25年12月来自中山大学(深圳校区)、西湖大学、理想汽车、多伦多大学、澳门大学和字节Seed的论文“OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving”。
自动驾驶技术取得显著进展,这主要得益于大量的真实世界数据收集。然而,获取多样化且包含极端情况的数据仍然成本高昂且效率低下。生成模型通过合成逼真的传感器数据,成为一种极具前景的解决方案。然而,现有方法主要专注于单模态数据生成,导致多模态传感器数据生成效率低下且存在不一致性。为了解决这些挑战,本文提出 OmniGen,它在一个统一的框架下生成对齐的多模态传感器数据。其方法利用共享的鸟瞰图(BEV)空间来统一多模态特征,并设计一种通用多模态重建方法 UAE,用于联合解码 LiDAR 和多视角相机数据。UAE 通过体渲染实现多模态传感器解码,从而实现准确灵活的重建。此外,引入带有 ControlNet 分支的 Diffusion Transformer (DiT),以实现可控的多模态传感器生成。全面的实验表明,OmniGen 在统一的多模态传感器数据生成方面取得理想的性能,并展现出良好的多模态一致性和灵活的传感器调整能力。
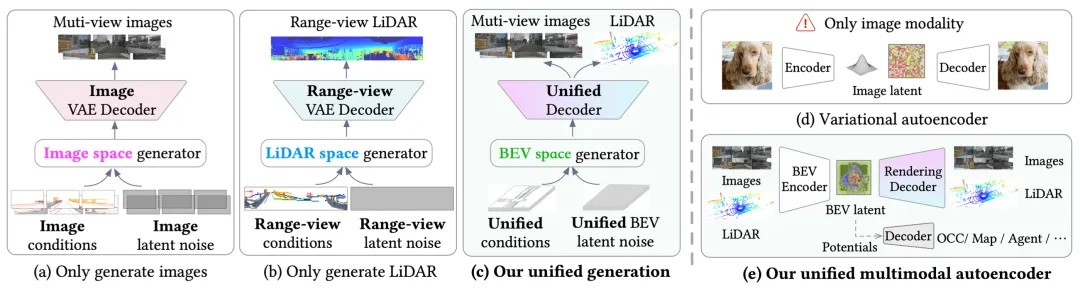
如图所示,现有的驾驶场景生成模型主要关注单模态传感器数据,而多模态数据的统一生成仍未得到探索。统一的多模态传感器生成具有诸多优势:提高效率——同时生成两种模态的数据可以省去单独的处理流程(例如数据处理、模型训练和模型更新);更好的传感器对齐——独立生成传感器数据难以在不同传感器之间进行对齐,这使得下游的多模态模型难以有效利用这些数据。然而,实现统一的多模态生成也面临着巨大的挑战。相机生成模型在图像潜空间中运行,其中条件被投影到透视图像视图中;而 LiDAR 生成模型则在距离视图潜空间中生成数据,并相应地投影条件。将这些不同的生成空间融合到一个统一的表示中,同时确保其在统一条件下可控,是一个非同寻常的难题。
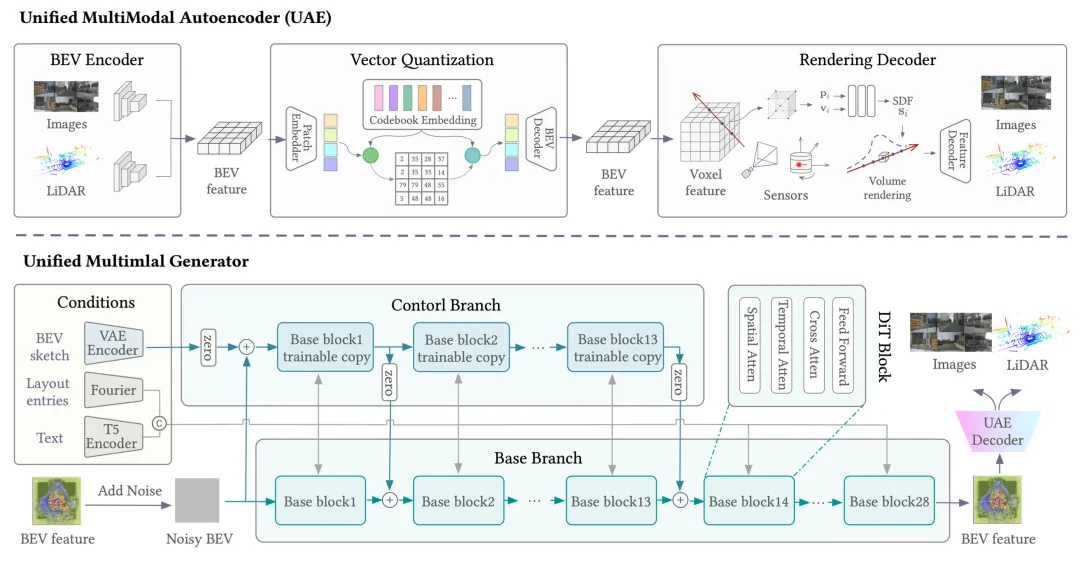
OmniGen 是一种用于自动驾驶的统一多模态传感器生成框架。将问题分解为几个关键步骤,可解决统一传感器生成方面的挑战:1)建立统一的表示空间:受先前多模态感知研究(例如 BEVFusion [30])的启发 [29, 36],将多模态特征统一到一个共享的鸟瞰图 (BEV) 空间中,该空间提供全局场景上下文,并与文本描述或道路草图等条件良好地对齐。2)从统一的 BEV 空间解码多模态传感器数据:借鉴可泛化的 NeRF 方法(例如 PixelNeRF [76]),利用体渲染来渲染传感器数据。得益于统一的 BEV 表示,本文提出 UAE,这是一个用于自动驾驶场景的可泛化 LiDAR-相机多模态重建方法。3) 生成多模态传感器数据的潜鸟瞰图(BEV)特征:为了使生成模型能够生成多模态传感器数据,用矢量量化(VQ)模块增强统一自编码器(UAE),并将其用作统一生成的多模态自编码器。对于生成模型,采用 ControlNet-Transformer 架构,该架构将 ControlNet 集成到强大的 Diffusion Transformer (DiT) 模型中。
如图所示,OmniGen 模型由一个多模态自编码器和一个多模态生成器组成。多模态自编码器 UAE 首先将相机和 LiDAR 传感器数据编码到统一的鸟瞰图 (BEV) 空间,然后通过体渲染将统一的 BEV 特征解码为多模态传感器数据。多模态生成器采用 ControlNet-Transformer 架构,该架构将 ControlNet 集成到 Diffusion Transformer (DiT) 模型中,从而实现精细且精确的控制。给定文本描述、BEV 路况草图和 3D 边框作为场景条件输入,生成器能够有效地生成所需的潜 BEV 特征。
将 Control-Net [78] 分支集成到 DiT 模型中,以实现道路草图条件控制。受 PixArt-δ [6] 的启发,创建模型前 13 个块的可训练副本。这些复制的块通过可学习的零线性层与相应的基本块集成。每个复制的块都结合道路草图特征,从而确保能够根据提供的草图条件进行精确控制。
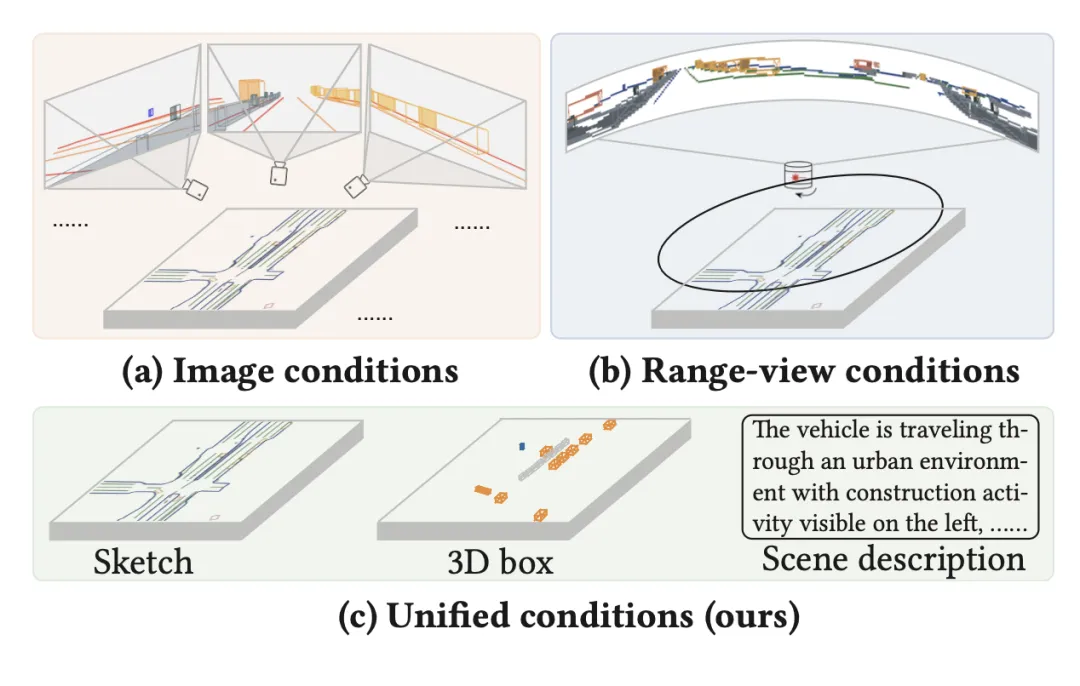
如图所示,与以往依赖于特定模态条件的方法不同,方法采用统一的条件来生成对齐的多模态传感器数据。具体而言,场景条件 S = {M, B, T} 包括道路草图 M ∈ {0, 1},表示 BEV 视角下的道路区域,包含 𝑐 个语义类别;3D 边框 B = {(b_𝑖, h_𝑖, l_𝑖, c_𝑖)},其中每个对象由边框 b_𝑖 ={(𝑥_𝑗,𝑦_𝑗,𝑧_𝑗)}、航向角 h_𝑖 ∈[−180,180)、实例 ID l_𝑖 ∈ [0, 1] 和描述 c_𝑖 ∈ C 组成;以及文本描述 T,用于概括整个场景的信息(例如,天气和时间)。布局条目,即实例细节(例如边框坐标、航向角和 ID),由傅里叶嵌入器 [41] 𝐹 进行编码,然后连接起来并通过 MLP 处理成统一的嵌入向量。文本输入使用 T5 [46] 语言模型 𝐸_T5 编码为 200 个 token。道路草图通过预训练的 VAE 模型 𝐸_VAE 提取潜特征。
将这些条件嵌入向量通过交叉注意机制集成到 DiT 模型中,从而实现灵活且精细的控制。道路草图功能集成到复制的模块中。
借助 LDM [83] 的最新进展,将 IDDPM [43] 替换为修正流 [34],以提高稳定性和减少推理步骤。修正流定义数据分布和正态分布之间的前向过程。
此外,将无分类器引导(CFG)[17]策略从文本条件扩展到3D边框和道路草图,以提高控制精度和视觉质量。CFG旨在增强生成图像与指定条件之间的匹配度,它在训练过程中同时执行条件去噪和无条件去噪,并在推理过程中结合两种估计的分数。在实践中,在训练期间以5%的概率随机将每个条件设置为无效值𝜙。引导尺度𝜆𝑀、𝜆𝐵、𝜆𝑇控制采样结果与条件之间的匹配程度。受IP2P [1]的启发,将无条件去噪结果分别应用于每个条件。
未来工作
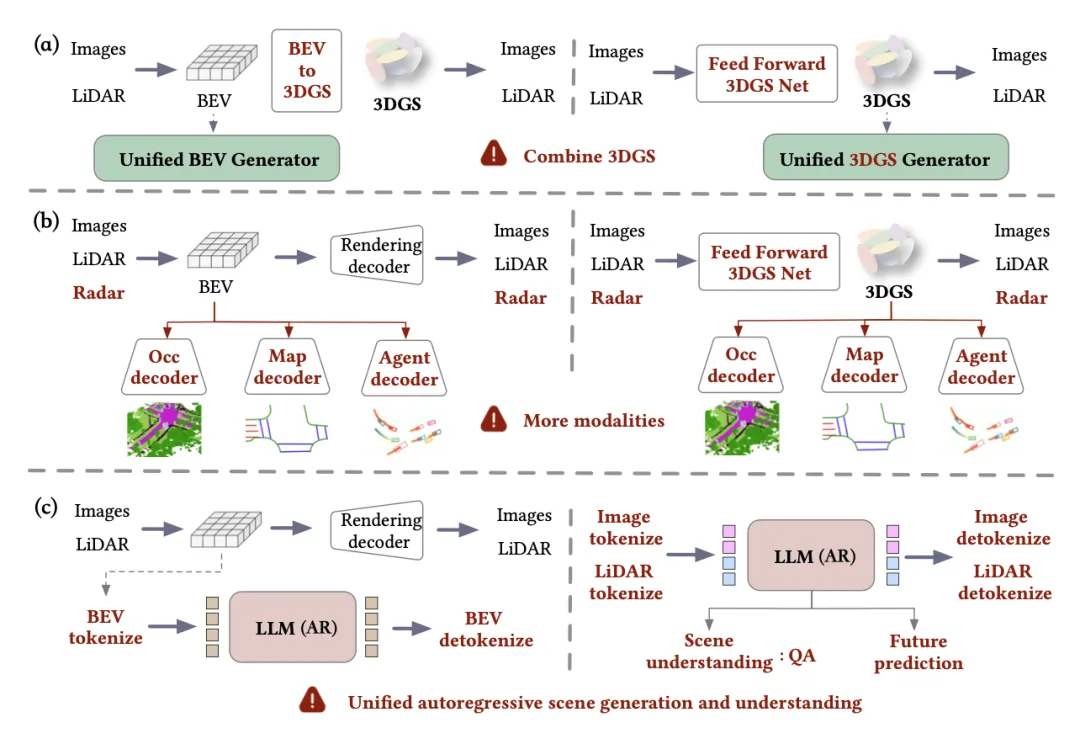
如图所示,得益于统一的框架,仍有许多值得探索的方向:
• a) 本文采用基于 NeRF/SDF 的渲染技术。然而,方法可以轻松扩展,以集成更先进的渲染方法,例如 3DGS。例如,如图左侧所示,可以集成一个 BEV 到 3DGS 的模块,如 [68, 77] 所示。或者,如图右侧所示,可以采用前馈 3DGS 设计,如 [9, 52] 所示,然后接一个 3DGS 生成器,例如 [31, 84]。
• b) 统一的 BEV 空间具有显著的可扩展性,可以轻松扩展到其他传感器,例如雷达。此外,它可以应用于以前由 BEV 表示支持的其他任务,例如占用率预测或生成 [58]、高清地图 [10] 或智体轨迹 [28]。这些任务可以通过简单地将相应的解码器连接到 BEV 或 3DGS 表示来实现。整合多个 BEV 支持的任务可以丰富和增强特征的鲁棒性,但同时也可能增加复杂性,引入诸如任务对齐和模态干扰等挑战。
• c) 目前,方法使用扩散模型进行生成。受 Emu3 [59] 等自回归模型的启发,还可以利用大语言模型 (LLM) 进行统一生成。这可以通过重用UAE 模块或直接对多模态传感器输入进行token化以进行交互来实现。使用 LLM 的优势在于它们能够进一步统一场景生成和理解,如 [54, 85] 所示,从而支持问答 (QA) 等任务。
基线。1) 对于可泛化的 LiDAR-相机重建,即 UAE,由于目前没有可泛化的 LiDAR 或多模态方法,将模型与最先进的可泛化相机重建方法进行比较,例如 SelfOcc [22]、UniPAD [20] 和 Distill-NeRF [55]。2) 对于多模态传感器生成,将模型与之前的单模态生成方法进行比较。对于相机传感器生成,与最先进的相机生成方法 MagicDrive [12]、DriveDreamer [57] 等进行比较。对于 LiDAR 传感器生成,与最先进的 LiDAR 生成方法 LiDARGen [88]、RangeLDM [19] 和 LidarDM [89] 进行比较。3) 对于下游任务,在流行的 BEV 检测模型(BEVFusion [36] 和 BEVFormer [29])和规划模型(UniAD [20] 和 FusionAD [75])上评估模型,以分析生成数据与真实世界数据之间的仿真-到-现实差距。
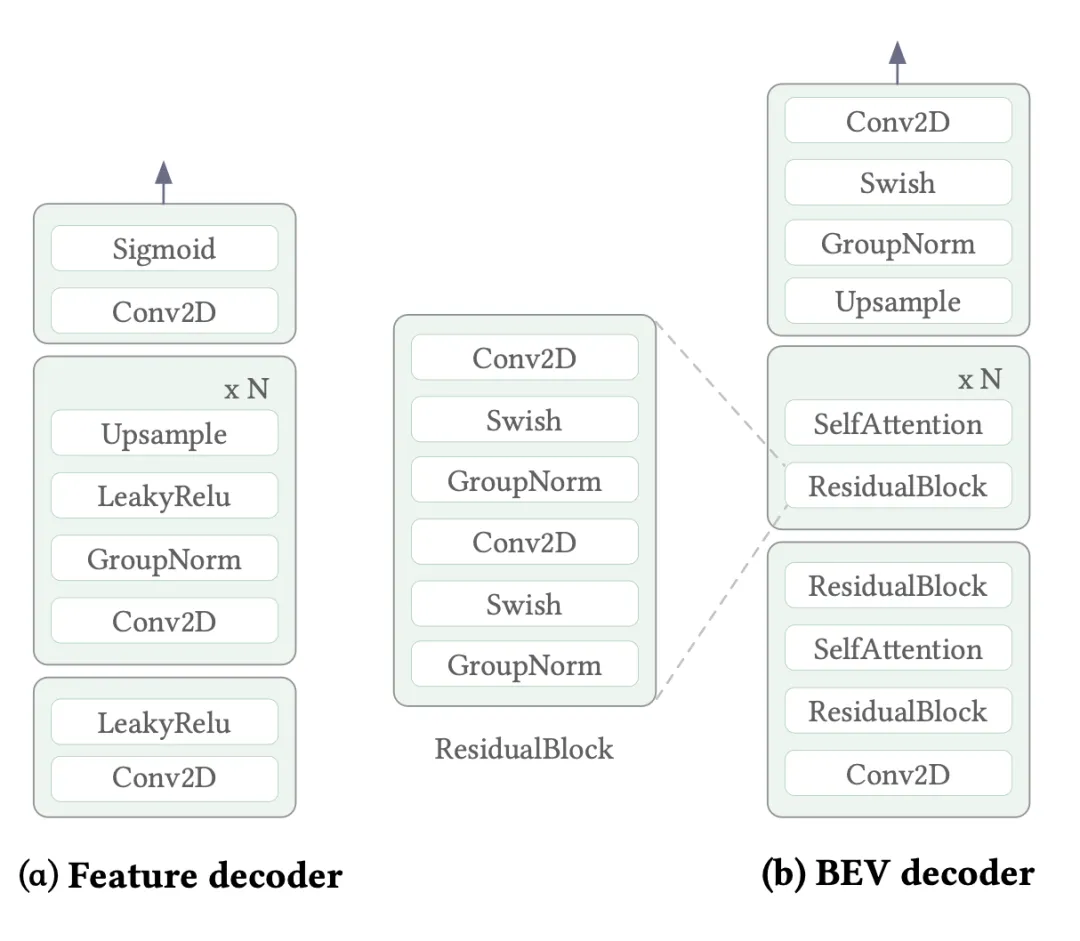
实现细节。1) 对于可泛化的 LiDAR-相机重建,即 UAE,代码基于 UniPAD [20]。分别使用 ConvNeXt-s [35] 和 VoxelNet [70] 作为默认的相机和 LiDAR 编码器。输入图像尺寸为 1600 × 900,体素化尺寸为 [0.075, 0.075, 0.2]。跨模态构建尺寸为 [0.6, 0.6, 1.6]、形状为 180 × 180 × 5 的统一体素表示。对于向量量化,遵循 [81],使用 BEV 块大小 𝑃 = 2 和码本大小 𝐾 = 512,维度为 𝐸 = 8。对于块嵌入器,用两个 3×3 卷积模块,通道数为 64 和 128。BEV 解码器的详细结构如图 (b) 所示。还使用衰减系数为 0.99、epsilon 值为 1e-5 的指数移动平均 (EMA) 来更新码本嵌入。对于渲染解码器,用一个 6 层的 MLP 来处理 SDF,详细的特征解码器如图 (a) 所示。在渲染阶段,每条光线采样 𝑁 = 192 个点。训练时,用 AdamW 优化器训练 UAE 24 个 epoch,初始学习率为 2e-4。还采用余弦学习率衰减策略,并在前 500 步进行预热。2) 对于多模态传感器生成,代码基于 OpenSora [83]。模型使用 AdamW 优化器进行优化,学习率为 1e-4,训练 3 万步,并包含 1500 步的预热。推理时,用 30 步的修正流进行采样,并将 𝜆𝑇、𝜆𝑀 和 𝜆𝐵 分别设置为 1.0、2.0 和 2.0。所有模型均在 8 块 NVIDIA A100 (80G) GPU 上进行训练。