自动驾驶 | LISN: 基于视觉语言模型的语言指令社交导航系统技术解析
- 2026-06-25 01:56:59
自动驾驶 | LISN: 基于视觉语言模型的语言指令社交导航系统技术解析
1. 前言
在人机共存的真实社交场景中部署移动机器人,面临着一个根本性挑战:机器人不仅需要规划安全高效的路径、避免与行人发生碰撞,更需要真正理解人类通过自然语言表达的任务目标和社交规范。传统社交导航研究大多聚焦于路径效率与避障安全这些基础能力,却很少考察机器人是否能够理解"请小心地绕过老人""紧急送药到1B病房""跟随医生前往手术室"这类包含丰富语义信息和社交约束的自然语言指令。这一能力缺失使得当前机器人在医院、仓库、商场等复杂社交环境中的部署面临严峻挑战——机器人可能在技术层面完成了导航任务,却因忽视社交规范而造成不良的人机交互体验。
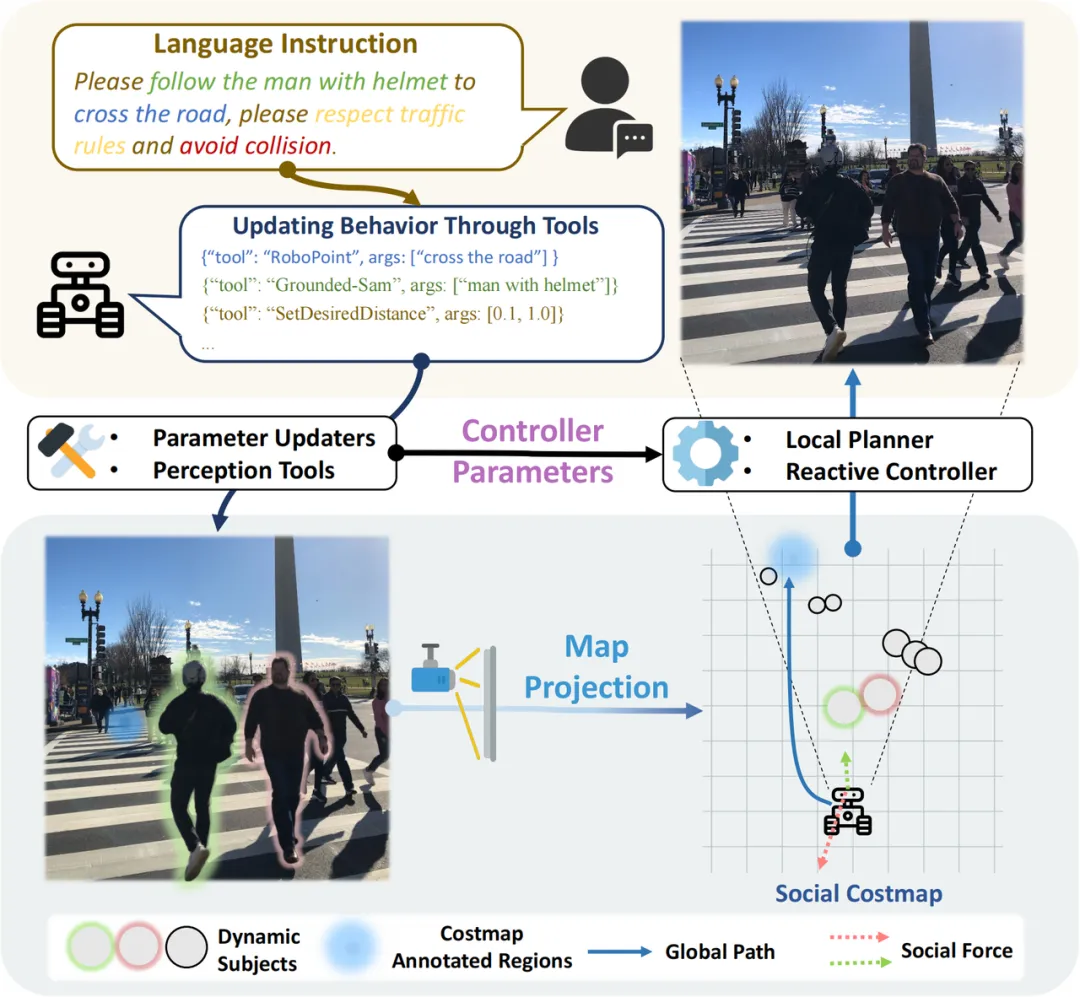
LISN(Language-Instructed Social Navigation)项目正是围绕这一核心目标展开深入研究。该项目创新性地提出了首个基于仿真环境的视觉语言指令社交导航任务与基准测试集LISN-Bench,为该领域的研究提供了标准化的评估平台。更重要的是,项目设计并实现了一个VLM驱动的快慢分层导航系统Social-Nav-Modulator,巧妙地解决了视觉语言模型推理速度慢(通常需要数秒)与高动态社交场景需要高频反馈控制(通常20Hz以上)之间的固有矛盾。本文将从技术原理、系统架构、核心代码实现等多个维度,结合tvss_nav开源代码库的实际实现,深入剖析LISN系统的设计思想与工程细节。项目主页位于https://social-nav.github.io/LISN-project/。
2. 问题背景与研究动机
2.1 现有社交导航研究的局限性
当前社交导航领域的研究主要存在以下三个方面的深层次不足,这些问题严重制约了机器人在真实社交环境中的部署能力:
第一,评测指标过于单一且偏重低层次性能。现有基准测试集如SEAN 2.0、SocNavBench、HuNavSim、Arena 3.0等,主要评估路径长度、行驶时间、与人类的最小距离等低层次指标。这些指标虽然对于衡量基础导航性能至关重要,但它们本质上只反映了机器人的运动学表现,无法捕捉机器人是否真正理解并遵循了用户通过自然语言表达的任务目标和社交规范。例如,一个机器人可能以最短路径到达目的地,但在途中忽视了"远离病房区域"的社交约束,这在现有评测体系中难以被有效识别和量化。
第二,缺乏语言理解能力的系统性评测。现有基准测试集很少涉及自然语言指令的理解与执行能力评估,无法检验机器人在接收到"跟随穿蓝色衬衫的人""远离病房区域""紧急前往叉车位置"等包含复杂语义信息和隐含社交约束的指令时的行为表现。这一缺失意味着我们目前缺乏有效手段来评估机器人将自然语言理解能力与导航决策相结合的综合能力,而这恰恰是实现真正智能社交导航的关键所在。
第三,仿真环境与真实控制存在显著差距。部分来自视觉语言导航(VLN)领域的基准测试集(如HA-VLN、Habitat 3.0)虽然引入了动态人类模型以增加场景复杂度,但它们通常采用回合制(turn-based)仿真模型,即智能体与环境元素轮流执行离散动作。这种仿真范式与真实机器人系统需要的连续实时控制存在本质差距——真实机器人需要以20Hz甚至更高的频率进行连续决策和控制,而非等待环境"回合"结束后再行动。
2.2 VLM导航的时域鸿沟
将大型视觉语言模型(VLM)应用于机器人导航面临一个根本性的技术挑战:推理速度与控制频率之间存在难以逾越的时域鸿沟。以GPT-4o为代表的前沿VLM模型,单次推理通常需要数秒甚至更长时间来处理复杂的视觉场景和语言指令。然而,在高动态社交场景中,机器人的反应式控制系统需要以20Hz甚至更高的频率运行,才能确保及时避让突然出现的行人或障碍物,保障人机交互的安全性。
这一矛盾的数学本质可以表述为:设VLM推理延迟为 ,典型值约为 ;而安全避障所需的控制周期为 ,典型值约为 (对应20Hz)。两者之间存在约两个数量级的差距,即 。这意味着在VLM完成一次推理的时间内,控制系统需要执行40-200次决策循环,期间环境状态可能发生显著变化。
现有的VLA(Vision-Language-Action)导航方法试图通过端到端的方式直接从视觉和语言输入生成控制动作,但即使采用经过优化的小型基座VLM,其控制频率也往往低于1Hz,远远无法满足动态环境的安全性要求。这一技术瓶颈促使LISN项目探索全新的系统架构设计思路。
2.3 LISN的核心目标
针对上述问题,LISN项目系统性地确立了三个相互关联的核心能力目标,这些目标共同构成了实现智能社交导航的完整能力框架:
1. 语言指令理解能力: 机器人需要具备理解用户通过自然语言表达的任务目标和社交规范的能力。这不仅包括对显式指令(如"前往接待台")的理解,还包括对隐含社交约束(如"紧急"暗示可以适度放宽某些安全限制)的推断能力。系统通过VLM的多模态理解能力实现这一目标,将抽象的语言描述转化为具体的导航参数调制策略。 2. 场景视觉语义理解能力: 机器人需要能够识别并理解场景中的关键社交实体和语义区域。这包括识别不同身份的人员(如医生、病人、工人)、关键物体(如轮椅、叉车、医疗设备)以及功能区域(如病房、公共区域、黄线标识的危险区域)。系统通过集成Grounded-SAM2等先进视觉分割模型,实现对场景的细粒度语义理解。 3. 动态人群中的安全导航能力: 机器人需要在高动态环境中实现实时避障和社交合规的导航行为。这要求系统能够以足够高的频率响应环境变化,同时将VLM的高层语义理解转化为低层控制决策。系统通过快慢分层架构实现这一目标,确保安全性与智能性的有机统一。
3. LISN任务定义与形式化描述
3.1 问题形式化
LISN将社交导航形式化为一个指令条件马尔可夫决策过程(Instruction-Conditioned MDP),这一数学框架能够优雅地将自然语言指令与传统导航决策过程相结合。给定自然语言指令 、RGB视觉输入 和激光雷达点云 ,机器人需要生成一系列控制动作 ,使其在动态社交环境中以符合语言指令和社交规范的方式完成导航任务。这里 表示线速度控制量, 表示角速度控制量,共同构成差分驱动机器人的运动学控制信号。
形式化表示为一个六元组:
其中各元素的详细定义如下:
• 是自然语言指令空间中的一条具体指令,包含任务目标和社交约束信息 • 是状态空间,包含机器人的运动学状态(位置、速度、朝向)以及基于传感器数据构建的局部动态代价图 • 是动作空间, 表示差分驱动机器人在时刻 的控制信号 • 是状态转移函数,描述机器人在执行动作后的状态变化 • 是条件于语言指令 的即时代价函数,这是LISN的核心创新点——代价函数的形式和参数由语言指令动态决定 • 是观测空间, 包含当前时刻的RGB图像和激光雷达扫描数据
这一形式化的关键洞察在于:通过将代价函数 设计为语言条件的,系统可以将抽象的社交规范(如"小心""紧急""远离")转化为具体的代价权重调整,从而在不改变底层规划算法的前提下实现语义感知的导航行为。
3.2 四种基本导航模式
LISN系统识别并定义了移动机器人在社交场景中应当执行的四种基本导航模式,这些模式沿两个正交的语义维度展开,形成完整的行为空间覆盖:
维度一:目标类型(Target Type)
• 行人(动态目标): 具有动态空间位置的移动个体或群体,其位置随时间变化,需要持续追踪 • 区域(静态目标): 指令中明确或隐含提及的环境区域,如禁区、目的地、功能区等,具有固定的空间边界
维度二:行为关系(Behavioral Relation)
• 接近(Approach): 机器人被指示靠近目标实体或区域,表现为降低与目标的距离 • 规避(Avoid): 机器人被指示远离目标实体或区域,表现为维持或增加与目标的距离
将这两个维度进行笛卡尔积组合,形成四种基本导航模式,每种模式对应特定的代价图配置策略:
值得注意的是,实际任务通常涉及多种模式的组合。例如,"跟随医生递送器械"任务同时涉及行人跟随(跟随医生)和行人规避(避让途中其他行人),系统需要协调这些可能存在冲突的行为目标。
3.3 LISN-Bench基准测试集
LISN-Bench是首个专门面向语言指令社交导航的仿真基准测试集,基于Arena 3.0平台构建。该基准测试集的设计充分考虑了真实社交导航场景的复杂性,提供了丰富的语义标注和多样化的评测任务,具有以下核心特点:
场景设计: LISN-Bench覆盖了医院、仓库等典型社交场景,这些场景具有高度的实际应用价值和丰富的社交交互模式。每个场景都提供了详尽的语义区域标注(如病房、公共区域、操作区)、行人身份标注(如医生、病人、工人)及其对应的高精度人体网格模型,以及预计算的导航路径等详细注释信息。这些标注信息为评估机器人的语义理解能力提供了可靠的ground truth。
任务设计: LISN-Bench包含五个精心设计的代表性任务,系统性地覆盖了四种基本导航模式的各种组合。每个任务都包含明确的语言指令和隐含的社交约束,能够全面检验机器人的综合导航能力:
评测指标: LISN-Bench设计了多维度的评测指标体系,从三个层面全面评估机器人的导航能力:(1)"是否听懂指令"——通过任务完成的语义正确性评估语言理解能力;(2)"是否遵守社交规范"——通过行人社交得分和区域社交得分评估社交合规性;(3)"是否安全高效到达"——通过成功率、碰撞率、路径平滑度等传统指标评估基础导航性能。这种多层次的评测框架能够区分不同类型的导航失败,为系统改进提供有针对性的指导。
4. 系统架构:快慢分层设计
4.1 设计理念
Social-Nav-Modulator采用创新的快慢分层架构设计,其核心设计理念源于一个关键洞察:如果将经典社交导航视为一个带约束的优化问题,那么可以使用VLM动态调制优化问题的输入参数和约束条件,使其与语言指令中蕴含的社交规范保持一致,而无需VLM直接参与高频控制决策。这种设计思路将VLM的角色从"控制器"转变为"调制器",巧妙地绕过了时域鸿沟的限制。
从控制论的视角来看,这种设计可以理解为将导航系统分解为两个时间尺度不同的子系统:慢系统负责语义理解和策略制定,运行频率约为 Hz;快系统负责实时控制和避障,运行频率约为 Hz。两个系统通过参数空间进行通信,而非直接的动作空间耦合,从而实现了时间尺度的解耦。
这种分层设计带来两个显著的工程优势:
优势一:保留经典规划器的实时安全性。快系统采用经过充分验证的社交力模型(SFM)局部规划器,能够以20Hz的高频率响应环境变化,确保机器人在高动态环境中能够及时避让突然出现的行人或障碍物。这种设计继承了经典方法在安全性方面的可靠保障,避免了端到端学习方法可能带来的不可预测行为。
优势二:将VLM优势转化为参数调制。慢系统利用VLM强大的多模态理解能力,将抽象的社交概念(如"谨慎""紧急""远离")转化为对代价图参数和SFM控制器参数的具体调制指令。这种转化使得语言中的语义信息能够以可解释、可调试的方式影响机器人行为,同时避免了VLM直接生成低层控制命令的延迟问题。
4.2 系统总体架构
系统由两个核心子系统构成,通过ROS话题和服务进行通信。以下是系统架构的详细描述,展示了从传感器输入到运动控制输出的完整数据流:

4.3 数据流与模块交互
系统的完整数据流展示了从原始传感器数据到最终控制命令的信息处理过程。这一流程体现了视觉感知、语义理解、参数调制和运动控制的有机协作:
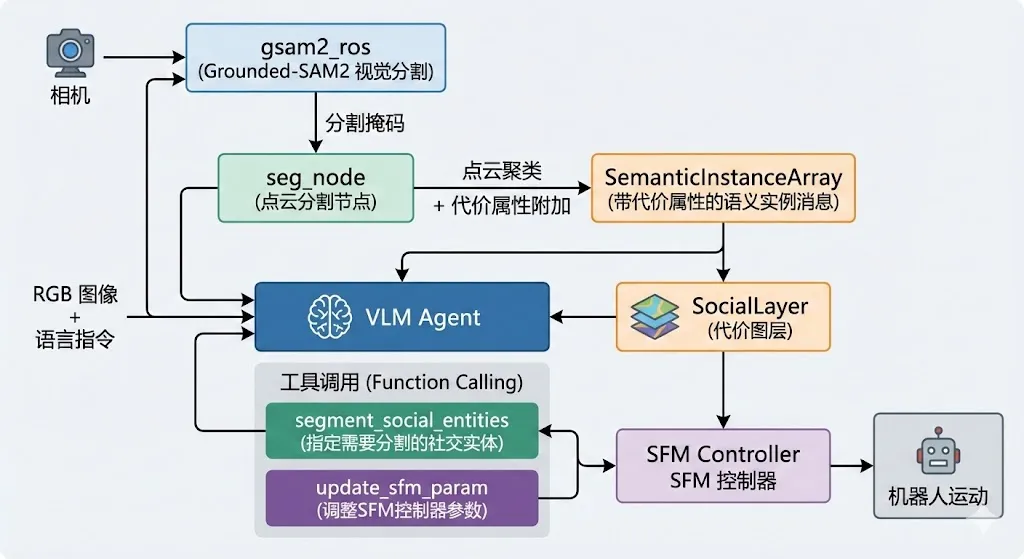
在tvss_nav的实际实现中,VLM Agent通过roslibpy库与ROS系统进行通信,发布分割提示到/segment_prompt话题,发布代价属性配置到/cost_attributes话题。gsam2_ros节点订阅分割提示后,使用Grounded-DINO进行目标检测,再通过SAM2进行实例分割,最终输出带有实例标签的分割掩码。这些掩码与点云数据融合后,生成带有代价属性的语义实例消息,供SocialLayer在代价图更新时使用。
5. 慢系统:VLM推理代理
5.1 VLM Agent核心实现
慢系统的核心是一个基于GPT-4o的VLM推理代理,负责解释视觉输入和语言指令中蕴含的社交语境,并将其转化为可操作的参数调制指令。在tvss_nav的实际实现中,VLM Agent采用了基于工具调用(Function Calling)的交互范式,使VLM能够通过结构化的方式与导航系统进行通信。这种设计既利用了VLM强大的推理能力,又确保了输出的可解析性和确定性。
以下是VLM Agent的核心初始化代码,展示了系统的关键配置参数和通信机制:
class VLM: def __init__(self, debug=False, update_period=10.0): self.shutdown_flag = False self.debug = debug self.paused = True self.update_period = update_period # 慢系统更新周期: 默认10秒 self.message_history: List[Dict[str, Any]] = [] self.max_history = 4 # 保持最近4轮对话历史,平衡上下文信息与token消耗 # 通过roslibpy建立与ROS的WebSocket连接 self.ros = roslibpy.Ros(host='localhost', port=9090) self.ros.run() # 从ROS参数服务器读取话题配置,支持灵活的系统集成 self.camera_topic = self.get_param('/tvss_nav/color_compressed_topic', '/camera/color/image_raw/compressed') self.text_topic = self.get_param('/tvss_nav/segment_prompt_topic', '/segment_prompt') self.cost_attribute_topic = self.get_param('/tvss_nav/cost_attribute_topic', '/cost_attributes') # 发布器: 分割提示 + 代价属性配置 self.text_publisher = roslibpy.Topic(self.ros, self.text_topic, 'std_msgs/String') self.cost_attr_publisher = roslibpy.Topic(self.ros, self.cost_attribute_topic, 'std_msgs/String') # 加载工具定义(YAML格式)和系统提示词 self.tools = yaml.safe_load(open('tools.yaml'))['tools'] self.system_prompt = open('system_prompt.md').read().strip() # OpenAI客户端初始化 self.client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))该实现的几个关键设计决策值得注意:(1)update_period=10.0定义了慢系统的更新周期,这一参数需要根据VLM的推理延迟和场景动态性进行权衡;(2)使用roslibpy而非原生ROS Python接口,使得VLM Agent可以在独立的Python环境中运行,避免ROS版本兼容性问题;(3)通过max_history=4限制对话历史长度,在保持上下文连贯性的同时控制API调用成本。
5.2 VLM查询与工具调用
VLM Agent在每个决策周期(约10秒)执行一个完整的感知-推理-执行循环。这一过程包括:捕获当前视角的RGB图像、将图像与任务指令组合成多模态提示、调用VLM进行推理、解析工具调用结果并执行相应的参数调制操作。以下是查询函数的核心实现,展示了多模态输入的构造和工具调用的处理流程:
def query_gpt(self, image_base64, user_query=None): """查询GPT并处理工具调用""" # 构建消息序列 messages = [{"role": "system", "content": self.system_prompt}] if self.initial_task: messages.append({"role": "user", "content": self.initial_task}) messages.extend(self.message_history) # 添加当前图像和查询 image_uri = f"data:image/jpeg;base64,{image_base64}" text = user_query if user_query else \\ "Now the image is 10s after what you last seen. Based on your " \\ "observation, call tools to segment all the important social " \\ "entities if any and update sfm parameters if necessary." user_message = { "role": "user", "content": [ {"type": "text", "text": text}, {"type": "image_url", "image_url": {"url": image_uri}} ] } messages.append(user_message) # 调用VLM response = self.client.chat.completions.create( model=self.config['model'], messages=messages, max_tokens=self.config['max_text_tokens'], tools=self.tools, tool_choice="auto", stream=False ) # 解析并执行工具调用 assistant_content = response.choices[0].message.content tool_calls = parse_tool_calls(extract_json_from_markdown(assistant_content)) if tool_calls: for tool_call in tool_calls: if tool_call['tool'] == "segment_social_entities_from_name": # 发布分割提示和代价属性 params = tool_call['args'] object_names = params['object_names'] cost_attrs = params.get('cost_attributes', {}) self.text_publisher.publish( roslibpy.Message({'data': object_names.strip()})) self.cost_attr_publisher.publish( roslibpy.Message({'data': json.dumps(cost_attrs)})) elif tool_call['tool'] == "update_sfm_param": # 更新SFM控制器参数 params = tool_call['args'] self.update_sfm_param( params['param_name'], float(params['value']))5.3 工具定义
VLM Agent通过两类精心设计的工具与导航系统进行交互,这些工具的定义遵循OpenAI Function Calling规范,使VLM能够以结构化的方式输出调制指令。工具定义存储在tools.yaml文件中,支持灵活的扩展和配置:
工具一: segment_social_entities_from_name
该工具负责指示视觉分割模块(Grounded-SAM2)对场景中的特定社交实体进行分割,并为每个分割出的实体指定相应的导航代价属性。这种设计使VLM能够根据语言指令中的语义信息,选择性地关注特定类型的对象,并为它们分配适当的规避优先级。在tvss_nav的实际实现中,对象名称采用点号分隔的格式,如doctor.patient.wheelchair,以支持同时分割多个不同类型的实体:
- type: function function: name: segment_social_entities_from_name description: >- 根据简洁的描述性名称分割场景中的社交实体。每个实体使用最多两个词描述 (如 seated woman, blue man)。多个实体使用点号分隔。同时为每个实体 指定导航代价属性,控制机器人对该实体的规避行为。 parameters: type: object properties: object_names: type: string description: "以点号分隔的对象名称,如 'doctor.child.wheelchair'" cost_attributes: type: object description: "每个对象的代价属性配置字典" additionalProperties: type: object properties: cost_value: type: integer description: "代价值 [0-254], 越高表示越需要规避, 254为致命障碍物" inflation_radius: type: number description: "膨胀半径(米), 定义规避区域的空间范围" decay_rate: type: number description: "衰减率, 控制代价随距离下降的速度"工具二: update_sfm_param
该工具用于动态调整SFM(Social Force Model)局部规划器的行为参数,使机器人能够根据任务语义调整其运动特性。例如,"紧急"任务可能需要提高最大速度限制,而"小心"任务则需要增强对行人的规避力度。这种参数调制机制是将语言语义转化为运动行为的关键桥梁:
- type: function function: name: update_sfm_param description: >- 更新社交力模型局部规划器的运动参数,调整机器人的导航行为特性。 支持速度限制、力权重等参数的动态配置。 parameters: type: object properties: param_name: type: string enum: ["max_lin_vel", "max_rot_vel", "sfm_goal_weight", "sfm_obstacle_weight", "sfm_people_weight"] description: "参数名称" value: type: number description: "参数新值"5.4 意图驱动的参数调制策略
VLM通过分析用户指令中蕴含的意图信息,采用差异化的参数调制策略。这种意图驱动的调制机制是LISN系统实现语义感知导航的核心所在。系统将常见的导航意图归纳为以下几类,并为每类意图定义了相应的参数调整策略:
这种意图-参数映射机制的优势在于其可解释性和可调试性。与端到端学习方法不同,系统管理员可以清晰地理解每种语言指令如何影响机器人行为,并在必要时进行调整和优化。
5.5 SFM参数动态配置
SFM参数通过ROS的dynamic_reconfigure服务进行实时更新,这一机制允许在机器人运行过程中无需重启即可调整控制参数。tvss_nav实现中定义了一组可配置的参数集合,涵盖了速度限制和力权重两大类:
# 可动态配置的SFM参数集合VALID_PARAMS = { 'max_lin_acc', # 最大线性加速度 $a_{max}$ (m/s²) 'max_rot_acc', # 最大角加速度 $\\alpha_{max}$ (rad/s²) 'max_lin_vel', # 最大线速度 $v_{max}$ (m/s) 'min_lin_vel', # 最小线速度 $v_{min}$ (m/s) 'max_rot_vel', # 最大角速度 $\\omega_{max}$ (rad/s) 'min_rot_vel', # 最小角速度 $\\omega_{min}$ (rad/s) 'sfm_goal_weight', # 目标吸引力权重 $w_{goal}$ 'sfm_obstacle_weight', # 障碍物排斥力权重 $w_{obstacle}$ 'sfm_people_weight', # 行人排斥力权重 $w_{people}$}def update_sfm_param(param_name: str, value: float, ros_client: roslibpy.Ros = None) -> bool: """通过dynamic_reconfigure服务更新SFM参数 Args: param_name: 参数名称,必须在VALID_PARAMS中 value: 参数新值 ros_client: 可选的ROS连接,若未提供则创建新连接 Returns: 更新是否成功 """ if param_name not in VALID_PARAMS: raise SFMConfigError(f"Invalid parameter: {param_name}") client = ros_client if ros_client else roslibpy.Ros( host='localhost', port=9090) if not ros_client: client.run() # 通过rosbridge调用dynamic_reconfigure服务 service = roslibpy.Service( client, '/jackal/move_base_flex/SFMControllerROS/set_parameters', 'dynamic_reconfigure/Reconfigure') request = { 'config': { 'doubles': [{'name': param_name, 'value': float(value)}], 'bools': [], 'ints': [], 'strs': [], 'groups': [] } } result = service.call(request) return True该实现的关键设计点包括:(1)参数白名单机制(VALID_PARAMS)确保只有预定义的安全参数可以被修改;(2)支持复用已有的ROS连接以提高效率;(3)采用rosbridge的服务调用接口,与VLM Agent的其他通信机制保持一致。
6. 快系统:社交力模型与代价图
6.1 社交力模型(SFM)局部规划器
快系统采用基于社交力模型(Social Force Model, SFM)的局部规划器,这是一种经典且经过充分验证的行人运动模型。SFM将智能体的运动建模为对多种虚拟"力"的响应,每种力代表一种特定的行为动机或约束。这种基于物理隐喻的建模方式使得机器人的运动行为具有良好的可解释性和可预测性。
机器人所受的总力 是多个力分量的加权线性组合:
其中各力分量的物理含义如下:
• : 期望力,驱动机器人向目标位置移动。其方向指向目标点,大小与当前速度和期望速度的差值成正比,形式化为 ,其中 是松弛时间, 是期望速度, 是指向目标的单位向量 • : 障碍物排斥力,使机器人远离静态障碍物。采用指数衰减模型 ,其中 是到障碍物的距离, 是远离障碍物的单位法向量 • : 社交力,管理与其他移动智能体(如行人)的交互,确保保持适当的社交距离 • : 群组力,用于处理机器人需要跟随或配合群体运动的场景
慢系统通过update_sfm_param工具动态调整权重参数 ,从而实现对机器人社交行为的高层语义控制。例如,当用户发出"紧急"指令时,可以增大 并降低 ,使机器人更激进地向目标移动。
6.2 社交代价层实现
社交代价层(SocialLayer)是快系统的核心组件,作为ROS Costmap2D的插件运行,负责将语义分割结果转化为导航代价图。在tvss_nav的实现中,SocialLayer继承自costmap_2d::CostmapLayer,并实现了标准的代价图更新接口。以下是其核心类定义:
namespace tvss_nav {// 社交观测数据类型typedef std::vector<tvsn_msgs::SemanticInstance> SocialObservation;// 社交缓冲区: 接收语义实例消息class SocialBuffer {public: SocialBuffer(ros::NodeHandle _nh, std::string _topic) { nh = _nh; stamp = ros::Time(0); topic = _topic; }void subscribe(){ sub = nh.subscribe(topic, 1, &SocialBuffer::callback, this); } SocialObservation getData(){ return data; }private:void callback(const tvsn_msgs::SemanticInstanceArrayConstPtr& msg){ stamp = msg->header.stamp; data = msg->instances; } ros::NodeHandle nh; std::string topic; ros::Time stamp; SocialObservation data; ros::Subscriber sub;};// 社交代价层: Costmap2D插件class SocialLayer : public costmap_2d::CostmapLayer {public:virtual void onInitialize();virtual void updateBounds(double robot_x, double robot_y, double robot_yaw, double* min_x, double* min_y, double* max_x, double* max_y) override;virtual void updateCosts(costmap_2d::Costmap2D& master_grid, int min_i, int min_j, int max_i, int max_j) override;protected: std::vector<boost::shared_ptr<SocialBuffer>> observation_buffers_; std::vector<boost::shared_ptr<SocialBuffer>> marking_buffers_; std::vector<boost::shared_ptr<SocialBuffer>> clearing_buffers_; dynamic_reconfigure::Server<tvss_nav::SocialPluginConfig> *dsrv_; tvss_nav::SocialPluginConfig config_;};} // namespace tvss_nav6.3 代价更新算法
社交代价层的核心功能由updateCosts函数实现,该函数在每个代价图更新周期被调用,负责将语义实例的点云数据投影到二维代价图上,并应用基于指数衰减的代价膨胀策略。这一算法确保了社交实体周围形成平滑的代价梯度,使规划器能够产生自然的避障轨迹。以下是tvss_nav中该函数的实际实现:
void SocialLayer::updateCosts(costmap_2d::Costmap2D& master_grid, int min_i, int min_j, int max_i, int max_j){ // 获取所有标记缓冲区的观测数据 std::vector<SocialObservation> observations; if (!getObservations(marking_buffers_, observations)) return; for (const auto& obs : observations) { for (const auto& instance : obs) { // 将点云从传感器坐标系转换到全局坐标系 pcl::PointCloud<pcl::PointXYZ> cloud, cloud_transformed; pcl::fromROSMsg(instance.cloud, cloud); geometry_msgs::TransformStamped tf_transform; try { tf_transform = tf_->lookupTransform( global_frame_, instance.cloud.header.frame_id, instance.cloud.header.stamp, ros::Duration(0.5)); Eigen::Affine3d tf_eigen = tf2::transformToEigen(tf_transform); Eigen::Matrix4f tf_mat = tf_eigen.matrix().cast<float>(); pcl::transformPointCloud(cloud, cloud_transformed, tf_mat); } catch (const tf2::TransformException& ex) { ROS_WARN("Transform failed: %s", ex.what()); continue; } // 获取实例的代价属性(由VLM设置) int base_cost = instance.cost_value > 0 ? instance.cost_value : config_.default_cost_value; double r = instance.inflation_radius > 0 ? instance.inflation_radius : config_.default_inflation_radius; double decay = instance.decay_rate > 0 ? instance.decay_rate : config_.default_decay_rate; int radius_cells = std::round(r / resolution_); // 遍历点云中的每个点 for (const auto& pt : cloud_transformed) { // 高度过滤 if (pt.z < config_.min_height || pt.z > config_.max_height) continue; unsigned int mx, my; if (!master_grid.worldToMap(pt.x, pt.y, mx, my)) continue; // 设置中心点代价 switch (config_.combination_method) { case 0: // Overwrite master_grid.setCost(mx, my, base_cost); break; case 1: // Maximum master_grid.setCost(mx, my, std::max(master_grid.getCost(mx, my), (unsigned char)base_cost)); break; } // 膨胀: 对周围单元格应用指数衰减代价 for (int dx = -radius_cells; dx <= radius_cells; ++dx) { for (int dy = -radius_cells; dy <= radius_cells; ++dy) { int nx = mx + dx, ny = my + dy; if (nx < 0 || ny < 0 || nx >= (int)master_grid.getSizeInCellsX() || ny >= (int)master_grid.getSizeInCellsY()) continue; // 计算欧氏距离并应用指数衰减 double dist = hypot(dx, dy) * resolution_; int inflated = std::round( base_cost * exp(-decay * dist)); switch (config_.combination_method) { case 0: // Overwrite master_grid.setCost(nx, ny, inflated); break; case 1: // Maximum master_grid.setCost(nx, ny, std::max(master_grid.getCost(nx, ny), (unsigned char)inflated)); break; } } } } } }}6.4 代价值语义
代价图中的代价值具有明确定义的语义含义,这些语义约定是ROS Navigation Stack的标准规范。VLM在通过segment_social_entities_from_name工具设置代价属性时,需要理解并遵循这些约定,以确保生成的代价图能够被规划器正确解释。以下是代价值的完整语义定义:
6.5 指数衰减公式
代价膨胀采用指数衰减公式,使代价值随距离平滑下降,形成连续可导的代价场。这种设计使得规划器能够产生平滑的避障轨迹,而非急剧的转向。指数衰减的数学形式为:
其中:
• : VLM设置的基础代价值,反映该实体的规避优先级 • : 衰减率(decay_rate),控制代价随距离下降的速度,单位为 • : 到障碍物中心的欧氏距离,单位为米
衰减率 的选择直接影响规避行为的"硬度":
• 较高的衰减率(如 ): 代价快速下降,规避区域边界清晰,机器人倾向于紧贴边界通过 • 较低的衰减率(如 ): 代价缓慢下降,规避区域边界模糊,机器人会保持更大的安全距离
在tvss_nav的默认配置中,default_decay_rate设置为1.0,提供适中的规避行为。VLM可以根据指令语义动态调整这一参数——例如,"小心"指令可能触发较低的衰减率以增大安全距离,"紧急"指令则可能使用较高的衰减率以允许更激进的路径。
7. 点云分割节点
7.1 功能概述
点云分割节点是连接视觉分割结果与导航代价图的关键桥梁模块。在LISN系统的数据流中,该节点接收来自Grounded-SAM2的RGB图像语义分割掩码,将其与深度传感器获取的点云数据进行时空对齐和融合,最终生成带有代价属性的语义实例消息供SocialLayer使用。
该节点的设计解决了一个核心技术挑战:如何将二维图像空间的语义分割结果转换为三维世界坐标系中的障碍物表示。这一转换涉及相机内参标定、点云与图像的像素级对应、坐标系变换、以及体素滤波降采样等多个处理步骤。通过精心设计的数据同步机制,节点确保了分割掩码与点云数据的时间一致性,避免了因传感器异步导致的错误对应。
7.2 核心实现
以下是点云分割节点的核心类定义和关键处理逻辑。节点使用ROS的message_filters库实现多话题精确时间同步,确保点云、分割掩码和实例类别字典三个数据源的时间戳严格匹配:
struct CostAttributes { int cost_value = 254; float inflation_radius = 1.0; float decay_rate = 2.7685;};class PointCloudSegNode {public: PointCloudSegNode(ros::NodeHandle& nh, ros::NodeHandle& pnh) : nh_(nh), tf_buffer_(), tf_listener_(tf_buffer_) { // 订阅: 点云 + 分割掩码 + 实例类别字典 cloud_sub_.subscribe(nh_, pointcloud_topic_, 1); mask_sub_.subscribe(nh_, mask_topic_, 1); instance_class_sub_.subscribe(nh_, instance_class_topic_, 1); // 订阅: 相机内参 + 代价属性(来自VLM) rgb_info_sub_ = nh_.subscribe(rgb_info_topic_, 1, &PointCloudSegNode::handleRgbInfo, this); cost_attr_sub_ = nh_.subscribe(cost_attribute_topic_, 1, &PointCloudSegNode::handleCostAttr, this); // 同步回调 sync_.reset(new Sync(ExactSyncPolicy(100), cloud_sub_, mask_sub_, instance_class_sub_)); sync_->registerCallback(boost::bind( &PointCloudSegNode::processData, this, _1, _2, _3)); // 发布: 语义实例数组 semantic_pub_ = nh_.advertise<tvsn_msgs::SemanticInstanceArray>( instance_array_topic_, 1); }private: // 处理VLM发布的代价属性void handleCostAttr(const std_msgs::StringConstPtr& msg){ cost_attr_map_.clear(); Json::Reader reader; Json::Value root; if (!reader.parse(msg->data, root)) { ROS_ERROR("Failed to parse cost attributes JSON."); return; } for (const auto& class_name : root.getMemberNames()) { const Json::Value& attr = root[class_name]; CostAttributes parsed; parsed.cost_value = attr.get("cost_value", 254).asInt(); parsed.inflation_radius = attr.get("inflation_radius", 1.0).asFloat(); parsed.decay_rate = attr.get("decay_rate", 2.7685).asFloat(); cost_attr_map_[class_name] = parsed; } } // 主处理函数: 融合点云与分割掩码void processData(const sensor_msgs::PointCloud2ConstPtr& cloud_msg, const sensor_msgs::CompressedImageConstPtr& mask_msg, const tvsn_msgs::StringStampedConstPtr& class_msg){ // 解析实例类别字典 Json::Reader reader; Json::Value root; if (reader.parse(class_msg->data, root)) { for (const auto& label_str : root.getMemberNames()) { int label = std::stoi(label_str); std::string class_name = root[label_str].asString(); label_to_class_map_[label] = class_name; } } // 解码分割掩码 cv::Mat mask = cv::imdecode(cv::Mat(mask_msg->data), cv::IMREAD_GRAYSCALE); // 获取坐标变换 geometry_msgs::TransformStamped tf_transform; tf_transform = tf_buffer_.lookupTransform( cloud_msg->header.frame_id, mask_msg->header.frame_id, cloud_msg->header.stamp, ros::Duration(0.5)); // 遍历点云,按分割标签聚类 std::unordered_map<int, pcl::PointCloud<pcl::PointXYZRGB>> point_clusters; sensor_msgs::PointCloud2ConstIterator<float> iter_x(*cloud_msg, "x"); sensor_msgs::PointCloud2ConstIterator<float> iter_y(*cloud_msg, "y"); sensor_msgs::PointCloud2ConstIterator<float> iter_z(*cloud_msg, "z"); for (int i = 0; i < cloud_msg->width * cloud_msg->height; ++i, ++iter_x, ++iter_y, ++iter_z) { // 将3D点投影到2D图像坐标 geometry_msgs::PointStamped pt_in, pt_out; pt_in.point.x = *iter_x; pt_in.point.y = *iter_y; pt_in.point.z = *iter_z; tf2::doTransform(pt_in, pt_out, tf_transform); int u, v; std::tie(u, v) = tvss_nav::projectToImage( pt_out.point.x, pt_out.point.y, pt_out.point.z, rgb_intrinsics_, rgb_distortion_); if (u >= 0 && u < mask.cols && v >= 0 && v < mask.rows) { int label = mask.at<uchar>(v, u); if (label == 0 || label == 255) continue; pcl::PointXYZRGB pt; pt.x = *iter_x; pt.y = *iter_y; pt.z = *iter_z; point_clusters[label].push_back(pt); } } // 体素滤波降采样 for (auto& pair : point_clusters) { pcl::VoxelGrid<pcl::PointXYZRGB> voxel; voxel.setInputCloud(pair.second.makeShared()); voxel.setLeafSize(voxel_leaf_size_, voxel_leaf_size_, voxel_leaf_size_); pcl::PointCloud<pcl::PointXYZRGB> filtered; voxel.filter(filtered); pair.second.swap(filtered); } // 构建语义实例消息 tvsn_msgs::SemanticInstanceArray semantic_instances; for (const auto& cluster : point_clusters) { const int label = cluster.first; std::string class_name = label_to_class_map_.count(label) ? label_to_class_map_[label] : "unknown"; // 查找VLM设置的代价属性 auto it = cost_attr_map_.find(class_name); if (it != cost_attr_map_.end()) { const auto& attr = it->second; AddInstance(label, cluster.second, cloud_msg->header, semantic_instances, attr.cost_value, attr.inflation_radius, attr.decay_rate, class_name); } } semantic_instances.header = cloud_msg->header; semantic_pub_.publish(semantic_instances); } std::unordered_map<int, std::string> label_to_class_map_; std::unordered_map<std::string, CostAttributes> cost_attr_map_;};7.3 关键算法解析
点云分割节点的核心处理流程涉及多个精心设计的算法步骤,每个步骤都针对特定的技术挑战进行了优化。以下是对关键算法的深入解析:
3D到2D投影算法: 该算法将三维点云中的每个点投影到二维图像平面,以获取对应的语义标签。投影过程使用针孔相机模型,给定相机内参矩阵 和点云坐标 ,像素坐标 的计算公式为:
其中 是焦距(以像素为单位), 是光心坐标。在tvss_nav的实现中,projectToImage函数还考虑了镜头畸变校正,确保投影结果的几何准确性。
体素滤波降采样: 为了减少点云数据量并提高后续处理效率,节点对每个语义实例的点云应用体素网格滤波。该算法将三维空间划分为规则的立方体网格(体素),每个体素内的所有点被其质心所替代。设体素边长为 (在tvss_nav中通过voxel_leaf_size_参数配置,默认值约为0.02-0.05米),则点云密度降低约为 倍,其中 是原始点云的平均点间距。这种降采样在保持点云几何特征的同时,显著减少了SocialLayer需要处理的数据量。
多话题时间同步: 节点使用ROS的message_filters库实现精确时间同步,采用ExactTime策略确保点云、分割掩码和实例类别字典三个数据源的时间戳完全匹配。同步缓冲区大小设置为100帧,容许一定程度的消息到达时间抖动。这种严格的时间同步机制对于动态场景至关重要——如果使用时间不一致的数据,可能导致行人位置的错误估计,进而产生危险的导航决策。
7.4 数据流与消息格式
点云分割节点在LISN系统中承担着数据格式转换和信息融合的关键角色。以下是节点处理的主要消息类型及其数据流向的详细说明:
输入消息:
• sensor_msgs/PointCloud2: 来自深度相机或激光雷达的三维点云数据,包含每个点的空间坐标和可选的颜色信息• sensor_msgs/CompressedImage: Grounded-SAM2输出的压缩格式语义分割掩码,每个像素值代表对应实例的标签ID• tvsn_msgs/StringStamped: JSON格式的实例类别字典,建立标签ID到类别名称(如"doctor"、"wheelchair")的映射关系• std_msgs/String: VLM Agent发布的代价属性配置,包含每个类别的cost_value、inflation_radius和decay_rate参数
输出消息:
• tvsn_msgs/SemanticInstanceArray: 包含所有检测到的语义实例的数组消息,每个实例包括:• 分割后的点云数据(sensor_msgs/PointCloud2格式) • 类别名称和实例标签 • VLM指定的代价属性(cost_value, inflation_radius, decay_rate) • 时间戳和坐标系信息
这种消息设计使得SocialLayer能够直接使用语义实例信息更新代价图,无需进行额外的格式转换或属性查询,实现了高效的模块间通信。
8. 总结与展望
LISN项目展示了将大型视觉语言模型与经典机器人控制方法相结合的可行路径。通过快慢分层架构的创新设计,系统在保持实时安全性的同时,实现了对自然语言指令的深度理解和社交规范的灵活遵循。随着基础模型能力的持续提升和机器人硬件的不断发展,我们相信语言指令社交导航将成为未来人机共存环境中移动机器人的标准能力,为医院、商场、仓库等复杂社交场景中的服务机器人部署奠定坚实的技术基础。
更多ROS、具身智能相关内容,请关注古月居
👉 关注我们,发现更多有深度的自动驾驶/具身智能/GitHub 内容!
🚀 往期内容回顾 👀
🔥 具身智能 | 统一世界模型(UWM)完全指南:从视频到机器人策略的桥梁🔥 行业动态 | 基于物理模拟器和世界模型的具身智能学习:深度解析与未来展望(下)🔥 行业动态 | 基于物理模拟器和世界模型的具身智能学习:深度解析与未来展望(上)

