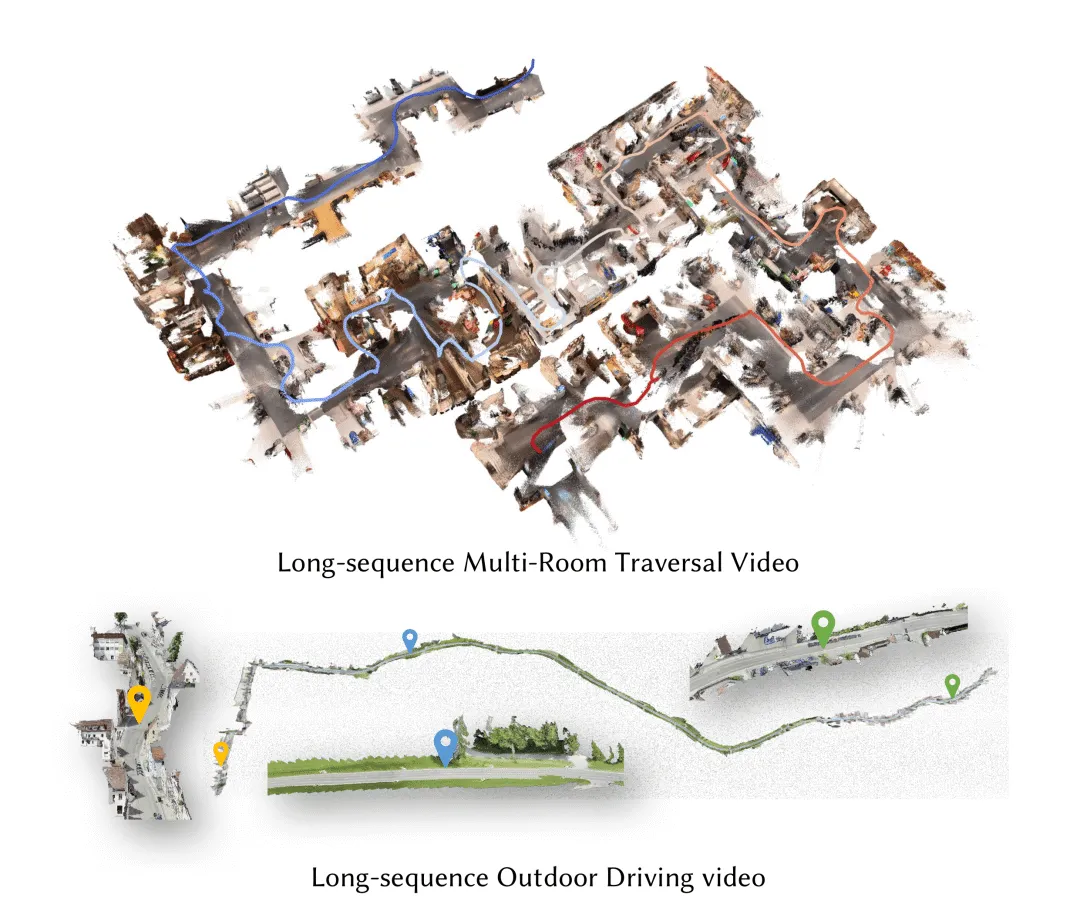
哈喽大家好~今天聊一个超硬核、但又特别贴近落地的技术:流式 3D 重建。
过去做 3D 重建,大家基本都在走 “先拍完、再集中算” 的离线路子。精度看着还行,但问题一大堆:等得久、占显存、序列一长就飘、没法实时用。机器人边走边建图、AR 眼镜即时叠空间、自动驾驶实时感知,这些场景根本等不起 “事后诸葛亮”。
最近开源的 LingBot‑Map,直接把这套逻辑推翻了。
它不是另一款堆精度的模型,而是一套专门为流式而生的前向 3D 基础模型,一句话总结:来一帧算一帧、边看边建、越长越稳、还不爆显存。
它到底解决了什么痛?
业内做流式 3D 重建,一直被三座大山压着:
LingBot‑Map 用一套几何上下文 Transformer,把这三个问题一起收拾了。
核心思路很聪明:把 SLAM 里那套 “锚点定坐标系、局部窗口保精度、轨迹记忆防漂移” 的逻辑,直接塞进 Transformer 里,让模型自己学会管理空间记忆,不用人写一堆复杂几何约束。
简单拆解它的三板斧:
- 锚点上下文
- 位姿参考窗口
- 轨迹记忆
再配上分页 KV 缓存注意力,显存开销几乎恒定,长序列也不崩。
效果有多顶?
- 518×378 分辨率,单卡稳定跑到 **≈20FPS**,满足实时需求
- 多个权威基准上,吊打传统流式方法,甚至优于不少离线方案
它不只是实验室玩具,是真能往机器人、AR/VR、自动驾驶、数字孪生里塞的工程级方案。
为什么这个事很重要?
以前 3D 重建更偏向 “做资产”,现在 LingBot‑Map 把它变成了 “实时感知能力”。机器不用再等你拍完、传完、算完,而是边走、边看、边建、边用,和人理解世界的方式越来越像。
这才是具身智能、空间智能真正需要的底层能力。
最后说两句
LingBot‑Map 最厉害的地方,不是堆参数、堆精度,而是把 “不可能三角” 变成了可能:
对做 3D 视觉、机器人、AR/VR 的朋友来说,这绝对是今年必须盯上的开源项目。
感兴趣的可以去 GitHub 看论文和演示,体验一下 “边拍边建 3D 世界” 到底有多爽。