芝能科技出品
在过去几年,自动驾驶行业有一个几乎没人质疑的前提:只要数据足够多、工程能力足够强,这个系统就会不断变好。
从感知到规划,从规则到端到端,整个行业都在围绕一个方向持续加码,更多传感器、更大算力、更复杂的软件栈。大家默认,这是一场“工程问题”,只要投入足够,结果只是时间问题。
但在GTC 2026,元戎启行CTO 曹通易 的分享,给了一个新的思考。数据在爆炸,车队规模在扩大,但系统的进步速度却在放缓。很多公司已经进入一种“看起来在进步,但用户体验没有质变”的阶段。
问题不在工程,而在“认知”。自动驾驶,正在从一个系统工程问题,转变为一个模型问题。
过去两年,端到端几乎成为行业共识。大家逐渐放弃模块化拼接的路径,把感知、预测、规划尽可能收敛进一个统一模型中,希望通过数据驱动来逼近人类驾驶能力。但现实是,端到端并没有带来想象中的跃迁。
模型在进步,但进步的斜率在变缓;数据在增加,但长尾问题依然顽固存在。
很多企业的真实状态是:系统越来越复杂,但对极端场景的处理能力,并没有同步提升。这背后是一个典型的Scaling Problem。
● 首先是模型容量的瓶颈。自动驾驶面对的不是标准化环境,而是高度开放的真实世界。鬼探头、异常行为、非结构化参与者,这些长尾场景本质上要求模型具备极强的泛化能力。而现有模型更多是在“记忆分布”,而不是“理解世界”,当遇到分布外数据时,很容易失效。
● 其次是数据效率问题。车端每天产生海量视频,但真正对训练有价值的片段极少,大量“正常驾驶数据”反而在稀释模型的学习能力。传统的数据筛选方法依赖规则和人工,本质上是一次性处理,很难形成持续积累。
● 更关键的是迭代速度。数据闭环链路过长,从采集到部署往往需要数天甚至更久。当车队规模扩大后,这种延迟会被进一步放大,最终形成“数据很多,但认知更新很慢”的结构性矛盾。
这些问题叠加在一起,构成了一道真正的墙——不是算力墙,而是“认知墙”。自动驾驶第一次遇到一个类似大模型领域的问题:不是你没有数据,而是你没有能力把数据转化为有效认知。
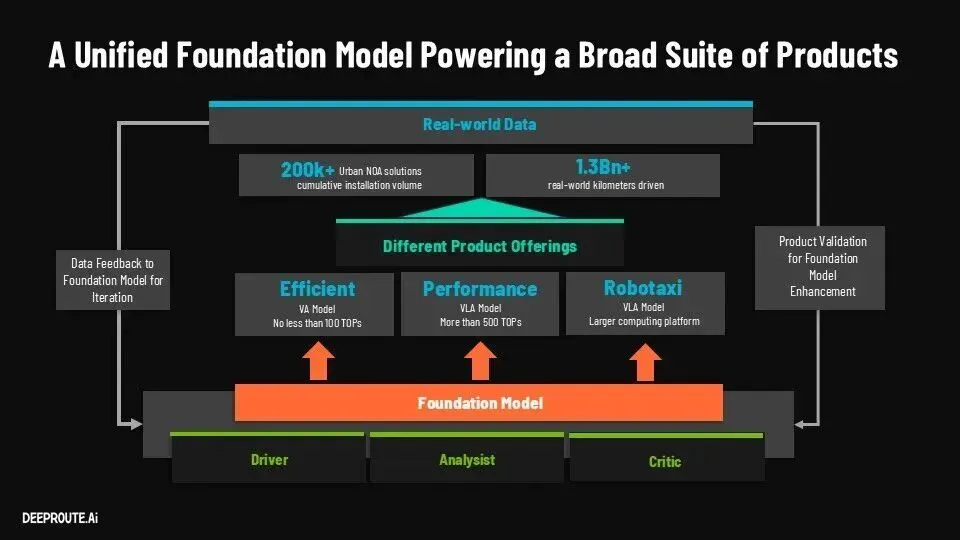
在这样的背景下,元戎启行提出的40B参数VLA模型是“更大的模型”,也是一种新的变化。
传统自动驾驶模型是一个执行系统——输入环境,输出动作。而VLA模型的设计,则试图让模型同时承担三种角色:驾驶员、分析师和评估者。模型不再只是“做决策”,而是开始“理解决策”。
在预训练阶段,元戎没有沿用轨迹监督的思路,而是转向视频预测。这一步看似简单,实则把训练目标从“模仿行为”转向“建模世界”。
当模型被要求预测未来帧时,它必须学习物体运动、空间关系和因果逻辑,这些能力构成了自动驾驶真正需要的基础认知。
进入Midtrain阶段,Driver、Analyst、Critic三个角色被同时训练。模型不仅要输出驾驶行为,还要解释当前场景、评估行为优劣。这种设计本质上是在构建一个“自洽系统”:它既是执行者,也是裁判。
语言的引入进一步强化了这一点。通过“Learning to Explain”任务,模型需要用自然语言描述场景和决策依据。
这并不是为了可解释性本身,而是借助语言这个载体,强制模型建立因果推理能力。某种程度上,这和大模型中的Chain-of-Thought是同一类问题——能说清楚,才意味着真的理解。
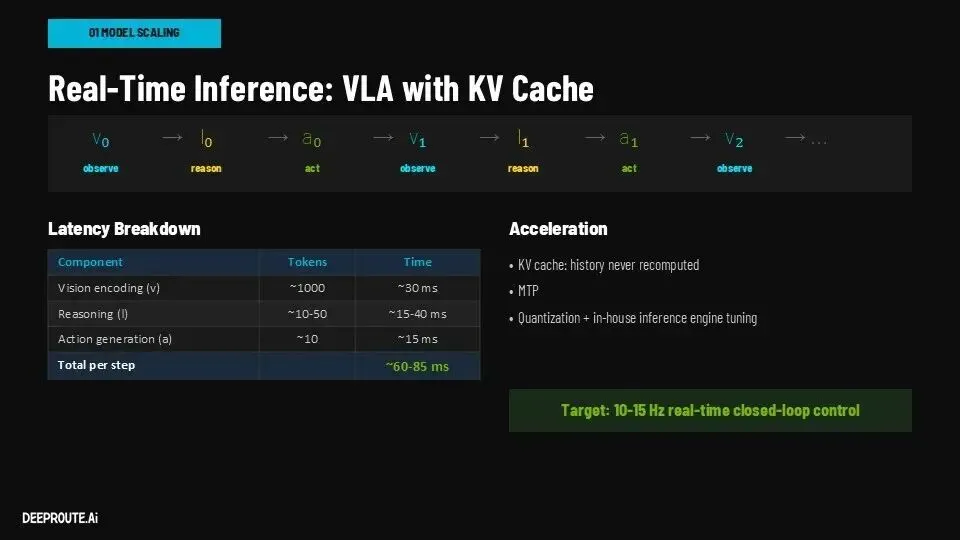
最终,在推理阶段,这套系统被抽象为Observe-Reason-Act三个连续步骤。
视觉输入被编码为Token,经过推理生成决策逻辑,再转化为控制指令。这种结构让自动驾驶第一次具备了类似“思考过程”的中间层,而不是直接从输入跳到输出。
如果从更高一层来看,这套VLA模型能不能从“反应系统”,进化为“认知系统”?
数据闭环被重写,
自动驾驶开始具备“自我进化”的能力
模型的变化,最终会体现在数据闭环上。在传统体系中,数据闭环是强人工驱动的:人去找问题、标注数据、定义规则,再反向优化模型。这种方式在早期有效,但随着规模扩大,会迅速遇到瓶颈。
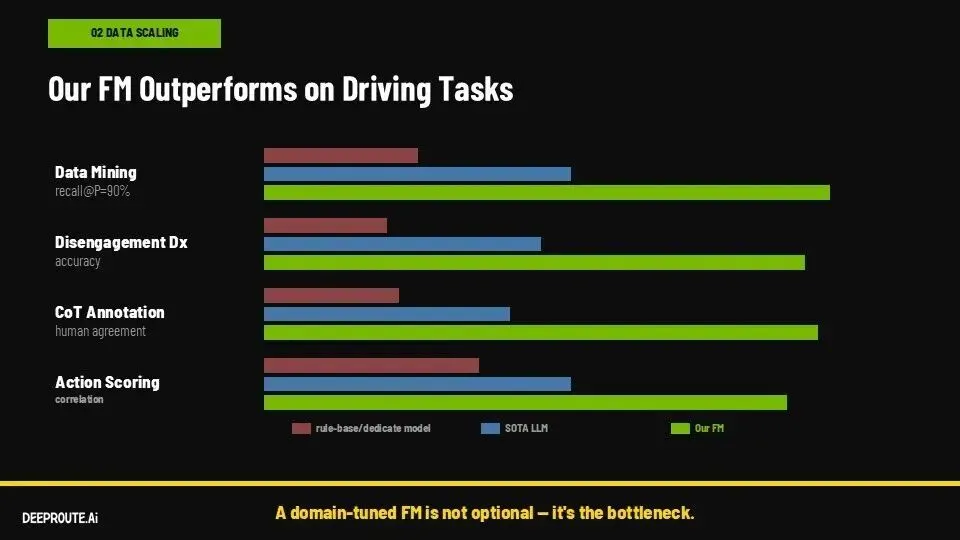
元戎的路径,是用Foundation Model重构整个闭环,让数据处理本身也成为模型能力的一部分。
在这个体系里,数据挖掘不再依赖规则,而是由模型自动识别高价值片段;接管分析不再是人工归因,而是模型对问题进行分类和诊断;标注过程从“标答案”变成“生成推理过程”;驾驶质量评估也由模型统一完成。
这些能力共享同一个模型基础,从而形成真正的飞轮:模型越强,数据处理能力越强;数据越多,模型又进一步提升。
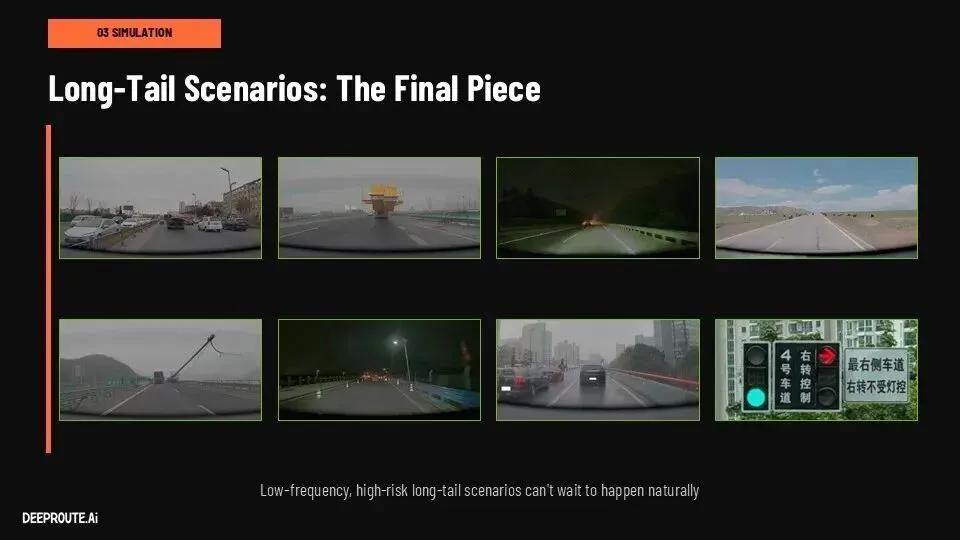
长尾问题的处理方式也发生了变化。过去需要人为定义“正确答案”的corner case,现在可以通过仿真和强化学习来解决。
模型在高保真环境中生成多种决策路径,通过自我评估不断优化策略分布。这意味着系统开始具备一种新的能力——不是被动学习,而是主动探索。自动驾驶第一次接近一种“自我进化系统”。
当然,工程问题依然存在。40B模型如何部署、如何控制成本、如何适配不同算力平台,这些都需要通过蒸馏等手段来解决。但这些问题的性质已经发生变化——它们不再决定上限,而更多是在约束落地节奏。
过去十年,这个行业比的是工程能力:谁的传感器更强,谁的系统更稳定,谁能把复杂度控制在可交付范围内。但在GTC 2026之后,大家考虑的是谁能构建一个可持续进化的“AI大脑”,行业的分层将被重新定义。
一部分公司,会继续沿着工程优化的路径前进,把系统做得更稳、更可控,但能力提升趋于线性;另一部分公司,则会押注模型驱动,承担更高的前期成本,但一旦跨过临界点,能力可能呈指数级提升。
自动驾驶,从来不是一个均匀演进的行业,更接近AI本身——要么长期停留在阈值之下,要么一旦跨过那条线,就迅速拉开差距,重写规则。