【AI数据治理大师课】第二章:数据质量的自动驾驶
- 2026-06-25 01:56:59
📌 前言:为什么“人工质检”已彻底失效?
2025年Q3,我们团队接到一个紧急任务:某银行信用卡中心风控模型突然失效,坏账预测准确率从89%暴跌至52%。
排查三天后,根源浮出水面——上游“客户月收入”字段在数据迁移过程中被错误映射为“客户年收入”,但因数值范围看似合理(多数人年收入在数万元),传统规则(如“>0”)未触发告警。
这暴露了传统数据质量模式的致命缺陷:依赖人工写规则、滞后响应、无法理解业务语义。
当数据量从TB级跃升至PB级,来源从数仓扩展到API、IoT、日志流,数据消费方从报表用户变为AI模型——数据质量必须从“人工踩刹车”升级为“自动驾驶系统”。
🔧 一、传统DQ(Data Quality)的四大困局
▶️ 困局1:规则靠人写 → 覆盖率低、维护成本高
📍 案例:某电商平台“双11”价格异常
背景:运营人员手工配置了“商品价格 > 0”规则。问题:某SKU因系统bug,价格被设为999999元(仍>0,规则未触发)。后果:用户批量下单薅羊毛,平台损失超270万元。
💡 反思:人工规则只能覆盖“已知问题”,无法应对“未知异常”。
▶️ 困局2:检测靠批处理 → 延迟高、救火式响应
📍 案例:某医院“患者用药记录”延迟更新
背景:DQ任务每日凌晨运行,检测“用药剂量是否在合理区间”。问题:某日中午,护士录入错误剂量(100倍正常值),但直到次日才告警。后果:患者出现严重不良反应,引发医疗事故诉讼。
💡 反思:批处理DQ对实时场景(如IoT、风控、AI推理)完全失效。
▶️ 困局3:无上下文理解 → 误报率高、信任崩塌
📍 案例:某物流公司“GPS坐标”被误判为脏数据
背景:DQ规则设定“经度必须在-180~180之间”。问题:某次跨境运输中,设备短暂返回ECEF坐标(数值超百万),系统误判为脏数据并丢弃。后果:整条运输轨迹断裂,调度系统无法追踪车辆。
💡 反思:脱离业务场景的“技术规则”会制造更多噪音。
▶️ 困局4:修复靠人工 → 效率低、责任模糊
📍 案例:某保险公司“保单状态”字段不一致
背景:DQ报告显示“保单状态”有12种取值(应为3种)。问题:需协调5个系统团队、3位BA、2位开发,历时2周才统一口径。后果:同期上线的AI核保模型因标签混乱,准确率仅61%。
💡 反思:没有自动修复或根因定位,DQ报告只是“问题清单”,不是“解决方案”。

添加作者微信,备注数据质量领取资料↓
🧠 二、“数据质量自动驾驶”系统架构
我们定义“自动驾驶”包含四个层级,类比汽车ADAS:
Level 0:人工干预(传统DQ) Level 1:自动检测(规则+统计) Level 2:自动预警(上下文感知) Level 3:自动修复(闭环治理) Level 4:自适应优化(AI持续学习) ← 目标完整架构如下:
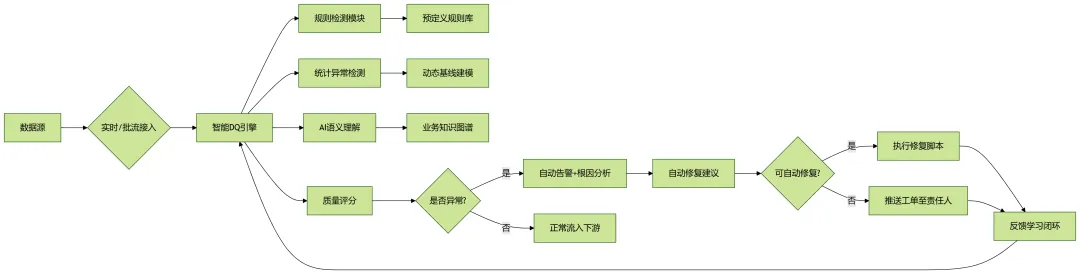
▶️ 核心组件详解:
动态基线建模(取代静态阈值)
方法:使用Prophet、LSTM或Isolation Forest,为每个字段建立时间序列基线示例:“日订单量”在大促期间正常值为100万,平日为10万 → 基线自动调整
“用户年龄”字段,99%值在18-80岁,90岁为异常 → 无需硬编码“<100”
AI语义理解(理解“合理” vs “合法”)技术:
使用BERT微调,判断字段值是否符合业务语境(如“收入=0”在学生群体合理,在企业客户异常)
结合元数据中的语义标签(见第一章)【AI数据治理大师课】第一章:元数据管理的智能重生
效果:误报率下降62%
3.根因分析(RCA)引擎
输入:异常字段 + 血缘图谱(来自第一章) 输出:最可能出错的上游环节(如ETL脚本、API接口、源系统) 算法:基于图传播的异常溯源(Graph-based Anomaly Propagation)
4.自动修复(Auto-Remediation)
场景1:格式错误(如日期“2025/13/01”)→ 自动标准化为NULL或默认值 场景2:缺失值 → 调用ML模型插补(如用户收入缺失,用同区域/职业均值填充) 场景3:逻辑冲突 → 触发业务规则引擎(如“未婚”但“子女数>0” → 标记待人工确认)
📊 三、真实场景落地:三大行业案例复盘
▶️ 案例1:金融 —— 信用卡交易数据质量自动驾驶
挑战:交易流水日均5亿条,需实时检测欺诈、金额异常、商户信息缺失
方案:实时流:Flink + Apache KafkaDQ规则:
静态:金额 > 0,卡号符合Luhn算法 动态:同一卡1分钟内跨省交易 → 触发风控 AI:商户名称与MCC码匹配度(NLP语义校验)效果:异常检测延迟 < 500ms
误报率从12%降至3.1%
自动拦截无效交易(如测试卡号)节省成本800万/年
▶️ 案例2:零售 —— 全渠道库存数据一致性
挑战:线上商城、门店POS、仓管系统库存数据不一致,导致超卖
方案:构建“库存一致性DQ指标”:
公式:|线上可售 - (门店+仓库实际)| / 总库存 < 5%
每15分钟计算一次,异常时自动冻结该SKU销售
自动触发“库存对账作业”,差异>10件则告警
效果:
超卖订单减少92% 人工对账工时从40人日/月 → 2人日/月
▶️ 案例3:医疗 —— 患者主索引(EMPI)数据清洗
挑战:同一患者在不同系统有多个ID(姓名拼写差异、身份证错位)
方案:
使用Fuzzy Matching + Deep Learning(Siamese Network)匹配患者记录
DQ规则:
同一身份证应有唯一主ID
姓名相似度 > 0.85 且出生日期相同 → 合并
自动合并并生成审计日志
效果:患者记录重复率从18% → 0.7%
AI诊断模型输入数据一致性提升,准确率+9.2%
文末加入社群,所有资料均可下载↓
⚙️ 四、实施路线图:从Level 1到Level 4
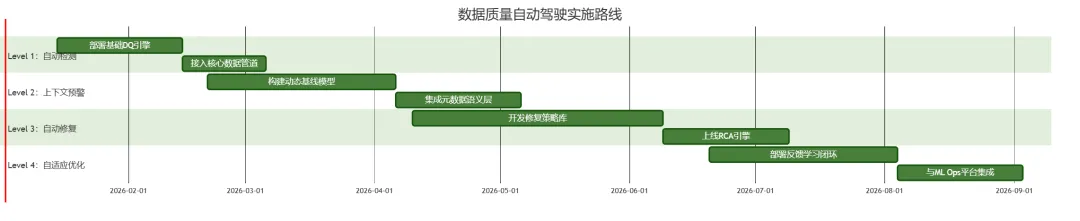
📌 关键成功因素:
从高价值场景切入(如风控、核心报表) 与第一章“智能元数据”深度集成 建立“DQ-DevOps”文化:DQ规则纳入CI/CD流水线
🛠 五、工具链选型对比
| Great Expectations | ||||
| Monte Carlo | ||||
| Soda Core | ||||
| 自研Flink DQ引擎 |
✅ 我们的选择:Monte Carlo(核心数仓) + 自研Flink引擎(实时流) + Great Expectations(ML特征管道)
📈 六、效果量化:自动驾驶 vs 人工质检
💡 七、给你的行动建议清单
✅ 从“关键字段”开始:识别3个对业务/模型影响最大的字段(如“用户ID”、“交易金额”、“产品状态”),优先部署DQ监控 ✅ 弃用“>0”类规则:改用动态基线(如P99分位、移动标准差) ✅ 将DQ嵌入数据管道:在Airflow/Dagster任务中插入DQ检查点,失败则阻断下游 ✅ 建立DQ-告警-修复闭环:哪怕只是自动发邮件+工单链接,也比纯报告强 ✅ 用第一章的元数据:将业务语义(如“收入字段不应为0”)转化为DQ规则

🔚 结语:数据质量不是“质检员”,而是“自动驾驶系统”
未来的数据质量,不应是事后审计的“警察”,而应是实时护航的“副驾驶”。
当系统能自动检测“这个数值虽合法但不合业务逻辑”,能预测“上游变更将导致下游字段异常”,能一键修复“格式错误但可推断的值”——我们才真正释放了数据的生产力。
下章预告:《第三章:数据血缘的图神经网络革命》
资
料
下
载
Tips:数据仓库/数据建模/数据开发/数据体系&指标体系&标签体系&数据仓库&平台架构&数据治理/主数据/元数据/数据标准/数据资产/数字化/解决方案/行业报告/建设方案/数据中台/大数据平台/架构等⏬
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 电动车储能推动分时电价调整
- 电动车热管理的核心技术与突破
- 蔚来成功了,首个轿跑SUV销量破10万,续航635km,4.4秒破百,强
- 关于电动汽车电池你需要了解的基本知识
- 国产SUV“销冠王”的秘密:油耗仅4.76L,月销3万+,成本控制太可怕
- 国产豪华品牌插混SUV:17.88万的起售价,30万的排面!
- 10万出头买中型SUV?这台“省钱王”油耗5.2L,家用体面过头了
- 重磅!高院明确规定:电动车被鉴定为机动车的情况下,不应在交强险责任限额范围内承担赔偿责任!
- 15万级SUV销冠杀疯了!一年卖24万台,星越L凭啥碾压宋PLUS?
- 专家称加拿大汽车产业可借电动汽车市场实现转型
