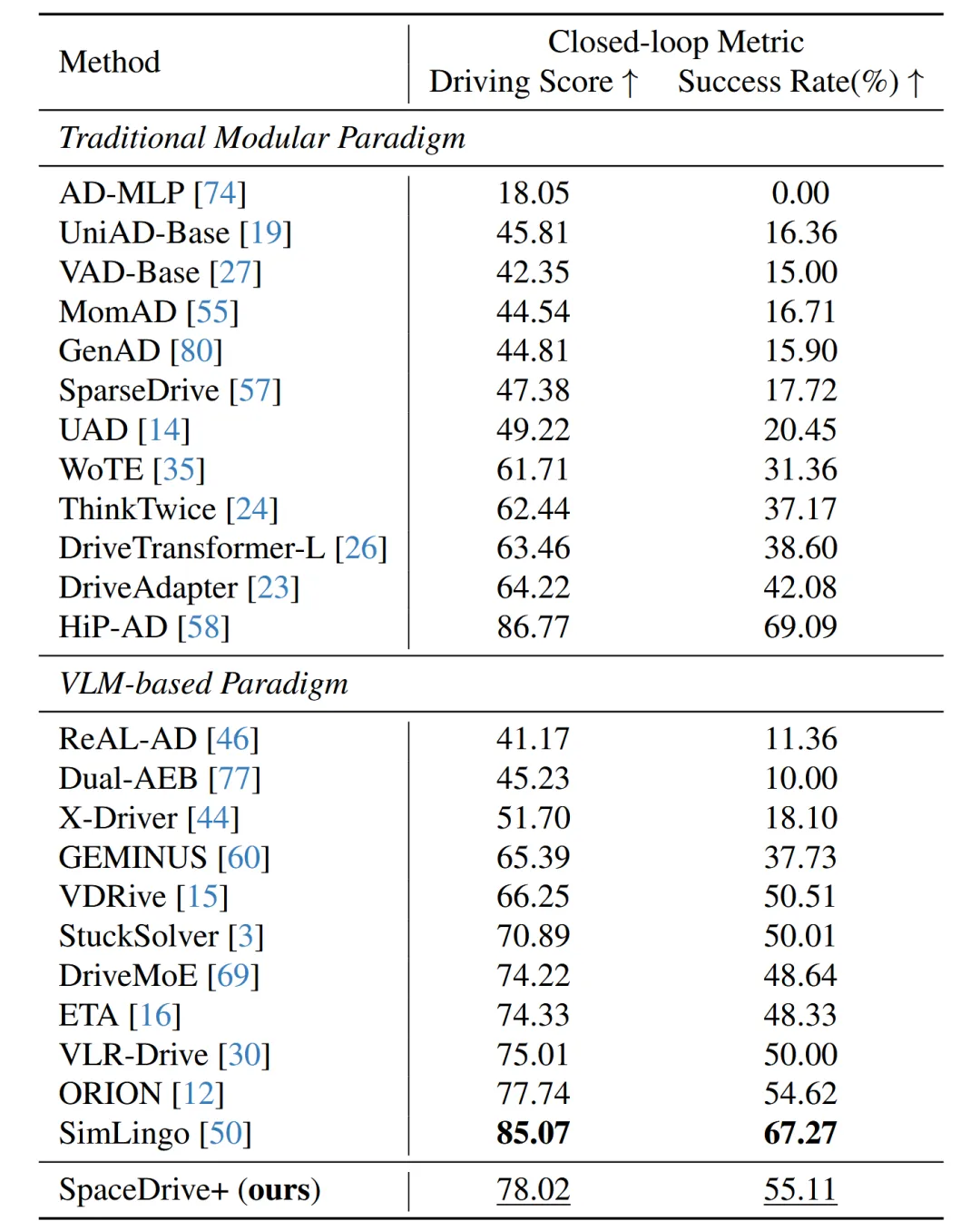
这篇由奔驰与图宾根大学联合发表的论文,核心结论很明确:通过一套统一的3D位置编码框架,把空间信息转化为显式的位置嵌入而非零散的文本数字,成功解决了视觉语言模型(VLM)在自动驾驶中3D空间推理薄弱的核心问题。实验证明,SpaceDrive在nuScenes开环评估中拿下VLM类方法的SOTA性能,平均轨迹误差仅0.32米,碰撞率低至0.23%;在Bench2Drive闭环仿真中,驾驶分数达到78.02(VLM类方法排名第二),成功率55.11%。它让VLM真正具备了精确的空间定位、物体关联和轨迹规划能力,而且不需要依赖复杂的稠密BEV特征。
这个框架的核心优势在于:统一的3D位置编码打通了视觉语义和空间几何的关联,用位置嵌入替代文本数字避免了固有缺陷,回归式解码提升了轨迹精度,还能适配Qwen-VL、LLaVA等多种VLM基座,泛化性拉满。
📷 图1 | SpaceDrive核心架构
原论文信息
- 论文题目:SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
- 作者单位:奔驰集团、图宾根大学、图宾根AI中心、慕尼黑工业大学等联合研发;
- 核心数据:在nuScenes开环测试中,平均轨迹误差0.32米、碰撞率0.23%、道路交叉率1.27%,均为VLM类方法最优;Bench2Drive闭环仿真中,驾驶分数78.02、任务成功率55.11%,位列VLM类方法第二;能直接适配Qwen2.5-VL、LLaVA等主流VLM基座;
- 关键创新:统一3D位置编码、视觉令牌空间增强、文本坐标替换、回归式轨迹解码;
- 实验基准:开环用nuScenes数据集,闭环用Bench2Drive(基于CARLA模拟器),主要看轨迹精度、碰撞率、驾驶分数和任务成功率;
- 模型配置:以Qwen2.5-VL7B或LLaVA为基础,用LoRA轻量化微调,搭配UniDepthV2深度估计模块,通过3D正弦-余弦位置编码和MLP回归解码器实现空间感知;
- 核心应用:VLM端到端自动驾驶规划、复杂场景空间推理、多模态驾驶决策;
- 发表状态:2025年12月11日 arXiv预印本(arXiv:2512.10719v1 [cs.CV])。
❓ VLM-based自动驾驶的三大“核心痛点”
- 3D空间推理弱:VLM没经过专门的3D数据预训练,只能靠2D知识猜空间关系,没法精准判断距离、物体尺寸这些关键几何信息;
- 文本数字处理坑:把坐标当成离散的文字逐位生成,忽略了数字之间的连续性,导致轨迹规划精度差、抖动明显;
- 没有统一空间语言:现有方法要么用任务专属的嵌入,要么用文本数字,没法在视觉语义和3D坐标之间建立明确关联,换个场景就容易失效。
🔧 核心突破:SpaceDrive的“四维创新”方案
1. 统一3D位置编码:打通空间与语义的“通用语言”
设计了一套通用的3D正弦-余弦位置编码,不管是深度图里的空间坐标、自车的行驶状态,还是文本提示里的位置信息,都能转化成统一格式的嵌入。这种编码能兼顾局部位置的区分度和全局空间的连续性,让不同来源的空间信息能直接“对话”。
2. 视觉令牌空间增强:给图像特征加“3D坐标标签”
先通过深度估计得到每个图像补丁的3D坐标,编码后和对应的2D视觉特征逐点相加,还会用一个可学习的归一化因子调整强度,避免特征分布混乱。这样一来,视觉特征不仅包含语义信息,还自带3D空间属性,VLM能快速通过空间位置找到对应的图像内容。
3. 文本坐标PE替换:告别零散的数字令牌
处理文本提示里的坐标信息时,不再用“3.82米”这种文字形式,而是直接换成统一的3D位置嵌入,前面加个特殊标识区分普通文字。这样VLM不用再逐字生成数字,而是直接基于空间嵌入做推理,避免了数字处理的精度损失。
4. 回归式轨迹解码器:直接输出精准轨迹
用一个简单的MLP网络替代VLM原来的文字生成头,专门负责输出轨迹坐标。这种回归式设计能直接对应连续的空间位置,不用再把坐标拆成文字生成,大幅提升了轨迹的平滑度和精度,同时还能保留VLM正常的文本推理能力。
关键内容
1. 核心工作机制
- 3D位置编码:用不同频率的正余弦函数处理x、y、z三个维度,既保证近距离物体能区分,又能覆盖远距离的空间关系;
- 视觉增强流程:先把深度图匹配图像补丁的大小,取每个补丁的最小深度作为它的空间位置,编码后和视觉特征融合,让每个图像补丁都知道自己在3D空间里的位置;
- 自车状态融入:把自车过去的行驶轨迹也用同样的3D编码处理,作为时空参考输入,让规划的轨迹更连贯;
- 训练目标:同时优化两部分——一是VLM的文本推理能力,二是轨迹坐标的预测精度,用平滑的损失函数减少极端误差的影响。
2. 关键实验结果
(1)开环规划表现(nuScenes数据集)
SpaceDrive+的平均轨迹误差仅0.32米,碰撞率0.23%,道路交叉率1.27%。对比同类VLM方法,OmniDrive-Q++的平均误差是0.33米、碰撞率0.30%,ORION的平均误差0.34米、碰撞率0.37%,SpaceDrive+在精度和安全性上都更优;即便是混合了传统模块的方法,SpaceDrive+的表现也毫不逊色。
(2)闭环仿真表现(Bench2Drive数据集)
在包含220条路线、44种交互场景的闭环测试中,SpaceDrive+的驾驶分数达到78.02,任务成功率55.11%。在所有纯VLM方法里排名第二,仅次于SimLingo;对比传统的端到端模型,比如VAD-Base(驾驶分数42.35、成功率15.00%),优势非常明显,能在复杂交互场景中做出合理决策。
纯文本方法在闭环仿真中退化失效
SpaceDrive可以胜任复杂的闭环驾驶场景
(3)多基座适配性
不管是用Qwen-VL还是LLaVA作为基础模型,SpaceDrive都能稳定发挥。比如用Qwen-VL时,开环平均误差1.80米、碰撞率1.88%;换成LLaVA后,平均误差1.82米、碰撞率2.44%,性能差异很小,说明这套框架不依赖特定基座,泛化性很强。
3. 核心优势验证
- 空间推理能力:在碰撞预测、安全判断等任务中,SpaceDrive的安全相关召回率达到63.6%,碰撞推理精度37.5%,明显超过传统VLM;
- 轻量化高效:只用LoRA微调10.09M可学习参数,不用冻结视觉编码器,训练成本低,适合实际部署;
- 去BEV依赖:不需要构建稠密的鸟瞰图特征,仅靠3D位置编码就能实现精准空间建模,简化了整个技术 pipeline。
💬 Q&A
Q1:为什么不用文本数字令牌,非要用3D位置编码?A:文本令牌会把连续的坐标拆成零散文字,比如“0.32米”拆成“0”“.”“3”“2”,VLM没法理解数字间的连续性,容易生成跳跃的轨迹;3D位置编码直接建模空间关系,能让VLM真正“感知”到位置,而不是单纯“朗读”数字。
Q2:SpaceDrive能适配我常用的VLM吗?A:可以的,它的设计很灵活,不用修改VLM的核心结构,只需要新增位置编码、回归解码器等少量模块,目前已经验证了Qwen-VL和LLaVA,其他主流VLM也能快速适配。
Q3:和BEV-based方法比,它的优势在哪?A:BEV-based方法需要构建复杂的鸟瞰图特征,计算成本高还依赖大量3D标注;SpaceDrive不用BEV,仅靠单目深度估计和3D位置编码就能实现空间建模,标注需求低、推理速度快,泛化性也更强。
🎯 点评
- 核心贡献:首次提出统一的3D位置编码框架,真正解决了VLM空间感知不足的痛点;打通了视觉、文本、自车状态的空间关联,让VLM从“看得到”升级到“看得懂空间”;验证了VLM在自动驾驶中“去BEV化”的可行性,为端到端规划提供了更简洁的方案;
- 创新点:3D位置编码的统一表示、视觉特征的空间增强、文本坐标的嵌入替换、回归式轨迹解码,四个创新点层层递进,直击VLM在物理世界交互的核心缺陷;
🌟 总结金句
SpaceDrive的核心价值,是给VLM搭建了一套“空间感知的通用语言”——当3D几何信息不再是零散的文本数字,而是和视觉语义深度绑定的显式嵌入,VLM才能真正从“2D语义理解”走向“3D物理交互”,为自动驾驶端到端规划提供兼具精度、泛化性与效率的全新方案。
📌 互动引导
你认为SpaceDrive最适合落地的自动驾驶场景是什么?● ✅ 城市道路复杂交互(需精准空间推理);● ✅ 低速园区自动驾驶(端到端部署需求);● ❌ 高速极端天气(需更强时序建模);欢迎在评论区分享观点,一起探讨VLM在自动驾驶中的落地边界与优化方向 👇
🧩 科研 Idea 彩蛋(可操作方向)
- 时序增强:给位置编码加入时间维度,融合多帧的空间信息,提升长距离规划的稳定性,适合投稿ICCV;
- 不确定性建模:让回归解码器输出轨迹的概率分布,量化预测误差,提升极端场景的安全冗余,适合投稿IEEE T-ITS;
- 多模态融合:把LiDAR点云的3D信息也融入统一编码,提升恶劣天气下的空间感知鲁棒性,适合投稿CVPR;
- 轻量化设计:对位置编码进行剪枝或量化,降低计算成本,适配车载边缘设备,适合投稿NeurIPS。