
🚗 还在为自动驾驶模型找不到“茬”而发愁吗?传统的对抗测试就像“一次性找茬”,找到问题也难回头教模型。同济大学这篇新论文,直接把“评估”变成了“进化”,让AI在持续生成的“刁难”场景中主动学习、越挫越勇!想第一时间掌握这种“闭环进化”的前沿玩法吗?👇扫码加入「龙哥读论文」知识星球,每天2分钟,前沿论文、实战代码、行业动态一站式拿捏,让你的研究也“闭环”起来!

龙哥推荐理由:
这篇论文最吸引我的地方在于,它把“找问题”和“解决问题”这两个通常割裂的环节,用一套精巧的框架给闭环了。不再是“测完拉倒”,而是“测到哪,学到哪”。它用拓扑分析精准定位“软肋”,再用扩散模型生成“高难度但合理”的对抗场景,让AI策略在持续“挨打”中主动进化。这种“评估即进化”的思路,不仅对自动驾驶,对任何需要在高风险、长尾分布环境中做决策的AI系统,都极具启发性和实用价值。
原论文信息如下:
论文标题:
Evaluation as Evolution: Transforming Adversarial Diffusion into Closed-Loop Curricula for Autonomous Vehicles
发表日期:
2026年04月
发表单位:
同济大学交通运输工程学院 (Yicheng Guo, Chengkai Xu, Peng Hang, Jian Sun); 北卡罗来纳大学教堂山分校计算机科学系 (Jiaqi Liu)
原文链接:
https://arxiv.org/pdf/2604.07378v1.pdf
想象一下,你教一个小朋友学骑车。传统的教法是:让他自己骑几圈,你在旁边看,摔了跤你记下来,然后下次还是让他自己骑同样的几圈——这不就相当于“训练-测试-问题报告”的死循环吗?
自动驾驶的开发和测试也陷入了类似的困境。模型在海量的正常行驶数据中练得“油光水滑”,但对那些极其罕见却致命的“黑天鹅”场景,应对能力基本靠猜。更头疼的是,就算费尽心思用“对抗测试”找到了模型的弱点,这些宝贵的失败案例也很难高效地“喂”回给模型,让它变聪明。
同济大学和北卡罗来纳大学的研究者们,就带来了一个堪称“学车教练”级的解决方案:Evaluation as Evolution (E²),一个让评估本身进化为学习课程的闭环框架。
它不再满足于当个“找茬员”,而是要成为一位洞察弱点、精准出题、批改作业、并据此调整教学难度的智能教练。
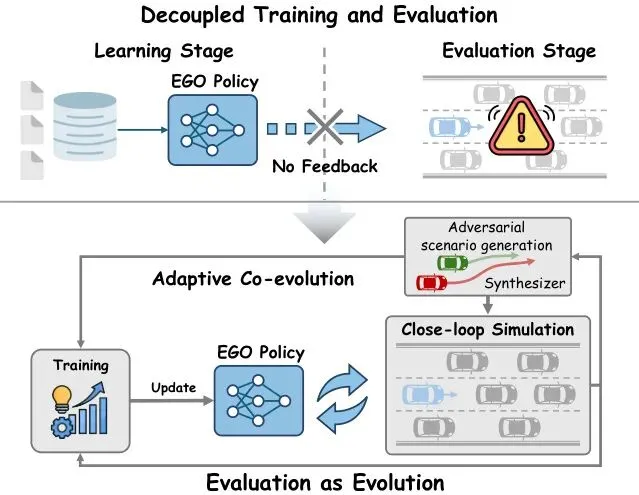
告别静态测试:让评估“活”起来,闭环演化如何炼成?
传统自动驾驶评估最大的痛点是“测教分离”。你用一个庞大的、静态的测试场景库去“考”你的模型,发现它在一个路口被“鬼探头”搞挂了。很好,你把这个失败案例写进报告。然后呢?模型不会自动学会应对这个场景。你需要手动把这个场景变成一个训练样本,重新扔进训练流程,祈祷下次它能学会。这个反馈环又慢又笨拙。
E² 的理念极其直接:别分开干了,让“找茬”(对抗生成)和“学习”(策略优化)手拉手一起跑。它的核心是一个闭环进化的过程。
图1:从解耦评估到闭环演化。上图:传统流程将训练和评估分开,发现的故障与策略学习脱节。下图:E² 将对抗合成器与自我策略耦合,为闭环模拟合成对抗性交互,并将结果作为学习信号回馈以更新自我策略。
1. 对抗合成器(攻击方):瞅准当前自动驾驶策略(Ego Policy)的软肋,利用学到的真实交通数据分布,合成一个“既刁钻又合理”的交通场景,专门让它犯错(比如制造碰撞)。
2. 自我策略(防守方):在这个生成的对抗场景里进行闭环模拟,如果真“翻车”了,这次的失败轨迹就成了宝贵的学习数据。
3. 策略更新:用这些“失败作业”对策略进行微调,让它记住这次的教训,变得更强。
4. 难度升级:策略变强后,原来的“刁难”可能就不管用了。合成器会感知到这一点,调整自己的攻击策略,去寻找策略新的、更高级的弱点,生成更难、更复杂的场景。
如此循环往复,自动驾驶策略就像一位在顶尖教练指导下不断挑战更高难度动作的运动员,其鲁棒性得以持续、自适应地进化。

三大核心组件拆解,精准打击策略弱点
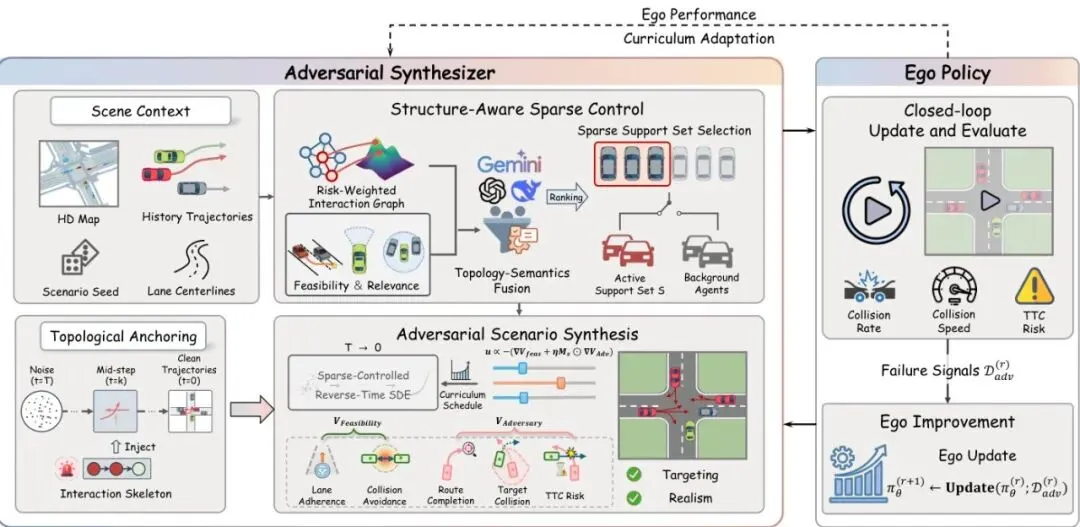
光有理念不够,还得有硬核技术支撑。E² 框架中最精妙的部分,就在于它如何实现那个“既刁钻又合理”的场景生成。这背后是三大核心技术的融合:
图2:评估即进化概览。左(对抗合成器):给定场景上下文,合成器构建风险加权交互图,通过拓扑分岔分析选择干预关键的前K个对抗集合,并通过在带有拓扑锚定的反时间SDE先验上进行传输正则化稀疏控制,合成可行、真实的对抗轨迹。右(自我策略):自我策略执行闭环模拟以获得安全信号来更新自我策略;更新后的性能反馈回来以调整合成器的课程。
一个十字路口可能有几十辆车,如果为了制造事故去胡乱操控所有车,生成的场景大概率会像一场车祸大杂烩,毫无真实感,也学不到有用的东西。
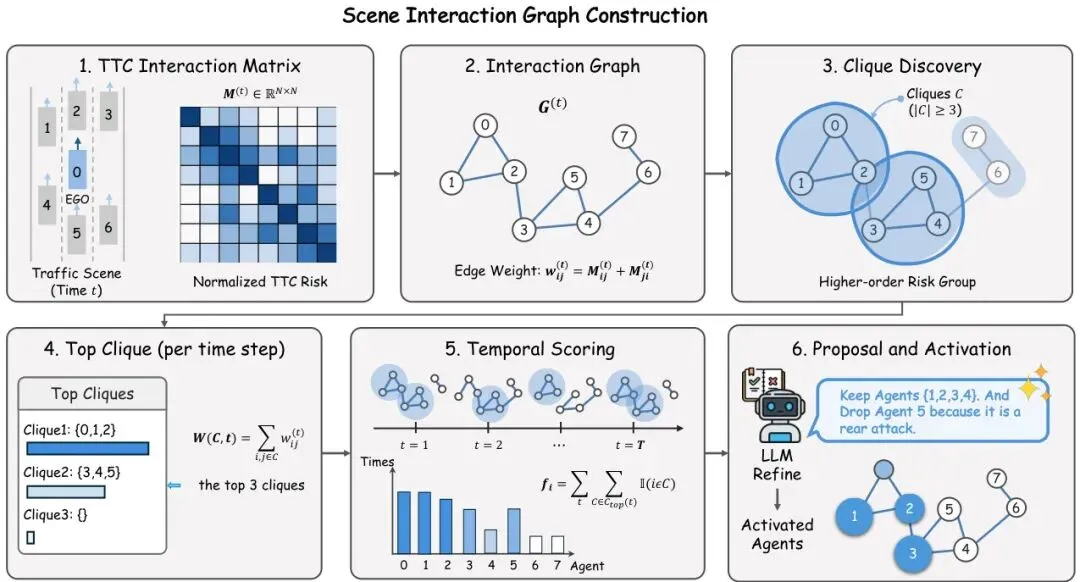
E² 的做法很聪明:只精准操控少数几个“关键先生”。怎么找?靠拓扑分岔分析 (Topological Bifurcation Analysis)。
首先,根据车辆之间的“碰撞时间”(TTC, Time to Collision)等指标,构建一个随时间变化的风险交互图。然后,在这个图中寻找那些紧密耦合、高风险的小团体(K-团,Clique)。最后,计算每个车辆在这些高风险小团体中出现的频率,频率最高的那几个,就是最有可能“牵一发而动全身”的拓扑关键节点。
图3:通过场景交互图构建实现结构感知的稀疏控制。合成器构建基于TTC的风险交互矩阵,将其转换为加权交互图,发现高阶风险组(团),并跨时间选择顶部团来评分和激活一小部分对抗智能体进行针对性控制。
这样一来,对抗控制就从“覆盖所有车辆的全局扰动”,变成了“对关键节点的精准外科手术”,计算量骤降,场景的真实性也得以最大程度保留。
二、 基于反时间SDE的传输正则化控制:戴着镣铐跳舞
找到了关键节点,下一步是具体怎么“操控”它们来生成对抗轨迹。这里用到了扩散模型 (Diffusion Model)和随机微分方程 (SDE, Stochastic Differential Equation)。
先训练一个扩散模型作为“交通行为先验”,它学会从噪声中生成看起来非常真实的、多智能体的未来轨迹。这个生成过程可以用一个反时间的SDE(Reverse-Time SDE)来描述:
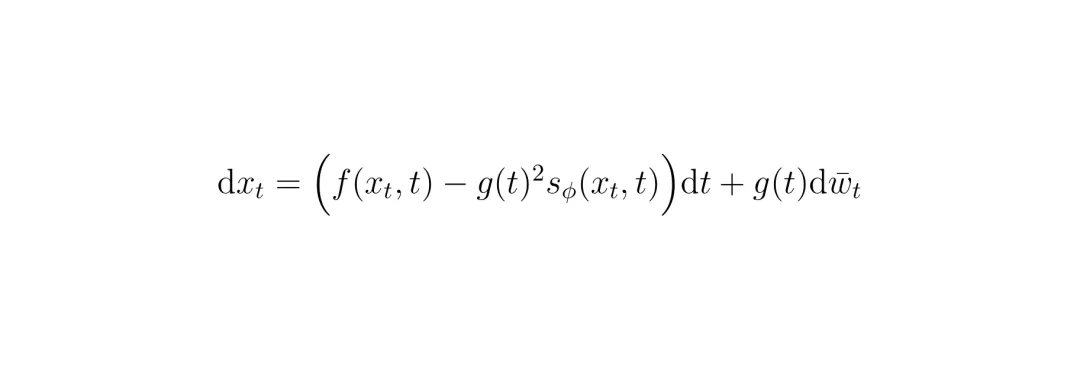 这个方程描述了如何从纯噪声 (x_T) 一步步“去噪”,最终生成符合真实数据分布 (p_0) 的轨迹 (x_0)。其中的分数项 (s_φ) 就是模型学到的交通规律。
为了制造对抗,E² 在这个反时间SDE中引入一个额外的控制项 (u_t),像一只“无形的手”,在去噪过程中把生成轨迹往“危险”的方向推:
这个方程描述了如何从纯噪声 (x_T) 一步步“去噪”,最终生成符合真实数据分布 (p_0) 的轨迹 (x_0)。其中的分数项 (s_φ) 就是模型学到的交通规律。
为了制造对抗,E² 在这个反时间SDE中引入一个额外的控制项 (u_t),像一只“无形的手”,在去噪过程中把生成轨迹往“危险”的方向推:
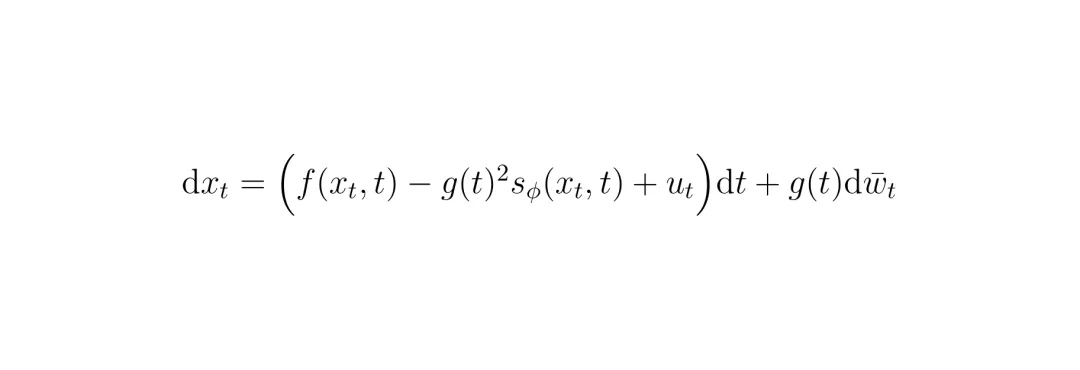 但光推不行,推得太猛场景就失真了,变成“汽车总动员”里的特技表演。所以E² 的核心约束是:在最大化危险目标(如碰撞风险)的同时,最小化生成场景分布与真实交通先验分布之间的KL散度 (KL Divergence)。这个KL散度可以理解为一种“传输成本” (Transport Cost)。
但光推不行,推得太猛场景就失真了,变成“汽车总动员”里的特技表演。所以E² 的核心约束是:在最大化危险目标(如碰撞风险)的同时,最小化生成场景分布与真实交通先验分布之间的KL散度 (KL Divergence)。这个KL散度可以理解为一种“传输成本” (Transport Cost)。
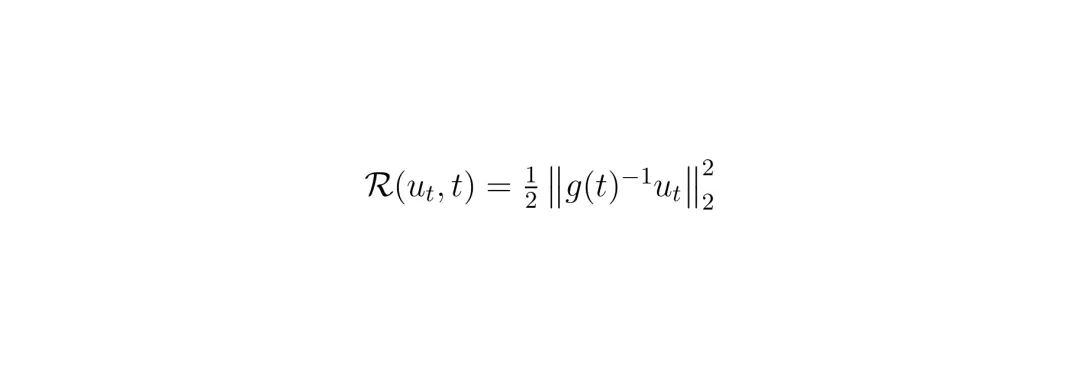 这个正比于控制能量 ||u_t||² 的项,正是KL散度的等价形式。它像一个“真实性锚”,确保那只“无形的手”不能为所欲为,生成的对抗场景始终在真实交通行为的合理边界内——这就是“戴着镣铐跳舞”。
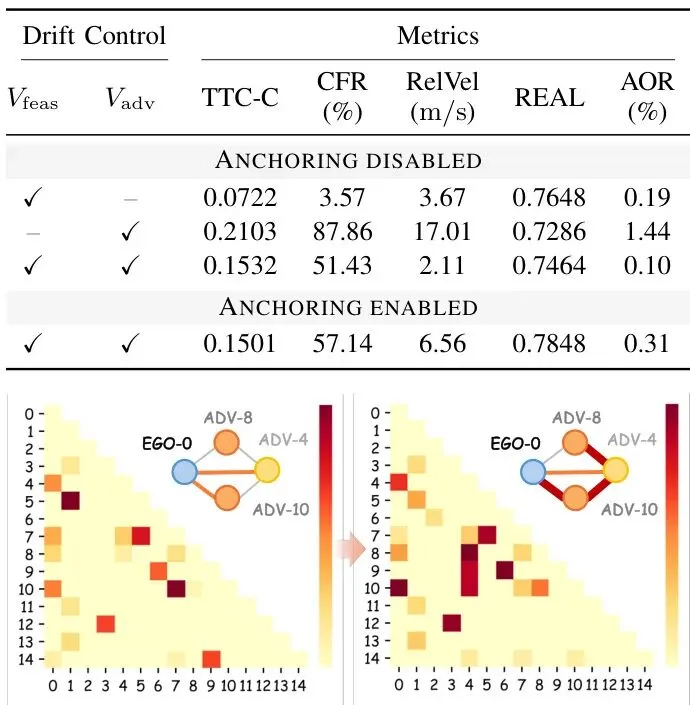
最后一个技术细节是拓扑锚定 (Topological Anchoring)。直接从纯噪声开始,试图引导生成一个复杂的、多车协调的对抗场景(比如“连环追尾”),过程可能很不稳定,容易跑偏。
E² 的做法是:在扩散去噪过程进行到一半(某个中间时间步 t_a)时,不是完全由噪声状态演变,而是将其与一个预设的“交互骨架”状态进行混合。
这个正比于控制能量 ||u_t||² 的项,正是KL散度的等价形式。它像一个“真实性锚”,确保那只“无形的手”不能为所欲为,生成的对抗场景始终在真实交通行为的合理边界内——这就是“戴着镣铐跳舞”。
最后一个技术细节是拓扑锚定 (Topological Anchoring)。直接从纯噪声开始,试图引导生成一个复杂的、多车协调的对抗场景(比如“连环追尾”),过程可能很不稳定,容易跑偏。
E² 的做法是:在扩散去噪过程进行到一半(某个中间时间步 t_a)时,不是完全由噪声状态演变,而是将其与一个预设的“交互骨架”状态进行混合。
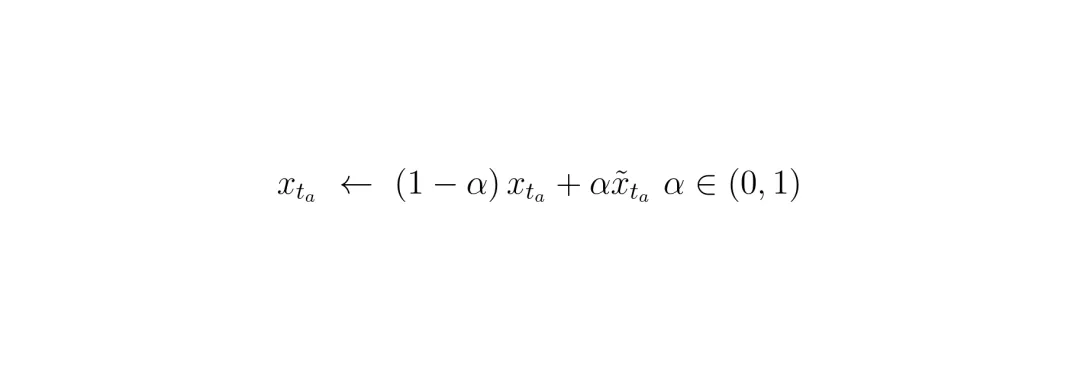 这个“交互骨架”是根据之前找到的关键节点,规划出的一个粗略的、符合运动学和交通规则的因果链(例如,远处的A车影响近处的B车,B车再影响主车)。锚定操作相当于告诉模型:“伙计,朝着这个大致靠谱的剧情方向走,细节上你自由发挥。”这极大地稳定了对抗场景的生成,让它更容易收敛到我们想要的、复杂的失败模式。
图5:定性交互骨架。同一场景下基于TTC的交互矩阵和激活的主车-对抗车链。左:禁用拓扑锚定。右:启用拓扑锚定。
这个“交互骨架”是根据之前找到的关键节点,规划出的一个粗略的、符合运动学和交通规则的因果链(例如,远处的A车影响近处的B车,B车再影响主车)。锚定操作相当于告诉模型:“伙计,朝着这个大致靠谱的剧情方向走,细节上你自由发挥。”这极大地稳定了对抗场景的生成,让它更容易收敛到我们想要的、复杂的失败模式。
图5:定性交互骨架。同一场景下基于TTC的交互矩阵和激活的主车-对抗车链。左:禁用拓扑锚定。右:启用拓扑锚定。
实验效果说话:故障发现率大幅提升,策略鲁棒性显著增强
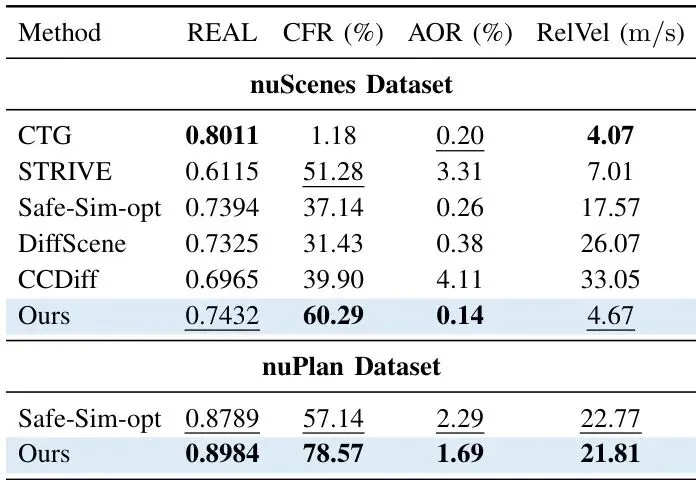
理论很美好,效果如何?论文在nuScenes和nuPlan两大主流自动驾驶数据集上进行了验证。
首先,E² 作为“找茬员”的本职工作干得极其出色。对比了包括 CTG, STRIVE, DiffScene 在内的多种先进对抗生成方法,E² 在碰撞故障发现率 (CFR, Collision Failure Rate)这个核心指标上全面领先。
表1:与基线的闭环性能对比。指标量化了生成交互的真实性和安全关键性。我们报告了7个随机种子的平均值。每列(每个数据集)最佳为粗体,次佳为下划线。蓝色代表E²。
具体来看,在nuScenes数据集上,E² 的碰撞故障发现率比最强的基线提升了9.01%。更夸张的是在nuPlan数据集上的零样本 (Zero-shot)测试(模型未在nuPlan上重新训练),E² 的故障发现率比基线高出21.43%!这证明了其强大的泛化能力。同时,E² 生成的场景在“真实性”指标上依然保持高水平,说明它不是靠“作弊”(生成离谱场景)来刷分的。
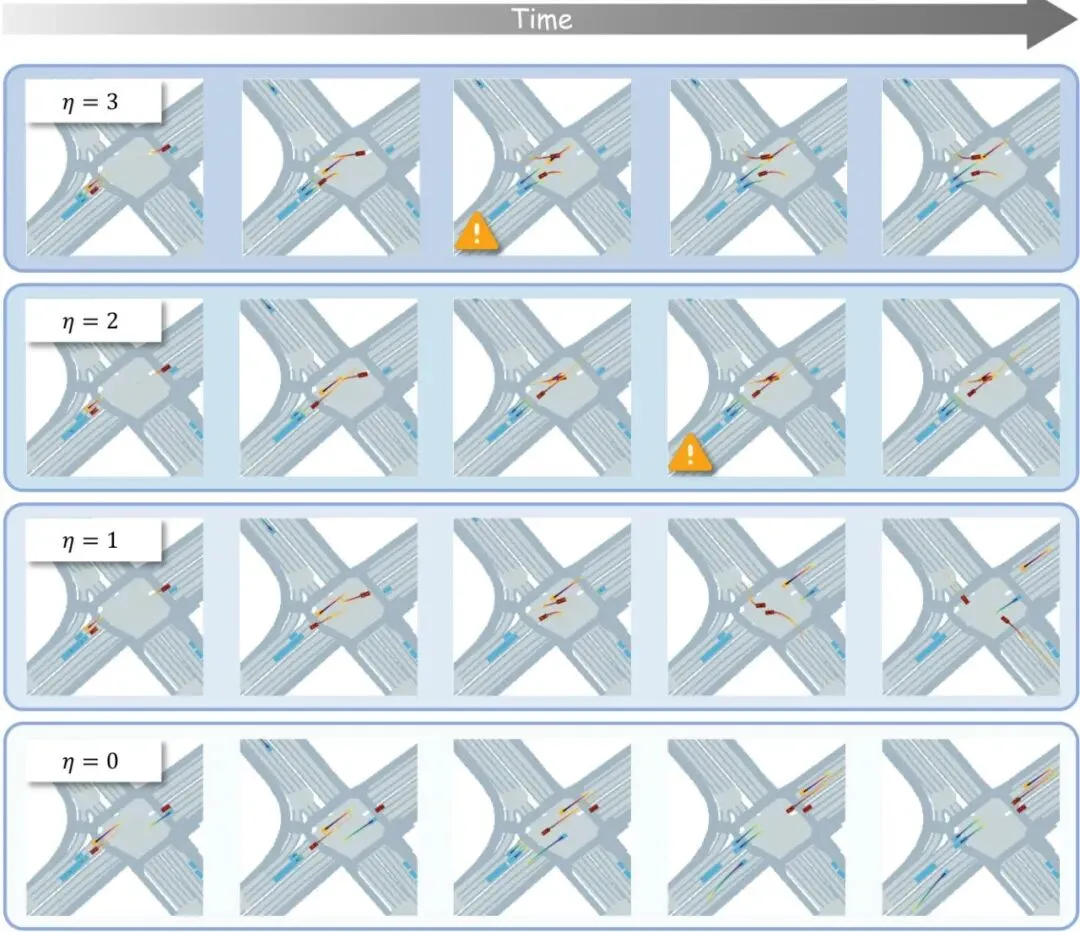
图4:故障时间和类型在增加的对抗强度下的定性可控性。固定随机种子(种子=50)下,针对车道图(LG)自我策略的闭环推演,η∈{0,1,2,3}从下到上。
“找茬”是为了“教学”。E² 的终极价值在于,它生成的这些高质量的、真实的对抗场景,真的能让自动驾驶策略变强。
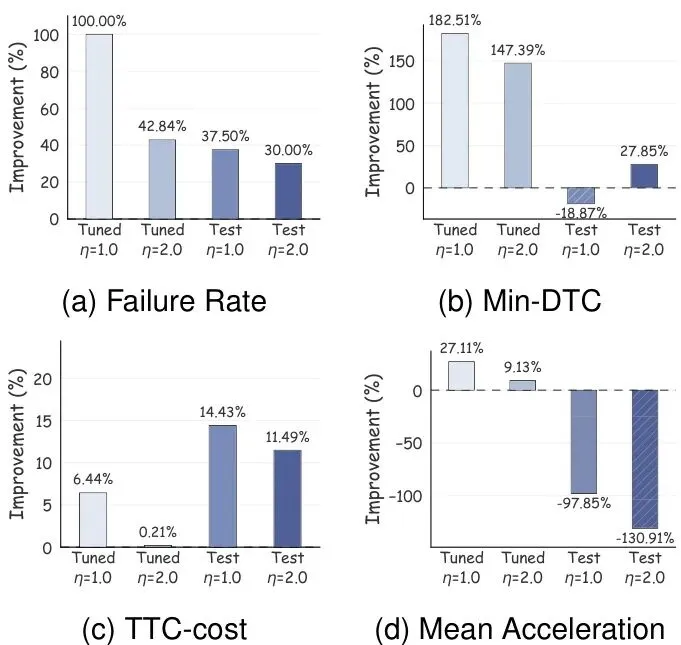
图6:通过对抗闭环微调带来的策略改进。柱状图显示了在nuScenes验证集的一个微调子集和一个不相交的测试子集上,相比于原始车道图策略的百分比增益,评估分别在匹配和增加的对抗强度(η=1.0, 2.0)下进行。
实验表明,使用E² 生成的边界案例对自动驾驶策略进行微调后,策略的鲁棒性得到了显著且可泛化的提升。在匹配强度的测试中(η=1.0),微调后的策略在未见过的测试集上碰撞率降低了约10%。即使在更高强度的对抗(η=2.0)下测试,其性能依然优于原始策略。这说明模型不仅仅记住了某个特定场景的解法,而是学到了一种更通用的、应对高风险交互的能力。
不止于评估:闭环课程如何重塑自动驾驶学习范式?
E² 的价值远不止于一个更好的“测试工具”。它代表了一种全新的自动驾驶研发范式的雏形。
传统的范式是“采集数据-训练-静态评估-手动分析-修改”。这个过程缓慢、割裂,且极度依赖工程师的经验去设计和分析那些“角落案例”(Corner Case)。
E² 开启的范式是“初始数据训练-闭环进化课程-自适应鲁棒性增强”。在这里,评估和学习不再是前后工序,而是一个统一的、自适应的协同进化过程。系统自己发现弱点,自己生成针对性的训练材料,自己验证学习效果,并据此调整下一步的“教学计划”。这就像给AI配备了一位不知疲倦、洞察力敏锐的私人教练。
这种思路不仅适用于自动驾驶,对于任何需要在高风险、长尾分布(Long-tail Distribution)环境中做决策的AI系统——比如机器人、金融风控、网络安全博弈——都具有深刻的启发性。如何高效地探索决策边界上的脆弱点,并利用这些点进行针对性强化,将是提升AI系统安全可信赖性的关键。龙迷三问
这篇论文解决的核心问题是什么? 解决自动驾驶开发中“训练”和“测试/评估”环节割裂的问题。传统方法找到的模型弱点(如特定碰撞场景)很难有效地反馈给模型用于再训练。本文提出的E²框架,将对抗场景生成与策略学习整合进一个闭环,使评估过程本身能自动、持续地产生“教学材料”,驱动策略鲁棒性进化。
E² 里的 “SDE” 和 “KL Divergence” 是什么意思? SDE (Stochastic Differential Equation),即随机微分方程,在这里是用来描述扩散模型中从噪声生成数据轨迹的数学过程。KL Divergence (Kullback–Leibler Divergence),即KL散度,是一种衡量两个概率分布差异的指标。在E²中,用它来约束生成的对抗场景分布不能偏离真实的交通行为分布太远,确保生成场景的合理性。
“拓扑分岔分析”听起来很抽象,它在E²里具体怎么用? 简单说,就是把复杂的交通场景看成一个动态的网络(图)。每个车是一个点,车辆之间根据碰撞风险(如TTC)的紧密程度构成边。拓扑分岔分析的任务就是在这个动态网络中,找出那些最“关键”的小团体(团)——通常是两三辆位置和速度关系最紧张、最容易出事故的车。E² 只对这些“关键先生”施加控制,就能高效且真实地制造出危险场景,而不是去控制所有车,这大大提升了效率和真实性。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将“评估”重新定义为“进化”,并构建了一套完整的技术框架来实现这一闭环,思想上有明显的跃升。将拓扑分析、SDE控制、课程学习三者有机结合,设计精巧。实验合理度:★★★★☆
在nuScenes和nuPlan两大基准上与多种SOTA方法对比,指标全面(兼顾安全性和真实性),进行了充分的消融实验验证各模块作用,并额外证明了策略微调的有效性,实验设计扎实。学术研究价值:★★★★★
非常高。不仅为自动驾驶安全评估与鲁棒性训练提供了一个强有力的新工具,其“闭环进化”、“基于传输正则化的对抗生成”、“拓扑引导的稀疏干预”等核心思想,可迁移到任何涉及智能体交互、长尾风险和安全关键决策的AI研究领域。稳定性:★★★☆☆
方法本身在实验中表现稳定,但其依赖于预训练的扩散模型作为先验,且对抗生成过程涉及优化。在极端复杂的真实世界角落案例中,生成过程的稳定性和成功率仍需在更广泛的部署中验证。适应性以及泛化能力:★★★★☆
在nuPlan上的零样本测试结果(提升21.43%)证明了其良好的跨数据集泛化能力。其方法论基于数据驱动和通用优化原理,理论上可适配不同的交通模型和策略架构。硬件需求及成本:★★★☆☆
需要运行预训练的大型扩散模型,并在其基础上进行迭代的反向扩散和优化控制,计算开销显著高于简单的规则或基于检索的测试方法,对算力有一定要求。复现难度:★★★☆☆
中等偏上。需要复现或获得一个高质量的多智能体交通扩散模型作为先验,并实现文中描述的拓扑分析、控制优化和闭环课程逻辑。算法细节描述较清晰,但工程实现有一定复杂度。产品化成熟度:★★☆☆☆
目前主要处于前沿研究验证阶段。要集成到实际的自动驾驶开发流水线中,需要解决与现有仿真工具链的对接、生成效率的进一步提升、以及对生成场景进行大规模自动化标注和质检等工程问题。可能的问题:本文实验均在模拟器中进行,生成场景的真实性上限受限于扩散模型先验和模拟器的保真度。闭环进化可能使策略过度拟合于当前生成器分布,需警惕“过优化”风险。如何定义和保证生成场景的“语义合理性”而非仅统计合理性,仍需探索。Guo, Y., Liu, J., Xu, C., Hang, P., & Sun, J. (2026). Evaluation as Evolution: Transforming Adversarial Diffusion into Closed-Loop Curricula for Autonomous Vehicles. arXiv preprint arXiv:2604.07378.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的AI模型也学会在“挨打”中成长吗?🤖 欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+上海+同济+龙哥),根据格式备注,可更快被通过且邀请进群。和更多同行一起,探讨如何“折磨”出更强大的AI!



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
