5个数据集SOTA!ViGT:用于自动驾驶的视觉隐式几何Transformer
- 2026-04-02 11:20:08
点击下方卡片,关注「3DCV」公众号选择星标,干货第一时间送达
来源:3DCV
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内有20多门3D视觉系统课程、300+场顶会讲解、顶会论文最新解读、海量3D视觉行业源码、项目承接、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎加入!
论文信息
标题:Visual Implicit Geometry Transformer for Autonomous Driving
作者:Arsenii Shirokov, Mikhail Kuznetsov, Danila Stepochkin, Egor Evdokimov, Daniil Glazkov, Nikolay Patakin, Anton Konushin, Dmitry Senushkin
机构:Lomonosov Moscow State University
原文链接:https://arxiv.org/abs/2602.05573
代码链接:https://github.com/whesense/ViGT
导读
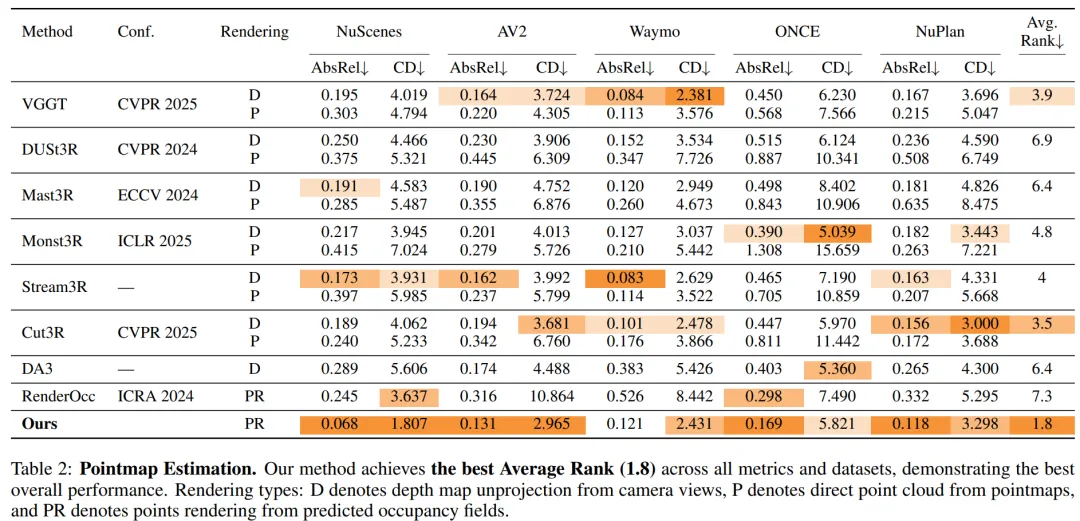
我们提出了视觉隐式几何变换器(ViGT),这是一种用于自动驾驶的几何模型,能够从环绕视图摄像头数据中估算出连续的3D空间占用场。ViGT代表了自动驾驶领域基础几何模型的重要进展,它注重模型的可扩展性、架构简洁性以及在不同传感器配置下的泛化能力。我们通过无标定架构实现了这一目标,使得单个模型能够适应不同的传感器设置。与那些注重像素对齐预测的通用几何基础模型不同,ViGT采用鸟瞰图视角来估算连续的3D空间占用场,从而满足特定领域的需求。ViGT能够自然地将多个摄像头的观测信息统一到单一的度量坐标框架中,为各种几何任务提供统一的表示方式。与大多数现有的空间占用模型不同,我们采用了自监督训练方法,该方法利用同步的图像与激光雷达数据对,从而无需进行昂贵的手动标注。我们通过在五个大规模自动驾驶数据集(NuScenes、Waymo、NuPlan、ONCE和Argoverse)上训练模型,验证了该方法的可扩展性和泛化能力。在点云估算任务上,我们的模型取得了最先进的性能,其平均排名在所有评估基准中最高。此外,我们在Occ3D-nuScenes基准测试中评估了ViGT的性能,结果发现ViGT的表现与监督学习方法相当。源代码已公开发布,
效果展示
GT与按平均排名排列的前3种方法预测点云的视觉对比。我们的方法生成的点云在几何精度上更为准确。我们还展示了预测占位情况的渲染效果,以此展示对连续几何结构的准确捕捉。颜色沿z轴表示高度。
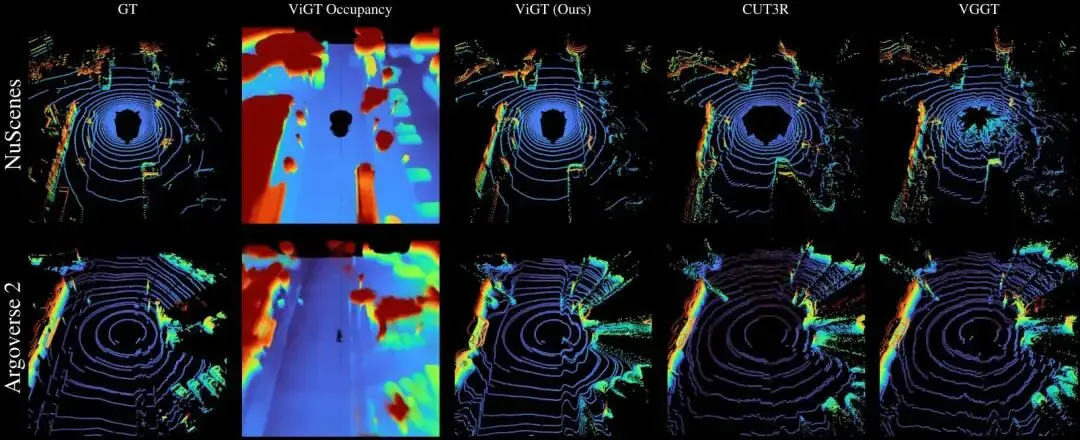
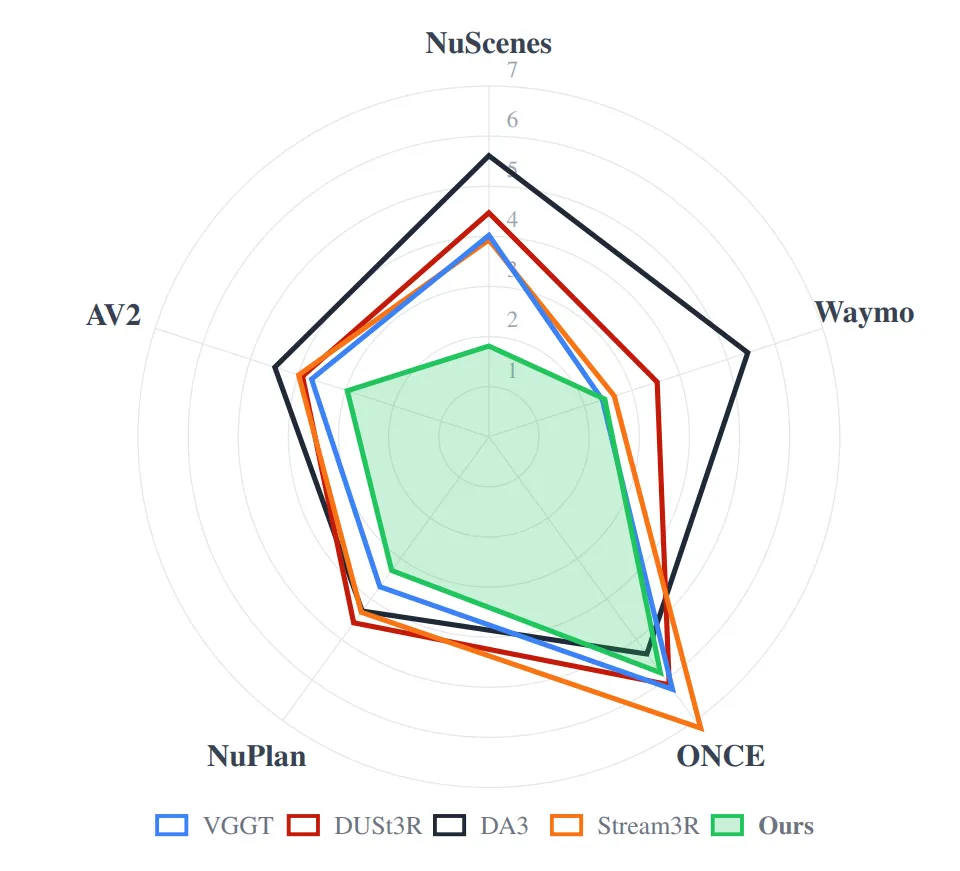
我们的可视化隐式几何变换器(VisuallmplicitGeometry Transformer)优于公开的自动驾驶数据集上最新的基本几何模型。离中心位置越近,表现越好。
引言
准确、具备度量意义的几何感知模型是实现可靠安全自动驾驶的关键。从图像及其他传感器模态中学习三维感知的几何表示,已成为自动驾驶和通用场景理解领域发展的核心。多视图重建领域的最新进展催生了一类新型端到端几何模型,它们能够直接从无标定的图像集合中估计稠密的三维点云图,并隐式恢复相机参数。尽管这些方法在通用领域的单目及多视图重建任务上表现出色,但其在自动驾驶场景中的应用仍面临挑战。首先,自动驾驶车辆常用的环视相机系统通常优先保证360度全覆盖而冗余有限,导致相机视图间重叠区域减少,从而削弱了这些方法所依赖的多视图几何假设。其次,许多近期出现的多视图重建模型未明确强制准确的度量尺度,而这对于自动驾驶应用至关重要。再者,逐像素的深度和点云预测通常与单张图像对齐而非全局场景对齐,导致难以协调多视角间的不一致性。相比之下,离散化的三维体素表示因能明确编码占据空间与自由空间,且与碰撞检测、运动规划等下游任务直接兼容,已在现代自动驾驶系统中被广泛采用。然而,基于体素的方法常面临可扩展性挑战,因其训练通常需要稠密且成本高昂的真值标注。
占据场提供了一种颇具吸引力的替代方案:它将三维场景建模为空间上的连续函数,而非依赖显式的体素网格或逐视图深度图。此类表示具有紧凑性、可微性、分辨率及传感器无关性,并能自然地将多视角几何统一到以场景为中心的坐标系中,因此非常适合自动驾驶应用。
主要贡献
本研究提出了视觉隐式几何变换器,它能直接从环视相机图像中估计连续的三维占据场。我们的模型学习一个紧凑的连续鸟瞰图场,可通过逐点解码器解码为二进制占据信息。该场提供了场景的灵活几何表示,并能通过查询逐点占据概率并进行渲染累积,进一步转化为下游所需的表示形式。与此前方法不同,我们通过设计无需标定、完全由数据驱动的图像到鸟瞰图的转换,简化了这一过程。该设计减少了归纳偏置,提升了模型的泛化能力和可扩展性。最后,我们采用了一种可扩展、传感器无关的自监督训练流程,利用同步但未标定的多视图图像和激光雷达数据,无需额外标注。
方法
我们通过设计模型架构,优先考虑可扩展性、简洁性及对不同传感器配置的泛化能力,朝着构建通用的自动驾驶基础几何模型迈进。我们的架构包含三个主要组件(图2):独立处理每张图像的编码器;无需标定的隐式相机到鸟瞰图投影模块,其将独立的图像特征统一到以场景为中心的鸟瞰图表示中;以及基于查询的隐式解码器,用于预测三维点的占据值。
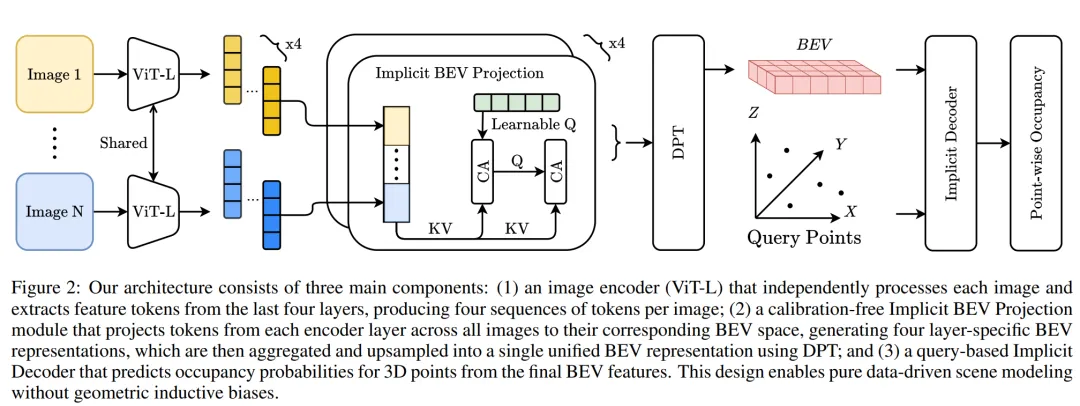
图像编码器:遵循简洁与可扩展性原则,我们采用ViT-Large主干网络从相机图像中提取视觉特征。与之前依赖感受野有限的卷积神经网络的自动驾驶模型相比,变换器架构通过自注意力捕获长程上下文依赖,同时引入的归纳偏置最小。每张图像由ViT-Large模型独立编码,生成一组紧凑的令牌嵌入,作为后续处理阶段的输入。
隐式鸟瞰图投影:自动驾驶应用需要在一个统一坐标系下、以度量尺度定义的、以场景为中心的几何表示。与深度图或点云图等图像对齐的表示不同,以场景为中心的表示支持对空间占据的直接推理,这对自动驾驶任务至关重要。为此,我们采用鸟瞰图表示,因为它能提供全面的场景覆盖,同时在计算和内存效率上优于稠密的三维体素网格。现有的自动驾驶方法依赖已知的相机内外参数,将图像特征显式投影到鸟瞰图空间。在简洁性和可扩展性原则指导下,我们寻求一种无需标定的、可将多视图视觉特征转换到鸟瞰图空间的方法,并适用于不同的相机配置。
我们设计了隐式相机到鸟瞰图投影模块,以从数据中学习几何变换。具体而言,该模块在图像块与鸟瞰图潜在查询之间使用了两个顺序的交叉注意力块。鸟瞰图潜在查询的数量少于图像块令牌的数量,以提升计算效率。为捕获多尺度几何信息,我们独立地将ViT-L编码器最后四层的输出投影到鸟瞰图空间,使用具有非共享权重和独立鸟瞰图查询的隐式投影模块。随后,所得的多层鸟瞰图表示通过DPT进行聚合与上采样,以获得最终细粒度的场景级鸟瞰图表示。我们通过消融实验比较不同投影结构和编码器层选择,验证了我们的设计决策。
隐式解码器:为了将离散的鸟瞰图网格转化为连续的占据场,我们采用了一个受ImplicitIO启发的隐式解码器,它将三维查询点映射为占据概率。我们对查询特征进行线性插值,并将其与归一化的查询点拼接。拼接后的特征通过卷积占据网络进行解码,以预测查询点的占据概率。

实验结果
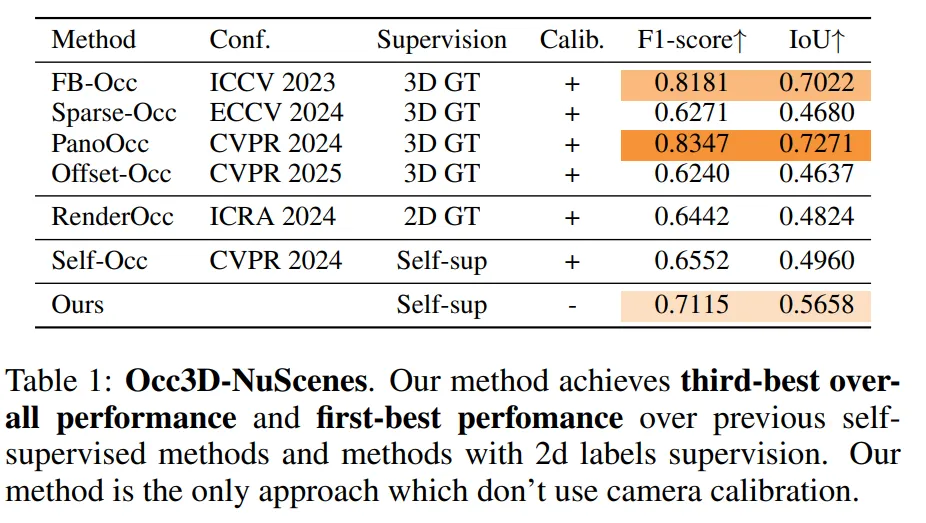
我们在不进行体素微调的情况下评估模型,以证明我们学习到的表示能够泛化到新的几何任务。我们的模型取得了综合性能第三名的成绩,F1分数为0.7115,IoU为0.5658,并且是唯一同时实现完全自监督和无需标定的方法。与需要昂贵三维标注的PanoOcc和FB-Occ等表现最佳的方法不同,我们的方法仅使用原始激光雷达点云进行监督,无需昂贵的人工标注。与此前最佳的自监督方法相比,我们在F1分数上提升了0.056,IoU上提升了0.07,同时还去除了对标定的需求。
如表2所示,我们的方法在所有指标和数据集上取得了最佳的平均排名。图12对平均排名前三的方法进行了可视化对比。在NuScenes和Argoverse 2数据集上,我们在AbsRel和CD指标上均优于所有竞争方法。在NuScenes数据集上,我们取得了0.068的AbsRel和1.807的CD,相比第二名方法分别提升了0.105和1.83。在Argoverse 2数据集上,我们取得了0.131的AbsRel,优于最佳竞争对手0.031;并取得了2.965的CD,优于最佳竞争对手0.716。在Waymo数据集上,我们取得了第二佳的CD性能,仅落后最佳方法0.05。在ONCE和NuPlan数据集上,我们取得了最佳的AbsRel性能,CD性能分别位列第三和第二。
总结 & 未来工作
本文提出了ViGT,一个用于自动驾驶的可扩展、基于视觉的几何模型,它能够直接从无标定的多相机图像中学习连续的三维占据场。ViGT基于同步的图像-激光雷达对,采用自监督学习流程在五个大规模数据集上联合训练。我们表明,所得的统一表示无需针对特定任务重新训练,即可直接用于多个下游任务的渲染,包括点云图估计和占据预测。大量评估实验证明,ViGT能有效泛化,在五种不同相机配置的数据集上的点云图估计任务中达到了最先进的性能,同时在基于体素的占据预测基准测试中与有监督方法相比仍具竞争力。我们认为,此类模型代表了为自动驾驶应用构建基础几何感知系统的一个前景广阔的研究方向。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉方向论文辅导来啦!可辅导SCI期刊、CCF会议、本硕博毕设、核心期刊等。



随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 高通联手Wayve下狠手:自动驾驶不再卖芯片,而是直接卖“整套大脑”
- 全球超豪轿车王者!新一代迈巴赫S级全球首秀
- 为什么二胎家庭90%会后悔买轿车?不是空间问题,是你没经历过3个大人+2个安全座椅
- 轿车托运可以随时问进度吗?可以,正规物流支持实时咨询
- 轿车托运可以押车吗?少数物流支持,本质是专人跟车看管
- 轿车托运视频验车可行吗?特定场景适用,需补全证据
- 年收入六万元的房奴不买轿车
- 落地300万的丰田世极SUV,百公里油耗10个,真实车主晒出仪表盘
- 买的“准新”SUV竟是泡水车?学会这5招验车法,车贩子都怕你……
- 2月豪华中大型SUV终端销量:国产宝马X5领跑 揽胜超卡宴
