元戎启行的 40B VLA 自动驾驶基座模型和方法论
- 2026-03-23 13:01:30
元戎启行的 40B VLA 自动驾驶基座模型和方法论
元戎作为中国辅助驾驶/自动驾驶算法供应商的后起之秀,在这两年来量产车辆大幅度上升,拥有长城、吉利、甚至传言拿下了新势力零跑的业务。而且元戎也是比较早喊“VLA”甚至量产"VLA"的供应商。 所以,算是有量产也有前瞻的自动驾驶解决方案提供商,本次GTC 2026 元戎的CTO 曹通易做了名为《Redefining the Boundaries of Autonomous Driving with Foundation Model》的演讲,分享了其基于Foundation model基模的VLA方法和理论。 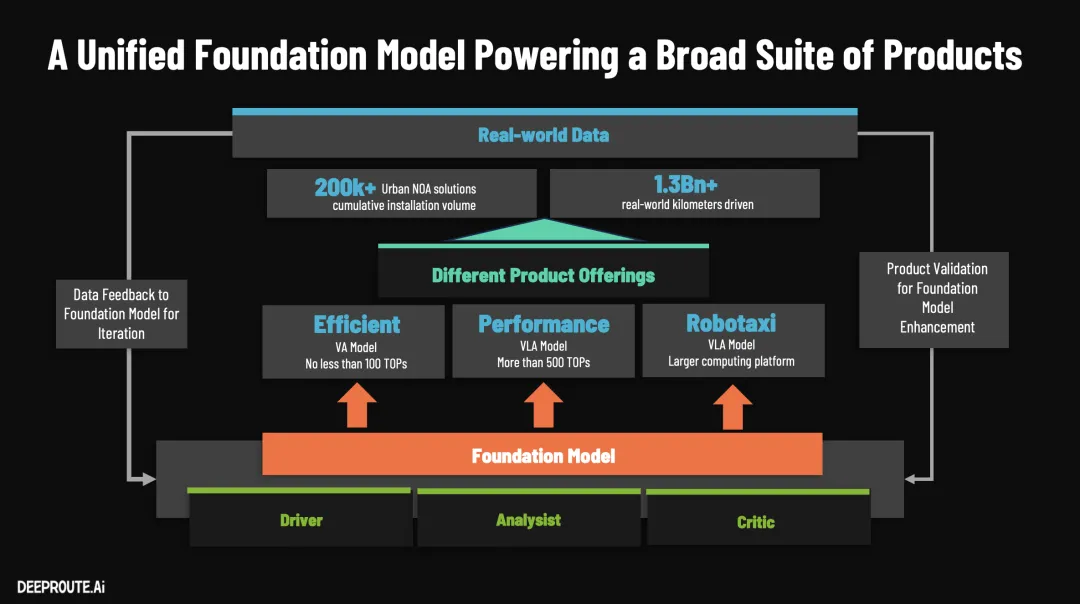
本文通过演讲和行业知识分享下此次演讲的核心内容和亮点。 元戎启行(DeepRoute.ai)解决自动驾驶,甚至走向 L5 级别的核心思路,是坚信“Scaling Law(扩展定律)”,通过构建统一的基座大模型来驱动模型尺寸和数据规模的同步爆发。 这里也看出目前行业内对当前端到端发展起来的各种技术比较自信,看到了自动驾驶的曙光,目前行业的核心重点是,优化算法也加大模型参数、推动算力芯片上升、优化工程落地。 以下是元戎其基座大模型架构与自动驾驶软件方法的硬核技术亮点: 元戎基于1亿Gb的视频构建了一个参数量为 40B 的原生 VLA(视觉-语言-动作)大模型, 小鹏也在去年年底表示其研发了基于2亿Clips(推断 大约10亿Gb数据)训练的72B(720亿)参数超大规模模型。 元戎表示其训练机制和端侧部署上进行了以下底层创新: 1. 架构创新:“三位一体”的模型角色这个大模型打破了仅作为“驾驶员”的单一设定。它在同一个模型中集成了三种能力:驾驶员、分析师以及评论员/裁判。这种能力复用不仅让认知和场景理解得以共享,还能有效提升驾驶任务本身的性能。 解读就是这个模型能看懂视频等传感器输入数据流,推理和分析,最终给出结论好坏。 2. 预训练(Pre-train)原理突破:从“轨迹监督”转向“视频预测”传统的端到端模型通常依赖驾驶轨迹进行监督训练,但这存在极大的数据浪费——1 PB 的驾驶视频中,轨迹数据仅占约 10 GB,数据利用率仅为 0.001%。元戎在预训练阶段创新性地采用了视频预测任务来让模型理解世界,这意味着视频的每一个像素都能作为监督信号,数据利用率达到 100%,从而为超大参数模型提供了极高质量的物理世界表征。 3. 中端训练(Mid-train)的跨模态推理融合在掌握了对世界的理解后,模型会进行三种核心任务的联合训练: V+A(视觉+动作):学习常规的端到端驾驶,典型的端到端架构。 V+A -> L(行动后解释):激活分析师和裁判角色,输入视觉和动作序列,输出对关键事件的抽象描述、行为因果解释以及好坏评判。 V -> L+A(多模态逻辑推理):训练带推理能力的司机。给定视觉输入,利用思维链(CoT)让模型先输出关键事件的语言描述和决策逻辑,再输出具体的驾驶轨迹。 
4. 极致的车端部署优化与量产蒸馏,根据GTC上曹通易的表述,目前元戎的VLA在车端可能实现了 10-15 Hz 的实时闭环控制(为什么实时闭环控制重要可以点击我们之前文章《揭秘特斯拉 FSD 核心:端到端算法的“三大难点”与“独门解法”以及对语音控车的想法》了解)。 
元戎表示其引入了 KV Cache(历史特征免重复计算,这个理想在本次GTC也表示采用了,具体可以看我们理想GTC 2026文章)、多 Token 预测(MTP)、量化技术以及定制化的推理引擎,将包含 1000 个视觉 Token 和数十个推理 Token 的单步处理延迟严控在 60-85 毫秒以内。 此外,基座大模型可以根据车端芯片算力进行灵活“蒸馏”:在 100 TOPS 平台上部署纯驾驶的 VA 模型,在 500 TOPS 平台上即可部署带有逻辑推理能力的 VLA 模型。 在软件和数据工程层面,元戎彻底重构了数据闭环和仿真系统,解决了“无聊数据损害模型”和人工介入效率低下的行业痛点: 1. 大模型全面接管的极速数据闭环传统的数据闭环(发现问题、诊断、挖掘、标注、训练)严重依赖人工或小型规则模型,一个循环往往耗时 5 天(100 小时以上)且能力无法沉淀。元戎直接利用前文提到的基座大模型(其分析师和裁判能力)接管了数据挖掘、自动诊断、思维链(CoT)标注以及动作评分等全流程。这不仅将闭环周期从 5 天极速缩短至 12 小时,更重要的是,闭环过程中产生的所有人工 Review 和机器标注结果,都会沉淀为大模型中端训练的新养料,实现 AI 能力的飞轮递增。 
2. 突破长尾场景的数据合成技术面对现实中难以收集的罕见高危场景(Long-Tail Scenarios),元戎采用了先进的生成式与合成技术: 3D 重建与风格迁移:利用 Nvidia 的 3D GUT 进行高保真重建,并用 Cosmos 模型实现天气和光照的风格迁移,将一个白天的素材转化为雨天或夜间的变体。 DiPIR 插入式编辑:这是元戎自研的技术,能够将生成的 3D 行人、骑行者或动物(如公路上突然窜出的羊)无缝插入到真实的道路视频中,并自动匹配光照和阴影,系统性地批量生成“极其危险且难以捕捉”的训练数据。 3. 仿真环境下的强化学习(RL)自我进化在仿真回测中,元戎的模型不再单纯依赖人工标准答案(在极端场景下人类也很难标注出完美轨迹)。基座大模型可以在重建的仿真场景中自己“采样(Rollout)”出多条不同的驾驶解决方案(比如遇到违规加塞时,是选择体感不佳的急刹,还是选择横向避让)。随后,模型内部的“评论员(Critic)”会结合预设的安全和舒适度规则,对这些轨迹进行行为分析和评分。通过这种闭环强化学习(RL Policy Optimization)的持续迭代,模型能够在极其复杂的边缘场景中输出更安全、更精准的决策。 以上就是元戎启行在本次GTC 2026分享的核心内容,欢迎留言交流更多核心背后的算法信息。 

01
基座大模型(40B VLA)
的原理与架构技术亮点
02
自动驾驶软件与数据方法亮点
参考资料以及图片
1. Redefining the Boundaries of Autonomous Driving with Foundation Model -元戎启行 曹通易
*未经准许严禁转载和摘录
END
✦
✦
大会推荐
✦
4月21-22日,智猩猩主办的2026中国生成式AI大会将举行,设有开幕式,AI算力基础设施、大模型、AI智能体3大专题论坛,以及OpenClaw、LLM强化学习、大模型记忆等6场技术研讨会。其中,OpenClaw最强轻量平替nanobot团队负责人黄超、Claw-R1项目负责人程明月等学者专家将带来报告分享。
✦
✦
入群申请
✦
智猩猩矩阵号各有所长
点击名片即可关注
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 智享升级,焕新体验 | 奔驰GLE SUV实力加码 重装上阵
- 广东百度无人驾驶基地参访纪实:沉浸式体验自动驾驶技术,试乘无人车, 聆听专家分享
- 10万级家用SUV怎么选?这两款1.5T爆188马力,空间大又靠谱
- 智驾定型之战:一文看透自动驾驶“端到端”的底层逻辑与架构演进
- 【高端就业:自动驾驶安全员】上五休二,可线上面试!购买社保五险一金!月薪7000元~9800元/月!广州深圳多地可选!
- 美媒:自动驾驶卡车每年可节省 90 亿美元,重塑货运行业未来
- 拒绝新能源溢价!10万级这三款燃油中型SUV,空间大到能躺平
- 【株洲日丰】第四代博越L卷王SUV现金优惠直降10000+
- 国产又一大 6 座 SUV,小鹏 GX 官图发布,外观不输路虎揽胜,年内上市
- 补胎 换轮胎 高价回收车 激活电瓶 轿车搭电
