自动驾驶的“断舍离”:清华团队用“学得更少”破解安全困局
- 2026-03-17 13:23:21
2026年3月14日,一则来自清华大学团队的科研成果,给狂飙突进的自动驾驶行业踩了一脚“理性的刹车”。
封硕副教授与美国密西根大学团队在 《自然·通讯》 上发表论文,提出了一种名为“密集学习” 的方法。这个方法的核心思想听起来有些“反直觉”:想要让自动驾驶更安全,不是让它学得更多,而是主动“学得更少”。
这则新闻之所以引人注目,是因为它直击了当前自动驾驶商业化进程中最大的“心病”——安全。
当各家车企还在比拼谁的测试里程更长、谁采集的数据更多时,清华团队却告诉我们:“题海战术”可能是条死胡同,学会“断舍离”,才能找到真正的出路。
(参考阅读请点击:
《滴滴自动驾驶牵手清华大学:成立深穹远航实验室,“产学研CP”能擦出啥火花?》)

清华大学封硕副教授
破解“跷跷板效应”:当AI“越吃越笨”
报道中提到了一个非常形象的困境——“跷跷板效应”。
这就像马斯克也曾头疼过的问题:你拼命给AI投喂事故数据,教会它避开A场景的危险,结果它开上B路段时,反而变得手足无措,冒出一堆新问题。
“按下葫芦浮起瓢”,事故并没有真正减少,只是换了个地方发生。
为什么会这样?
团队在研究中揭示了背后的科学本质——“稀疏度灾难”。
在真实世界中,真正导致事故的高价值数据,就像大海里的针,极其罕见。
传统深度学习的逻辑是把海量数据一股脑儿全吞下去,结果99.9%都是平平无奇的“正常驾驶”,那根“针”早就淹没在信息的海洋里,AI被喂得“虚胖”,却根本没学到点子上。
这就像一个人为了准备考试,把图书馆里所有的书都背了一遍,看似勤奋,实则效率极低,该错的题还是错。
密集学习的智慧:寻找那些“差点就对了”的瞬间
那么,清华团队给出的解药是什么?不是继续加大“投喂量”,而是给AI配了一个 “智能刷题教练”。
这套“密集学习”方法的精髓,在于重新定义了什么是 “高价值数据” 。
它告诉我们一个反常识的真相:最有价值的学习材料,既不是那些AI完全搞不定的“超高难度题”,也不是那些闭着眼都能开对的“送分题”,而是那些“差点就对了”的边缘场景——也就是报道中提到的“可避免的事故”或“险些发生的事故”。
这就像学生时代刷题,真正让你提分的,往往是那些你“差点做对”的错题。
做对了,你总结成功经验;
做错了,你吸取失败教训。
 来源:Nature Communications
来源:Nature Communications
而对于那些难度远超你当前水平的题目,反复练习只会浪费时间,甚至让你怀疑人生。
这套方法通过算法,从海量数据中精准筛选出这些“信息密集型样本”,然后针对性地进行“密集学习”。
它给自动驾驶模型配备了一个名为SafeDriver 的“AI安全教练”。
这个教练平时“沉默寡言”,只在模型即将犯错、面临风险的时刻,才会出手“接管”或“干预”。
它不是靠死板的规则,而是基于高价值数据训练出的直觉,在关键时刻拉AI一把。
从“题海战术”到“精准滴灌”:为AI进化开新药方
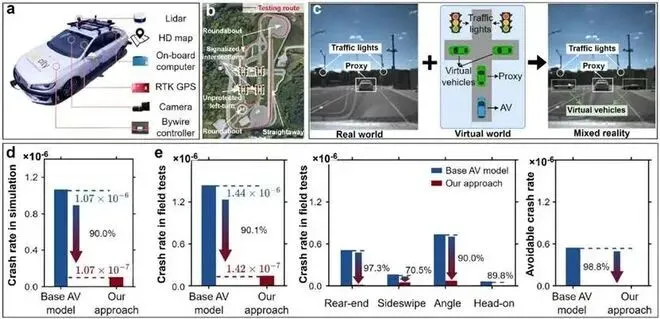
这套“减法”的疗效,在实验中得到了惊人的验证。
报道中的数据显示,应用“密集学习”后,自动驾驶的安全性提升了1到2个数量级。
在仿真测试中,高速场景碰撞率降低86.3%,城市场景更是降低了98.0%。
在密西根大学的实车测试中,实体车辆的碰撞率降幅也高达90.1%。这意味着,原本可能发生的事故,十起里能避免九起。
这项研究的颠覆性在于,它跳出了业界长期以来依赖的两种传统路径:
一种是疯狂采集和堆砌事故数据(往往治标不治本),另一种是试图用穷举的规则去约束系统(在复杂现实面前显得力不从心)。
清华团队用一套漂亮的理论推导和实验验证,证明了“精准”远比“海量”重要,“质量”远比“数量”关键。
这不仅是自动驾驶的福音。
正如封硕副教授所言,这项技术未来有望拓展至医疗机器人、航空航天等其他“安全关键系统”。
在任何一个不允许失败的领域,这种“断舍离”的智慧,都可能成为AI从“能用”走向“可信赖”的关键一跃。
当整个行业都在为Scaling Law(规模法则)狂热时,清华团队的这项研究提醒我们:
AI的进化,除了“大力出奇迹”,还有“四两拨千斤”。
学会在信息的汪洋中辨别真金,学会在关键时刻做减法,或许才是通往真正智能的必经之路。
参考文献: DeepTech深科技 报道《自动驾驶安全难题,被清华团队用一套“减法”破解了》
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- SUV极氪8X预售开始了,43万起,不是吹牛,是真把三电机、空气悬架、激光雷达全塞进一台家用里了.
- 宝马暂时放弃L3级自动驾驶?为什么?
- 方盒子SUV扎堆上市,奇瑞V27却悄悄改了玩法,它想让硬派车也能接上家用电
- 自动驾驶已能让飞机自己飞,为啥驾驶舱还得坐2名飞行员?| 招飞老师科普
- 2025 自动驾驶战略与政策指南:完整版解读,抢占科技制高点可落地路径(附下载方式)
- 十五五规划纲要全文发布,3次提及自动驾驶,未来5年,或定终局.
- 便宜的三厢轿车!
- 太难了!又一车企暂时放弃L3自动驾驶
- 标配半固态电池?名爵全新纯电SUV发布,续航至少500km以上
- 【Nature】自动驾驶的“眼睛”升级了:0.06°角分辨率+65米探测距离,4D成像时代来了
