盘点|2025 自动驾驶六大顶会最值得阅读的20篇论文(CVPR/ICCV/IROS/ICRA/RSS/CoRL)
- 2026-07-09 23:01:09

「从世界模型到端到端...」
“顶会论文浩如烟海,但真正能定义‘年度技术风向标’的,往往只有那一小撮。”
ps:需要说明的是,本文的选取仅为管窥一豹,旨在呈现技术脉络的若干剖面。欢迎大家在评论区推荐/补充。
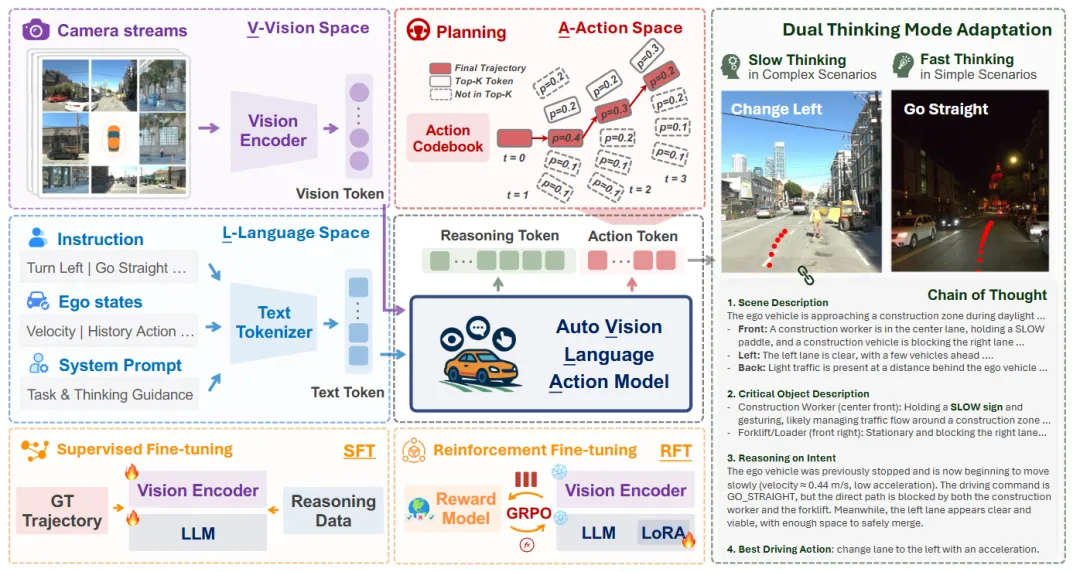
机构:中国科学院计算技术研究所;中国科学院大学;北京控制工程研究所
亮点:这项研究针对自动驾驶中4D雷达在恶劣天气下可靠、但其点云稀疏嘈杂严重影响检测的痛点,提出了一个即插即用的CORENet模块。它采用“训练时借力激光雷达进行跨模态监督,推理时仅需纯雷达数据”的巧妙设计,在不增加实际传感器依赖的前提下,有效为雷达点云去噪并增强特征,从而直接提升下游检测器的输入质量。在充满真实噪声的DualRadar数据集上验证,该方法显著提高了目标检测的鲁棒性与综合性能。
链接:https://arxiv.org/pdf/2508.13485
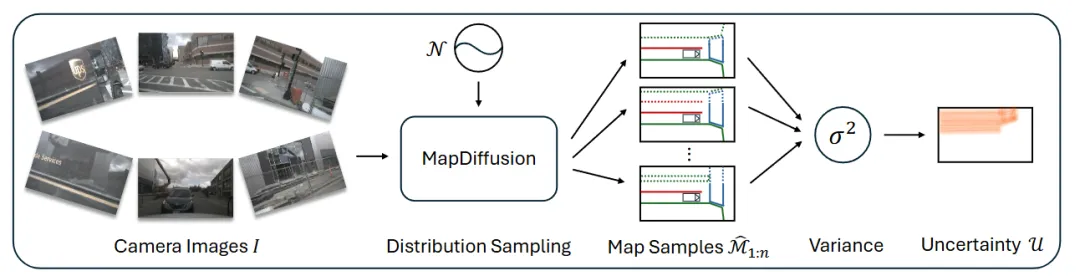
机构:梅赛德斯 奔驰北美研发中心;斯图加特大学;加州大学圣地亚哥分校;南安普顿大学
亮点:这篇论文正视了在线构建高清地图中的一个根本局限:现实路况常因遮挡、标识不清等产生地图的合理歧义。为此提出的MapDiffusion不再输出“唯一确定”的地图,而是引入扩散模型,把地图构建变成一个从噪声逐步推理出多版本合理结果的生成过程。这种做法实际上承认并建模了地图本身的不确定性——系统能同时输出多个可信的地图假设,聚合这些结果通常比单一预测更准;而各版本差异大的区域,则直接反映出高不确定性(比如被遮挡处),为规划模块提供了宝贵的风险指示。在nuScenes数据集上,该方法以单样本超越基线,多样本聚合进一步稳步提升,同时产出的不确定性地图也符合真实驾驶的直觉判断。
链接:https://arxiv.org/pdf/2507.21423
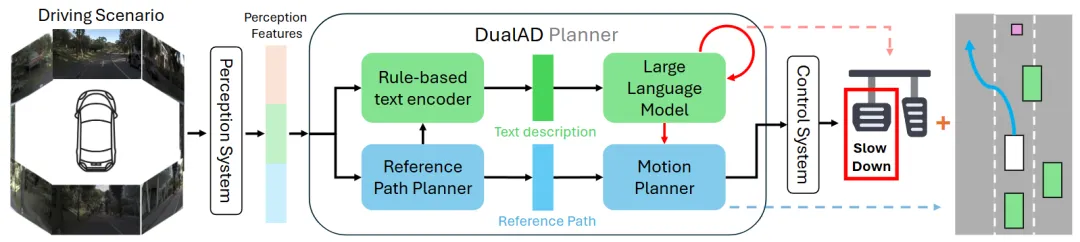
机构:慕尼黑工业大学
亮点:本文提出了一种双层自动驾驶框架,旨在为系统嵌入常识推理能力。其下层负责执行高频的规则化运动规划;上层则创新地利用大语言模型作为“安全监督员”——通过文本编码器将驾驶场景转化为自然语言描述,供模型进行风险推理。一旦识别隐患,上层可直接介入,执行动态限速或紧急制动。该方法的关键在于,即使使用零样本大模型,也能显著提升系统安全性,而场景描述的有效性至关重要。该设计将核心推理能力与大模型能力解耦,为未来直接接入更强大的模型提供了清晰的升级路径。
链接:https://arxiv.org/pdf/2409.18053
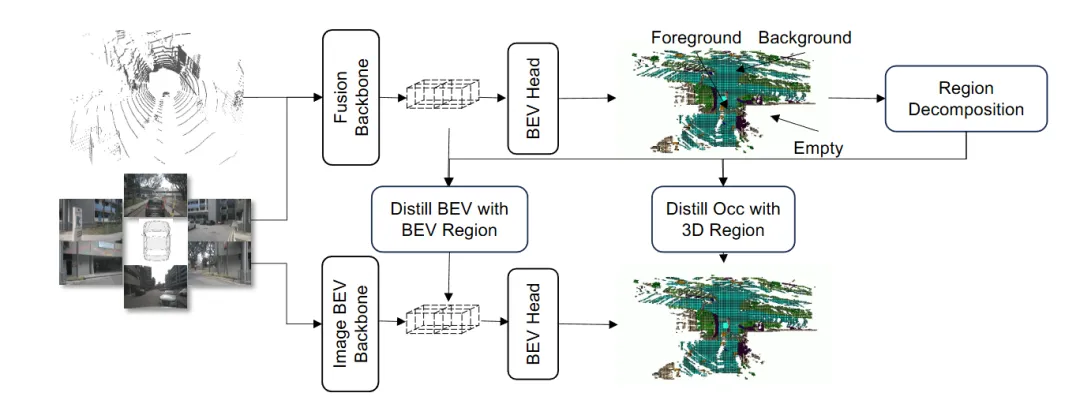
机构:清华大学;智能绿色车辆与交通全国重点实验室;卡尔动力;纵目科技
亮点:本文直面3D占用预测落地中模型沉重与标注昂贵两大瓶颈,提出轻量化框架EFFOcc。其核心在于双管齐下的高效设计:模型方面,避免使用沉重的3D卷积或Transformer,转而采用以2D运算为主的高效架构,在精度领先的同时极大降低了计算负担;训练方面,创新性地引入面向占用的多阶段知识蒸馏,利用融合模型作为“教师”来指导纯视觉“学生”模型,从而大幅减少对昂贵密集体素标注的依赖。实验表明,仅需40%的标注数据,经蒸馏的纯视觉模型性能即可接近全量监督基线。该方法为高精度3D占用预测的实际部署,提供了一条通向更轻、更省、更易用的可行路径。
链接:https://arxiv.org/pdf/2406.07042
后台私信0104,免费领取自动驾驶顶会论文合集
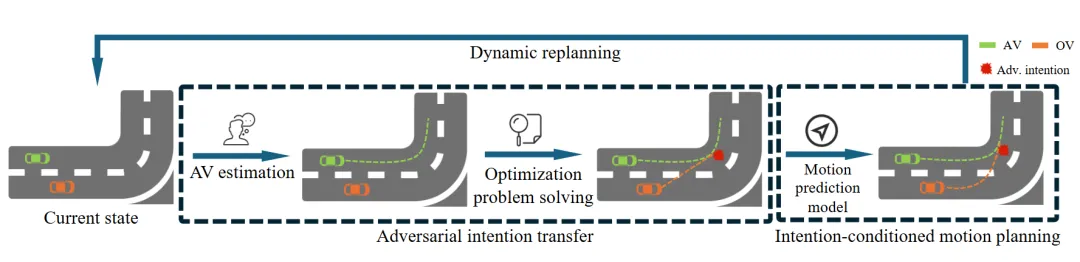
机构:上海交通大学;上海人工智能实验室
亮点:本文聚焦于自动驾驶测试中长尾危险场景难以真实复现的核心难题,提出了一种创新的对抗场景生成框架IntSim。其核心突破在于将“意图”与“轨迹”解耦处理:首先,不直接修改轨迹,而是通过一个约束优化问题,高效搜索并生成对自车构成潜在威胁的多样化驾驶意图(如卡位、逼迫)。随后,基于此意图,利用从真实数据中学到的强深度模型生成符合交通常识且看起来自然的运动轨迹,确保对抗行为像真实人类驾驶员所为。该方法进一步支持动态意图调整,从而实现自车与周围车辆之间持续、灵活的对抗性互动。实验表明,IntSim能高效生成更真实、更危险的测试场景,并且利用这些场景训练可以显著提升自动驾驶规划器在极端情况下的应对能力。
链接:https://arxiv.org/pdf/2503.05180
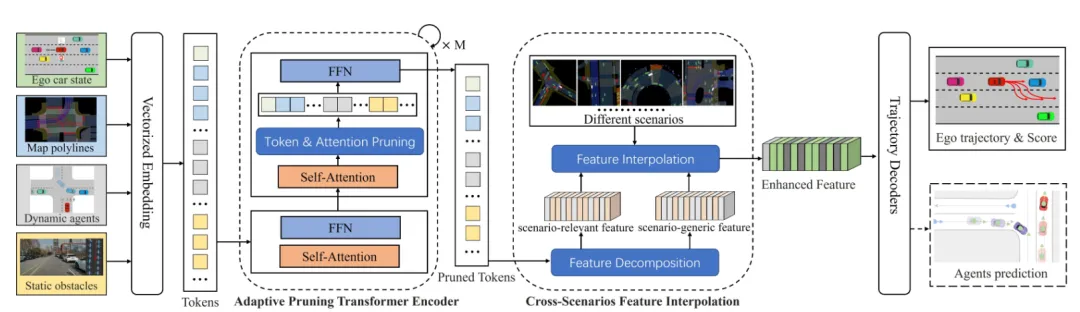
机构:中国科学技术大学;合肥综合性国家科学中心 人工智能研究院;中国科学技术大学
亮点:本文聚焦模仿学习在自动驾驶轨迹规划中的核心挑战:闭环测试中的“因果混淆”误差累积与训练数据的场景不均衡。为解决这两大问题,提出的CAFE-AD框架从特征层面入手,采用自适应特征剪枝过滤输入中的噪声与冗余信息,同时通过跨场景特征插值人为构造多样化的中间场景特征。这种设计让模型在训练中既专注于关键信息,又能接触到更丰富的场景变化,从而显著提升了在长尾困难场景下的规划鲁棒性。该方法在极具挑战性的nuPlan闭环测试榜上超越了现有主流规划器,为模仿学习走向可靠落地提供了新思路。
链接:https://arxiv.org/pdf/2504.06584
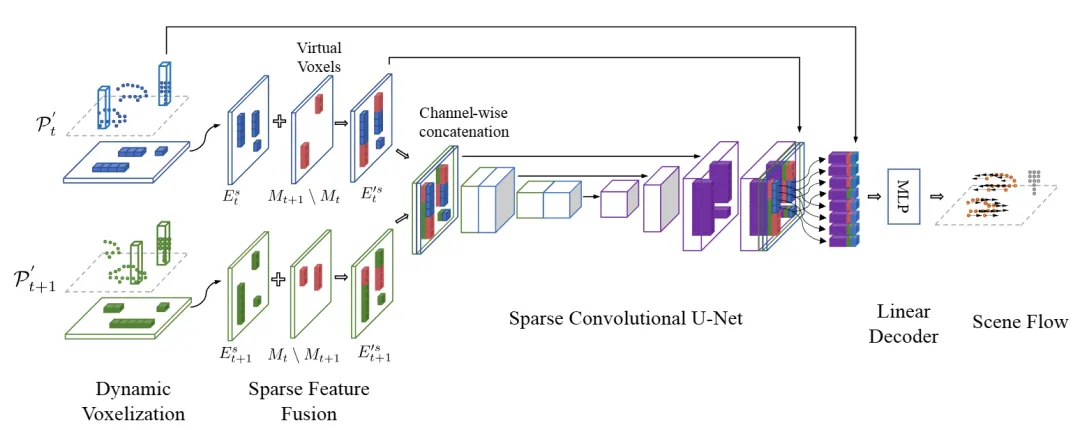
机构:皇家理工学院;斯堪尼亚集团 自动运输解决方案实验室;斯坦福大学
亮点:该论文针对3D场景流(描述3D点云中每个点的运动)在长距离估计时计算量激增的痛点,提出了首个面向长距离的稀疏场景流估计框架SSF。其核心创新在于摒弃传统密集网格方法,转而采用稀疏卷积网络,仅在有点云的体素中进行高效计算,从而克服了距离增长带来的计算负担。为解决两帧稀疏特征因非对齐而无法融合的关键难题,作者引入了“虚拟体素”索引补齐技术,巧妙地实现了跨帧稀疏特征的对齐与有效融合。此外,通过设计距离加权的训练损失,使模型更专注优化远距离点的运动估计精度。在Argoverse2数据集上的实验表明,该方法在长距离场景流估计任务上达到了领先水平。
链接:https://arxiv.org/pdf/2501.17821
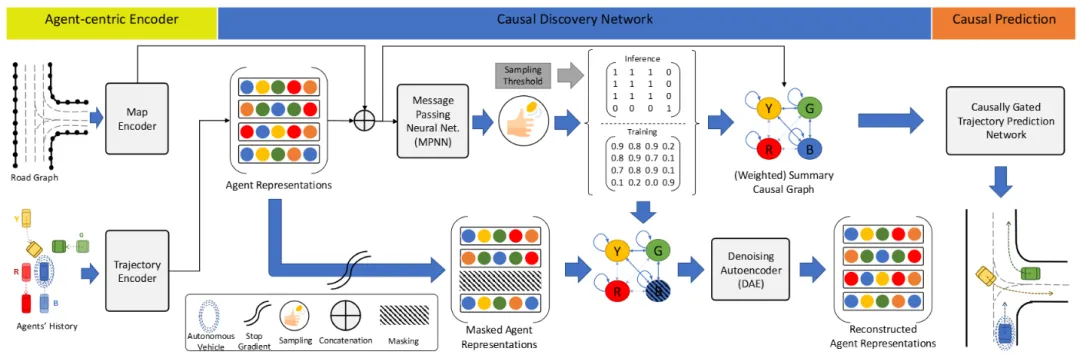
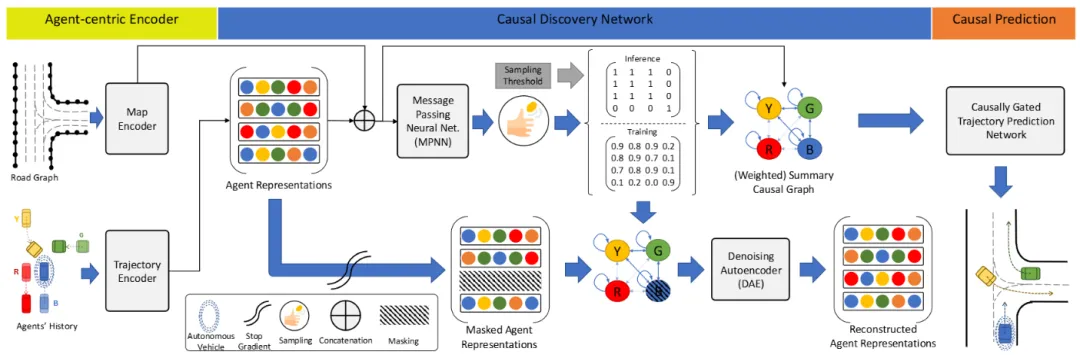
机构:阿尔伯塔大学;华为 诺亚方舟实验室;康奈尔大学
亮点:这篇论文揭示了轨迹预测中一个关键但常被忽略的问题:模型容易被与自车决策无关的交通参与者所干扰。为解决此问题,作者提出CRiTIC框架,其核心创新在于引入显式的因果关系建模:首先通过一个子网络自动发现历史交互中“谁真正影响了谁”的因果图,随后在Transformer预测器中利用此因果图对注意力进行门控筛选,从而引导模型聚焦于具有因果关联的关键参与者,而非被无关的“路人”行为所误导。该方法显著提升了模型对无关扰动与分布外场景的鲁棒性(最高达54%)与泛化能力(跨域性能提升达29%),在保证预测精度的同时,使预测结果更为专注和可靠。
链接:https://arxiv.org/pdf/2410.07191
后台私信0104,免费领取自动驾驶顶会论文合集
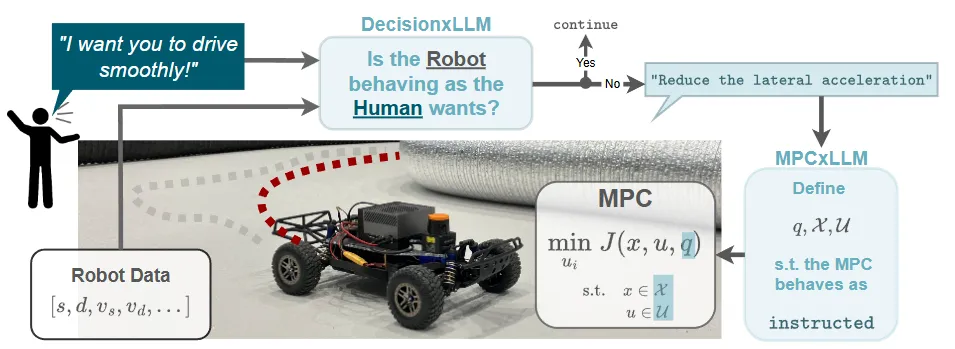
机构:苏黎世联邦理工学院;浙江大学 控制科学与工程系
亮点:本文致力于将大语言模型(LLM)务实且高效地部署到车端,以补足传统数据驱动方法在常识推理上的短板。其核心是提出一种混合决策架构,让LLM与传统模型预测控制(MPC)各司其职:首先由 DecisionxLLM 对齐人类指令与车辆状态,进行高层理解与决策偏好判断;随后由 MPCxLLM 将此偏好转化为对 MPC 控制器参数(如代价函数权重)的实时调整,而安全底层的控制仍由MPC严格保证。为实现车载实时运行,作者系统地采用了检索增强(RAG)、LoRA微调与量化等“上车三件套”进行优化。实验表明,该框架不仅显著提升了决策准确性与控制适应性,更在推理效率上实现了数量级提升,证明了其不只是一个概念,更是一条通往实用落地的清晰技术路径。
链接:https://arxiv.org/pdf/2504.11514
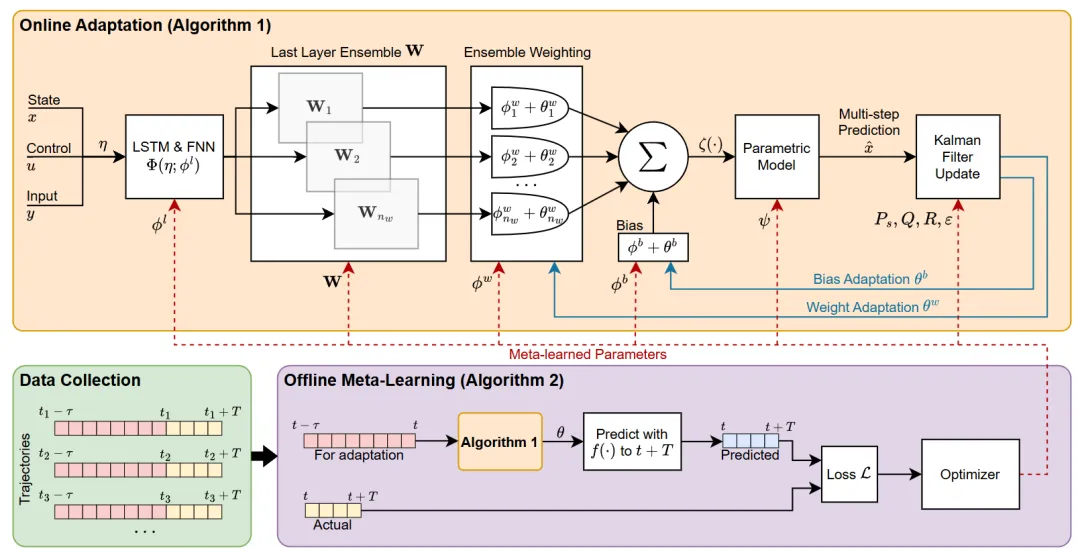
机构:德克萨斯大学奥斯汀分校;佐治亚理工学院;加州理工学院
亮点:这项研究直面越野自动驾驶的核心挑战:多变地形导致车辆动力学模型难以准确建模。为解决此问题,作者提出了一种结合元学习(离线准备)与在线滤波(实时适应) 的两阶段方案:离线阶段,通过元学习提炼出能快速适应新地形的模型结构与调整策略;在线运行时,则基于卡尔曼滤波机制,实时利用传感器观测微调动力学模型参数,实现“边跑边学”。该方法最终服务于模型预测控制,在大量测试及全尺寸实车验证中,其预测准确性、控制性能与安全性均超越基线,尤其在危险、易失稳的场景中表现更为突出。
链接:https://arxiv.org/pdf/2504.16923
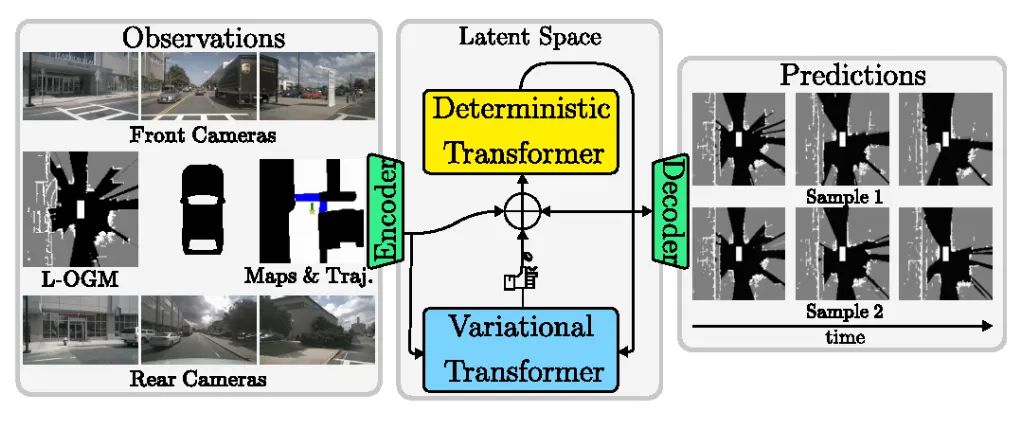
机构:斯坦福大学;加州大学河滨分校
亮点:本文针对自动驾驶环境预测中“未来唯一确定”这一不切实际的假设,提出了一种名为LOPR的潜空间生成式预测框架。其核心思路是将未来的多种可能性建模于一个隐变量空间中,从而自监督地生成多样且合理的未来占用栅格,而非单一确定结果。该框架能灵活融合图像、地图及自车轨迹等多种条件信息,使预测更贴合实际驾驶上下文。为实现高效部署,它创新地提供了两种解码模式:轻量一步解码保障实时性,扩散式迭代解码则进一步优化时间连贯性与细节质量。实验表明,该方法在nuScenes与Waymo Open数据集上全面超越了传统方案。
链接:https://arxiv.org/pdf/2410.07191
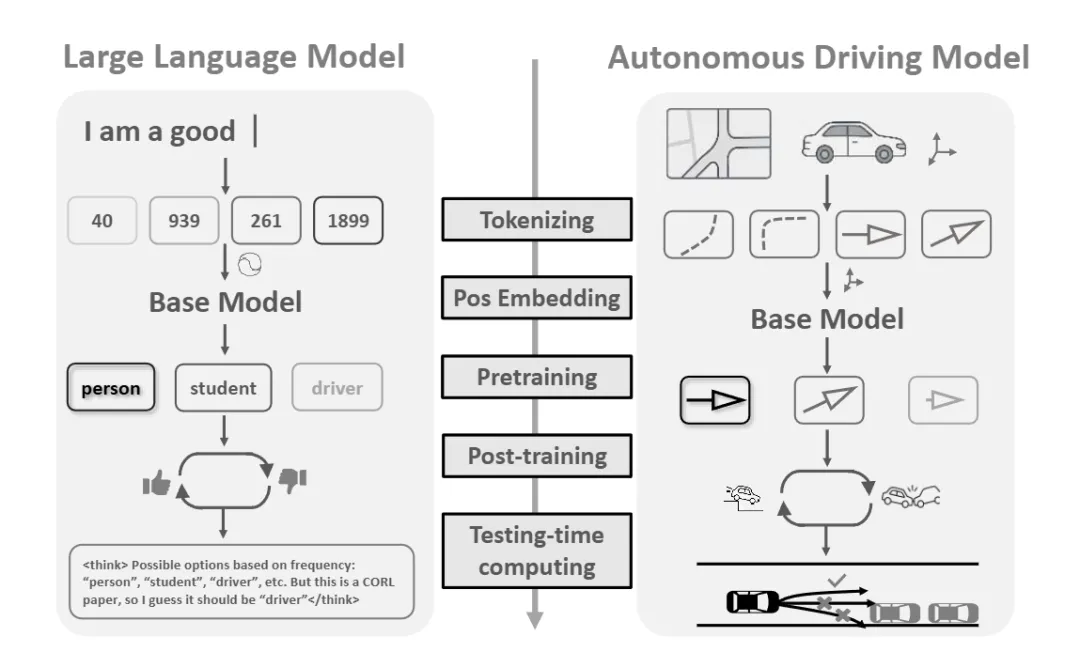
机构:西湖大学;浙江大学
亮点:这篇论文对当前“将大语言模型组件迁移至自动驾驶运动生成”的热潮进行了一次系统性的实证检验。研究指出,尽管两者同属序列生成任务,但LLM的模块不能简单套用。为此,作者在Waymo Sim Agents基准上,围绕Tokenizer设计、位置编码、预训练与后训练策略、测试时计算这五大核心组件展开了详尽的“拆解式”评估。其核心结论并非给出一个万能模型,而是提供了一份基于实验的 “组件迁移指南” :明确指出了哪些LLM技术经针对性改造后能显著提升性能,哪些会“水土不服”及其原因。这项研究为如何理性、高效地吸收LLM成功经验,而非盲目套用,提供了扎实的实验依据与设计原则。
链接:https://arxiv.org/pdf/2509.02754
后台私信0104,免费领取自动驾驶顶会论文合集
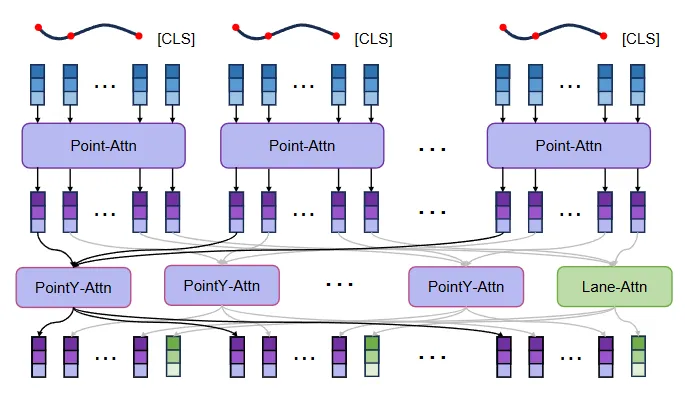
机构:中国科学院自动化研究所;中国科学院大学;
亮点:该研究揭示了单目3D车道线检测中一个被忽视的根本性风险:为追求效率而广泛采用的稀疏点表示方法存在严重的结构性缺陷,在复杂场景下可能引发高达20米的几何误差。为解决此问题,作者提出了创新的补全拼接(patching)策略,并配套设计了一个端点头(EP-head),使模型能够从稀疏点中预测车道线的完整延伸,从而用更少的点实现更精确、结构更完整的表示。同时,他们引入了PL-attention机制,将车道线的几何结构先验融入注意力计算,以增强模型对连续结构的理解。这两项改进可作为通用插件,显著提升包括Persformer、Anchor3DLane在内的多种主流模型的性能(如F1分数),为构建既高效又可靠的3D车道线检测系统提供了关键思路。
链接:https://arxiv.org/pdf/2503.06237

机构:GigaAI;中国科学院自动化研究所;理想汽车;北京大学;慕尼黑工业大学
亮点:这篇论文聚焦于自动驾驶仿真中传感器渲染的核心痛点——如何在自车执行变道等复杂新轨迹时,仍能生成物理一致、时空连贯的可信画面。传统基于重建的方法(如4DGS)严重受限于训练数据(多为前向行驶)的分布,一旦视角或运动超出该范围,渲染质量便急剧下降。为此,作者创新性地提出DriveDreamer4D,其核心思路是将驾驶视频生成模型(World Model)转化为一个“数据引擎”,用以合成真实世界中稀缺的复杂驾驶轨迹视频。通过引入结构化条件生成机制,该方法确保了合成视频中动态元素的时空一致性,进而将这些高质量的合成数据与真实数据共同优化4D高斯场景表示。此外,提出的“cousin data”训练策略有效缓解了合成数据带来的分布偏移问题。实验表明,该方法在新轨迹视角生成质量(如FID指标)和动态元素的物理一致性(如NTA-IoU)上均显著优于现有方法,首次实现了通过生成模型来系统性提升驾驶场景的4D重建与渲染能力。
链接:https://arxiv.org/pdf/2410.13571
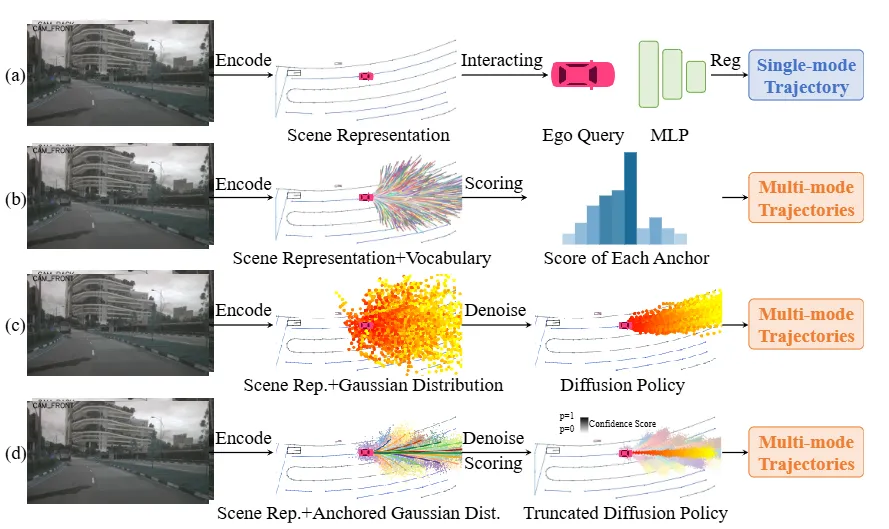
机构:华中科技大学;地平线
亮点:这篇论文解决了端到端自动驾驶中扩散模型生成多样性与推理实时性难以兼得的核心矛盾。提出的DiffusionDrive通过引入先验的多模态锚点与截断扩散机制,实现了高效推理。其核心思路是从一组代表常见驾驶意图的轨迹锚点出发进行快速去噪,而非从纯噪声开始漫长迭代,从而将去噪步数减少一个量级。结合级联式扩散解码器设计,该方法在确保生成轨迹多样且合理的同时,达到了接近实时的推理速度,为扩散模型在动态驾驶场景中的实际部署提供了可行路径。
链接:https://arxiv.org/pdf/2411.15139
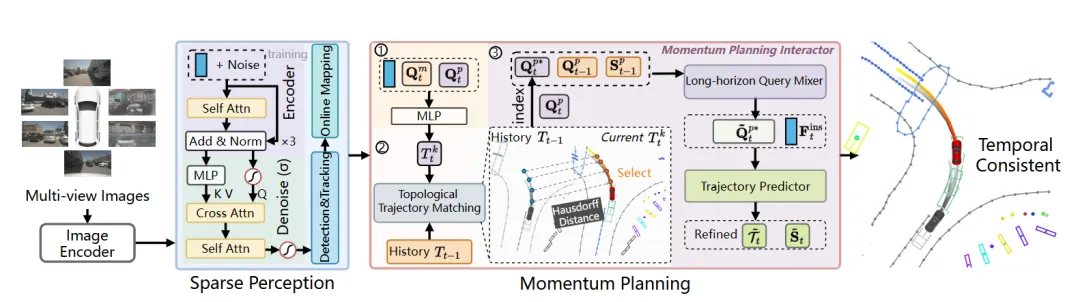
机构:北京交通大学;地平线
亮点:该研究针对端到端自动驾驶规划中因缺乏历史连续性导致的控制抖动与轨迹不稳定问题,提出了一种引入“动量”感知的规划框架MomAD。其核心在于强制当前决策与历史规划保持一致,具体通过拓扑轨迹匹配筛选与过去最连贯的轨迹候选,并利用动量规划交互器融合历史信息来稳定场景理解与长时域预测。该方法在训练中还结合了实例去噪以提升对噪声的鲁棒性,并提出了新的轨迹一致性评估指标。实验表明,MomAD显著提升了长时域规划的平滑性与安全性,在nuScenes等基准上降低了碰撞率并提高了闭环驾驶成功率,使端到端驾驶行为更接近人类连续、稳定的决策模式。
链接:https://arxiv.org/pdf/2503.03125
后台私信0104,免费领取自动驾驶顶会论文合集
机构:中国科学院自动化研究所;理想汽车;鹏城实验室;新加坡国立大学;清华大学
亮点:这篇论文旨在实现一种不依赖昂贵人工感知标注的端到端自动驾驶规划,其核心是构建一个自监督的潜空间世界模型。该方法首先融合视觉基础模型的语义先验与驾驶意图,形成对场景的深度理解;进而在给定意图下生成多条未来轨迹,并在潜空间中预测每条轨迹所对应的未来状态演化,实质上是让模型“预演”不同决策的后果。最后,通过一个世界模型选择器评估并筛选出最优轨迹。训练过程中,通过将模型预测的未来与真实观测在潜空间中对齐,使模型自主学习物理规律,完全摆脱了对感知标注的依赖。实验表明,该方法在nuScenes和NavSim基准上实现了“标注自由”下的性能领先,显著降低了轨迹误差与碰撞率。
链接:https://arxiv.org/pdf/2507.00603

机构:复旦大学 数据科学学院;上海创新研究院
亮点:这项研究致力于解决自动驾驶仿真中动态场景重建对高精度、高成本位姿标注的严重依赖问题。为此提出的BézierGS方法创新性地使用可学习的贝塞尔曲线来建模动态物体的运动轨迹。其核心在于将动态物体的运动视为一条时间上连续、可微的平滑曲线,而非依赖可能含噪的离散位姿标注,从而以曲线本身的连续性自动纠正标注误差,并实现更合理与连贯的运动表示。该方法还通过针对动态渲染的额外监督与曲线间的一致性约束,提升了动态与静态场景元素分离与重建的质量。实验表明,在Waymo和nuPlan等数据集上,该方法在新视角合成与动态/静态重建质量上均超越了现有主流方法。
链接:https://arxiv.org/pdf/2506.22099
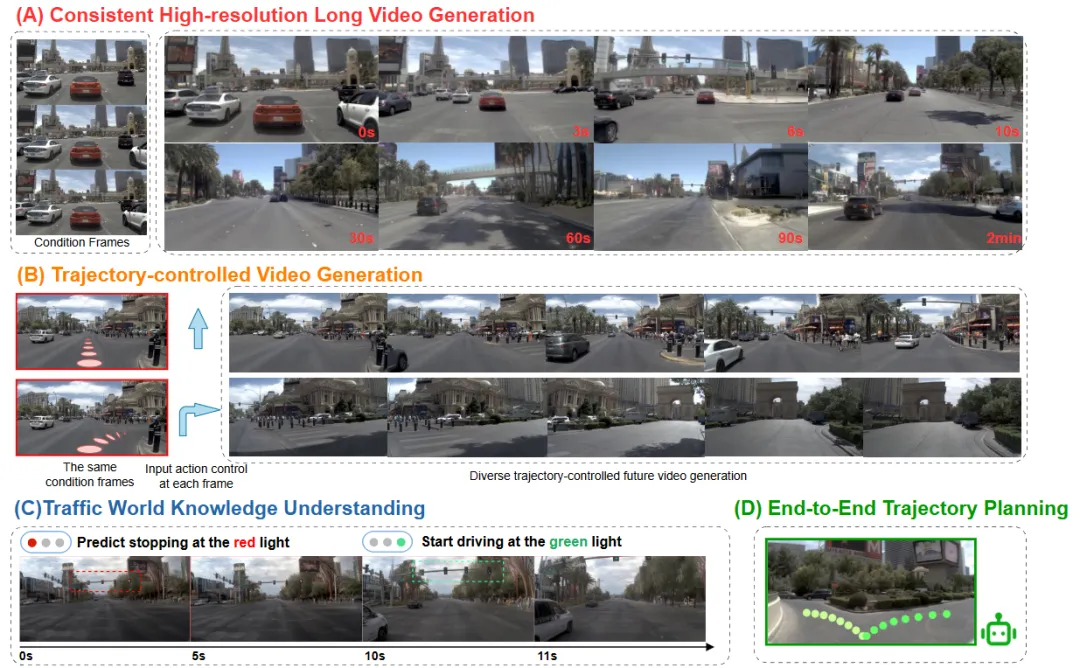
机构:地平线;清华大学;北京大学;南京大学;香港科技大学;南洋理工大学;腾讯混元
亮点:这篇论文旨在将自动驾驶中的“世界模型”从一个被动的未来视频生成器,升级为一个能进行长时预测与实时规划的主动决策引擎。针对现有视频扩散模型难以生成灵活时长预测、且与规划任务割裂的局限,其提出的Epona框架核心在于自回归扩散范式,即将未来拆解为逐步生成的步骤,实现更可控的长时预测。为此,它引入了解耦的时空因子分解来分别建模动态规律与细节生成,并采用模块化设计将轨迹预测与视频生成紧密结合,使模型能一体输出可执行的规划。通过链式训练策略缓解了自回归的误差累积问题。实验表明,Epona不仅在长时视频生成质量(如FVD指标)上取得提升,支持分钟级预测,其学到的世界模型更能直接作为实时运动规划器,在NAVSIM等基准上超越主流端到端方法,真正推动了世界模型从“生成观看”走向“决策使用”的质变。
链接:https://arxiv.org/pdf/2506.24113
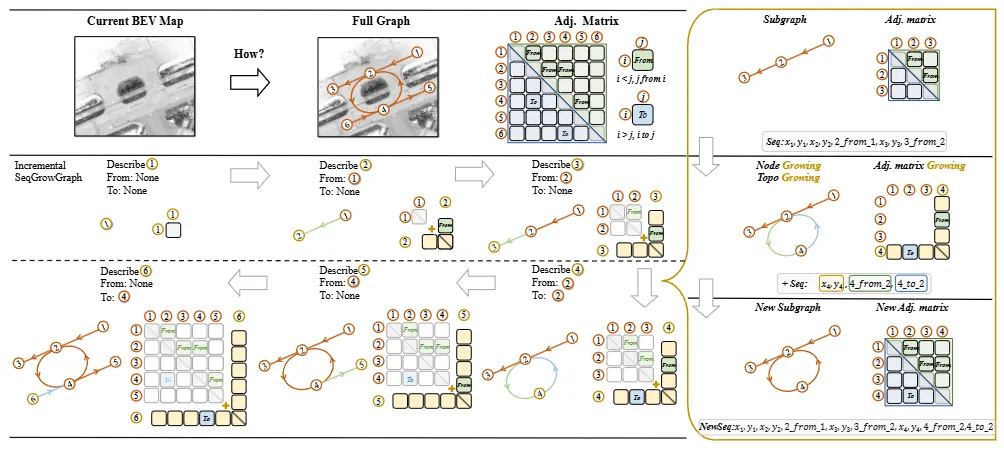
机构:阿里巴巴集团 高德地图;西安交通大学
亮点:这篇论文致力于解决自动驾驶高精地图构建中复杂车道拓扑结构难以统一建模的根本挑战,提出了一种新颖的“逐步生长”式图生成框架SeqGrowGraph。该方法将车道拓扑建模为一个自回归的图扩张过程:模仿人类绘图习惯,模型每一步只预测新增的一个拓扑节点及其与现有节点的连接关系,并利用二次贝塞尔曲线参数化车道几何。通过深度优先顺序将图生成序列化,使得Transformer能够有效处理这一动态结构。该框架统一且稳健地学习了车道连接与几何形状,在nuScenes与Argoverse2数据集上取得了领先性能。
链接:https://arxiv.org/pdf/2507.04822
后台私信0104,免费领取自动驾驶顶会论文合集
2025 年前后的自动驾驶技术演进,正在经历一场从“单点极致”向“系统智能”的深刻质变。其演进主线愈发清晰:
无论是地图构建(MapDiffusion)、轨迹预测(CRiTIC)还是未来场景预测(LOPR),研究不再满足于输出一个脆弱的“唯一答案”,而是致力于生成多种合理假设并明确其不确定性,为后续规划提供关键的“风险地图”。
针对端到端规划中的“抖动”(MomAD)、闭环仿真中的因果混淆(CAFE-AD)、以及环境扰动带来的影响,研究者们系统性地引入历史连续性约束、注意力筛选、在线自适应等机制,确保智能体在长时序交互中行为一致、可靠。
“轻量化”与“可部署性”成为关键设计准则,这体现在利用蒸馏减少标注依赖(EFFOcc)、设计稀疏高效架构(SSF)、以及推动大模型在车端实时运行(Enhancing AD with On-Board LLMs)等多个层面。研究正从“证明有效性”转向“证明可应用性”。
世界模型从视频生成器升级为具备长时预测与规划能力的引擎(Epona, World4Drive);仿真技术致力于生成更真实、更危险的交互场景(IntSim)以锤炼系统。这表明,感知、预测、规划与仿真正在一个统一的“世界模型”框架下走向深度融合。
技术不息,探索不止。
如果你觉得这篇盘点对你有启发,欢迎点赞、在看,并分享给身边在这个领域一同探索的朋友。
审编|阿蓝

商务推广/稿件投递请添加:xinran199706(备注商务合作)


· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇


