题目:Rethinking the Spatio-Temporal Alignment of End-to-End 3D Perception论文:https://arxiv.org/pdf/2512.23635代码:https://github.com/lixiaoyu2000/HAT一、文章所属的研究方向
研究方向:
自动驾驶(Autonomous Driving, AD)
端到端三维感知(End-to-End 3D Perception)
多摄像头 3D 目标检测与多目标跟踪(3D Detection & MOT)
时空对齐(Spatio-Temporal Alignment, STA)
运动建模与目标级时间建模
该工作位于计算机视觉 + 自动驾驶感知系统交叉领域,重点解决端到端感知框架中历史信息如何有效对齐到当前帧这一核心问题。
二、研究背景
在自动驾驶感知系统中: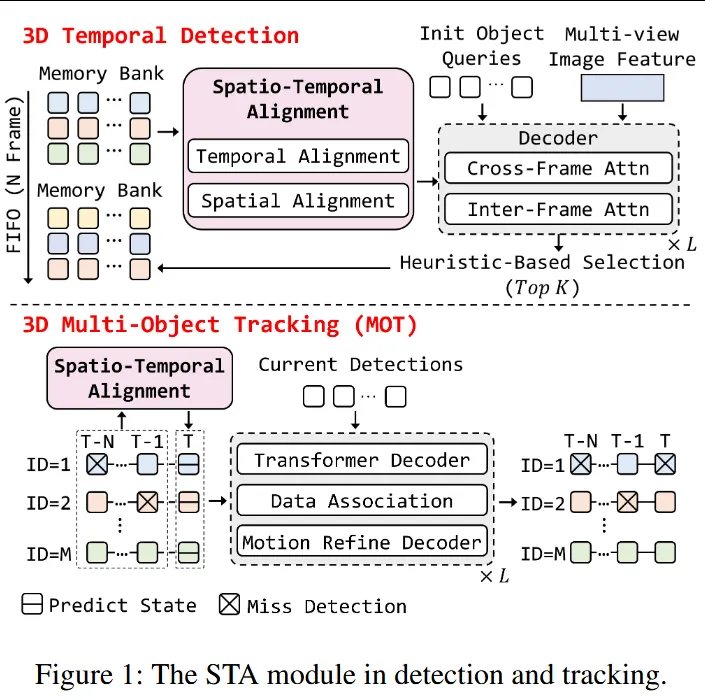
时间建模至关重要多摄像头 3D 检测与跟踪普遍依赖历史帧信息,通过 memory bank 和 query propagation 进行时序增强。
现有 STA 方法的局限性
真实世界中目标运动 类别相关、时间变化显著
单一运动假设难以覆盖复杂动态
过度依赖语义特征,弱化了显式运动建模
依赖 注意力机制进行隐式对齐
使用 单一显式运动模型(如匀速模型 CV)
传统模块化方法的矛盾
Kalman / IMM 等方法具备多模型能力
但需要人工调参、泛化性差
难以融入端到端体系
核心问题:
如何在端到端感知中,既保留显式运动模型的物理合理性,又避免传统方法的脆弱与人工干预?
三、研究方法(HAT 模块)
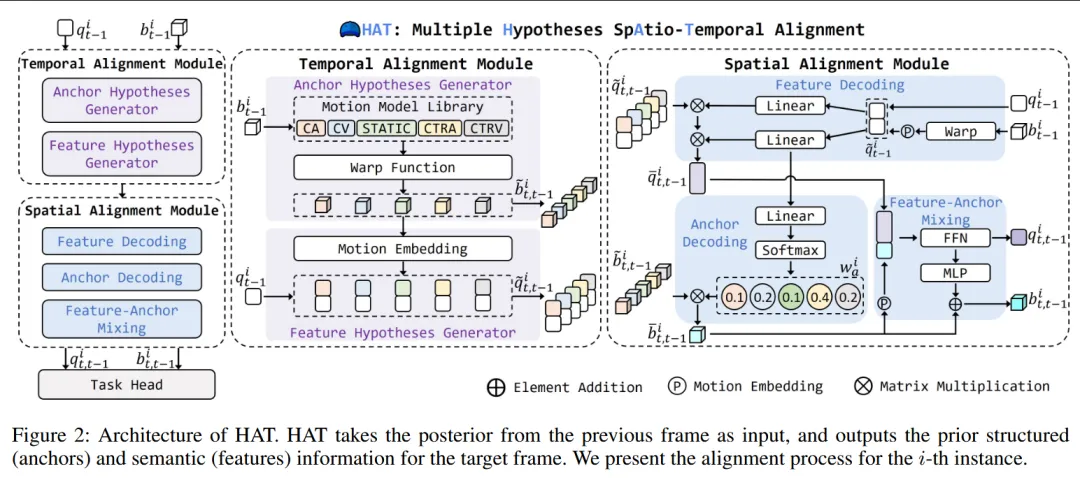
作者提出 HAT(Hypotheses spAtio-Temporal alignment),一种多假设时空对齐模块,核心思想是:
用多个显式运动模型生成候选对齐假设,再通过网络自适应地选择最优假设。
1. 总体框架
HAT 是一个 可插拔(plug-and-play)STA 模块,位于:
整体分为两个阶段:
2. Temporal Alignment Module(时间对齐模块)
目标:生成多种运动假设
(1) 多运动模型库(Motion Model Library, MML)
包含 5 种经典物理模型:
这些模型覆盖了:
(2) 多 Anchor 假设生成
(3) 多 Feature 假设生成
3. Spatial Alignment Module(空间对齐模块)
目标:从多假设中选择“最优对齐结果”
包含三步:
(1) Feature Decoding
根据历史 query 生成动态权重
对多假设特征进行加权融合
自适应选择更符合当前运动状态的特征
(2) Anchor Decoding
类似 IMM(交互多模型滤波)
使用 softmax 学习各运动模型权重
加权求和得到最优 anchor
(3) Feature–Anchor Mixing
融合最终特征与 anchor
通过 FFN + MLP 进一步细化
输出对齐后的先验信息
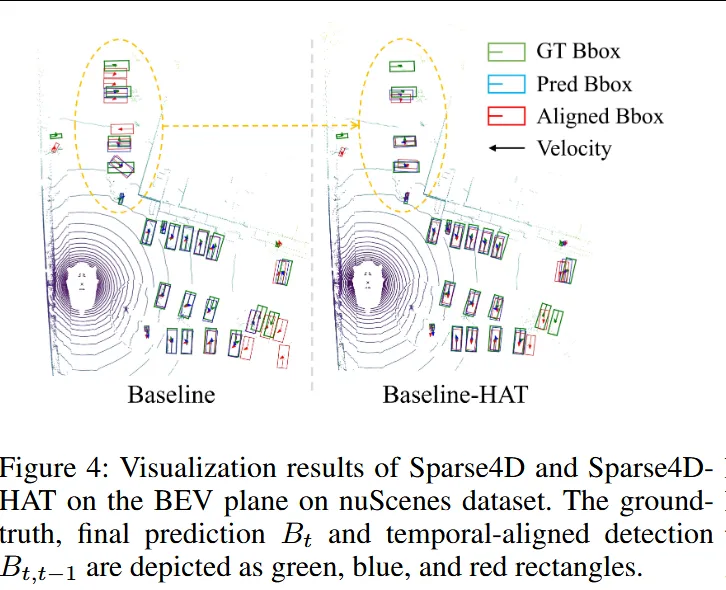
四、实验结果与性能表现
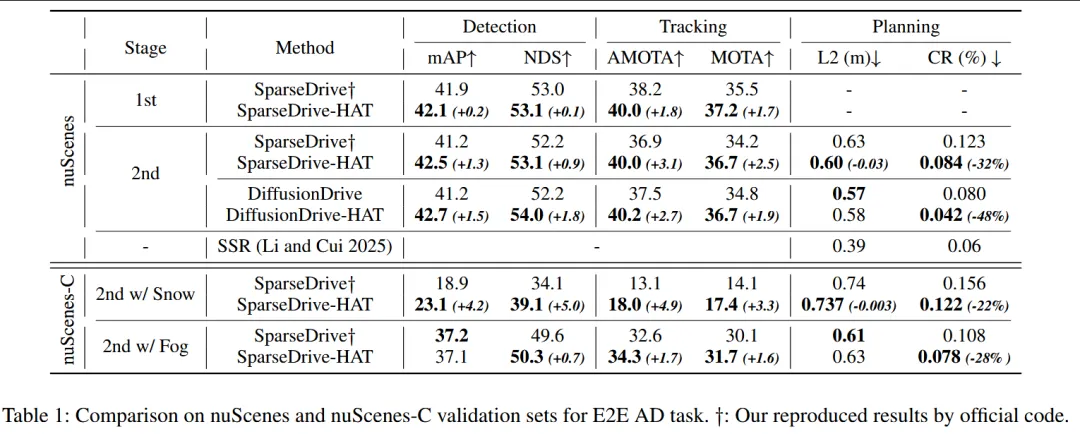
1. 3D 检测与跟踪(nuScenes)
检测任务
+0.5% ~ +0.9% mAP
+0.7% ~ +0.9% NDS
跟踪任务
+1.3% AMOTA(验证集)
46.0% AMOTA(测试集,SOTA)
2. 端到端自动驾驶(E2E AD)
在 SparseDrive / DiffusionDrive 中:
感知精度显著提升
碰撞率下降 32% ~ 48%
规划轨迹更稳定、更安全
3. 鲁棒性(nuScenes-C)
在雪雾等语义退化场景下:
4. 计算代价
仅增加 约 7 ms / 帧
性能–效率比极高,具备工程可行性
五、总结(作者核心观点)
运动建模在端到端感知中仍然不可或缺
单一运动假设无法覆盖真实世界动态
多假设 + 自适应选择是 STA 的更优范式
HAT 成功融合:
在检测、跟踪、规划多任务中均展现出强泛化能力
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~本文仅做学术分享,如有侵权、笔误等,请联系修改、删文。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
