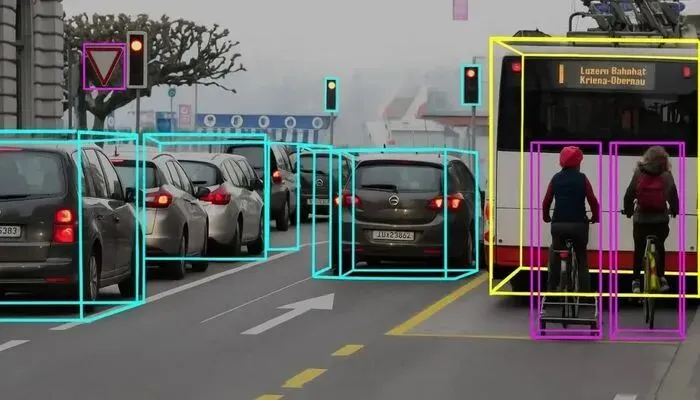
一、时空维度升级:从二维像素到四维时空的深度重建
大模型时代的自动驾驶,已彻底摆脱对单一二维图像的依赖,转向对物理世界的立体化、时序化理解,标注工作也从“平面画框”跨越到“四维时空重建”,这是其最核心的特殊要求。
1. 空间立体化:毫米级多传感器对齐的精准诉求
与早期仅识别图像像素的标注模式不同,当前大模型需在统一俯视图下,精准理解物体在三维物理空间中的坐标、尺寸、朝向等核心参数,实现向量空间的精准感知。这就要求标注工具必须将车身周围多摄像头画面、激光雷达点云,在同一三维坐标系中完成毫米级对齐——哪怕传感器标定参数存在微小误差,映射到三维空间后,也会出现物体重影、位置偏移等问题,直接影响模型感知精度。
2. 时间连贯性:动态物体的时序追踪与行为预判
三维空间标注的需求进一步延伸至时间维度,形成四维时空标注。大模型需理解物体随时间的运动变化,因此标注系统必须确保同一动态物体在数百帧连续画面中拥有唯一身份标识,实现时序连贯性标注——这是模型预判其他交通参与者行为的关键。例如,系统需通过行人过去几秒的运动轨迹,判断其是准备横穿马路还是仅在路边停留,这就要求标注流程处理的不再是孤立单帧图像,而是长达数十秒甚至数分钟的连续数据剪辑。
3. 回溯标注:破解遮挡难题的工程实践
为实现高维度时空重建,行业普遍采用“回溯标注”方法:在行驶片段中,若单帧画面因遮挡、距离过远无法获取物体完整信息,可利用车辆驶近后、遮挡物移开后的画面,反向标注历史帧的物体属性。自动化标注系统借助离线大模型的算力优势,对历史轨迹进行平滑修正,生成高精度真值数据。但在实际工程中,如何处理多相机曝光差异、快门延迟及高速运动导致的图像模糊,仍是亟待突破的技术难点。
4. 标注量与精度的双重升级
从“看照片”到“理解世界”的转变,直接引发标注量的爆炸式增长:过去标注一千张二维照片仅需数天,而大模型时代标注一个复杂城市路口的三维场景,需数小时算力支持与专业人工复核。同时,大模型对数据多样性、准确性的要求极高,任何细微的标注噪声都可能在训练中被放大,导致车辆在特定场景下出现误刹车、误转向等安全隐患,因此标注精度的管控成为核心重点。
二、工程体系重构:自动化标注流水线的搭建与突破
面对海量路测数据,纯人工标注已无现实可行性,自动化标注流水线成为大模型时代自动驾驶标注的标准配置,但其搭建与优化面临多重工程难题,也对标注体系提出了全新要求。
1. “影子舰队”模式:大模型驱动的自动标注逻辑
以特斯拉为代表的行业龙头推行的“影子舰队”模式,核心是利用云端超大参数量模型,标注车端采集的原始数据。这种“大带小”的教学逻辑,依托云端模型无需考虑实时性的优势,可反复处理同一数据片段,甚至调取路段历史车辆数据联合优化,让车载模型学习到人类标注员肉眼难以辨认的细节,大幅提升标注效率与精度。
2. 核心工程难点:动静分离与异形障碍物处理
自动化流水线的核心挑战的是静态背景重建与动态因素分离:为生成精准路面真值,系统需通过神经辐射场等技术合成路面,但真实道路环境瞬息万变,路边摇晃的树木、穿梭的车辆等动态因素,若无法完美从背景中剔除,会导致路面模型充满噪点。这就要求标注算法精准理解物理世界结构,区分永久设施(马路边沿)与临时物体(临时停放的垃圾桶)。
另一大难点是异形障碍物标注。传统标注主要针对车辆、行人等固定形状物体,而大模型时代需感知所有占据空间的物体(如路面掉落的木箱、倾斜的电线杆、异形工程车等)。行业通过“占用网络”技术,将空间划分为无数微小体素,标注每个体素的占用状态,但这种方式对存储、计算的要求呈几何倍数增长。尽管可通过符号距离场等数学技巧降低复杂度,但标注精度与计算效率的平衡仍是工程实践的重点。
3. 人的角色转型:从“画框者”到“规则制定者与审核员”
自动化标注体系中,人类的角色发生根本性转变:不再是直接的标注执行者,而是规则制定者与异常审核员。当模型生成错误标签时,标注员需精准分析原因(光线过暗、雨水遮挡、传感器标定失效等),这要求标注员具备极高的技术素养。同时,为实现流水线自我进化,需构建闭环反馈机制——人工修正的高精度数据将重新输入自动化模型,持续提升其标注准确度,这也是自动驾驶系统不断突破性能上限的关键。
三、场景适配升级:破解遮挡、极端环境与长尾场景的标注瓶颈
大模型时代的自动驾驶,需适配真实道路的复杂环境,因此标注工作必须突破遮挡、极端天气、长尾场景等传统难点,满足“全场景感知”的特殊要求。
1. 遮挡场景:对“不可见”区域的概率标注与推理
遮挡是自动驾驶感知的“致命痛点”(如货车遮挡前方行人),大模型需不仅能识别可见物体,还能预判遮挡区域的潜在风险。这就要求标注工作引入空间概率概念,明确标注视线盲区及盲区内可能存在的风险,通过场景上下文推断遮挡后的潜在状况——这种针对“未知”的标注,对标注系统的逻辑推理能力提出了极高要求。
2. 极端环境:多模态融合的跨模态标注
暴雨、浓雾、强光逆光等极端天气下,视觉传感器画面噪声大、对比度低,传统标注算法完全失效。对此,标注系统必须转向多模态融合路径,将4D毫米波雷达(可穿透浓雾、直接测量距离和速度)的物理测量值,与视觉图像的语义信息深度绑定。其核心难点在于,雷达数据稀疏且存在虚假反射点,标注系统需具备强大的筛选能力,过滤护栏反射等假目标,保留真实风险信号。
3. 长尾场景:高信息密度标注与仿真数据校准
长尾场景(极少发生但后果严重的极端情况,如奇特掉落物、异常交通参与者、复杂施工路段)是标注工作的深水区。由于这类场景在原始数据中出现概率极低,标注系统需具备“异常挖掘”能力——利用大模型扫描海量里程数据,筛选出模型置信度低、车辆接管率异常的片段,进行高难度精细标注,重点追求数据“信息密度”,而非数量。
当现实数据不足时,仿真数据成为补充标注集的重要路径,但难点在于缩小仿真与现实的差异。若仿真标注过于理想化,训练出的模型在真实复杂环境中可能出现幻觉、误判。因此,大模型时代的标注工作,不仅要处理真实图像,还需对仿真数据的真实度进行评估校准,确保虚拟世界学到的经验可完美迁移到真实道路。
四、标注逻辑转型:面向端到端决策的因果与意图标注
随着端到端技术的普及,自动驾驶架构从“感知-决策-执行”分段式,转向“传感器输入→轨迹输出”的集成化,标注逻辑也从“描述世界”升级为“解读驾驶智慧”,这是大模型时代标注最具颠覆性的特殊要求。
1. 行为意图标注:解决驾驶行为的多样性难题
端到端模型需学习人类的驾驶决策逻辑,因此标注不仅要捕捉驾驶员的轨迹、操作,还要标注行为意图及动作优劣——面对同一路口,不同驾驶员的操作可能存在差异(激进或稳重),若简单将所有数据输入模型,可能导致模型学习到矛盾逻辑,引发行为异常。通过添加行为意图标签(如“避让”“变道”“超车”),标注数据从冷冰冰的坐标,转变为充满逻辑的决策序列,助力模型理解驾驶行为的合理性。
2. 跨模态语义标注:融合大语言模型的因果解读
为提升端到端模型的可解释性,行业将大语言模型引入标注流程,将视觉场景转化为自然语言描述(如“左前方车辆刹车灯亮起,右侧有变道空间,驾驶员选择轻微制动并向右偏移”)。这种带语义解释的标注,帮助车载模型理解驾驶行为的因果关系,而非单纯模仿轨迹曲线。其核心难点在于,确保语言描述与物理世界的像素、坐标完全对齐,实现视觉、空间、时间与语言的深度关联。
3. 负样本标注:筑牢安全边界的关键
端到端模型的安全落地,离不开“负样本”标注——绝大多数路测数据仅包含成功驾驶行为,而模型需学会规避错误操作。由于无法在真实道路制造事故,需通过数据增强、生成式AI创造“临界场景”标注(如修改正常轨迹为潜在碰撞轨迹,标注为“不可行区域”)。这种针对安全边界的标注,超越了对现实的描绘,成为端到端自动驾驶上车的安全基石。
最后的话
大模型时代的自动驾驶标注,早已摆脱“廉价劳动力密集型”的传统标签,演变为集成高精地图、三维重建、时空感知、认知推理于一体的尖端技术领域。其特殊要求背后,是自动驾驶向“全场景、高安全、高智能”迈进的必然需求——尽管复杂度提升带来了成本与技术的双重压力,但这种标注体系的重构,正是自动驾驶跨越最后1%长尾挑战、实现规模化落地的核心支撑,也为行业高质量发展奠定了坚实基础。