
🐉 龙哥读论文知识星球来了!还在为自动驾驶的算力瓶颈和网络延迟发愁?星球里不仅有这篇论文的深度拆解,更有海量边缘计算、V2X通信、模型优化的前沿论文和实战代码,帮你快速找到“云端协同”的解题思路!👇扫码加入「龙哥读论文」知识星球,解锁自动驾驶技术新视野~

龙哥推荐理由:
这篇论文把“车-云协同”玩出了新高度!它没有停留在简单的计算卸载,而是提出了一个动态自适应的混合计算框架,能根据实时网络带宽,智能调整模型分割点和量化精度,在保证实时性的前提下最大化感知精度。更难得的是,所有实验都在真实道路上跑过,不是纸上谈兵。对于做自动驾驶、边缘计算和网络优化的同学来说,这绝对是一个兼具工程实用性和学术启发性的绝佳案例。
原论文信息如下:
论文标题:
Bandwidth-adaptive Cloud-Assisted 360-Degree 3D Perception for Autonomous Vehicles
发表日期:
2026年02月
发表单位:
卢森堡大学跨学科安全、可靠与信任中心 (SnT), 瓦萨学院, 波尔图大学电信研究所
原文链接:
https://arxiv.org/pdf/2602.23871v1.pdf
开源代码链接:
https://gitlab.com/rui-meireles/cloud-assisted-perception
想象一下,你开的是一辆未来感十足的自动驾驶汽车,周身环绕着六个高清摄像头,每秒都在疯狂捕捉周围世界的图像。这些图像需要立刻被一个强大的AI模型处理,识别出哪里是车、哪里是人、哪里有障碍物,并实时计算出3D的鸟瞰图,为决策系统提供“眼睛”。
但问题来了:这么厉害的AI模型(比如文中用到的BEVFormer),计算量巨大,而车上的“大脑”——车载计算芯片(如NVIDIA Jetson)——算力有限,还受到功耗和散热的严格限制。
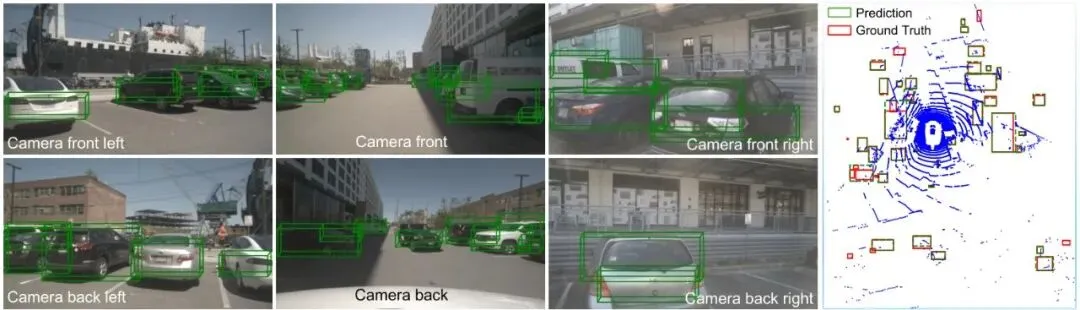
结果就是:处理一帧图像要花将近700毫秒!这远超出自动驾驶实时感知通常要求的100毫秒红线。感知系统慢半拍,就像人反应迟钝,在复杂的城市路况下极其危险。图7:在nuScenes数据集上,使用分割层3和FP16量化得到的360度BEV感知及多视角相机图像的3D边界框预测结果可视化。可以直观感受下车辆“看到”的世界。
怎么办?卢森堡大学SnT中心等机构的研究者们提出了一个非常接地气的思路:算力不够?让云来凑!
他们不是简单地把所有计算扔到云端(那样网络延迟受不了),而是设计了一套“动态协同流水线”。简单说,就是让车和云分工协作:车辆负责前期的、轻量的特征提取,然后把提炼过的“中间成果”(特征向量)通过5G/V2X网络传给云端;云端凭借其强大的GPU算力,完成剩余繁重的计算,最终得出3D检测结果。
更妙的是,这套分工不是固定的。它能根据实时网络带宽的好坏,智能调整“分工线”(分割层)的深浅,以及数据传输的“精简程度”(量化精度),目标是在严格的延迟约束下,尽可能保住感知的准确性。
车载算力捉襟见肘?让云端来帮忙!
这个研究的核心是一个叫做 BEVFormer 的模型。简单理解,它就像一个高级拼图大师,能把车辆周围多个摄像头拍到的2D画面,在脑子里(通过复杂的Transformer和注意力机制)拼合成一个统一的、上帝视角的3D地图(Bird‘s-Eye View, BEV)。在这个地图上,它能准确地标出每辆车、每个行人的3D位置和大小。
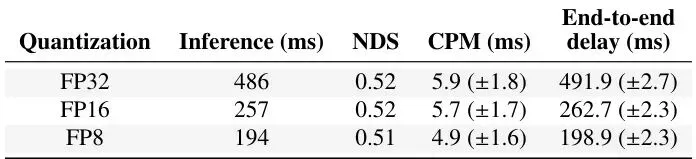
但BEVFormer的计算“胃口”很大。论文里用的版本以ResNet101作为主干网络,在车载Jetson Orin上跑一帧要673毫秒,即使经过TensorRT优化,用最快的FP8精度,也要194毫秒,还是达不到100毫秒的实时要求。
表2:BEVFormer模型(ResNet101主干)在车载平台上,经TensorRT不同量化级别优化后的性能指标。FP8量化下,端到端延迟为198.9毫秒,仍高于100毫秒目标。
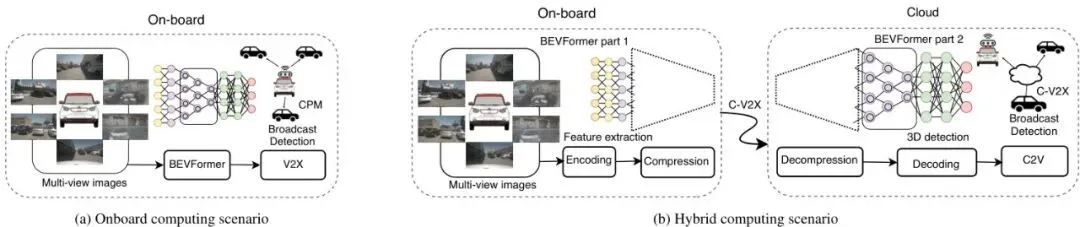
于是,“车云混合计算”的想法应运而生。它的核心理念是:把完整的BEVFormer模型从中间“切一刀”。前面几层(比如ResNet的前面几个Block)在车上跑,提取出初步的图像特征。然后,把这个“半成品”特征向量传上云端,由云端的强大GPU(文中用了4块Tesla V100)完成剩下的网络层、视角转换、BEV编码和最终的3D检测。
图1:纯车载计算与混合计算场景示意图。左侧是纯车载计算,BEVFormer模型完全在本地运行,检测结果通过ITS-G5发送。右侧是混合计算,压缩后的特征向量通过C-V2X发送到云端进行密集计算,检测结果广播给附近车辆。
1. 传输什么? 传原始图像数据量太大。传深层特征?可能已经损失了信息。所以选择了传中间层特征,这是一个平衡点。
2. 怎么传得快? 中间特征向量体积也不小。为此,论文用了三招“瘦身术”:量化(Quantization)(比如把FP32精度的数用FP16甚至FP8来表示)、裁剪(Clipping)(把特征值中极大和极小的“离群值”去掉,文中用了第10和90百分位),以及无损压缩(Compression)(用zlib算法)。
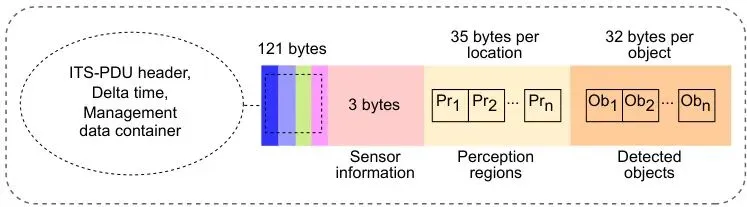
3. 结果怎么用? 云端算出的3D检测结果,会被编码成一种标准化的协同感知消息(Cooperative Perception Message, CPM),通过V2X广播给附近的其他车辆或基础设施,实现“车-路-云”协同感知,让大家的“视野”都更开阔。
图2:由ETSI标准定义的CPM消息格式中包含的不同容器的基本概述。确保不同厂商的系统能互相理解。
核心方法:动态分割与带宽自适应
“切一刀”说起来容易,切在哪里却大有讲究。这就是“分割层”(Split Layer)的选择问题。
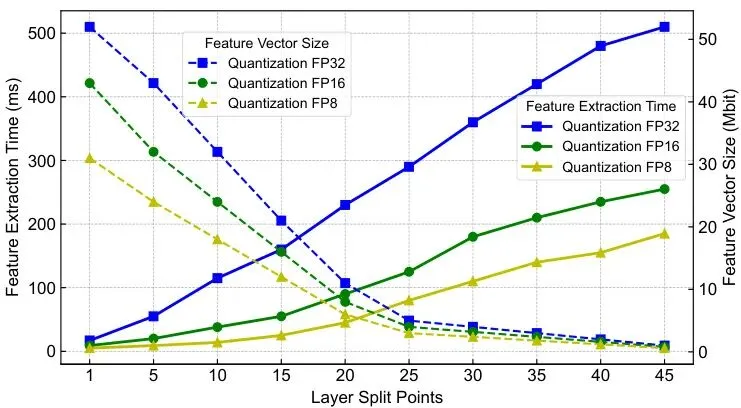
切得越早(比如在第1层之后切),车上算得越少,负担越轻,但需要上传的特征图尺寸越大,网络传输压力大。
切得越晚(比如在第5层之后切),需要上传的数据量小了,但车上要完成的计算变多,可能又会导致本地延迟增加。
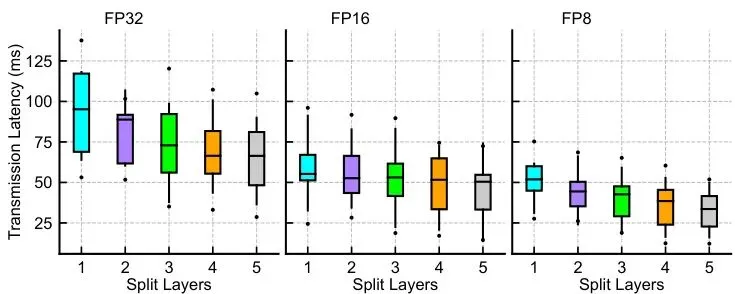
图4:特征向量大小和提取时间与分割层的关系。实线代表特征提取时间(左y轴),虚线表示特征大小(右y轴)。较低精度的量化(如FP16、FP8)同时减少了提取时间和特征大小。
同时,量化精度(Quantization Level)的选择也是个权衡。用FP8,数据量最小,传输最快,但可能损失更多信息,影响最终检测精度;用FP32,精度保留最好,但数据量大,传输慢。
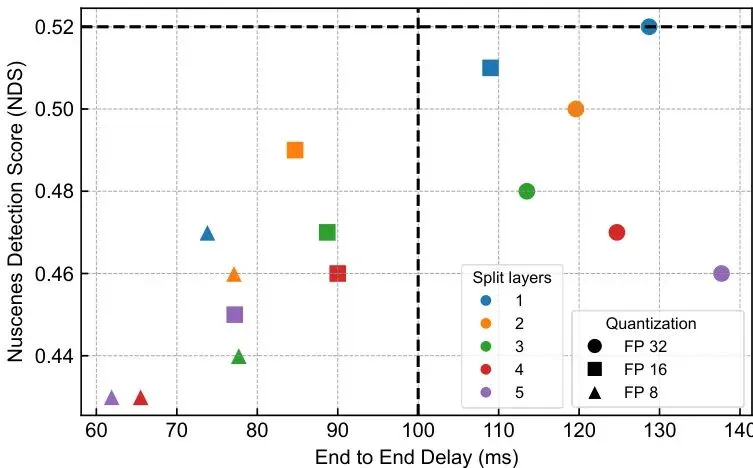
所以,这里存在一个经典的“延迟-精度”权衡(Latency-Accuracy Trade-off)。不同的(分割层,量化级别)组合,会得到不同的延迟和精度表现。
但事情还没完!车辆是在真实网络中移动的,5G/V2X的带宽是波动的。在市中心和郊区,在基站切换时,可用带宽可能天差地别。
如果你固定使用一套参数(比如“分割层=3, FP16”),那么在网络好的时候,你可能浪费了带宽潜力,明明可以用更高精度的模式;在网络差的时候,这套参数可能导致传输时间过长,总延迟超标,危及安全。
因此,这篇论文最精髓的部分来了:它不预设固定方案,而是提出一个“动态参数选择算法”。这个算法实时感知当前的网络上行/下行带宽,然后从所有可能的(分割层,量化级别)组合中,挑选出能在满足严格延迟约束(例如≤100ms)的前提下,让感知精度最高的那组参数。
这相当于给你的自动驾驶汽车配了一个智能的“网络状况自适应调度器”。网好时,多用高精度模式追求极致感知;网差时,果断切换到精简模式,优先保障实时性(不超时)。
实验结果:延迟大降,精度可控
光有想法不行,效果如何?研究者们在卢森堡的真实城市道路上进行了测试。
首先,他们验证了纯车载方案的瓶颈。即使经过TensorRT FP8优化,端到端延迟(本地计算+结果发送)也要198.9毫秒,而且本地GPU利用率高达65%,没有余力处理其他任务。
然后,切换到混合计算模式。当选择合适的分割层和量化参数时,端到端延迟可以大幅降低。
表4及图6:不同分割层和量化级别的性能指标,以及端到端延迟与检测精度的权衡关系。图中绿色高亮行表示延迟低于100ms的方案。可以看到,混合计算方案下,许多配置都能将延迟压到100ms以下。
论文中给出了一组对比数据:在相同量化级别(FP8)下,混合计算方案相比纯车载方案,平均实现了72%的端到端延迟降低!
精度方面,他们使用nuScenes数据集的标准评价指标NDS(nuScenes Detection Score)来评估。NDS是一个综合分数,兼顾了检测的准确率(mAP)和各类误差(如位置、大小、方向等)。
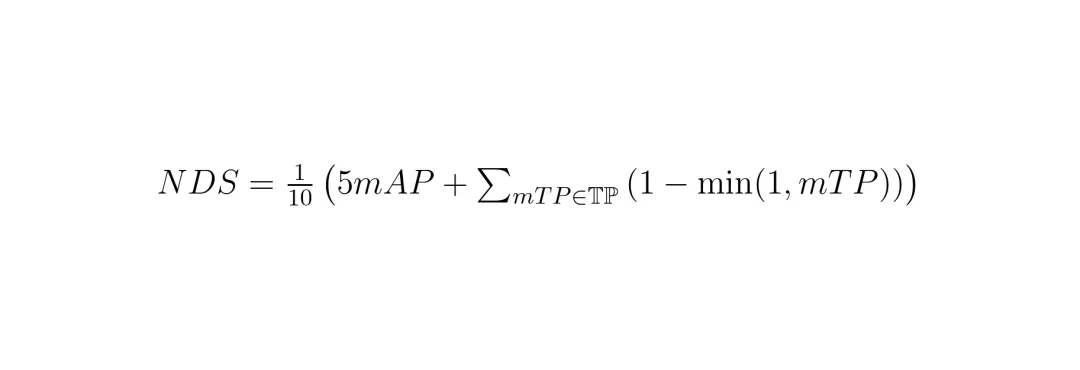 NDS计算公式。它是一个0到1之间的值,越高越好。
实验表明,通过精心选择分割层和量化级别,可以在将延迟降低到实时范围内(<100ms)的同时,将NDS精度损失控制在可接受的范围内。例如,某个配置下NDS为0.47,虽然比纯车载FP32的0.52有所下降,但换来了延迟从近500ms降到100ms以内,这个交易对于实时系统来说是值得的。
图5:在5G C-V2X网络上,不同量化级别(FP32, FP16, FP8)下,五个分割层的特征向量从车辆到云端的传输延迟。FP8延迟最低最稳定。
NDS计算公式。它是一个0到1之间的值,越高越好。
实验表明,通过精心选择分割层和量化级别,可以在将延迟降低到实时范围内(<100ms)的同时,将NDS精度损失控制在可接受的范围内。例如,某个配置下NDS为0.47,虽然比纯车载FP32的0.52有所下降,但换来了延迟从近500ms降到100ms以内,这个交易对于实时系统来说是值得的。
图5:在5G C-V2X网络上,不同量化级别(FP32, FP16, FP8)下,五个分割层的特征向量从车辆到云端的传输延迟。FP8延迟最低最稳定。
动态优化算法:智能应对网络波动
静态配置已经能带来巨大提升,但动态优化才是将潜力完全释放的关键。研究者们利用在实际路测中收集的带宽波动数据(如图8所示),来验证动态算法的优越性。
图8:用于评估动态混合计算参数选择算法的实际上传带宽分布。带宽波动很大,均值和差异明显。
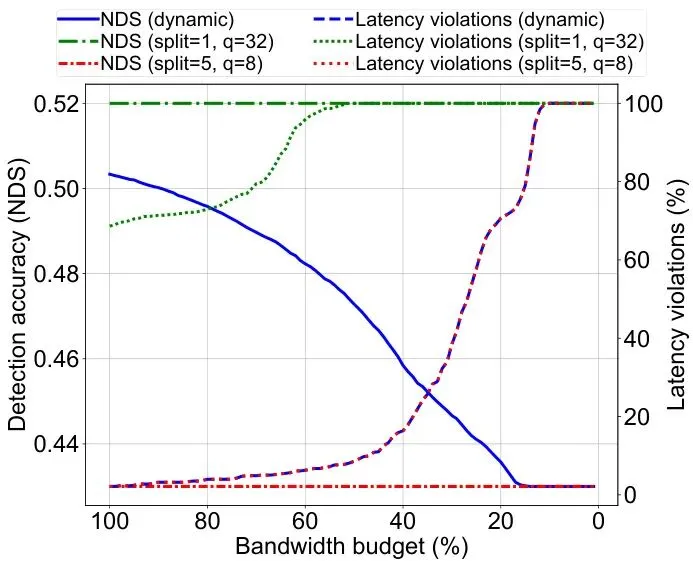
· 静态高精度策略: 永远使用最早分割层(split=1)和最高精度(FP32),追求极限精度,不顾延迟。
· 静态低延迟策略: 永远使用最晚分割层(split=5)和最低精度(FP8),追求极限延迟,牺牲精度。
动态算法的目标很明确:在给定当前带宽和严格延迟约束(latmax)下,选择能最大化NDS精度的参数组合(split, q)。这可以形式化为一个带约束的优化问题:
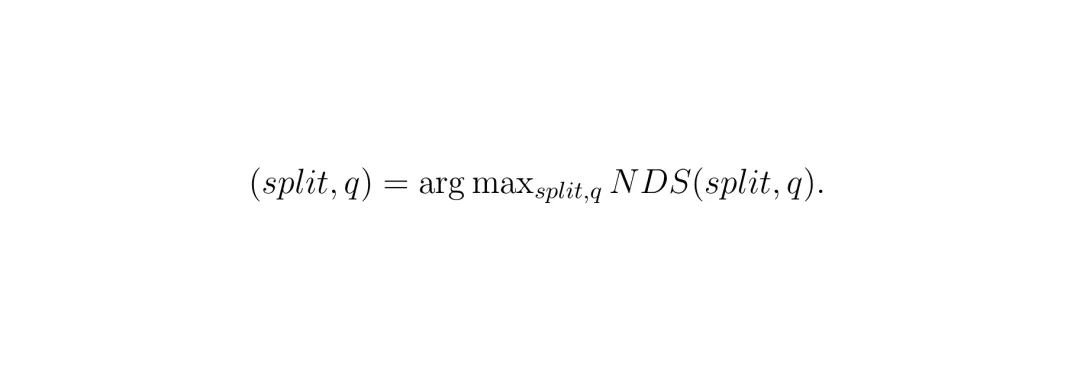 优化目标:在满足延迟约束的前提下,选择使NDS最高的(split, q)参数对。
优化目标:在满足延迟约束的前提下,选择使NDS最高的(split, q)参数对。
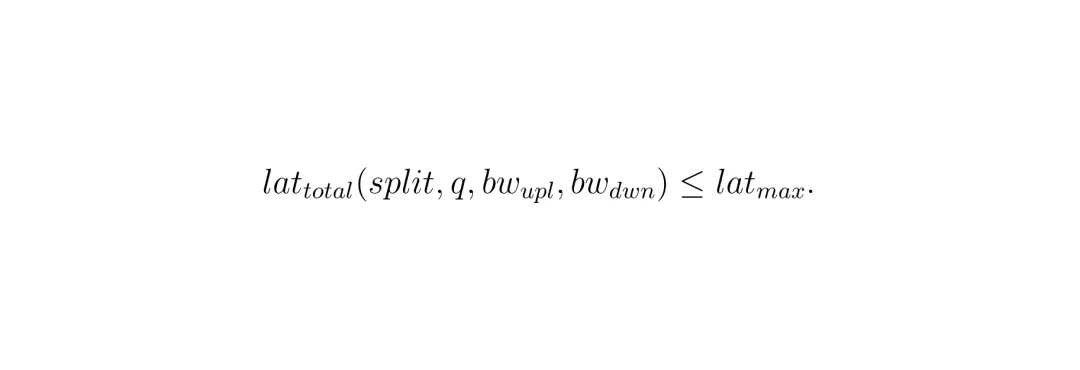 约束条件:总延迟(本地计算+上传+云端计算+结果下发)不能超过最大允许延迟latmax。
图10:动态算法与两种静态策略的对比。动态算法(蓝线)在几乎所有带宽条件下,都能在确保零延迟违规(右下子图)的前提下,取得比静态低延迟策略(红线)高得多的检测精度(左上子图)。
具体来说,在相同的延迟性能(即都不超时)下,动态自适应策略相比静态参数化策略,能将感知精度提升高达10%到20%!
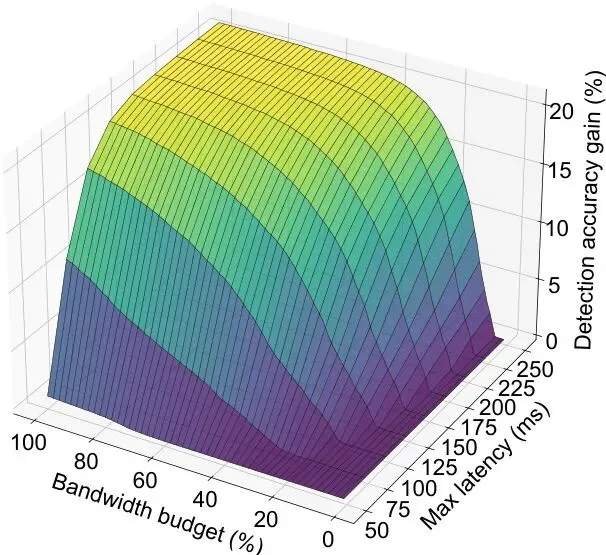
图11:动态选择算法带来的检测精度(NDS)增益,随分配给感知任务的带宽变化。在中低带宽区间,动态优化的增益最为显著。
约束条件:总延迟(本地计算+上传+云端计算+结果下发)不能超过最大允许延迟latmax。
图10:动态算法与两种静态策略的对比。动态算法(蓝线)在几乎所有带宽条件下,都能在确保零延迟违规(右下子图)的前提下,取得比静态低延迟策略(红线)高得多的检测精度(左上子图)。
具体来说,在相同的延迟性能(即都不超时)下,动态自适应策略相比静态参数化策略,能将感知精度提升高达10%到20%!
图11:动态选择算法带来的检测精度(NDS)增益,随分配给感知任务的带宽变化。在中低带宽区间,动态优化的增益最为显著。
未来展望:从单车智能到协同感知
这篇论文的价值,不仅在于它提出了一套行之有效的车云混合计算技术方案,更在于它清晰地指出了一条路径:通过深度融合通信(V2X)、边缘计算和人工智能,来突破单车智能的算力与感知瓶颈。
它把云端从单纯的“数据仓库”或“训练平台”,变成了实时感知流水线中不可或缺的一环。一个在本地快速初筛,一个在云端精细加工,形成了“边缘-云端”一体化的新型计算架构。
更进一步,云端处理完的结果以标准化CPM的形式广播出去,这又将单车智能引向了“协同感知(Cooperative Perception)”。你的车不仅能“看”自己传感器范围内的东西,还能“听”到云端或其他车辆“告诉”你视野之外的障碍物,真正实现了“眼观六路,耳听八方”。
当然,走向大规模应用前,还有一些挑战需要解决,比如:更极致的特征压缩编码、网络中断或高延迟下的降级与容错机制、多车任务在云端的调度与资源分配、以及安全与隐私问题等。
但毫无疑问,这篇论文为我们展示了一个充满可能性的未来。当汽车的“大脑”可以弹性扩展到云端,更复杂、更强大的感知与决策模型将得以部署,自动驾驶的安全性与智能水平有望迈上新的台阶。
龙迷三问
什么是BEVFormer?BEVFormer是一种基于Transformer的3D物体检测模型,专为自动驾驶设计。它最大的特点是能直接将多个环视摄像头拍摄的2D图像,通过注意力机制“投射”并融合成一个统一的鸟瞰图(Bird‘s-Eye View, BEV)特征表示,然后在这个BEV空间中进行3D边界框的预测。这样就绕开了传统方法中需要复杂后处理来关联多视角检测结果的步骤,实现了端到端的360度全景3D感知。
文中的V2X、C-V2X、ITS-G5都是什么?这些都是车用无线通信技术。V2X(Vehicle-to-Everything)是总称,指车与外界的一切通信。它主要包含两大技术路线:一是基于蜂窝网络的C-V2X(Cellular V2X,包括4G/5G),二是基于Wi-Fi改进的ITS-G5(在欧洲也称IEEE 802.11p)。本文中,纯车载计算场景使用ITS-G5广播最终的CPM结果,因为其广播特性好,延迟低且稳定;而混合计算场景使用C-V2X(5G)来上传特征向量到云端,因为其带宽更高,适合传输较大数据。
量化(FP32/FP16/FP8)具体是怎么减少数据量的?这涉及到计算机中如何表示一个浮点数。FP32(单精度)用32位(4字节)存储一个数,FP16(半精度)用16位(2字节),FP8则只用8位(1字节)。位数越少,能表示的数值范围和精度就越有限,但存储和传输所需的空间也成倍减少。例如,一个1000维的FP32特征向量需要4KB,而用FP8只需要1KB。在神经网络中,许多计算对精度并不极度敏感,适当降低精度(量化)可以在几乎不影响结果的情况下大幅提升速度、减少存储和带宽占用。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将成熟的模型分割、量化和V2X通信技术,与一个新颖的、基于实时带宽感知的动态优化算法相结合,构建了一套完整的自适应车云协同感知方案。思路清晰,集成度高,动态自适应是亮点。实验合理度:★★★★★
最大加分项在于真实道路、真实V2X通信环境下的测试,而非纯仿真。对比实验设置合理(纯车载 vs. 混合静态 vs. 混合动态),数据详实,延迟和精度指标测量完整,结论令人信服。学术研究价值:★★★★☆
为自动驾驶感知领域的“边缘-云端”协同计算提供了一个优秀的范例和详实的基线数据。其动态优化思想可扩展至其他计算密集型车载任务(如预测、规划),对后续研究有启发性。稳定性:★★★☆☆
高度依赖稳定且低延迟的无线网络连接。在隧道、信号盲区或网络极端拥塞时,系统性能会急剧下降甚至失效。需要强大的网络降级和本地备份策略作为安全保障。适应性以及泛化能力:★★★★☆
核心方法(分割、量化、动态选择)不依赖于特定感知模型,可适配其他BEV或非BEV的检测模型。但性能表现与具体的网络结构、特征分布密切相关,换模型需要重新分析和调整参数。硬件需求及成本:★★★☆☆
对车载硬件要求降低了(只需跑部分模型),但引入了持续的蜂窝网络流量费用和云端GPU租赁费用。大规模部署时,云端算力成本和网络成本需要仔细核算。计算量从车端转移到了云端和网络。复现难度:★★☆☆☆
论文已开源代码,这是巨大优点。但复现涉及真实车辆、多传感器标定、V2X硬件(Y-Box)、云端服务器集群部署等,软硬件门槛很高,个人或普通实验室难以完全复现其真实路测部分。产品化成熟度:★★★☆☆
在限定区域(如智慧园区、港口)或网络覆盖极好的城市路段,作为增强感知能力的增值服务,已具备试点应用潜力。但要作为量产车核心安全感知链的一环,仍需在通信可靠性、安全冗余、成本控制方面经历长期验证。可能的问题:论文整体扎实,但动态优化算法部分可进一步深入,例如考虑预测带宽变化趋势,或与车辆决策层联动,在确保安全的前提下动态调整latmax约束,可能获得更优的整体系统性能。[1] 论文原文:Bandwidth-adaptive Cloud-Assisted 360-Degree 3D Perception for Autonomous Vehicles[11] BEVFormer: Learning Bird‘s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers[23] ETSI EN 302 637-2 V1.4.1: Intelligent Transport Systems (ITS); Vehicular Communications; Basic Set of Applications; Part 2: Specification of Cooperative Awareness Basic Service[52] nuScenes: A multimodal dataset for autonomous driving*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🚗 自动驾驶的算力焦虑,就像开车时手机电量告急!想和行业大咖、技术同好一起探讨如何“边开车边充电”的混合计算妙招吗?
扫描下方二维码或添加龙哥助手微信(kangjinlonghelper),备注
“自动驾驶+地点+公司/学校+昵称”,加入「龙哥读论文」自动驾驶技术群,一起驶向未来!



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
