小编观点
这篇论文解决的,是端到端自动驾驶模型中可解释性与安全性缺失的核心难题。
目前的 VLA 模型(如 RT-2 或各类 AD-VLA)大多是“直觉反应式”的:输入图像,直接输出轨迹。模型往往只描述“我看到什么”和“我要做什么”,却从来不问自己“我这样做安全吗?”或“如果我这样做会发生什么?”。这种缺乏反事实推理(Counterfactual Reasoning)的机制,导致模型在遇到复杂长尾场景时容易犯低级错误。
它的方法链路很清晰:输入端接收多视角视频帧与导航指令 → 元动作生成(Meta-Action Generation) 初步规划高层意图(如“加速”、“变道”) → 反事实推理(Counterfactual Reasoning) 结合视觉上下文反思初始计划的安全性(“如果现在变道会不会撞车?”) → 动作修正(Action Revision) 若发现风险则生成修正后的元动作 → 轨迹生成(Trajectory Generation) 输出最终的安全轨迹。
这套方法成立依赖两个关键工程假设:
- 分层推理更有效:直接反思高维的轨迹坐标很难,但反思高层的“元动作”(如加速/减速、左转/右转)则容易得多且符合人类逻辑。
- 数据可挖掘:通过对比模型生成的“错误计划”和人类专家的“正确操作”,可以自动构建海量的“反思-修正”数据对,教会模型如何自我纠错。
一句话点评:CF-VLA 为自动驾驶大脑装上了“前额叶”,让它在踩下油门之前,先在脑海里预演一遍后果,真正实现了从“条件反射”到“深思熟虑”的跨越。
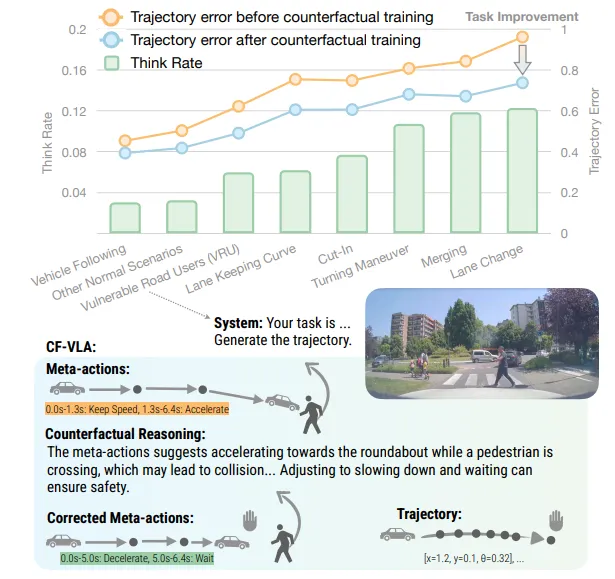
图 1 :CF-VLA 核心理念与反思流程
这张图直观展示了 CF-VLA 的核心差异:
- Top (Adaptive Reasoning) :模型并非在所有时刻都“思考”,而是在遇到高难度的复杂场景(Complex Scenarios)时,自动触发推理模式。
- Bottom (Self-Reflection) :模型首先生成一个初始计划(Initial Plan),然后进行自我批判(Critique),发现风险后输出修正计划(Revised Plan),最后才执行。
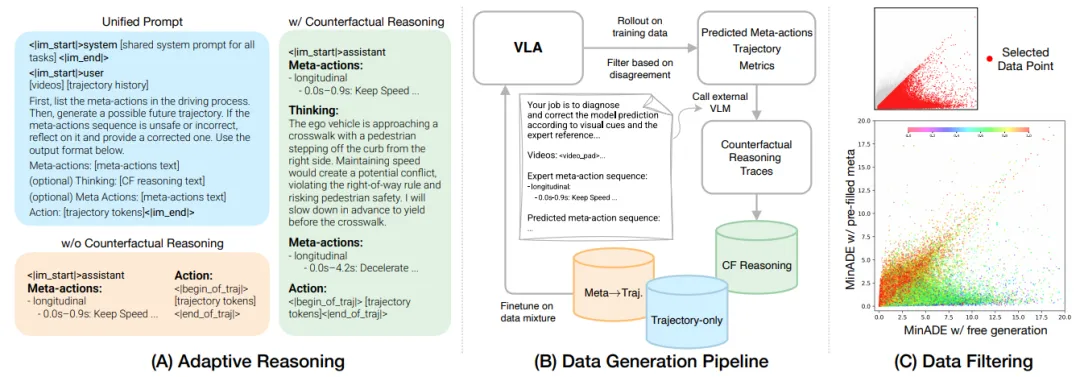
具体算法实现细节
CF-VLA 的核心在于将“反事实推理”嵌入到了 VLA 的推理闭环中。其实现聚焦三个关键模块:自适应推理架构(系统设计)、数据生成管线(数据源)、元动作定义(表征层)。
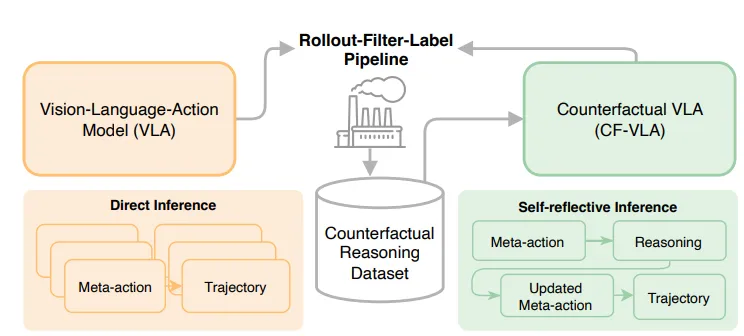
图 2 :CF-VLA 系统整体架构
这张图详细拆解了 CF-VLA 的工作流:
- Base VLA:基于 LLaVA 等 VLM 构建,输入视频和文本。
- Step 1: 预测 Meta-Actions(时间分段的高层指令,如 0-3s 等待,3-6s 加速)。
- Step 2: 进行 Reasoning。模型基于当前图像和 Step 1 的计划,生成一段推理文本(Thinking Trace),分析潜在风险。
- Step 3: 输出 Revised Meta-Actions。
- Step 4: 基于修正后的元动作,解码出最终的 10Hz 轨迹点。
关键模块一:Rollout-Filter-Label 数据生成管线
这个模块解决的是“反思数据从哪来”的问题。
- 痛点:缺乏大规模的“错误计划 -> 修正逻辑”配对数据。
- Rollout(预演):让未微调的基础 VLA 模型在海量场景中自由生成“初始元动作”。
- Filter(筛选):将生成的元动作与 Ground Truth(人类专家)对比。利用轨迹不一致性(Trajectory Disagreement)筛选出那些“模型犯错”的高价值样本。
- Label(标注):将“场景视频”、“错误的初始动作”和“正确的人类动作”喂给强大的教师模型(如 Gemini-1.5-Pro),要求其生成一段反事实推理文本,构建出高质量的 CF Reasoning Dataset。
图 3 :数据生成与筛选流程
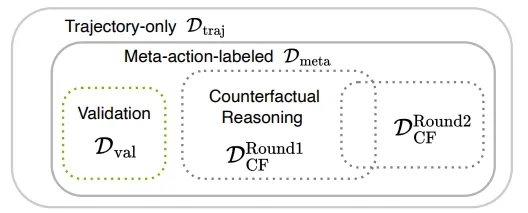
关键模块二:数据集构成与验证
这个模块确保了模型训练的基石稳固。
- 图表展示了数据集的组成结构。除了基础的元动作数据(),CF-VLA 重点构建了反事实推理数据集()。
- 这种精细的数据划分确保了模型不仅能学会“怎么开”,还能学会“为什么这么开”。
图 4 :数据集构成分析
实验结果与性能分析
实验平台
- 数据集:nuScenes(开环测试)和 NAVSIM(闭环仿真测试)。
- 指标:L2 误差、碰撞率(Collision Rate)、违规率。
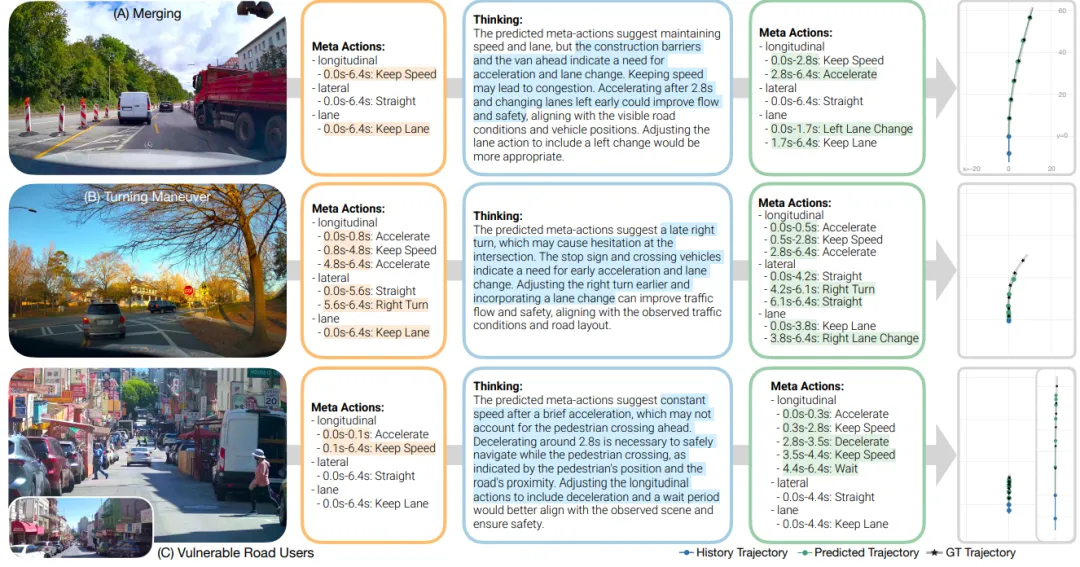
图 5 :开环测试定性结果展示 (Qualitative Results)
这张图展示了模型在三个安全关键场景下的表现:
- 核心逻辑:每一行展示了 Initial Meta-Actions(左) -> Reasoning Trace(中) -> Updated Meta-Actions(右) 的完整修正过程,生成的绿色轨迹明显比初始的橙色轨迹更安全。
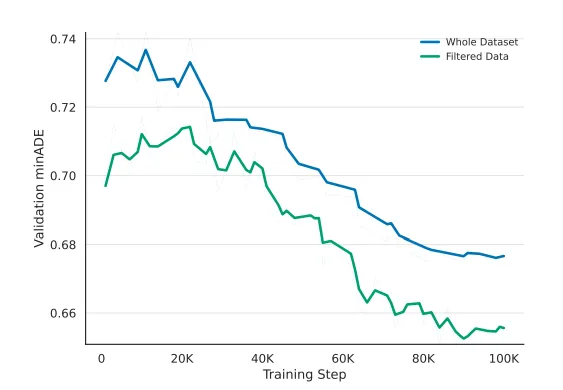
图 6 :反事实数据过滤策略的定量影响
这张折线图(Training Curve)用定量数据回答了一个核心问题:“是不是让模型反思得越多越好?” 答案是否定的。
- Whole Dataset(全量数据,蓝线):如果强迫模型对所有简单场景都进行“反思”,引入的无效梯度噪声反而会导致误差(Validation minADE)居高不下,收敛缓慢。
- Filtered Data(筛选数据,绿线):仅使用通过 Rollout-Filter-Label 管线 筛选出的“困难样本”(即模型真正犯错的场景)进行训练。结果显示,这种策略不仅收敛迅速,而且最终达到了最低的误差水平。
- 结论:“少即是多”。提升安全意识的关键不在于数据量的堆砌,而在于精准挖掘那些需要反思的“长尾关键场景”。