在自动驾驶领域,全局定位始终是绕不开的核心难题。依赖高精地图的传统方案成本高昂、可扩展性差,GPS又在城市密集区域频频“掉链子”,跨模态定位虽有尝试却受限于传感器标定和场景泛化能力。今天要分享的这篇顶刊级论文,提出了名为LSV-Loc的跨模态定位框架,仅凭单次激光雷达扫描和公开街景图像,就能实现无先验地图的3自由度粗粒度定位,为城市自动驾驶定位提供了全新思路!
论文信息
题目:LSV-Loc: LiDAR to StreetView Image Cross-Modal Localization
LSV-Loc:激光雷达与街景图像的跨模态定位
作者:Sangmin Lee, Donghyun Choi, Jee-Hwan Ryu
一、痛点直击:现有定位方案的三大“卡脖子”问题
自动驾驶想要精准导航,首先得知道“自己在哪、朝哪走”,但现有方案始终存在难以突破的瓶颈:
- 高精地图依赖症:生成高清地图需要昂贵的移动测绘系统和重复采集,不仅成本高,还只能覆盖已测绘区域,未勘测地带直接“失灵”;
- 传感器局限性:GPS在城市高楼区、隧道等场景信号衰减严重,额外加装定位传感器又会增加部署成本和复杂度;
- 跨模态适配难:此前的跨模态定位方法需预先记录参考数据,且传感器模态不匹配时泛化能力大幅下降,无法应对未知环境。
而LSV-Loc的核心突破,正是摆脱了对高精地图、GPS初始化和传感器标定的依赖,仅用激光雷达和公开街景图像就实现了鲁棒的全局定位。
二、核心创新:四大亮点打破传统定位桎梏
LSV-Loc之所以能实现上述突破,核心在于四大关键创新设计:
1. 跨模态共享嵌入空间:让激光雷达与街景图像“说同一种语言”
论文提出基于权重共享的视觉Transformer(ViT)编码器,将激光雷达强度图像和地理标记的街景全景图映射到同一共享嵌入空间。这一设计摒弃了模态特定的特征提取方式,强制网络关注建筑立面、道路边界等跨模态一致的语义线索,无需预先标定就能实现鲁棒的跨模态检索和粗粒度定位。
2. 等距柱状投影PnP求解器:搞定航向不一致的核心难题
激光雷达与街景图像的朝向差异,是影响定位精度的关键障碍。为此,论文设计了等距柱状投影的PnP求解器,利用注意力引导的块级特征对应关系,在等距柱状图像域内求解相对姿态,把定位结果从单纯的“认地点”升级为包含精确航向估计的3自由度粗粒度定位。
3. 单次扫描定位:零先验也能实现全局定位
该框架仅需单次激光雷达扫描和公开街景图像即可完成全局定位,完全摆脱了对昂贵高精地图、GPS初始化的依赖,借助公共街景数据的可扩展性,大幅提升了在未知城市环境中的部署能力。
4. 端到端两阶段流程:无缝衔接地点识别与度量定位
LSV-Loc构建了“地点识别+位姿精修”的两阶段框架:第一阶段通过跨模态对比学习完成地点识别,第二阶段利用块级特征通过等距柱状PnP求解器精修航向与位置,实现了完整的3自由度位姿估计。
三、方法详解:LSV-Loc的核心实现逻辑
LSV-Loc的整体框架分为两大核心模块——跨模态地点识别网络和等距柱状投影PnP求解器,整体结构可参考下图:
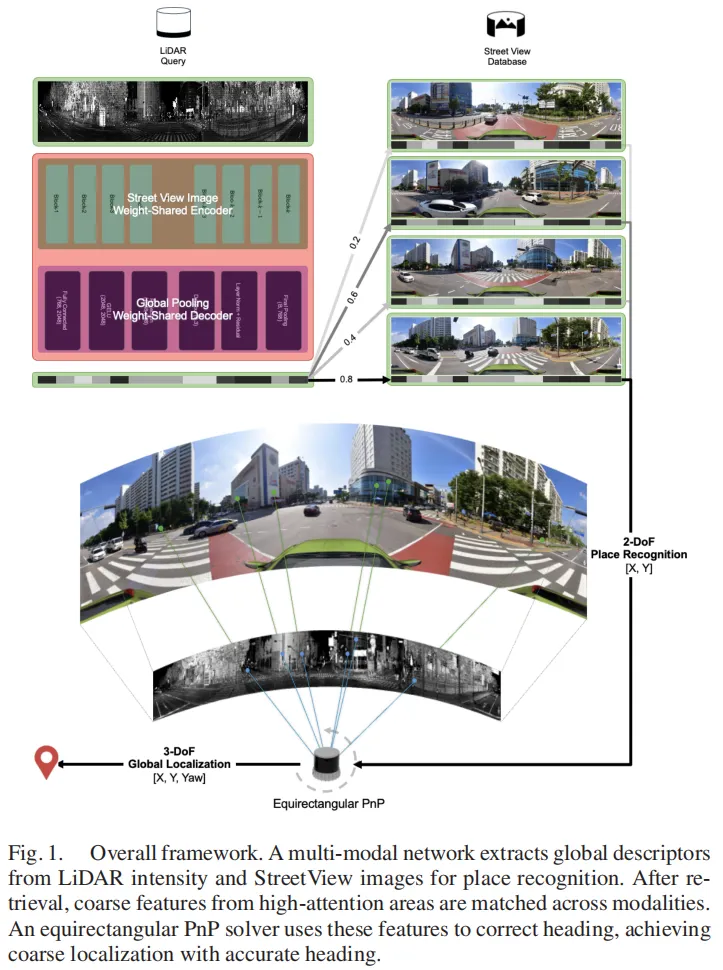 图1
图1第一步:地点识别——先“认对地方”
1. 等距柱面图像投影:统一几何结构
首先将激光雷达点云投影到等距柱面图像坐标系,使其几何结构与街景全景图的360°二维结构对齐(两者均遵循一致的经纬度映射)。同时裁剪掉天空、车辆遮挡等无信息区域,仅保留90°垂直视场的有效区域,减少模态差异的同时保证空间对应关系。
2. 权重共享的ViT编码器:提取跨模态一致特征
采用DINOv2预训练的ViT-B作为共享编码器,分别处理激光雷达强度图像和街景全景图。通过共享权重强制生成模态无关的嵌入特征,再借助[CLS]标记提取全局场景描述符,最后用InfoNCE损失优化,让同一位置的跨模态描述符“聚在一起”,不同位置的“分开”,实现高精度地点识别。
第二步:全局定位——再“算准姿态”
地点识别只能确定大致位置,航向估计才是路径规划的关键。LSV-Loc通过以下步骤实现3自由度位姿估计:
- 注意力引导的特征匹配:从ViT编码器提取块级特征,筛选出注意力分数前10%的高置信度特征,通过互最近邻过滤保证匹配鲁棒性;
- 3D点重建与重投影:利用激光雷达距离信息重建3D坐标,并将其重投影到等距柱面图像平面,与街景特征坐标对齐;
- 鲁棒优化求解位姿:通过带有Huber损失的最小二乘优化,求解平面3自由度位姿(偏航角+2D平移),即使没有相机内参和高精地图,也能精准估计航向。
四、实验验证:性能碾压现有方案,鲁棒性拉满
为验证LSV-Loc的有效性,作者在MulRan、STheReO等多个公开激光雷达数据集,以及内部采集的城市数据集上开展了全面测试:
1. 召回准确性:全序列领先现有方法
以25米为正确匹配阈值(粗粒度定位常规标准),LSV-Loc在所有测试序列中召回率均显著高于LiP-Loc、LC2、AECM-Loc等主流跨模态定位方法,即使面对窄视场、低分辨率的激光雷达配置,零样本泛化性能依然领先。
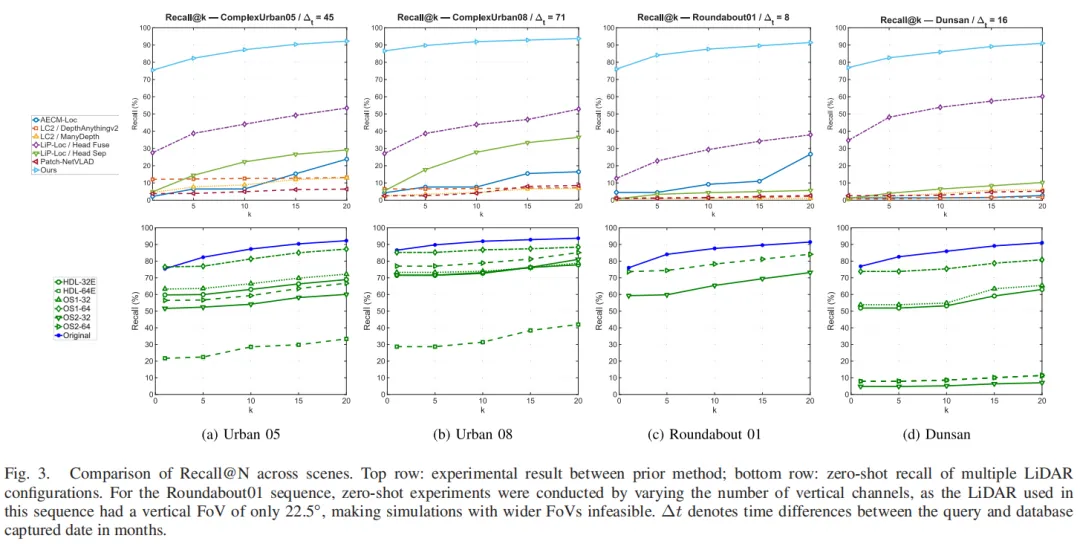 图3
图32. 定位准确性:航向误差大幅降低
实验结果显示,相比单纯的地点识别,LSV-Loc通过等距柱状PnP求解器能显著降低航向误差,即使存在跨模态视点差异,航向估计依然精准;虽因块级特征粒度限制,位置误差未明显降低,但已足够满足粗粒度定位需求。
 图4
图43. 消融实验:验证核心设计的必要性
替换共享权重编码器为独立编码器后,Recall@1从74.65%暴跌至48.64%,证实统一的共享嵌入空间是跨模态特征对齐的核心;投影池化模块的消融也表明,该设计能有效提升特征可区分性。
五、局限性与未来方向
尽管LSV-Loc表现优异,但仍存在一定局限性:
- 块级特征的空间粒度有限,难以实现厘米级的精确度量定位;
- 仅适配旋转式激光雷达,与MEMS/闪光激光雷达不兼容;
- 互最近邻搜索成为运行时瓶颈(整体框架运行频率约9-10Hz)。
未来研究将聚焦于:提升低分辨率激光雷达下的鲁棒性、适配更多激光雷达架构、融合细粒度几何对齐模块实现更高精度定位。
六、总结
LSV-Loc的提出,为自动驾驶跨模态定位提供了全新的轻量化方案——无需高精地图、无需GPS初始化、无需传感器标定,仅靠激光雷达和公开街景图像就能实现3自由度粗粒度定位。其共享嵌入空间+等距柱状PnP的核心设计,不仅解决了跨模态异构性和航向不一致问题,还大幅提升了定位方案的可扩展性和部署效率,为城市环境下的自动驾驶定位开辟了新路径。
对于自动驾驶研发人员而言,这一方法既降低了定位方案的成本,又提升了未知环境的适配能力,值得深入研究和落地尝试。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
