现阶段,自动驾驶技术正从高级辅助驾驶(L2/L2+)向高度自动驾驶(L4)迈进。这一等级的跃迁不仅是软件算法和传感器技术的革新,更是对底层计算硬件——汽车芯片架构的根本性重塑。
核心驱动力
自动驾驶等级的提升,最直观的差异体现在对算力需求的急剧膨胀。这种需求差异是驱动芯片架构分化的根本原因。
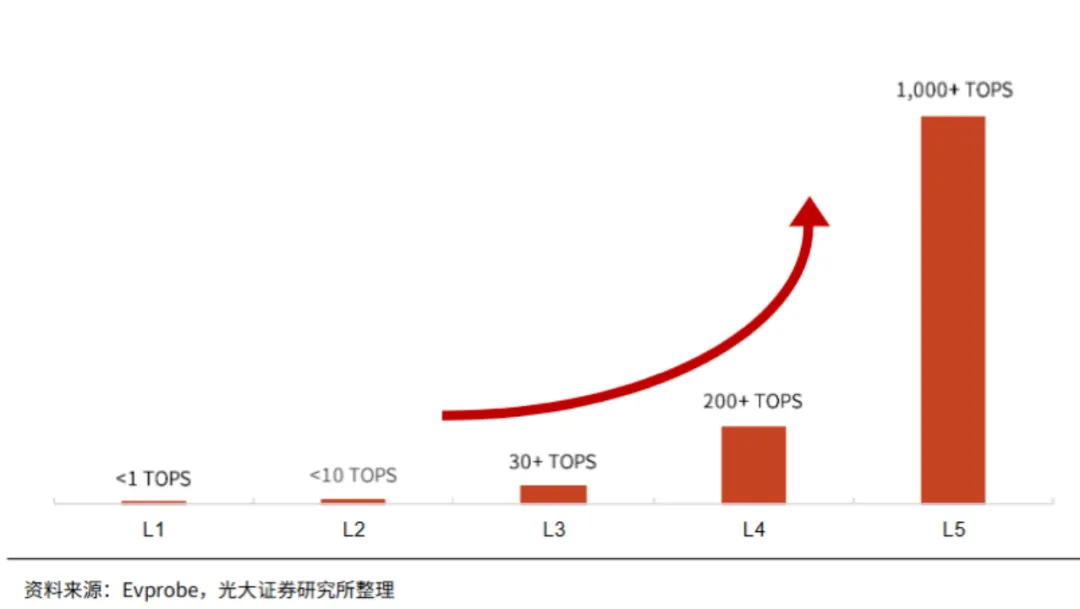
L2+作为L2功能的增强版,主要处理如自适应巡航、车道保持、自动泊车等功能。其芯片算力需求相对温和,通常集中在5至50 TOPS(每秒万亿次操作)的区间。
例如,市场上主流的L2+方案,其AI算力普遍在16 TOPS左右。这一算力水平足以支撑由数个摄像头和毫米波雷达组成的感知系统,进行目标检测、分类和路径规划等任务。其架构设计的核心目标是在成本可控的前提下,提供足够的性能来优化驾驶体验。
而更高级别的自动驾驶,如L4,其目标是在特定场景下完全替代人类驾驶员,无需人类监控和接管。这意味着系统必须能够处理远比L2+复杂得多的环境。
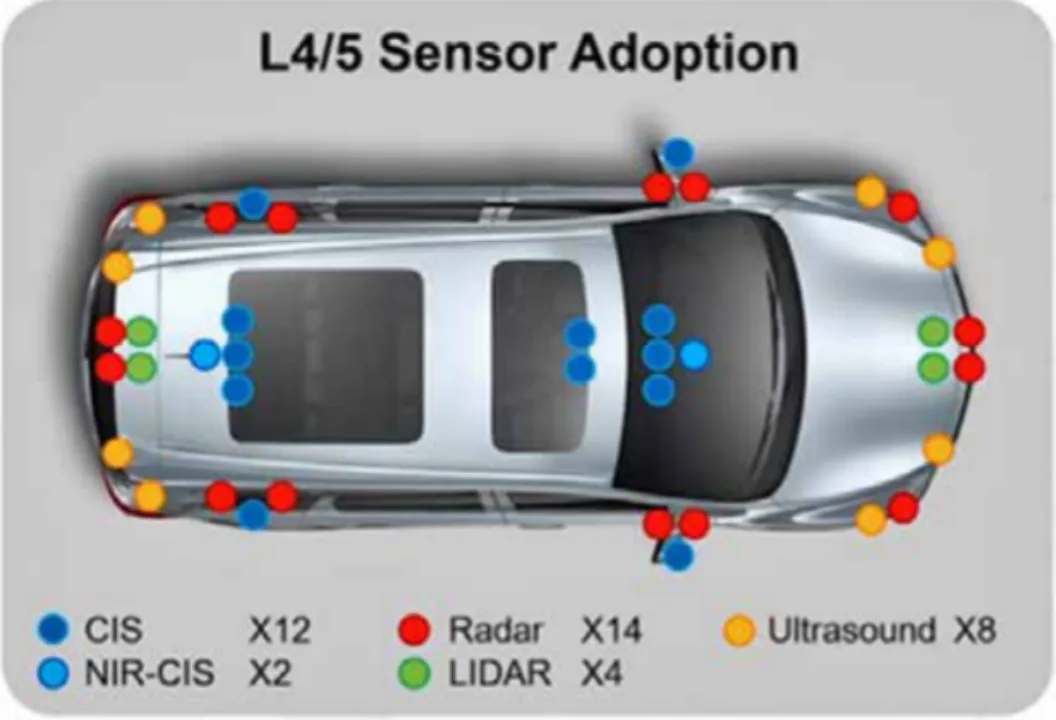
L4系统通常配置激光雷达、4D成像雷达、更多更高清的摄像头等构成的复杂传感器矩阵。这些传感器每小时产生的数据量可高达数TB。
为了实时处理如此庞大的数据流,并运行复杂的深度学习模型进行环境感知、行为预测和决策规划,L4芯片需要极其庞大的算力。其算力需求通常从200 TOPS起步,高端方案甚至超过2000 TOPS,进入PetaFLOPS(每秒千万亿次浮点运算)级别。
例如,英伟达的DRIVE Orin平台算力达到254 TOPS,而其后续的Thor平台则更高,这些都是为L3/L4级别设计的。这种算力量级的巨大差异,决定了L4芯片必须采用全新的、为大规模并行计算而生的架构。
上图展示了L1-L5不同等级对应的辅助驾驶/自动驾驶芯片算力要求
架构设计的根本分野
如果说算力是性能上的量变,那么功能安全与冗余设计则是架构哲学上的质变。这是区分L2+和L4芯片设计的核心标志。
在L2+系统中,驾驶员始终是最终的安全责任人。
因此,芯片架构设计的首要目标是高效实现各项辅助驾驶功能。虽然也需要遵循汽车安全完整性等级(ASIL)标准,但其核心计算单元通常不要求具备硬件级的完全冗余。系统可能会采用一些软件层面的监控和降级策略,或依赖机械备份(如传统的转向和制动系统)作为最后的防线。
进入L4级别,系统在特定条件下承担全部驾驶责任,这意味着任何单点故障都可能导致灾难性后果。因此,“零单点故障”成为L4硬件架构的核心要求。芯片架构必须从设计之初就深度集成功能安全与冗余机制。这体现在以下几个层面:
系统级冗余:L4计算平台通常采用多颗SoC(片上系统)并行工作的冗余方案。例如,采用两颗或多颗高性能SoC,一颗作为主计算单元,另一颗作为备份或进行交叉验证。当主芯片出现故障时,备份芯片能够瞬时接管,确保车辆安全。
IP核级冗余:在SoC内部,对关键的计算单元和处理路径实施硬件级冗余。例如,特斯拉的自研FSD芯片就采用了三模冗余(TMR)技术,即同一个计算任务由三个相同的处理单元并行执行,通过投票机制来纠正单个单元的瞬时错误。
双模冗余(DMR)也是常见的做法,尤其是在AI加速器中,用于确保计算结果的正确性。
全链路冗余:冗余设计不仅限于计算单元,还必须覆盖数据通路、电源供应、时钟信号等所有关键环节,确保不存在单一组件的失效能导致整个系统崩溃。
功能安全等级:L4系统的核心芯片及其内部IP必须满足汽车行业最高的功能安全等级——ASIL-D。这要求在芯片设计、验证、制造的全流程中都遵循ISO 26262标准的严苛规范。
微观架构的演进
算力和安全需求的差异,最终体现在芯片的微观架构上,包括计算核心的类型与配置,以及内存系统的设计。
计算核心:从通用走向高度异构与专用
L2+和L4芯片普遍采用异构计算架构,但其复杂度和侧重点截然不同。
L2+芯片架构通常集成多个CPU核心(如ARM Cortex-A系列)用于任务调度和通用计算,一个中等规模的GPU用于图像处理和并行计算,以及一个或多个专门的AI加速器(NPU或DLA)来执行神经网络推理。其设计更侧重于能效比和成本控制。
L4芯片则是异构计算的极致体现。它集成了更多、更强的处理单元:
高性能CPU集群:通常包含多组、多核心的高性能CPU(如ARM Cortex-A78AE),以应对复杂的操作系统和上层应用软件。
超大规模GPU:用于传感器原始数据的预处理、特征提取以及部分AI模型的并行计算。
强大的AI加速器阵列:这是L4芯片的核心算力来源。它不再是单个NPU,而是由多个深度学习加速器(DLA)或神经处理单元(NPU)组成的阵列,专门为大规模神经网络运算进行优化。
专用安全岛:集成专用的安全处理器,负责实时任务处理、系统监控、故障诊断和安全策略执行,独立于主计算集群运行,确保在主系统异常时仍能执行安全关键操作。
图像信号处理器:为处理多路高清摄像头输入,L4芯片集成了性能强大的ISP,进行高质量的图像处理。
(3)内存体系:带宽与容量的飞跃
数据是自动驾驶的“燃料”,而内存系统就是输送燃料的“管道”。
由于数据处理量相对较小,L2+芯片通常搭配LPDDR4或LPDDR4X内存,其带宽和容量足以满足需求。片上缓存的规模也相对有限。
L4系统面临着巨大的数据洪流,内存带宽成为关键瓶颈。为了“喂饱”强大的计算核心,L4芯片必须采用更高带宽的内存技术:
功耗与散热
随着算力的飙升,功耗和散热成为制约高级别自动驾驶芯片发展的关键物理瓶颈。
L2+芯片的设计目标之一是实现高能效比。其功耗通常控制在几十瓦以内。
L4芯片的功耗常常高达数百瓦,这给车辆的能源系统和热管理带来了巨大挑战。高功耗直接影响电动汽车的续航里程。因此,L4芯片必须:
采用先进工艺:普遍采用7nm、5nm甚至更先进的半导体制程,以在提升性能的同时控制功耗。
依赖复杂散热方案:高功耗密度使得风冷捉襟见肘,必须采用更高效的散热技术,如液体冷却系统,这增加了整车设计的复杂性和成本。
软硬件协同优化功耗:通过动态电压频率调整(DVFS)、时钟门控、任务智能调度等软硬件协同设计策略,在保证实时性的前提下,最大限度地降低系统平均功耗。
展望2026年及以后,为了应对L4及更高级别自动驾驶的挑战,芯片架构正朝着新的方向演进。
Chiplet架构:传统的单片SoC设计在面临超大算力需求时,遇到了良率和成本的瓶颈。Chiplet技术通过将不同功能的模块(如CPU、AI加速器、I/O)分别制造在独立的“小芯片”上,再通过先进封装技术将它们集成在一起,成为构建L4及以上级别高性能计算平台的重要趋势。
这种模式提供了更高的灵活性、成本效益和可扩展性。
3D堆叠与集成:为了进一步缩短数据通路、降低延迟和功耗,3D堆叠技术被视为突破性的架构创新。通过在垂直方向上堆叠逻辑和存储单元,可以实现前所未有的集成密度和性能,这对于需要极致访存性能的自动驾驶芯片极具吸引力。
神经形态计算:作为一种模仿人脑工作原理的新型计算范式,神经形态计算以其事件驱动、超低功耗和实时处理的特性,在自动驾驶的感知和决策领域展现出巨大潜力。它有望在未来处理特定任务时,提供远超传统架构的能效。
软硬件协同设计:这已成为高级别自动驾驶芯片设计的行业标准。芯片厂商(如NVIDIA)、系统供应商和车企(如Tesla)越来越倾向于从应用场景和软件算法出发,定制化设计硬件架构,以实现算法与硬件的最佳匹配,从而榨取每一瓦特的极致性能。
—end—
推荐阅读:
汽车电子架构演进与芯片变革:从分布式ECU到集中式SoC
2025中国AI芯片产业融资赛道与商业化生态深度剖析
一文详解汽车AI芯片类型与市场格局
除了自动驾驶,汽车芯片还受哪些汽车技术影响?
联发科MT8678芯片解析:3纳米工艺与三丛集CPU架构
2025年中国芯片上市企业的突围与展望