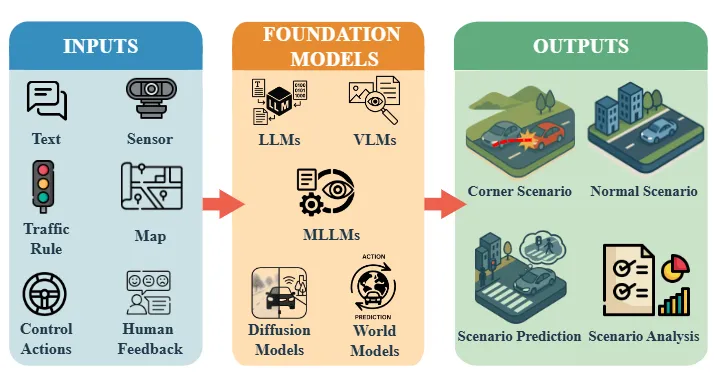
6❓ 核心QA(基于论文综述内容)
Q1:五大基础模型的核心区别与选型逻辑是什么?
A1:LLM擅长文本驱动生成/语义分析,适合脚本生成/风险评估;VLM聚焦图文对齐,适配视觉相关任务;MLLM支持多传感器融合,用于复杂场景理解;DM主打高保真可控生成;WM擅长环境动力学建模,适配闭环仿真。选型需匹配“输入模态-任务类型(生成/分析)-精度需求”。
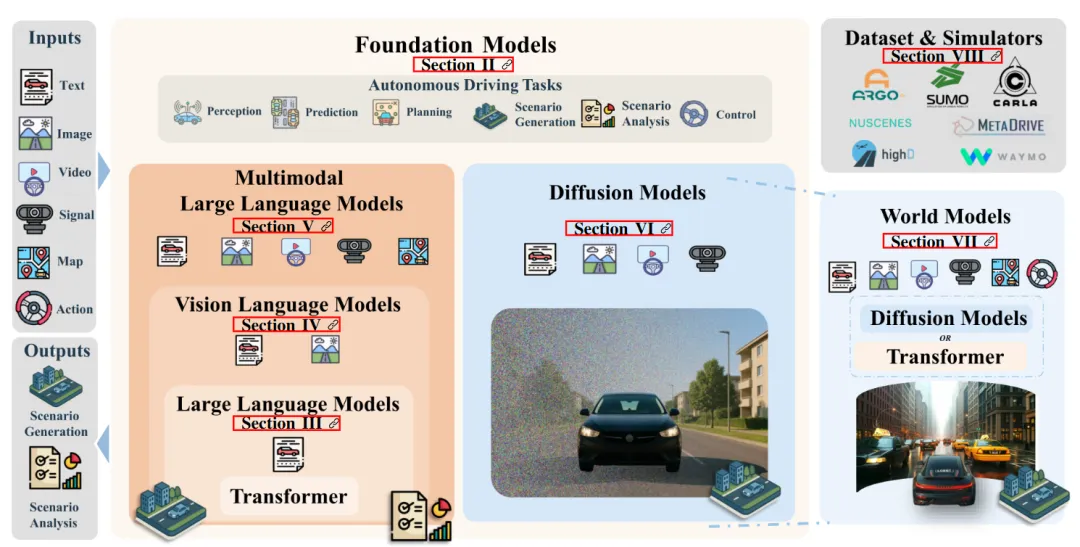
Q2:基础模型应用的核心挑战是什么?
A2:三大核心挑战:1)多模态数据稀缺(LiDAR/RADAR+文本标注不足);2)评估标准不统一(缺乏场景“真实性/安全性”量化指标);3)计算成本高(训练需16×A100 GPU,端侧部署难)。
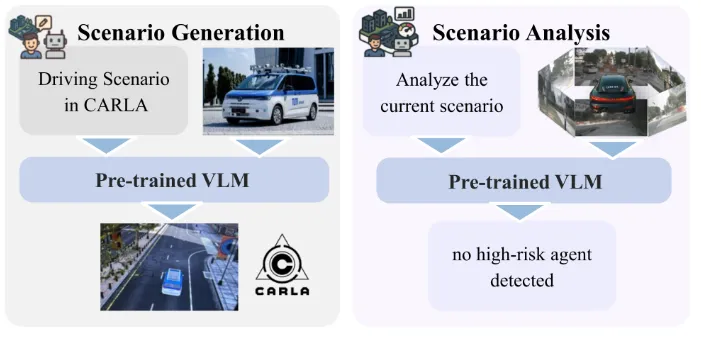
Q3:如何解决罕见场景生成难题?
A3:两种核心路径:1)LLM+DM联动(LLM生成场景描述,DM转化为高保真视频);2)WM“梦境生成”(基于训练的环境动力学,合成未见过的安全临界场景);3)MLLM+反事实推理(修改现有场景参数生成罕见变体)。
Q4:工业落地的关键适配步骤是什么?
A4:1)数据层:选择nuScenes等真实数据集预训练,补充合成数据增强多样性;2)模型层:用LoRA微调适配特定场景,降低计算成本;3)工具层:集成CARLA/SUMO自动执行场景脚本;4)评估层:结合FID(生成)+TTC(安全)+人工校验(可解释性)。


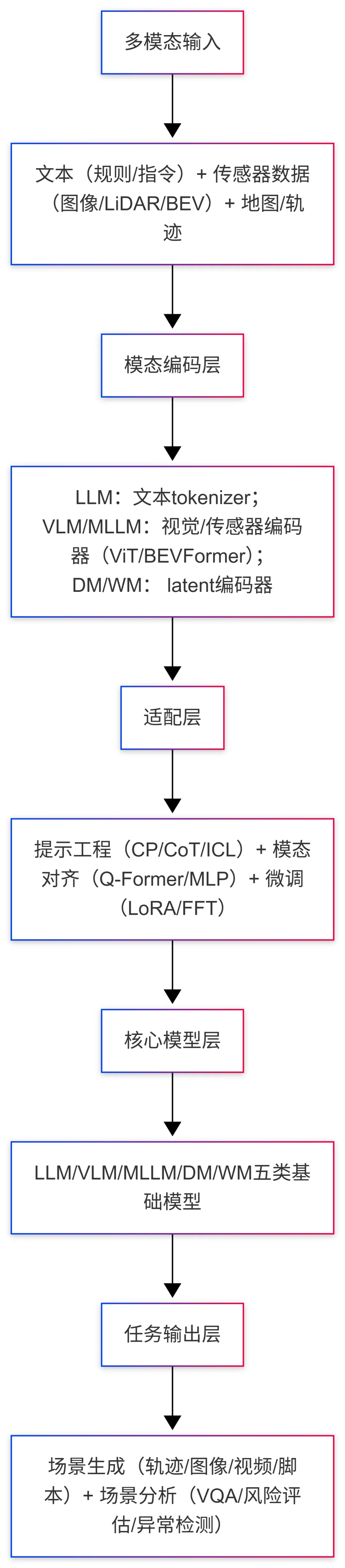

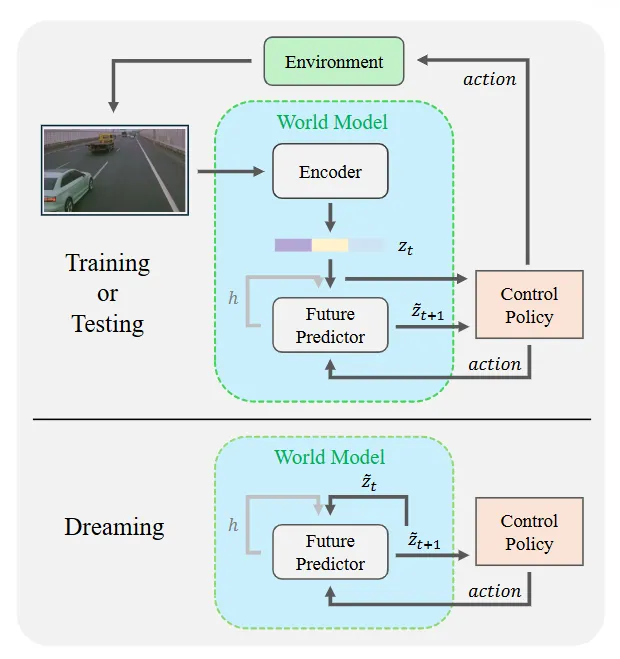
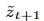 是对下一时间步潜在表示的预测,并且h是编码过去信息的隐藏状态。在梦境阶段(底部),模型以自回归的方式生成未来的潜在变量
是对下一时间步潜在表示的预测,并且h是编码过去信息的隐藏状态。在梦境阶段(底部),模型以自回归的方式生成未来的潜在变量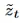 :
: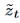 由
由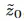 初始化,然后递归地反馈作为未来预测器的输入,该预测器计算下一个值。
初始化,然后递归地反馈作为未来预测器的输入,该预测器计算下一个值。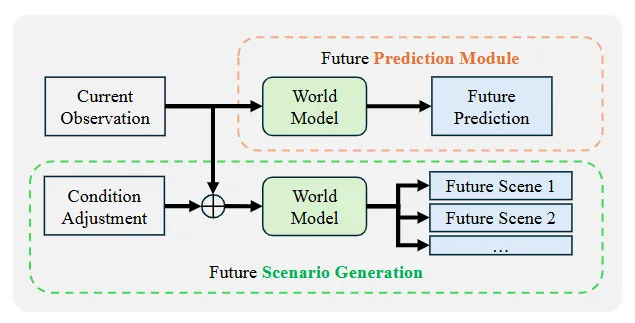
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
