作者:王多鱼,加油
地址:https://zhuanlan.zhihu.com/p/1967328211483460994
经授权发布,如需转载请联系原作者
我去年学习过sparse drive,但是那会没有搞懂。这次我们先学习一下传统基于模块的自动驾驶是怎么做的。然后学习一下端到端到底是如何替换了传统模块方案对应功能的。
模块化方案基于dense(稠密)的bev输出车道线和障碍物的信息,纯视觉方案你能根据摄像头内参外参和深度信息计算到车道线和障碍物相在你自车坐标系的位置。然后融合模块如果不考虑多传感器的情况下,需要基于比如传统匈牙利算法或模型对感知检测的障碍物进行trick跟踪,感知输出的是离散检测框,跟踪需解决跨帧同一性(即ID一致性)。跟踪的目的是关联跨帧检测结果,形成连续轨迹。融合模块能自动拿到实时变化的障碍物信息,然后把这个信息给到planning模块,planning模块需要融合的感知数据+定位信息+高精地图信息(暂时不考虑轻图方案)。等于你把你车的坐标信息,速度信息,障碍物信息放到了高精地图的坐标系里,然后你就知道了车道线在哪里,你的前车后车信息,然后你就可以给方向盘和脚踏板发信息,来实现控车。控车用一些传统算法,pid和lqr和mpc等控制横向纵向速度。
到此就是我见过的简化后的全套自动驾驶源码的精髓了。基于这个我们聊端到端,本次我们聊不了vla,vlm,因为这俩车端一般硬件帧率还是到不了10hz。那么基于sparse drive等端到端方案到底做了哪些事情。这种方案只到planning,不包括control。
核心工作:
1)需要取代融合,取代目标物的trick跟踪。如果有激光雷达,融合也是模型直接做。
2)基于自己trick目标+定位+地图信息,计算得到最佳路径。
3)在地平线片子上跑全局的bevformer的资源已经不容易了,你模型又加了这么多注意力关连,帧率达不到控车要求,所以需要基于planning优先的sparse(稀疏)方案。
我学习依赖的基础知识是两句话,attention is all you need和压缩即智能。
压缩能还原的基础是有attention。attention就是一切,大到天体运行,小到性压抑。而attention就是算点积。点积的注意力是无论是npu还和gpu都是最佳的计算方式,无论是啥脉冲矩阵还是mac矩阵,无论是tensor core还是cuda core。
Sparse4D v1 能实现目标物跟踪,等于实现了融合模块的匈牙利匹配算法。Sparse4D v3再上面基础上增加了planning的部分。
Sparse4D 把“实例 query”同时当3D 检测框、轨迹 ID 和规划障碍物;用递归 attention 完成时序一致性,用稀疏 plan query 直接回归轨迹,从而把“跟踪”和“规划”都压缩进同一条稀疏 query 序列里,端到端可训练,无手工后处理。
真正的端到端方案是sparse drive,它的感知部分和sparse 4D是类似的。
2.1 sparse drive
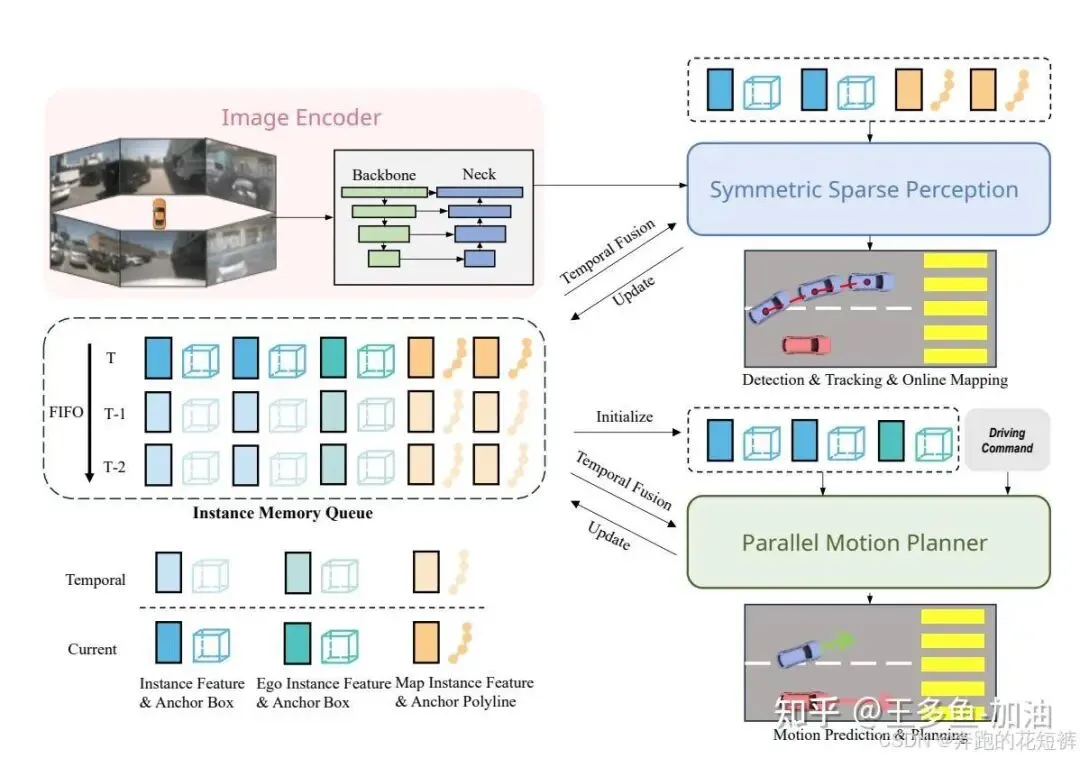
SparseDrive是一种端到端自动驾驶的新范式,它通过稀疏场景表示和并行运动规划器来提升效率。SparseDrive包括一个对称的稀疏感知模块和一个并行的运动规划器。对于一个实例(动态道路使用者或静态地图元素),SparseDrive用解耦的实例特征和几何anchor来完整地表示该实例。稀疏感知模块采用对称的模型架构,学习完全稀疏的场景表示,整合了检测、跟踪和在线建图任务。在并行的运动规划器中,首先从自车实例初始化模块获得一个语义和几何感知的自车实例。有了自车实例和从稀疏感知获得的其它交通参与者的实例后,同时进行运动预测和规划,获得所有道路使用者的多模态轨迹。为了确保规划路径的合理性和安全性,使用一个分层的规划选择策略(融合了碰撞感知重打分模块),从多模态候选轨迹中选取最终的规划轨迹。SparseDrive在所有任务的性能上都大幅度领先于当前的SOTA方法,并实现了更高的训练和推理效率。
SparseDrive通过稀疏表示技术来提高自主驾驶的性能和效率。稀疏感知模块统一了目标检测、跟踪和在线映射任务,通过对环境场景的稀疏特征表示来提升系统对环境的理解。该模块的结构对称,将周围动态代理(如其他车辆和行人)和静态地图元素(如道路和交通标志)统一为稀疏实例表示。各实例利用变形聚合、前馈网络和输出层进行更新和分类。该模块包含多个解码器,其中一个非时序解码器用于初始化新的实例,而多个时序解码器用于处理历史帧的信息,增强目标检测和跟踪的准确性。
SparseDrive的架构包括三个部分:图像编码器、对称的稀疏感知和并行的运动规划器。给定多视图图像,图像编码器包括主干网络和neck,首先将图像编码为多视图、多尺度的特征图。在对称的稀疏感知模块,将特征图聚合为两组实例,学习驾驶场景的稀疏表示。这两组实例分别表示其它交通参与者和地图元素,输入进并行的运动规划器,和初始化的自车实例做交流。运动规划器同时预测其它交通参与者和自车的多模态轨迹,通过分层规划选取策略,选择一条最安全的轨迹作为最终规划的结果。
SparseDrive不依赖高精地图,只依赖车辆自身的感知系统自动建图。可以提前建出大约200米的轻图。
核心有两个模块:
2.4.1Symmetric Sparse Perception
(1)该模块统一实现三个任务:动态目标检测、多目标跟踪、在线地图构建,结构如下图所示
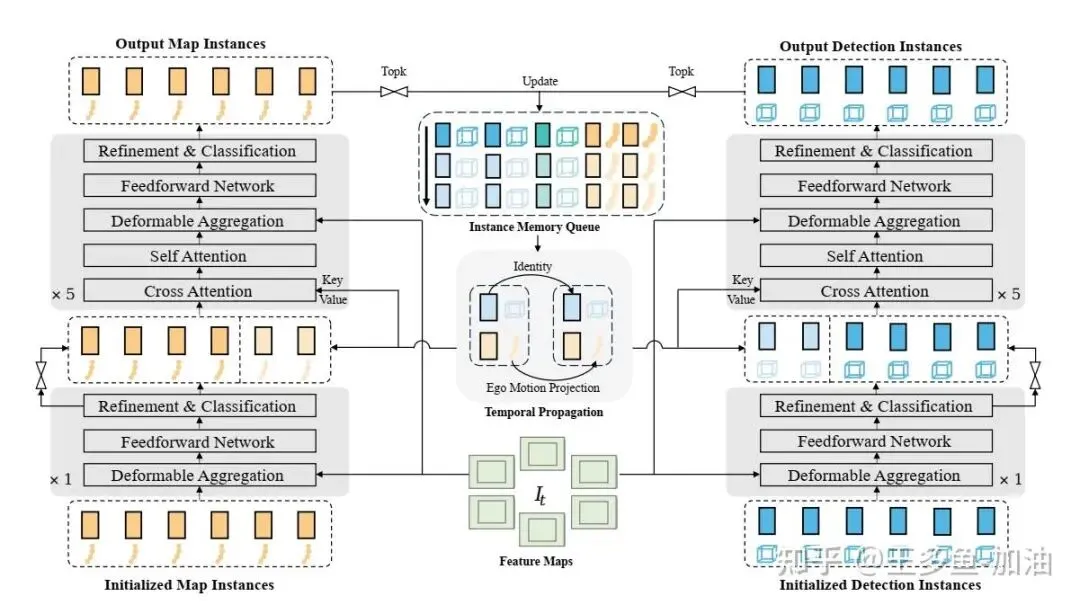
(2)来自多视角图像经过Encoder编码后的多尺度图像特征图。对于动态目标定义Anchor为B_d ∈ R^(N_d × 11),包括x, y, z, log(w), log(h), log(l), sin(yaw), cos(yaw), v_x, v_y, v_z。对于地图元素定义Anchor为L_m ∈ R^(N_m × N_p × 2),表示N_p个点组成的折线,每个Anchor通过K-Means对训练集聚类进行初始化。在Decoder中,通过Deformable Attention在特定空间位置采样图像特征,得到该Anchor对应的实例特征向量,经过通过一个MLP回归出相对于Anchor各个维度的Offset对Anchor进行更新。在Temporal Decoder中还对实例特征向量增加了不同帧之间的Temporal Cross-Attention以及当前帧的Self-Attention。 (3)对于Tracking部分,采用类似Sparse4Dv3的方法,不引入额外Tracking损失,若检测得分超过阈值(T_thresh=0.2),赋予唯一ID并在后续帧中保留,依靠特征的一致性完成Tracking,避免复杂的数据关联逻辑,具体而言就是在Temporal Decoder会将前一帧的实例特征(带有ID)传播到当前帧,因为这些特征带有语义与空间信息,Transformer的Temporal Cross-Attention能够学习哪个当前帧实例与哪个历史帧实例最相似,从而将历史ID传递到当前帧的相应实例上,不需要IOU匹配、不需要手工关联策略,只靠Attention中Learnable特征的相似性实现Tracking。
2.4.2 Parallel Motion Planner
(1)作者观察到Motion Prediction与Motion Planning的三点相似性:都需要建模交通参与者之间的高阶交互,都依赖语义+几何信息,都具有多模态不确定性
(2)Ego车辆初始化:特征的初始化由于Ego位于车体中心图像盲区,无法直接用Deformable Attention提取图像特征,所以采用前视图最小特征图做平均池化,使用前视图是因为前视图能看到即将进入驾驶路径的环境,是最相关的上下文信息源。Anchor的初始化中位置信息从车辆状态获知,速度部分避免直接使用真实值(防止泄露标签),通过预测前一帧的速度进行初始化,辅助任务预测当前Ego状态(速度、加速度、转向角等)。
(3)空间-时间交互:将 Ego 和其他车辆实例合并,然后执行 3 种交互注意力操作:Agent-Temporal Cross Attention、Agent-Agent Self Attention、Agent-Map Cross Attention
(4)多模态轨迹预测:预测轨迹结果为τ_m ∈ R^(N_d × K_m × T_m × 2),轨迹预测得分为s_m ∈ R^(N_d × K_m),自车规划结果得分为τ_p ∈ R^(N_cmd × K_p × T_p × 2),自车规划轨迹得分为s_p ∈ R^(N_cmd × K_p),其中K_m、K_p为预测/规划模式数(如:直行、左转、右转,论文中值为6),T_m、T_p未来时间步数,论文中值为6,N_cmd = 3为驾驶指令个数(左转、右转、直行)
(5)分层规划轨迹选择:第一步根据高阶驾驶指令筛选子集轨迹,第二步利用预测到的其他实体轨迹,评估Ego与之是否会碰撞,对高碰撞风险轨迹降分甚至置0,第三步选择最高分轨迹作为最终输出,相比UniAD的后处理优化方式,作者证明该方式更安全,且保持端到端结构闭环。 整个模型的损失函数为: L = L_det + L_map + L_motion + L_plan + L_depth。
//todo 对着代码,深入研究一下网络结构的设计。
2.2 为啥sparseDrive不需要Rv模型
Sparse4D/SparseDrive 之所以能“看得远”,核心不是镜头变长,而是“纯稀疏查询”+“时序金字塔”+“多尺度 anchor”三件套,避开了 BEV 网格在远场的分辨率陷阱。具体原因如下:
传统 BEVFormer 必须把图像特征先拍成 50×50 或 100×100 的稠密鸟瞰图,一格 0.5 m——100 m 处只占 2 格,信号被“稀释”。
Sparse4D 直接用 稀疏实例 query(典型 400900 条)做可变形交叉注意,每条 query 可在任意 3D 位置采样多尺度图像特征,不受格子大小限制,远处目标也能分到 1632 个采样点,特征不会“被平均”。
- 动态 query:在 0.5 m120 m 范围内按 对数间隔预置 anchor,越远 anchor 越密(0.5 m→0.8 m→1.2 m…→120 m),保证 100 m 外仍有足够候选。
- 静态地图 query:最远 400 m×400 m 区域均匀撒点,每条负责 20 m×20 m 区域,比 BEV 0.5 m 格子大 40 倍,用密度换距离。
同一实例 query 在 T=9 帧里递归传播,远处小目标在 9 帧图像里累积 9×16=144 个采样点,等效“凝视”效果,SNR 提升 3-4 dB,检测阈值下降。
地平线 2024 发布会给出 SuperDrive(Sparse4D-v3 内核)指标:
- 动态车辆追踪 2 km(靠 400 m 有效检测 + 运动补偿外推)
- 100 m 处车辆检测 mAP 比 BEVFormer 高 3.9 点
因为“无稠密 BEV”,Sparse4D 200 m 感知范围内 FLOPs ∝ 实例数×采样点,与距离无关;BEV 要保持 0.5 m 分辨率,200 m 需 400×400=160 k 格,显存爆炸,Sparse4D 仍只需 900 条 query,推理速度 17 FPS vs BEVFormer 1.7 FPS 。
结论:Sparse4D 用稀疏 query + 对数 anchor + 时序累积三招,跳出“远场=低分辨率”诅咒,所以能在不增加算力的前提下把可靠感知距离从 50 m 拉到 400 m,甚至 2 km 追踪。
2.3 sparse 4D支持OCC占用网格能力吗
SparseDrive 的静态地图分支输出 400 m×400 m 稀疏 occupancy 点,动态分支 100 m 内靠实例,100-400 m 靠地图点云补盲;即使近处 query 全丢,仍可用地图 occupancy 做碰撞检查,高速 NOA 场景已验证 。
2.4 sparse 输出几条planning 轨迹线
根据模型直接输出单条轨迹与否,端到端智驾系统可划分为单模轨迹范式和多模轨迹范式。单模轨迹范式直接输出单条轨迹,通常根据预设规划时间(如5秒)、单位时间内轨迹点数目(如每秒5个)等信息,轨迹输出头中使用全连接层直接回归出输出轨迹,较早期的端到端框架如UniAD、VAD、Transfuser均采用该范式。由于其他道路参与者的意图具有不可预测性,且不同的道路条件和人类驾驶员行为会引入的模糊性,最优轨迹预测本质上是随机的。单模轨迹范式具有环境和响应动作间存在确定性关系的假设,然而这种确定性假设与实际场景并不相符,尤其当场景复杂、以至于当可行解空间是非凸的时。基于此,多模轨迹范式最近受到了诸多关注,该范式的核心是模型并不输出确定性的单条轨迹,而是同时输出多条轨迹、及轨迹的概率分数;下游可综合轨迹概率分数、安全性、舒适性、效率等因素得出轨迹最终得分,选择分数最高轨迹作为控制模块输入。
Sparse drive输出6条轨迹线,由planning 的后处理模块来决定使用哪个。
我发现无论是bevformer 还是sparse 4D 还是sparse drive,开源的python代码都是基于mmdet3d框架来实现的。py配置文件定义了训练和推理的全部信息,包括模型信息,输入输出信息、训练数据集信息等。mmdet这个框架会根据这个配置文件生成模型,然后调用对应的test和train能力。我发现mmdet这个框架会依赖mmcv这个lib,想deform attn这种新算子都是再mmcv里面实现的。bevformer 还是sparse 4D 还是sparse drive的mmdet plug定义的plug文件都是一个壳子,本质还是调用了mmcv的接口(我个人感觉你也可以用cuda来手写算子,然后用pybind11 注册到python接口里)。
mmcv有两个接口python的和cpp的。我目前看到的python接口的具体实现都是手写cpp代码来实现,根据本平台我发现有npu cpu gpu等,不同的硬件平台它都手撸了一套。这些cpp的接口用pybind 给注册为了python接口,也符合python first的使用习惯。
到这里就基本感觉搞懂了代码层级,下一步就是对具体的特定算子的分析了。
//我因为能力差,总是得从一个非常基础的点引出来答案。我看到的讲端到端的文章都上来太复杂了,基础不够的其实一头雾水。我一直觉得的一点是,当你明白上下文,其实你已经懂了1/3