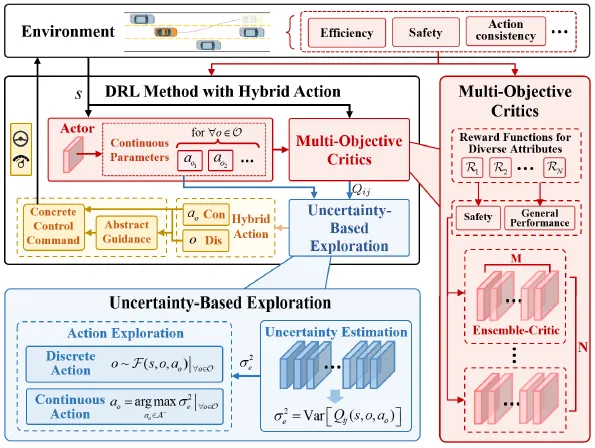
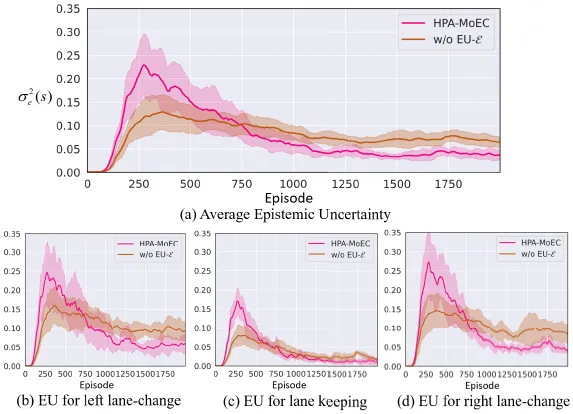
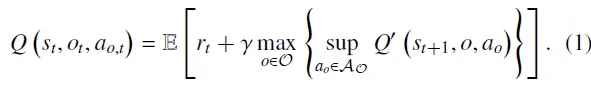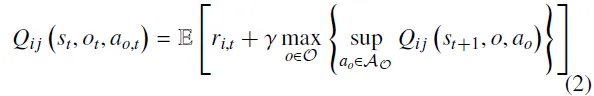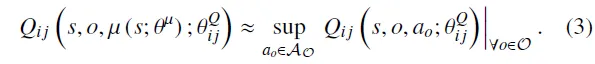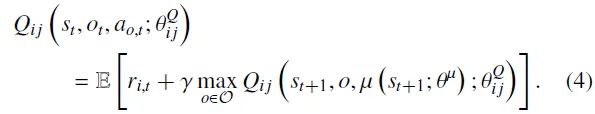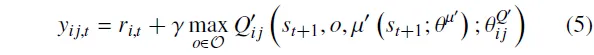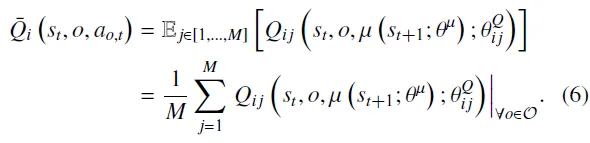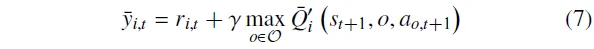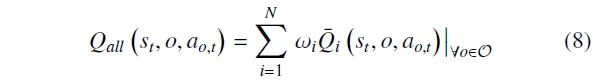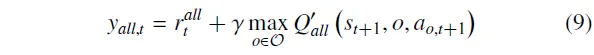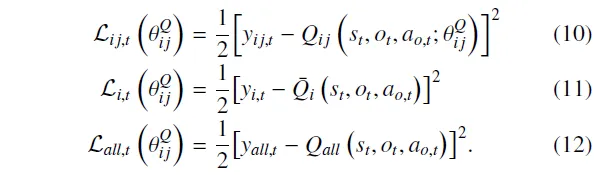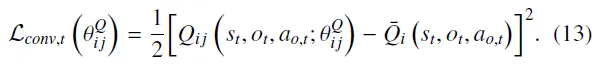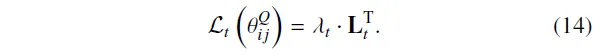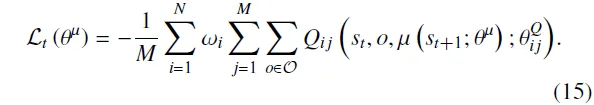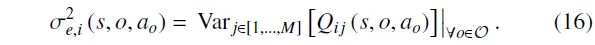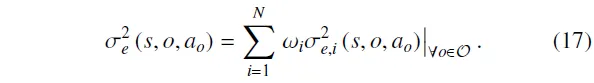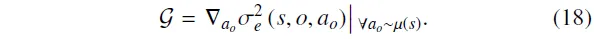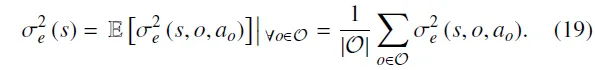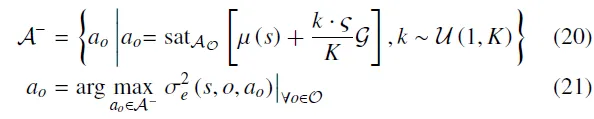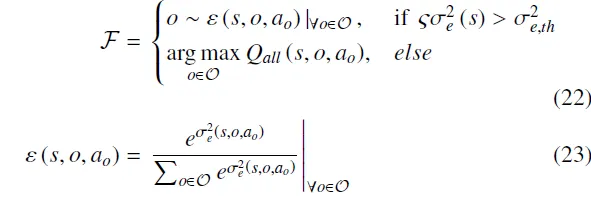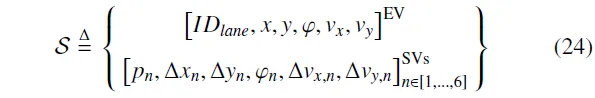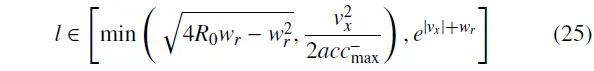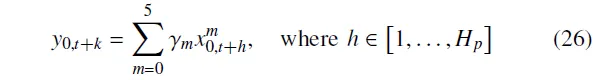A.总体框架
本文提出的方法基于一种混合参数化动作空间,用于策略评估与改进,并同时考虑多目标以实现多目标兼容性。因此,MDP可以被重新表述为如下新的元组形式:,其定义如下:
1)表示混合参数化动作空间,其中。表示从离散动作集合 中选取的离散动作选项,表示与该离散动作对应的连续动作参数,其取值来自于与对应的连续空间。
2)表示一组有个奖励函数,其中表示第个奖励函数,其中。
为了构建一种适用于混合道路结构的细粒度抽引导,所设计的混合动作空间使智能体能够同时输出离散动作和连续动作参数,从而在两者层面均实现最优性。这些输出随后被用于生成引导与具体控制指令。即横向控制通过将引导与先验知识相结合来生成,而纵向控制指令则直接由连续参数导出。
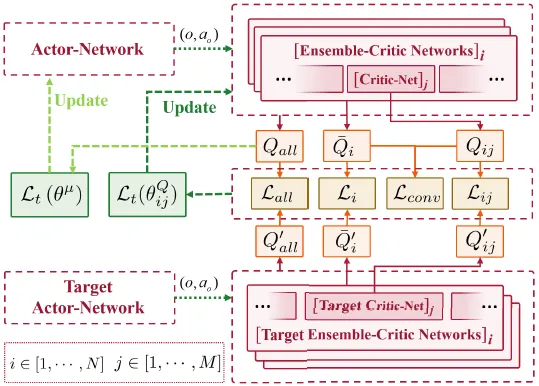
为此,设计了多目标集成评论家(MoEC)框架,该框架以各类属性作为评估目标,并引导智能体在高不确定性区域进行探索。具体而言,该框架由个协同工作以完成策略评估,其中每个评论家关注不同的属性。同时,每个集成评论家内部包含个子评论家。通过集成评论家可以刻画认知不确定性及其变化趋势,从而用于引导探索方向。本文提出的HPA-MoEC方法整体框架如图1所示。
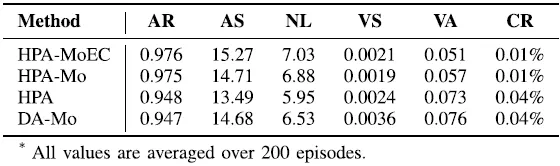
图1. 所提出的HPA-MoEC方法整体框架。该强化学习方法中的actor首先根据状态生成连续动作参数,随后将其与状态一同输入多目标评论家模块以进行价值函数评估。该模块由N个集成评论家组成,分别对应不同的属性目标,每个集成评论家内部包含M个子评论家。随后,探索策略模块从这些集成评论家中捕获认知不确定性,并据此选择最终的混合动作,从而提升训练效率。
B.策略和价值函数表示
在混合参数化行动空间下,最优策略的状态-行动值函数可由贝尔曼最优方程描述,如下:
HPA-MoEC由个集成评论家组成,每个集成评论家包含个子评论家,从而在价值函数评估中总计包含个评论家。具体而言,每个评论家都可以基于其关注的属性,对状态下动作的价值进行估计。设表示第个集成评论家中第个子评论家对应的最优价值函数:
其中,且。然而,在参数化动作空间中求解最优连续动作是一项具有挑战性的任务。为了解决这一问题,假设价值函数是固定的。在此假设下,优化连续动作的问题可以转化为确定从状态到动作的映射关系:。为逼近该映射关系,引入确定性策略网络,从而得到连续动作,其中网络参数为。同时,采用价值网络对价值函数进行逼近,其参数记为。在价值函数固定的假设下,参数化动作空间中的MDP可以被视为:在给定的条件下,对策略进行优化的过程。
具体而言,该过程可以通过双时间尺度更新规则[59]进行近似,其中参数的训练更新步长显著大于的更新步长。因此,可以表示为:
为了追求更高的回报,参考DQN[21]中的价值网络更新目标,单个评论家的更新目标是:
其中,和分别表示用于辅助更新评论家和策略的目标网络,其参数分别为和。
评论家的更新目标需要同时融合两类信息:一是基于集成评论家的属性视角,二是基于多目标兼容的整体性能视角。对于第个集成评论家,其在给定属性下对策略性能的整体评估可表示为其内部个子评论家输出价值的期望:
相应地,训练中本次集体批评的总体目标可表示为:
其中,表示所有的期望值。此外,策略的输出会根据权重对个集成评论家赋予不同的关注程度。因此,在整体层面上用于评估策略多目标兼容性的价值函数可以表示为如下形式:
其中,。在此基础上,HPA-MoEC中所有评论家的整体更新目标可以表示为:
其中,表示基于各集成评论家注意力权重的属性奖励加权组合,即。同时,表示加权后的综合价值函数。
因此,参数的更新不仅考虑该评论家自身的时序差分(TD)误差,还同时考虑同一属性下所有评论家的平均TD误差,以及所有评论家的整体TD误差。基于这三个方面,对应的损失函数定义如下:
本文在参数的损失函数中引入了一项引导项,该机制有助于确保同一集成评论家中的所有子评论家在参数更新时保持相似的方向。
总之,当更新参数时,最终损失函数说明了前面讨论的四个方面:
其中,表示损失函数向量,为对应的权重系数向量。通过对定义的损失函数进行反向传播,价值网络可以进行迭代更新。
更新策略的目标更简单,即通过最大化总价值函数找到多目标兼容的最佳策略
总体而言,策略参数以及任意评论家参数的更新过程如图2所示。
图2. 所提出的演员和任何评论家的网络参数更新过程。目标网络进行软更新。
C.不确定性评估和探索策略
认知不确定性反映了由于学习不充分而导致的智能体知识缺失,可通过集成评论家进行刻画[60]。在第个集成评论家中,各子评论家的评估结果差异越大,表明对应属性上的认知不确定性越高。第个属性的认知不确定性方差可表示为:
考虑到为实现多目标兼容性,不同集成评论家被分配了不同的关注权重,这些权重也用于计算智能体的整体认知不确定性。
在参数化动作空间中,被视为离散动作的参数。因此,对于任意动作对,其认知不确定性的变化可以通过梯度进行刻画。
此外,需要明确的是,表示在条件下,状态–动作对的认知不确定性;而在状态下环境的整体不确定性则表示为:
在认知不确定性引导下,智能体针对离散动作及其对应连续动作采用两种不同的探索策略,探索潜在的有效策略空间。对于连续动作,其最终执行的,由策略的输出以及共同决定。因此,理想的连续动作探索策略可以被表述为如下非线性连续优化问题:。然而,直接求解该优化问题在计算上代价较高。因此,通过构建一个有限的动作集合来近似该过程,其中。该集合基于策略的原始输出以及认知不确定性的梯度信息进行构造,从而将连续空间中高不确定性动作的选择问题离散化处理。
其中,表示在区间上的均匀分布。系数随训练过程逐步减小,其中,用于反映智能体在探索与利用之间的动态权衡。
类似地,最具探索性的离散动作是使认知不确定性最大的动作,即:。引入不确定性阈值,当不确定性较低时,促使智能体转而采用以奖励最大化为目标的贪婪策略。针对评论家网络的参数在训练初期是随机初始化的,其输出可能产生波动这一问题,采用概率化方法,而非直接选择具有最大不确定性的动作。具体而言,类似于Softmax函数,离散动作的选择概率由其不确定性值决定,且所有动作的选择概率之和为1。因此,离散动作的选择服从如下函数,即:。
其中表示选择各个动作的概率。
基于上述方法,本文在算法1中给出了HPA-MoEC的完整训练流程。