押错自动驾驶路线,比没押还危险
- 2026-05-13 10:20:47
押错自动驾驶路线,比没押还危险我一直觉得,自动驾驶这个赛道,绝大多数人都在聊错方向。 大家聊的是:谁的激光雷达更好?谁的摄像头算法更强?谁先落地商业化? 
但很少有人说清楚一件事—— 自动驾驶,底层的技术路线,到底走向哪里? 这个问题不搞清楚,投资逻辑就是沙上建塔。 先说一个有点绕、但很关键的比喻 相机和激光雷达在一起做融合,就像瞎大爷过马路,拉上聋大奶奶,聋大奶奶说不出来,但她能领路,这俩人凑一起了,过了马路。 听起来像笑话,但这说的是一件严肃的事: 感知融合,是现阶段自动驾驶的主流方案。一个负责"看",一个负责"定位",两者互补。这没问题。 但问题在于,凑合着过马路,不等于真的看清了路。 
融合方案能解决"感知"的问题,解决不了"理解"的问题。 感知和理解,是两回事。 这就引出了自动驾驶真正的核心战场。 现在有两条路,方向完全不同 我先说主流路线,也就是现在大多数新势力在走的路——VLA路线。 VLA是什么?Vision-Language-Action,视觉-语言-行动。 简单说:把摄像头看到的画面,先翻译成人类语言描述,再通过语言模型理解,最后输出驾驶行为。 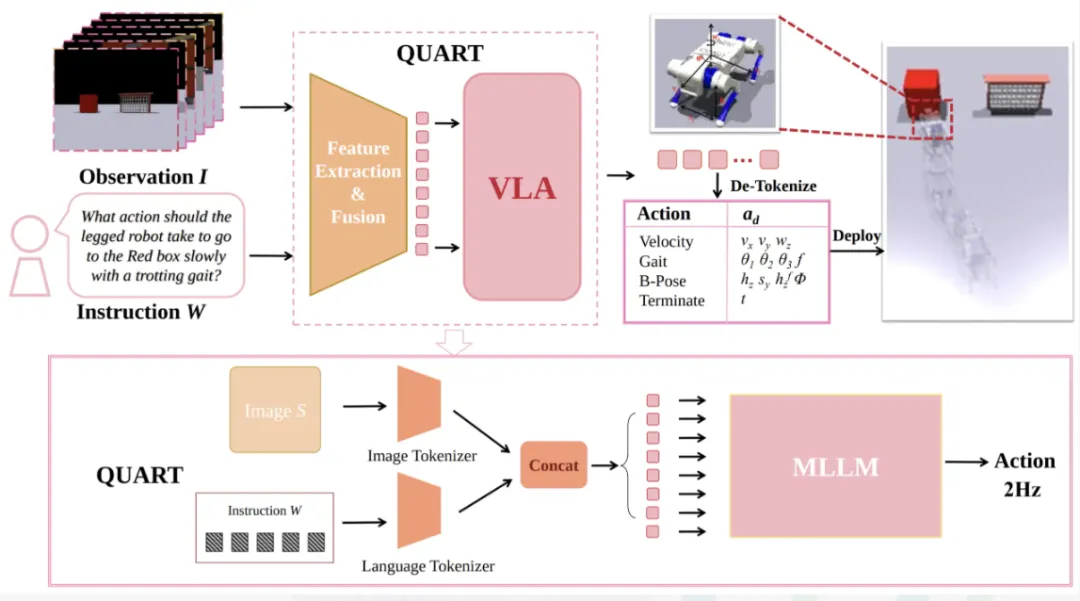
听起来很合理,对吧?借助大语言模型的能力,理解复杂场景。 但这里有一个根本性的问题。 我们为什么要把它变成一个人类所讲的语言?物理世界,和语言世界,天然存在信息损耗。中文和英文之间,很多概念就已经对不上了。物理世界和人类语言之间,信息缺口只会更大。 你强行用语言描述一个复杂的驾驶场景,就像用文字描述一首音乐——能说,但必然失真。 这个"必然失真",就是VLA路线的天花板。 那另一条路呢? 特斯拉在走一条没有公布的路 我注意到一个细节。 业内几乎所有新势力,都在跟着主流论文的方向走VLA。但特斯拉,没有公布自己的技术路径。 其实就是特斯拉没有公布出它的这个技术路径。然后这边一下子就觉得猜不着,只能说按照主流的论文的方向去做。 但特斯拉那套东西,底层逻辑就是: 把整个物理世界Token化。 
Token化,到底是什么意思 这里要说到一个物理概念,波粒二象性。 波粒二象性是指光波既是波又是粒子。它既表现成像一个球,又表现出像一个波。这是我们人为了理解强行把它变成这样。 机器不需要套人类的框架。它可以用自己的方式理解物理世界——用Token。 不是把场景翻译成语言,而是直接把场景打包成一种机器原生的表达形式。 其实自动驾驶当中的这个所谓VLA当中的中间部分,就是我们在把这个视觉和最后的Action就是行为之间做转换的过程。我们尽量用一种隐藏的Token来表示。 
视觉输入,到行为输出,中间那层转换,尽量不经过人类语言。 这,就是两条路线的本质区别。 那投资上,这意味着什么? 我直接说结论。 VLA路线,上限被语言压缩的信息损耗锁死了。 不论是怎么起名字吧,只要L不去掉这个限制就解除不了。 这不是工程问题,是路线问题。工程优化解决不了路线的天花板。 那跟着VLA路线走的供应链,就要注意了。 语言模型处理层、基于语言理解的感知模块——这些如果深度绑定了VLA路线,一旦行业切换方向,就是硬切。 不是渐进式迭代,是路线替换。 这种风险,在PPT里看不出来。得看技术底层。 那谁可能受益? 我的判断框架是这样的: 不依赖特定路线的基础设施层,是最安全的。 不管走VLA还是Token化,都需要算力。都需要数据。都需要传感器。都需要高精地图。 这些东西,是路线无关的。 但更值得关注的,是押对了Token化路线的整车厂或技术平台。 为什么? 因为Token化路线,数据飞轮的壁垒比VLA更深。 VLA的能力上限,在语言模型本身。语言模型是公共资源,大家都能用。 但Token化路线,要训练的是机器对物理世界的原生理解。这个理解,来自海量真实驾驶数据的持续喂养。 数据越多,Token化的世界模型越准。这是一个正反馈循环。 而且这个循环,先跑起来的人,壁垒会越来越厚。 最后谈谈 我觉得,自动驾驶这个赛道,现在真正的分水岭不是"谁更快落地"。 是谁在做更正确的事。 自动驾驶的终局是把世界Token化。 现在大多数人盯着的那些指标——每公里接管次数、城市路段覆盖率——都只是短期的。 真正的终局,是谁能建立起对物理世界的原生理解能力。 这个能力,用语言模型压缩不出来。只能用数据和时间,一点一点喂出来。 所以我的判断是:这个赛道,接下来的竞争,会越来越像AI基础模型的竞争 拼的不是今天谁跑得快,而是谁的飞轮转得更健康。 
看清楚这一点,很多所谓的"弯道超车"叙事,就自然站不住了。 我是亮哥。关注我,带你穿透产业迷雾,吃到硬核科技爆发的真正红利。 
深扒自动驾驶两大“死局”:小鹏特斯拉的真正对手,根本不是其他车企 你花钱买的激光雷达,其实是一堆噪音
自动驾驶真正的终局,没人说清楚过
END
觉得内容能帮你,点赞 + 推荐,关注我,做有底气的产业赢家。
往期推荐:
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 白色轿车突然变道
- 掘金自动驾驶,不要把大坑当机会
- 畅行无忧,油我补贴!传祺 SUV 家族团购专场,福利炸裂来袭!
- 跑再次掀桌!21.98万,D19把高端SUV卷成白菜价
- ICRA 2025 | 自动驾驶 & 机器人通用:基于 STL 的路径积分轨迹规划新方法
- 11万块买四驱混动轿车,油耗比油车还低,安全配置却像坦克.
- 22.99万,大众800V纯电SUV,正式上市
- 自主燃油SUV没好车?盘点一季度市场最热的五款自主SUV车型
- 11万就能买到的国产纯电SUV!续航610公里后排还能跷二郎腿,这还让燃油车怎么活?
- 会车纠纷升级,四川阆中摩托车主打砸轿车被刑拘,警方:因其不满小驶入该路段
