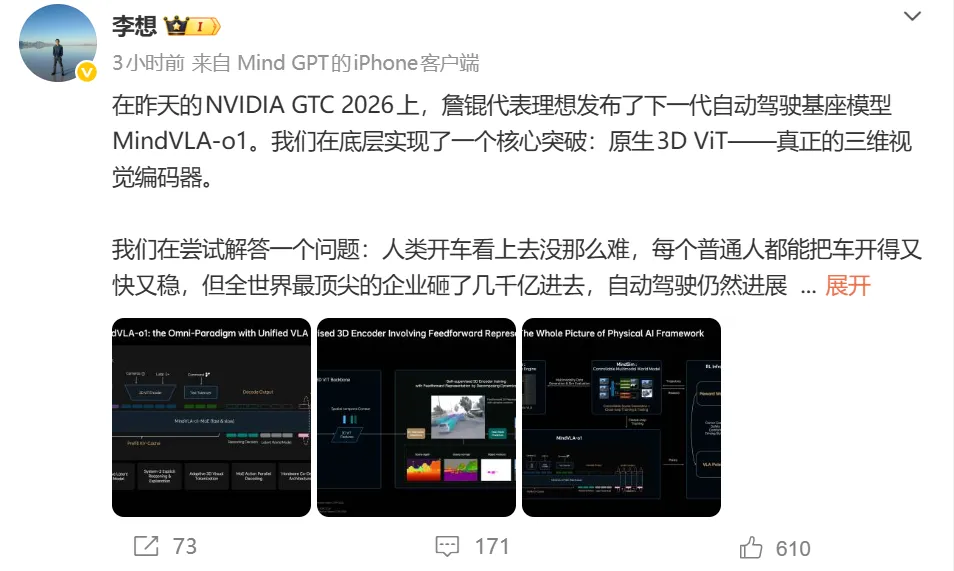
3月18日,李想在其个人社交媒体发了一篇长文,来阐述刚刚发布的理想汽车自动驾驶模型MINDVLA,表述理想对自动驾驶模型的突破和理解。和特斯拉的模型一样,理想自动驾驶的模型不再仅仅是一个自动驾驶模型,而是一个通用到各个物理世界的智能体模。
理想汽车在自动驾驶领域的核心突破就是真正的三维视觉编码器,原生3D VIT。李想解释了原来端到端模型之所以不是3D的,而是2D的,是因为它没有经历3D预训练,全都是搞的一些2D预训练。
但理想的3D VIT解决了这个问题,不再是用2D还原3D,而是一开始就在3D当中工作。
所以,有了3D VIT,MindVLA-o1把空间理解、思考推理、驾驶行为统一在一个模型里。MindVLA-o1把空间理解、思考推理、驾驶行为统一在一个模型里。不光看见世界,还能在隐空间里模拟未来几秒的场景变化,想清楚再开。我们把这种能力称之为多模态思考。理想也已经进行了验证,这套基座模型不只是为自动驾驶设计的。同一套VLA基座模型,能开车,也能控制机器人,它正在逐渐演化成一个通用的物理世界智能体。理想的自动驾驶模型,不再局限于汽车,而是在物理世界里能够通用,将是一个彻头彻尾的智能体。马斯克曾经说特斯拉的ADS就是这样一个在汽车里能用,在其他地方也能用通用模型。在新能源汽车智驾大放异彩的时期,希望国内品牌都能有自研能力,有自己的智驾路线,为消费者提供丰富的产品体验。
感谢您的耐心阅读!若喜欢请在文章页底右下角点赞和在看,或“分享”转发,让更多人感到您的态度;感谢您的喜欢,请点击文章左上角蓝色字体“季风汽后”,再“关注公众号”,便于收到更新。谢谢!