多模态理解与强化学习:自动驾驶闭环规划,生成器-判别器框架;视觉RAG,分层动作空间密集奖励;视觉切换知识蒸馏,模型压缩
RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
2026-04-16|HUST, Horizon Robotics|🔺26
http://arxiv.org/abs/2604.15308v1https://huggingface.co/papers/2604.15308https://hgao-cv.github.io/RAD-2
研究背景与意义
在自动驾驶的演进过程中,运动规划(Motion Planning)始终是核心挑战。传统方法如模仿学习(IL)虽能学习人类驾驶的表面特征,却因缺乏“负反馈”机制而难以处理长尾分布中的危险场景,且容易陷入因果混淆。近年来,基于扩散模型(Diffusion Model)的规划器因其强大的多模态建模能力脱颖而出,但其高维连续的动作空间与强化学习(RL)中稀疏的标量奖励之间存在巨大的“表征鸿沟”,导致优化过程极度不稳定。
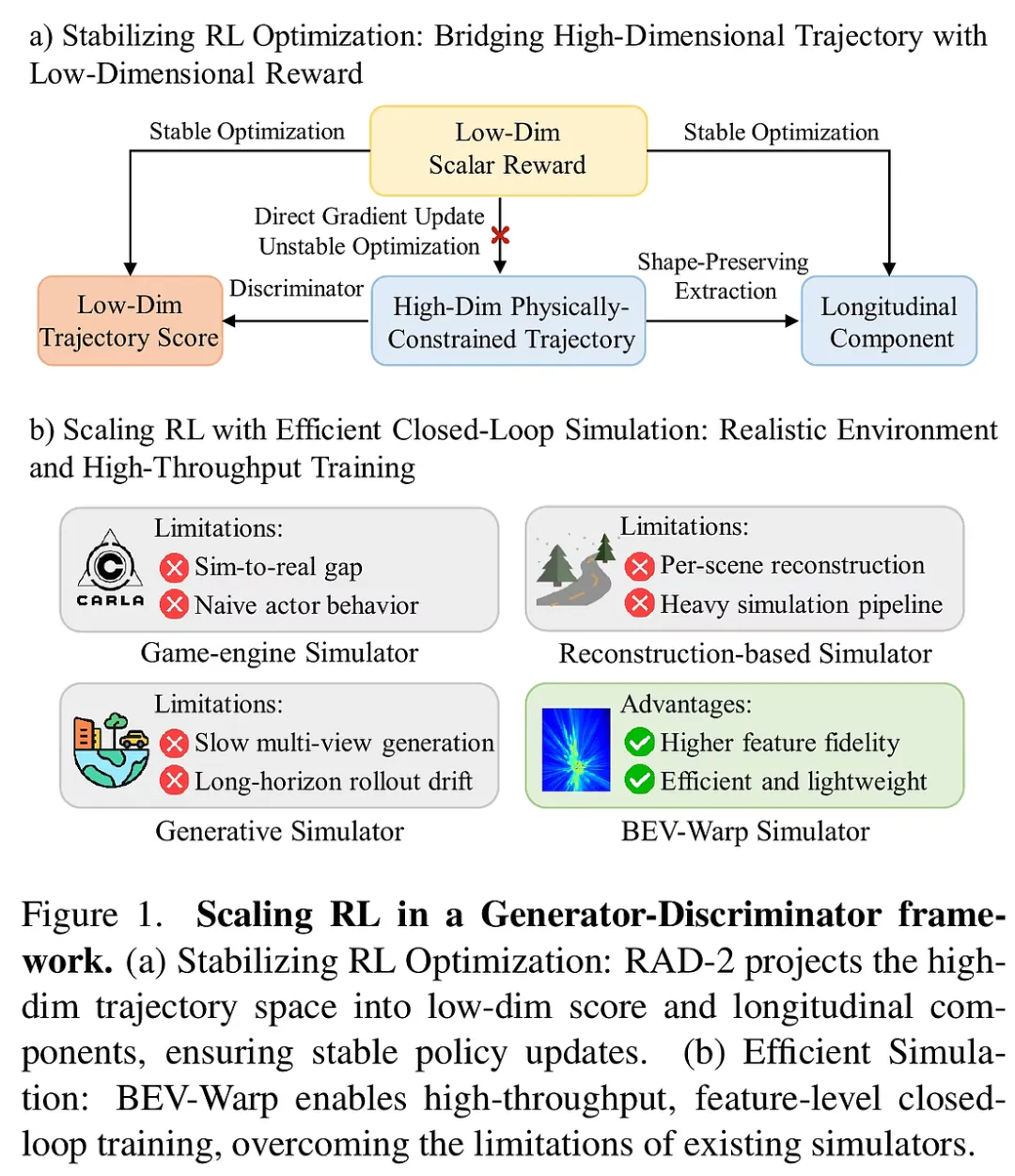
RAD-2 的提出,正是为了攻克“如何在复杂闭环环境中稳定扩展强化学习”这一难题。其核心意义在于,它打破了直接对高维轨迹进行强化学习优化的固有思维,转而采用一种“解耦再协同”的架构。通过引入高效的 BEV-Warp 仿真环境和创新的策略优化算法,RAD-2 不仅显著提升了自动驾驶在复杂城区环境中的安全性(碰撞率降低 56%),更通过生成器与判别器的协同进化,为自动驾驶系统从“模仿专家”向“超越专家”的跨越提供了理论支撑与工程范式。这标志着强化学习在处理高维、连续、强交互的具身智能任务上迈出了坚实的一步。
研究方法与创新
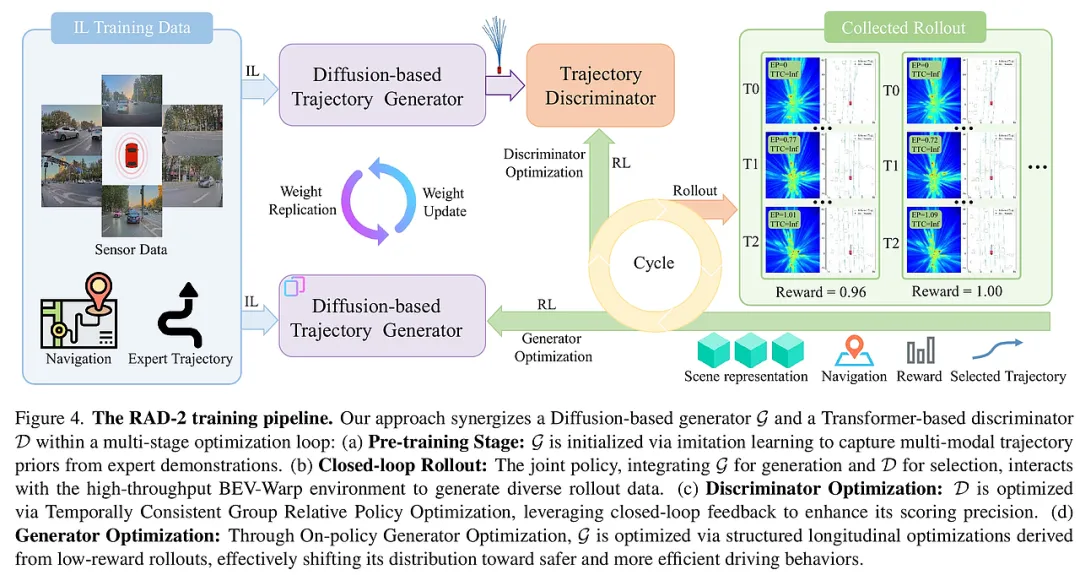
RAD-2 的核心贡献在于构建了一个高度协同的“生成器-判别器”框架,并通过三项关键创新解决了强化学习在运动规划中的不稳定性、信用分配难以及仿真效率低的问题。
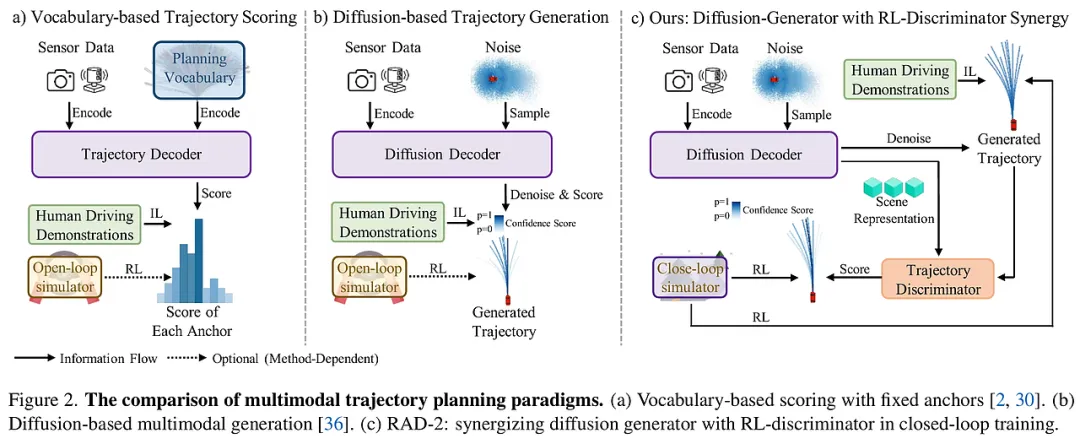
1. 生成器-判别器解耦架构:将高维优化降维打击 RAD-2 并没有尝试直接用强化学习去微调扩散模型生成的高维轨迹,因为在数千维的轨迹空间中,稀疏的标量奖励(如“是否碰撞”)就像大海捞针,难以给出明确的梯度指引。
- 扩散生成器(Generator): 负责“发散思维”,基于当前场景特征(BEV 特征、地图、动态障碍物)产生一组多样化的候选轨迹。它保留了模仿学习对人类驾驶先验的理解。
- RL 判别器(Discriminator): 负责“精准决策”。判别器接收生成器的候选集,通过 Transformer 架构对轨迹与场景进行深度融合建模,输出每个轨迹的评分。 这种设计的精妙之处在于,强化学习的优化目标被限制在判别器的标量输出空间内,这与 RL 的标量奖励天然对齐,极大地降低了优化的数学难度,确保了策略更新的平稳性。
2. TC-GRPO:解决时空维度的信用分配难题 在自动驾驶的闭环交互中,一个关键的痛点是“信用分配”(Credit Assignment):如果车辆在 10 秒后发生碰撞,究竟是哪一秒的决策出了问题?
- 时空一致性采样(Temporally Consistent Sampling): RAD-2 引入了“轨迹重用”机制。在仿真过程中,一旦选定某条轨迹,系统会在固定步长内坚持执行该意图,而非高频切换。这保证了车辆行为的连贯性。
- TC-GRPO 算法: 基于组相对策略优化(GRPO),RAD-2 进一步引入了时空约束。它将奖励直接关联到这一段连贯的行为意图上,通过对比同一场景下不同意图组的相对优劣来更新判别器。这种方式有效地过滤了环境噪声,使得判别器能够精准识别出哪些细微的轨迹差异会导致长期的安全风险。
3. 在线生成器优化(OGO):引导分布向“高光时刻”靠拢 判别器虽然能选出最好的,但如果生成器产生的候选集全是“烂苹果”,系统依然无法安全行驶。
- 结构化纵向优化: RAD-2 提出了一种非对称的优化路径。它不直接对生成器做 RL,而是根据闭环反馈(如碰撞风险或效率低下)对原始轨迹进行“结构化修正”。例如,如果检测到前方有风险,就通过纵向压缩(减速)生成一个优化的伪标签。
- 分布偏移: 生成器通过学习这些经过修正的、具有更高长期奖励的轨迹,逐渐将其概率分布向更安全、更高效的流形(Manifold)偏移。这种“循序渐进”的优化方式,既保持了生成器的多模态特性,又提升了其输出质量的下限。
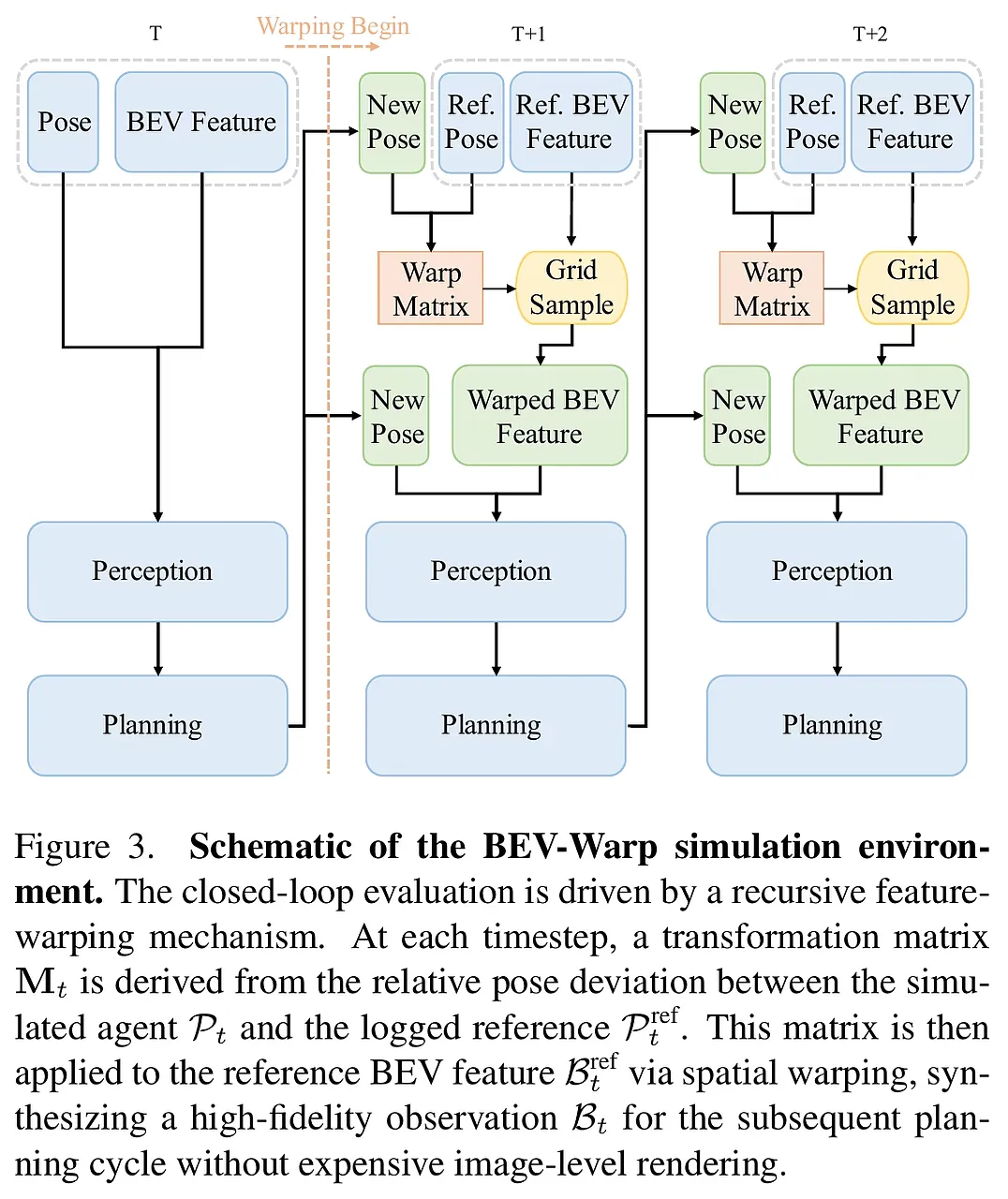
4. BEV-Warp:高吞吐量的特征级仿真环境 为了支持大规模强化学习训练,RAD-2 抛弃了沉重的图像渲染引擎。
- 空间等变性利用: 既然感知模型已经将图像转为了 BEV 特征,那么车辆的移动在特征空间中本质上是坐标变换。BEV-Warp 通过对 BEV 特征图进行空间采样(Spatial Warping),直接合成下一帧的观察特征。
- 效能飞跃: 这种方法绕过了昂贵的渲染过程,实现了极高的仿真吞吐量,使得在有限的计算资源下进行大规模闭环 RL 训练成为可能,真正实现了“数据驱动”的闭环进化。
实验设计与结果分析
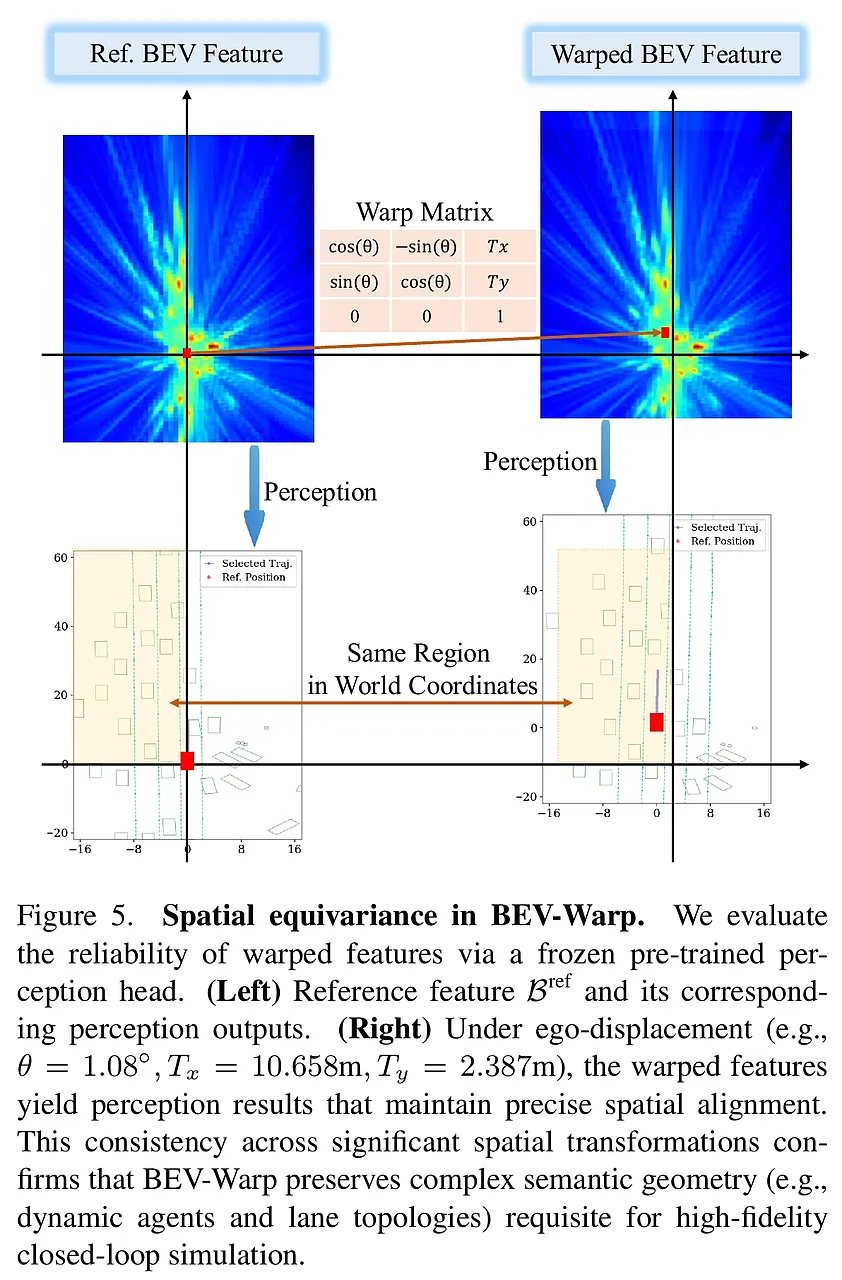
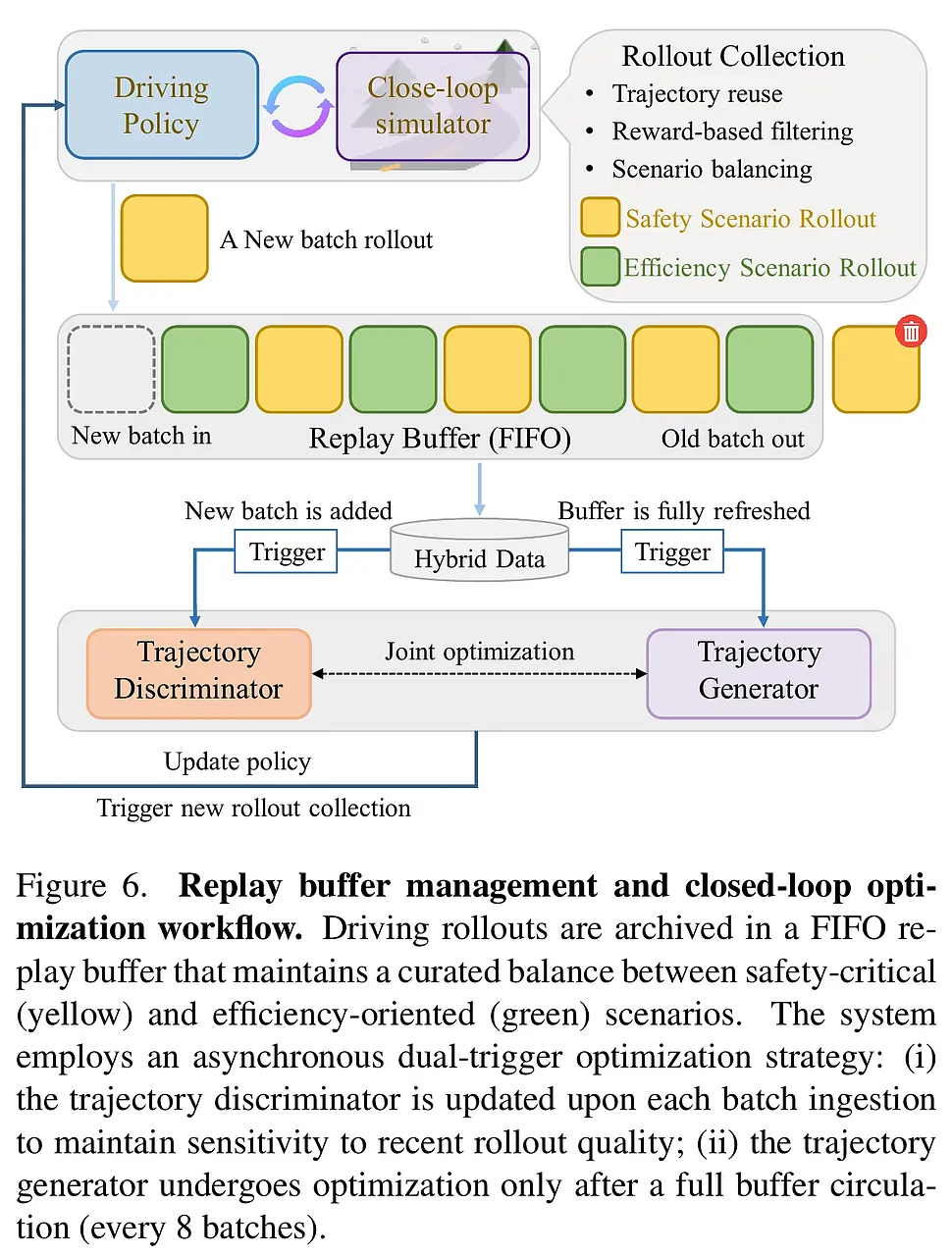
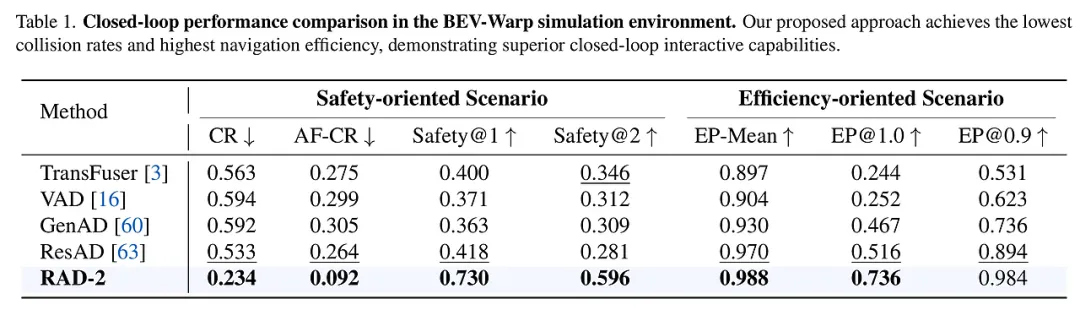
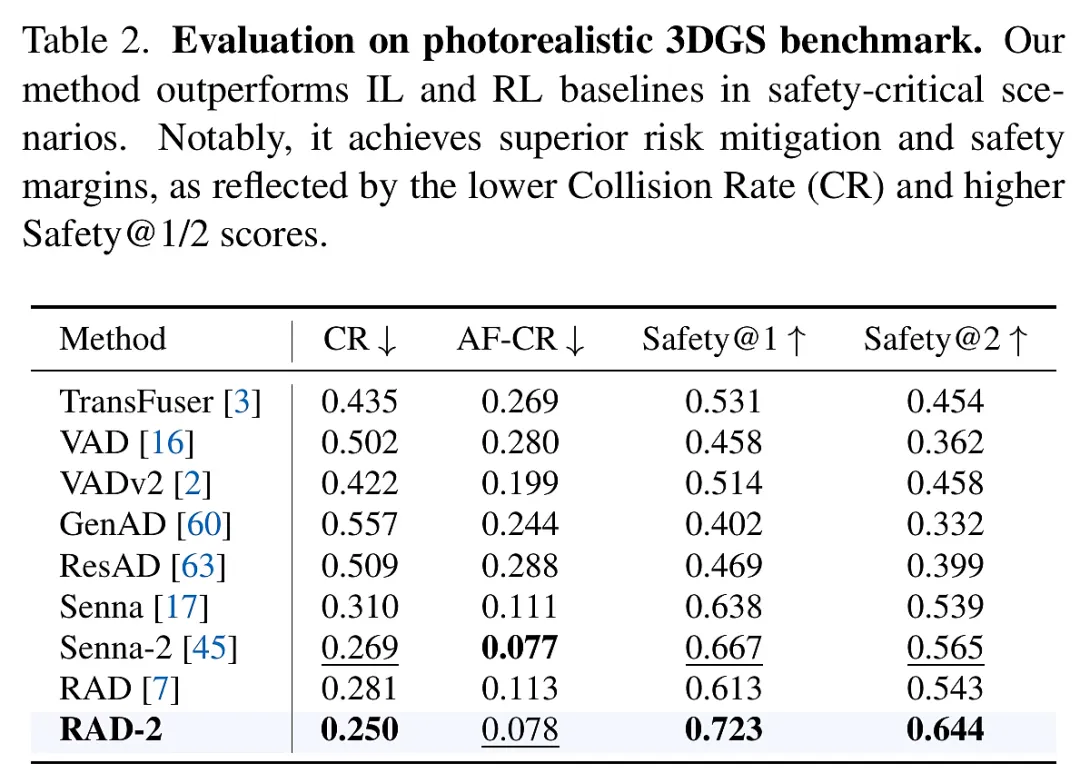
RAD-2 的验证过程严谨且多维,涵盖了从高效特征仿真到高保真光影渲染,再到真实世界部署的全链路测试。
实验设计: 研究团队采用了 50,000 小时的真实驾驶数据进行生成器的预训练,随后在 BEV-Warp 环境中利用 10,000 个精选的挑战性片段(涵盖安全风险和效率瓶颈)进行强化学习训练。为了验证泛化性,模型还在基于 3D 高斯泼溅(3DGS)的光影级仿真器中进行了闭环评估,并与 TransFuser、VAD、ResAD 等前沿规划器进行了对比。
结果分析:
- 安全性实现质的飞跃: 在安全导向的测试中,RAD-2 的碰撞率(CR)较强基线 ResAD 降低了约 56%。尤其在“责任碰撞率”(AF-CR)上表现优异,证明其判别器能有效识别并规避潜在的危险意图。
- 效率与舒适度兼顾: 导航效率指标(EP-Mean)达到 0.988,远超传统方法。这说明 RAD-2 不仅仅是“胆小”的避障,而是学会了像老司机一样在保证安全的前提下高效穿梭。
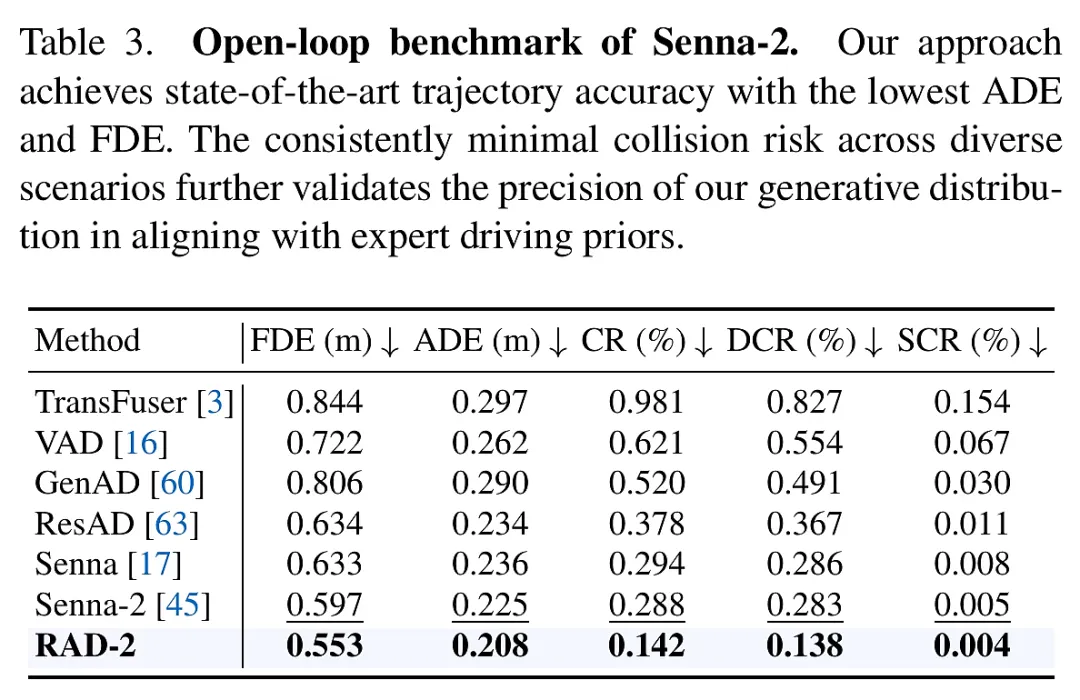
- 开环与闭环的双重领先: 在 Senna-2 等公开基准测试中,RAD-2 在轨迹预测精度(ADE/FDE)和安全性指标上均刷新了纪录。实车部署进一步证实,该系统在复杂城区交互中表现出极高的感知安全性和行驶平顺性,验证了其从仿真到现实(Sim-to-Real)的强大迁移能力。
结论与展望
总结贡献: RAD-2 成功构建了一个能够大规模扩展强化学习的自动驾驶规划框架。它通过生成器与判别器的功能解耦,巧妙解决了高维动作空间下 RL 训练不稳定的顽疾;TC-GRPO 和 OGO 算法的引入,为复杂时空序列下的信用分配提供了优雅的数学解法;而 BEV-Warp 则为学术界和工业界提供了一种低成本、高效率的闭环训练新范式。
局限性分析: 尽管表现卓越,RAD-2 目前仍存在一定的局限性。首先,其生成器的纵向优化主要依赖于启发式的规则修正(如加减速调整),对于极度复杂的横向避障逻辑(如复杂的 S 型绕行)覆盖尚不够全面。其次,系统对底层感知特征的依赖度较高,若感知端出现严重的几何畸变,特征级仿真的鲁棒性可能会受到挑战。
方法展望: 未来的研究可聚焦于将这种解耦框架进一步推向“端到端”的深度融合,探索如何让判别器的评分信号直接反哺感知端的特征学习。同时,引入更具泛化性的世界模型(World Model)来替代启发式修正,将使生成器的进化更加智能化。RAD-2 的成功预示着,未来的自动驾驶将不再仅仅是模仿人类,而是通过在虚拟世界中进行千万次的自我博弈,进化出超越人类直觉的驾驶智慧。
UniDoc-RL: Coarse-to-Fine Visual RAG with Hierarchical Actions and Dense Rewards
2026-04-16|GlintLab, Deep Glint|🔺10
http://arxiv.org/abs/2604.14967v1https://huggingface.co/papers/2604.14967https://github.com/deepglint/UniDoc-RL
研究背景与意义
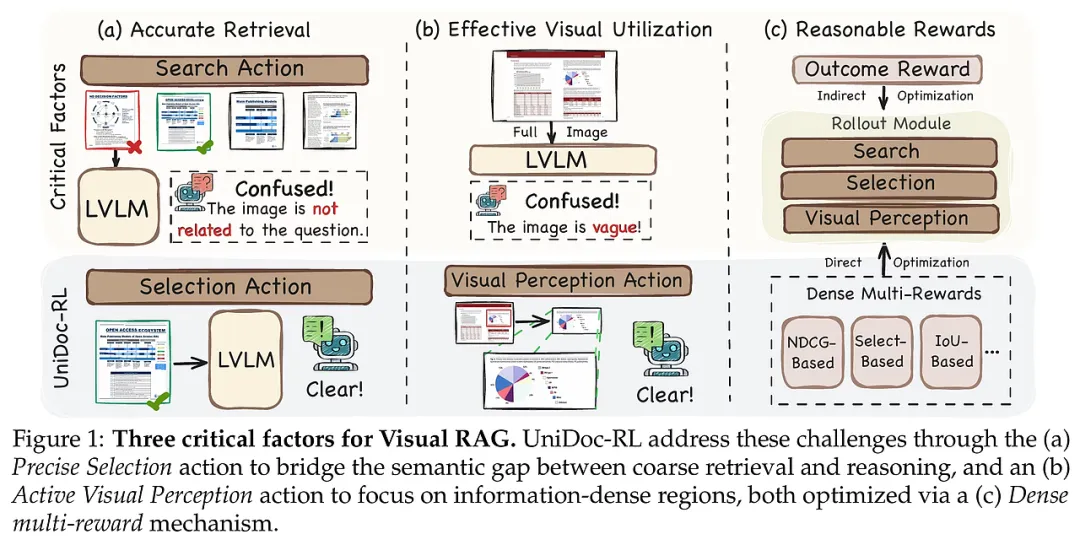
在多模态大模型(LVLM)飞速发展的今天,检索增强生成(RAG)已成为解决模型幻觉、提升知识时效性的核心技术。然而,当研究视野从纯文本转向包含图表、报告和复杂布局的“视觉文档”时,传统RAG架构显露出了明显的局限性。视觉文档具有极高的信息密度和冗余的背景噪声,现有的视觉RAG系统大多依赖通用的检索信号,这种“粗放式”的检索往往忽略了复杂推理所需的细粒度视觉语义。
目前该领域面临三大核心挑战:首先是检索精度不足,错误的检索会引入无关上下文,直接导致模型产生幻觉;其次是视觉利用率低下,模型往往被动地接收整张图像,无法像人类一样聚焦于关键局部区域;最后是优化困境,现有的强化学习(RL)方案通常仅依赖最终结果的稀疏奖励,难以对检索、裁剪等中间决策过程进行有效的信用分配(Credit Assignment)。
UniDoc-RL的提出正是为了打破这一僵局。其目标是构建一个统一的强化学习框架,将视觉信息获取建模为一个序列决策问题。通过引入“从粗到细”的层级化动作空间和密集奖励机制,该研究旨在赋予LVLM主动探索、筛选和感知视觉证据的能力。这不仅提升了文档理解的准确性,更为多模态智能体在复杂环境下的自主决策提供了新的理论范式与实践路径。
研究方法与创新
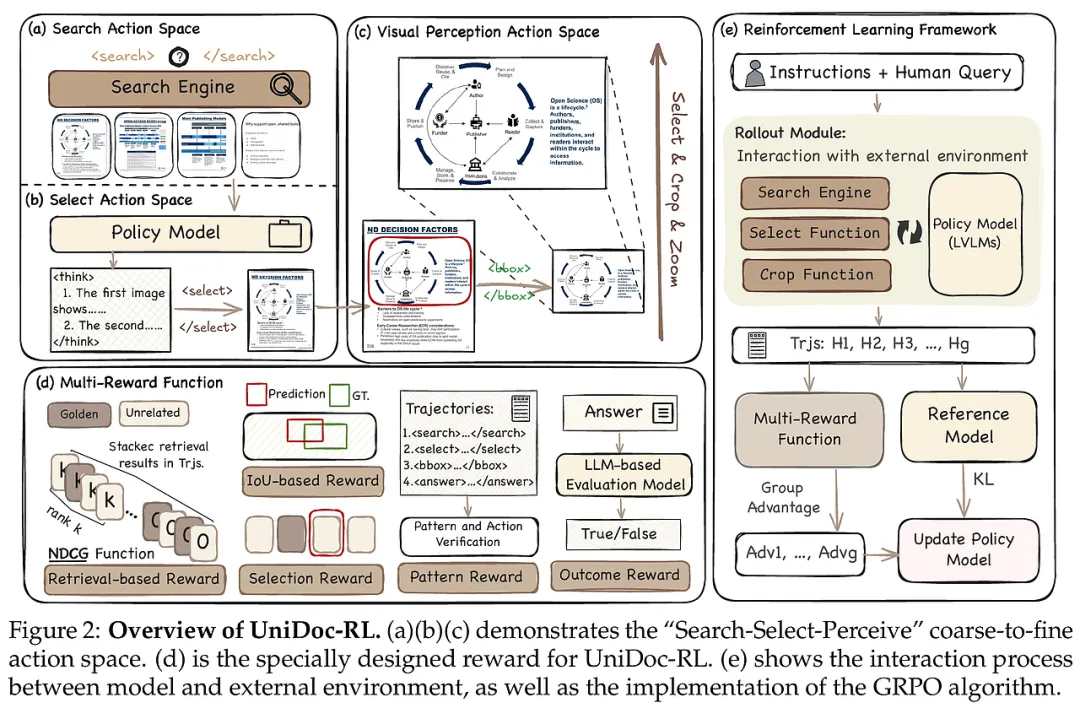
UniDoc-RL的核心创新在于其将视觉RAG流程重构为一个由强化学习驱动的智能体决策过程,通过“Search-Select-Perceive”(搜索-筛选-感知)的层级化动作空间,实现了从海量文档到关键局部像素的精准跨越。
1. 层级化动作空间的构建 UniDoc-RL摒弃了传统RAG中检索与生成脱节的模式,设计了三个维度的连续动作:
- 图像搜索(Image Search): 智能体根据初始查询生成搜索指令,调用外部工具从大规模语料库中获取初步的候选文档集。这一步解决了“大海捞针”的问题。
- 精准筛选(Precise Selection): 这是连接粗粒度检索与细粒度推理的关键桥梁。LVLM作为决策核心,会对候选图像进行语义对齐评估,剔除无关干扰项。这种基于语义的重排序机制显著降低了后续推理的计算负担和噪声干扰。
- 主动视觉感知(Visual Perception): 这是该方法最具洞察力的创新点。模拟人类视觉注意力的“缩放”机制,智能体可以生成特定区域的边界框(Bounding Box),对信息密集区域进行主动裁剪和放大。这种从全图到局部的演进,使得模型能够捕捉到微小图表或文本中的关键细节,彻底改变了以往“被动消费”全图信息的低效模式。
2. 密集多奖励机制(Dense Multi-Reward Scheme) 为了解决强化学习在长链条任务中监督信号稀疏的问题,UniDoc-RL设计了一套覆盖全流程的奖励函数,确保每一步动作都能得到即时且明确的反馈:
- 检索奖励: 采用归一化折损累计增益(NDCG)指标,量化搜索结果的质量。
- 筛选奖励: 通过伪监督策略,评估模型选出的图像是否包含真实答案所需的证据。
- 感知奖励: 基于预测裁剪区域与真实感兴趣区域(ROI)之间的交并比(IoU),引导模型学习精准定位。
- 格式与结果奖励: 确保输出符合预定义的XML规范,并最终对答案的准确性进行模型基准评估。 这种密集的反馈网络使得模型能够进行端到端的协同优化,避免了中间步骤的错误累积。
3. 训练范式与算法优化 在训练策略上,UniDoc-RL采用了群体相对策略优化(GRPO)算法。该算法的优势在于无需额外的价值网络(Value Network),通过组内相对评分来估计优势函数,极大地降低了训练资源开销。 此外,研究团队还构建了一个高质量的训练数据集。通过调用顶级模型(如Qwen3-VL)作为“教师智能体”合成推理轨迹,并结合专业文档解析工具(如Mineru)生成细粒度的动作标注。这种“教师引导+自我进化”的模式,为模型在冷启动阶段打下了坚实的逻辑基础,并在随后的RL阶段实现了能力的飞跃。
4. 理论基础与优势对比 UniDoc-RL的理论根基在于将RAG视为一个主动感知过程而非静态检索过程。相比于现有的VRAG-RL等方法,UniDoc-RL的优势在于其动作的连贯性和反馈的深度。它不只是简单地增加了一个裁剪功能,而是通过强化学习将搜索、筛选、裁剪和推理四个环节耦合在一起,形成了一个能够自我修正、动态调整策略的闭环系统。这种架构使得模型在面对长文档和复杂视觉元素时,表现出极强的鲁棒性和灵活性。
实验设计与结果分析
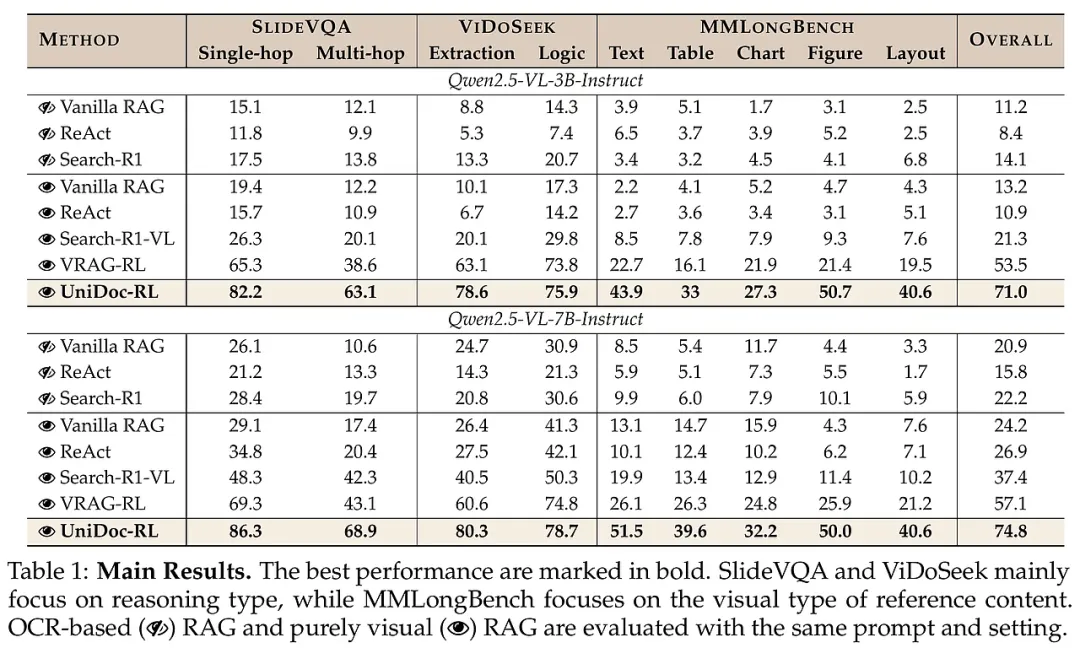
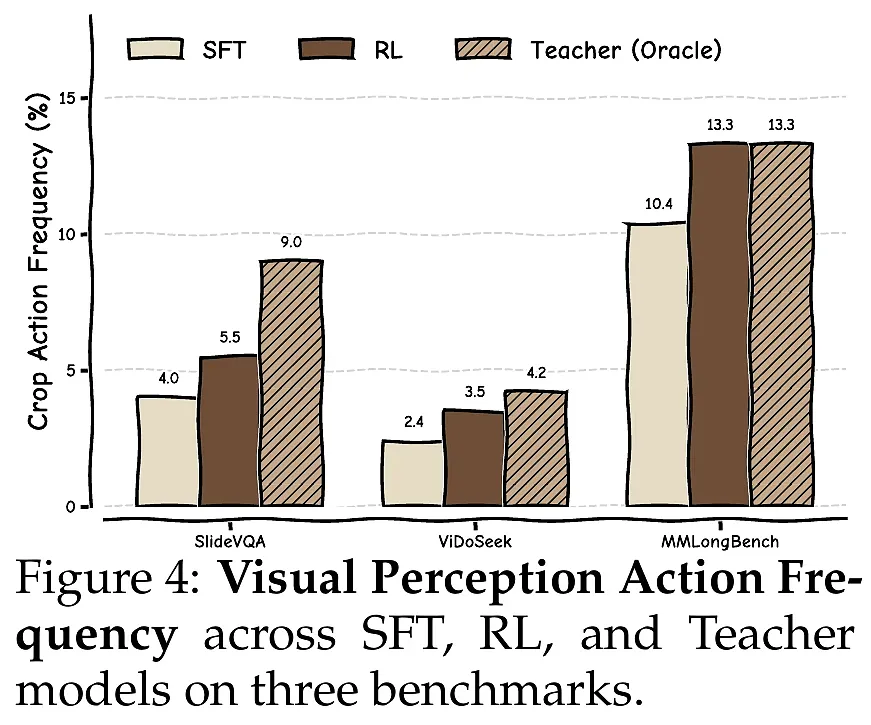


研究团队在三个具有代表性的视觉文档基准测试集上进行了严密评估:专注于多跳推理的SlideVQA和ViDoSeek,以及侧重细粒度视觉细节的MMLongBench。实验涵盖了从3B到7B不同参数规模的模型,并对比了Vanilla RAG、ReAct、Search-R1等多种前沿基线。
实验结果显示,UniDoc-RL在所有基准测试中均取得了显著的领先地位。在3B和7B模型上,它分别超越了此前最强的RL基线方法(VRAG-RL)达17.5%和17.7%。在处理复杂逻辑提取和图表分析任务时,UniDoc-RL的表现尤为突出。
深度分析表明:
- 筛选动作的价值: 消融实验证实,引入“精准筛选”步骤后,检索召回率在多个数据集上提升了5%-10%,有效弥补了外部检索工具与特定推理任务之间的语义鸿沟。
- 主动感知的进化: 相比于SFT(监督微调)阶段模型倾向于保守地查看全图,经过RL训练后的模型触发“裁剪”动作的频率大幅增加,且裁剪精度(IoU)显著提升。这证明了强化学习确实教会了模型如何高效地利用视觉工具。
- 跨场景鲁棒性: 无论是在需要多步逻辑跳转的PPT分析中,还是在需要识别微小标注的超长文档中,UniDoc-RL均展现了稳定的性能增益,证明了其密集奖励机制在不同任务目标下的普适性。
结论与展望
UniDoc-RL的研究为视觉检索增强生成领域贡献了一个极具启发性的统一框架。它成功地证明了:通过将复杂的视觉信息获取过程分解为层级化的主动决策,并辅以密集的强化学习反馈,可以显著提升大模型处理高密度视觉文档的能力。其核心贡献不仅在于算法性能的突破,更在于发布了一套高质量的细粒度动作标注轨迹数据集,为后续研究提供了宝贵的资源。
局限性分析: 尽管表现卓越,UniDoc-RL仍面临一些挑战。首先,多轮交互过程(搜索-筛选-裁剪-推理)虽然提升了精度,但也带来了更高的推理延迟和计算成本。其次,系统目前仍部分依赖外部检索工具的初始表现,若底层索引质量极差,智能体的优化空间会受到限制。
未来展望: 未来的研究方向可聚焦于进一步提升智能体的决策效率,例如探索更轻量级的动作触发机制以降低能耗。同时,将该框架扩展到更广阔的多模态环境(如实时视频流RAG或动态网页交互)也将是一个极具潜力的方向。UniDoc-RL所倡导的“主动感知”理念,无疑是通往更高级通用人工智能(AGI)的重要一步。
Switch-KD: Visual-Switch Knowledge Distillation for Vision-Language Models
2026-04-16|Li Auto Inc.|🔺8
http://arxiv.org/abs/2604.14629v1https://huggingface.co/papers/2604.14629https://github.com/haoyi199815/Switch-KD
研究背景与意义
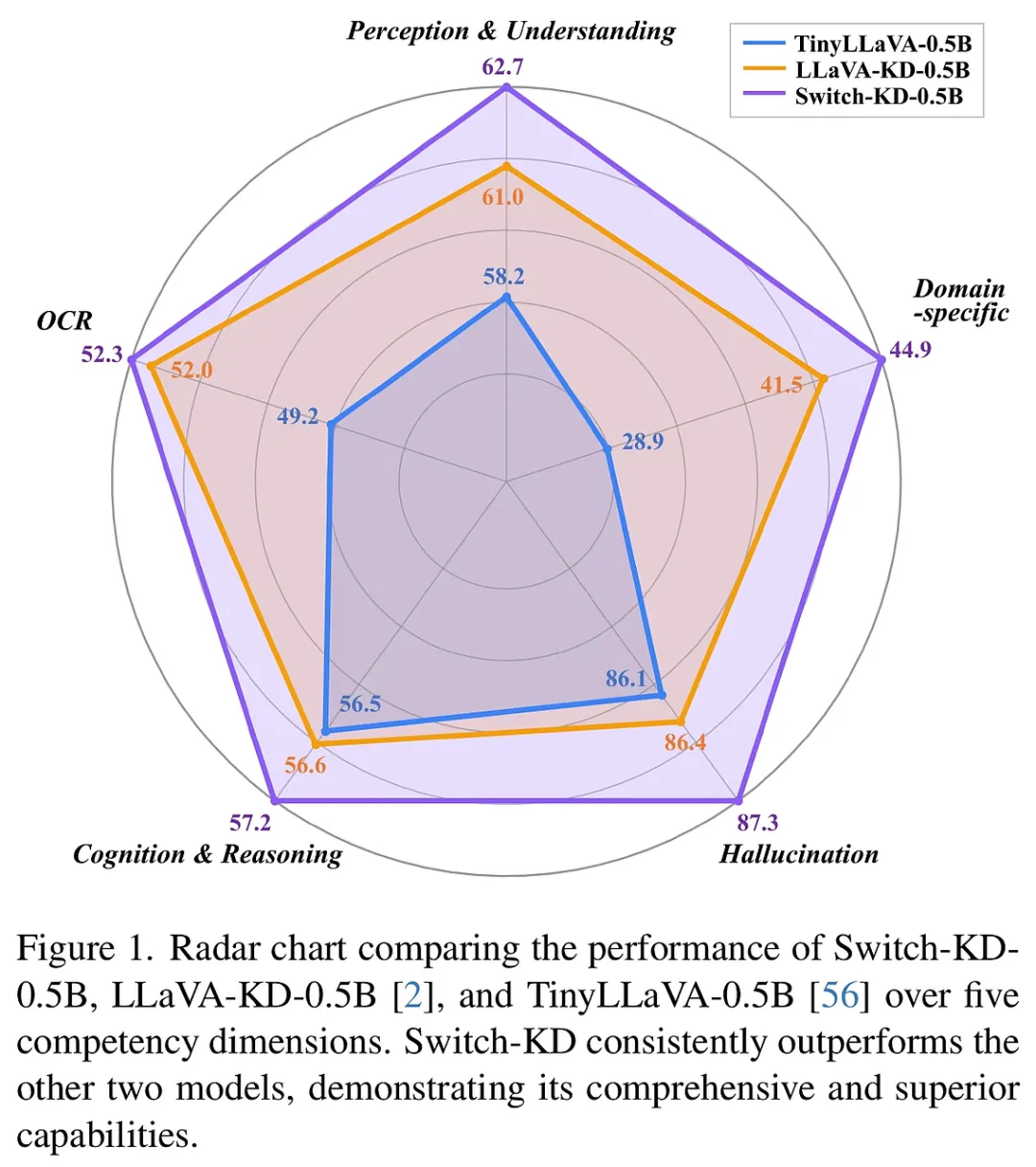
在多模态大模型(VLM)飞速发展的今天,模型性能往往遵循“规模定律”(Scaling Law),即参数量越大,理解能力越强。然而,这种性能的飞跃伴随着沉重的计算负担和内存占用,使得这些“巨兽”难以部署在手机、嵌入式设备等资源受限的场景中。知识蒸馏(KD)作为一种经典的“瘦身”技术,旨在将大模型(教师)的博学传递给小模型(学生),但在多模态领域,这一过程面临着严峻的挑战。
目前的主流方法往往将视觉和语言视为两个独立的维度进行监督,这种“割裂式”的蒸馏忽略了多模态知识在本质上是高度耦合的。虽然 VLM 的多模态知识最终在语言空间中融合,但现有技术在对齐视觉表征与语言逻辑时,缺乏一种统一的视角,导致学生模型在理解复杂视觉语义时容易出现“认知偏差”或“幻觉”。
本研究提出的 Switch-KD 框架,其核心意义在于打破了模态间的界限。它创新性地提出在统一的“文本概率空间”内进行跨模态知识迁移,通过让教师模型的“大脑”去解读学生模型的“眼睛”,实现了视觉与语言知识的深度对齐。这不仅显著提升了轻量级 VLM 的性能,也为未来高效、统一的多模态模型压缩提供了一条极具启发性的技术路径。
研究方法与创新
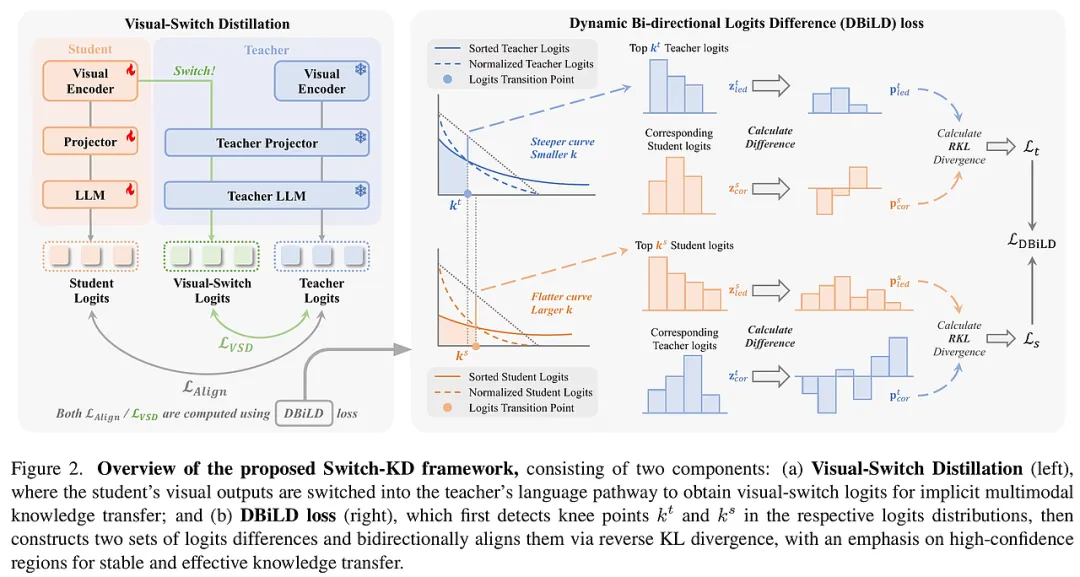
Switch-KD 的核心逻辑在于其对“统一概率空间”的深刻洞察。研究者认为,既然 VLM 的最终输出是文本概率分布,那么所有的视觉理解最终都应转化为对语言空间的贡献。基于此,该方法引入了两个支柱性的创新:视觉切换蒸馏(Visual-Switch Distillation)架构与动态双向逻辑差异(DBiLD)损失函数。
1. 视觉切换蒸馏:教师大脑与学生之眼的融合 传统的蒸馏方法通常是“并联式”的:学生学学生的,教师教教师的,最后比对两者的输出。而 Switch-KD 提出了一种大胆的“串联式”路径——视觉切换路径(Visual-Switch Pathway)。
具体而言,该框架构建了一个混合推理过程:将学生模型视觉编码器(Visual Encoder)提取的特征,直接输入到教师模型的语言解码器(Projector + LLM)中。这一设计的妙处在于它模拟了一个“假设场景”:如果让博学的教师通过学生的“眼睛”去看世界,它会得出什么样的结论?
- 隐式视觉对齐:通过最小化“教师原始输出”与“教师解读学生特征后的输出”之间的差异,迫使学生的视觉编码器去产生那些能被教师“理解”的高质量特征。
- 统一空间监督:这种方法将视觉层面的监督完全转化为了语言概率空间的对比,避免了直接在特征维度进行对齐时可能出现的模态坍塌或噪声干扰。
2. DBiLD 损失函数:动态且精准的知识捕捉 在语言模型的蒸馏中,模型输出的逻辑值(Logits)通常呈现长尾分布,即只有少数几个词的概率很高,而绝大多数词的概率微乎其微。传统的固定 Top-K 蒸馏方法往往难以适应不同样本间的分布差异。
- 动态阈值(Kneedle 算法):Switch-KD 引入了“膝点检测”技术。它不再死板地选取前 50 或前 100 个词,而是根据概率分布曲线的曲率,动态地找到信息丰富区与长尾噪声区的交界点(即“膝点”)。对于简单的样本,可能只需要关注前几个词;而对于复杂的语义,则会自动扩大关注范围。这种灵活性确保了蒸馏过程始终聚焦在“最有营养”的知识区间。
- 双向逻辑差异对齐(Bi-directional Logits Difference):研究者发现,单纯对齐概率值是不够的,词与词之间的“相对关系”(结构信息)同样重要。DBiLD 损失通过计算 Top-K 词对之间的差值,构建了一个反映知识结构的概率分布。
- 教师引导与学生自验:该损失包含两个分支。教师引导分支负责将教师的信心传递给学生;而学生引导分支则让学生针对自己最有把握的预测去向教师“求证”。这种双向的对称监督,极大地增强了蒸馏过程的稳定性。
- 逆向 KL 散度(Reverse KL):在对齐过程中,研究者选择了逆向 KL 散度而非前向 KL。这一选择体现了“寻模”的思想,即让学生模型优先模仿教师模型中概率最高的区域,从而在有限的参数容量内,优先掌握最核心、最确定的知识,减少了模型产生幻觉的风险。
3. 理论基础与优势对比 Switch-KD 的理论根基在于将多模态对齐视为一种“翻译”过程。现有的方法如 Align-KD 试图在中间层强制对齐注意力图,但这往往会限制模型的表达灵活性;而 LLaVA-KD 虽然关注了逻辑值,却未能解决视觉特征与语言逻辑的深度耦合问题。Switch-KD 通过在共享的文本概率空间内进行端到端的统一监督,不仅简化了训练流程(无需复杂的中间层匹配),更在逻辑上保证了视觉特征的“语义纯度”,使得 0.5B 规模的小模型也能展现出接近 3B 甚至更大模型的推理逻辑。
实验设计与结果分析
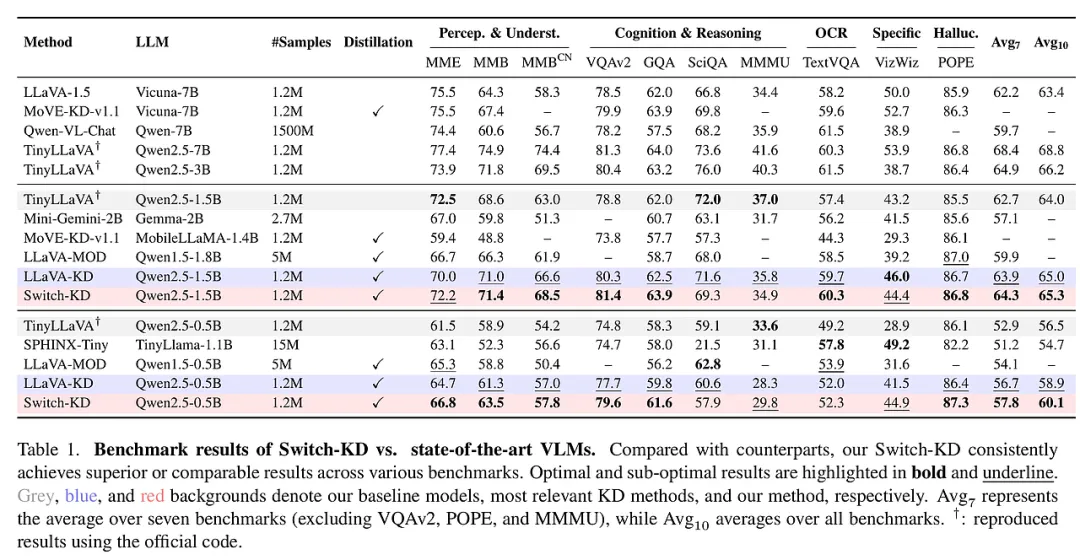
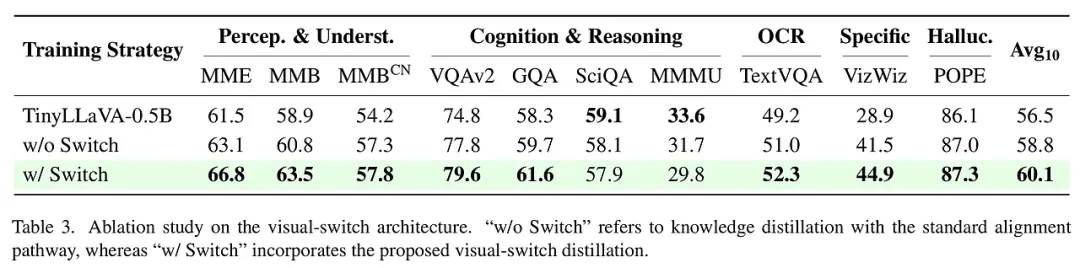
为了验证 Switch-KD 的实战效果,研究团队在 10 个主流的多模态基准测试上进行了严苛的评估,涵盖了感知理解、认知推理、OCR 文字识别、幻觉检测及特定领域应用等多个维度。
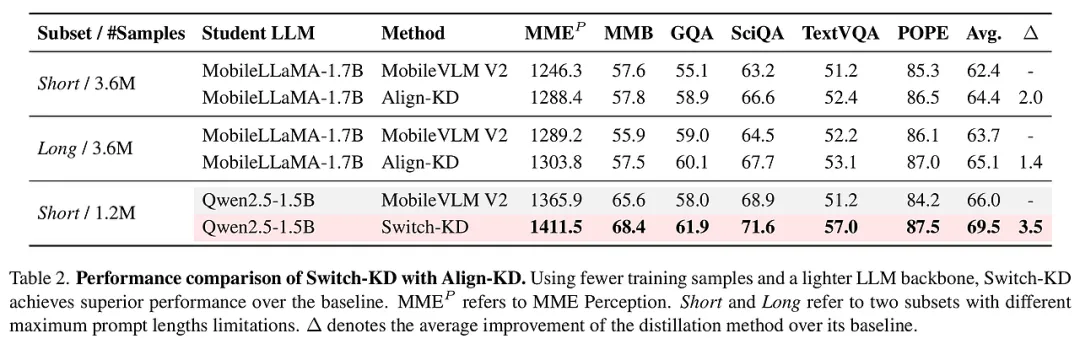
实验配置与表现: 实验采用了 SigLIP 作为视觉编码器,并以 Qwen2.5 系列作为语言底座,构建了 0.5B 和 1.5B 两个版本的学生模型。在与 TinyLLaVA、MobileVLM、LLaVA-KD 等一众强劲对手的较量中,Switch-KD 表现出了压倒性的优势。
- 性能飞跃:在 0.5B 的极小参数规模下,Switch-KD 在 10 项任务上的平均分提升了 3.6 分。尤其在需要深度视觉理解的 VizWiz 任务上,提升幅度惊人,这直接证明了“视觉切换”机制在增强视觉鲁棒性方面的卓越贡献。
- 跨架构的优越性:即便使用更少的数据(仅 1.2M 样本)和更轻量的底座,Switch-KD 依然超越了那些使用更多数据训练的竞争对手(如 Align-KD),展现了极高的蒸馏效率。
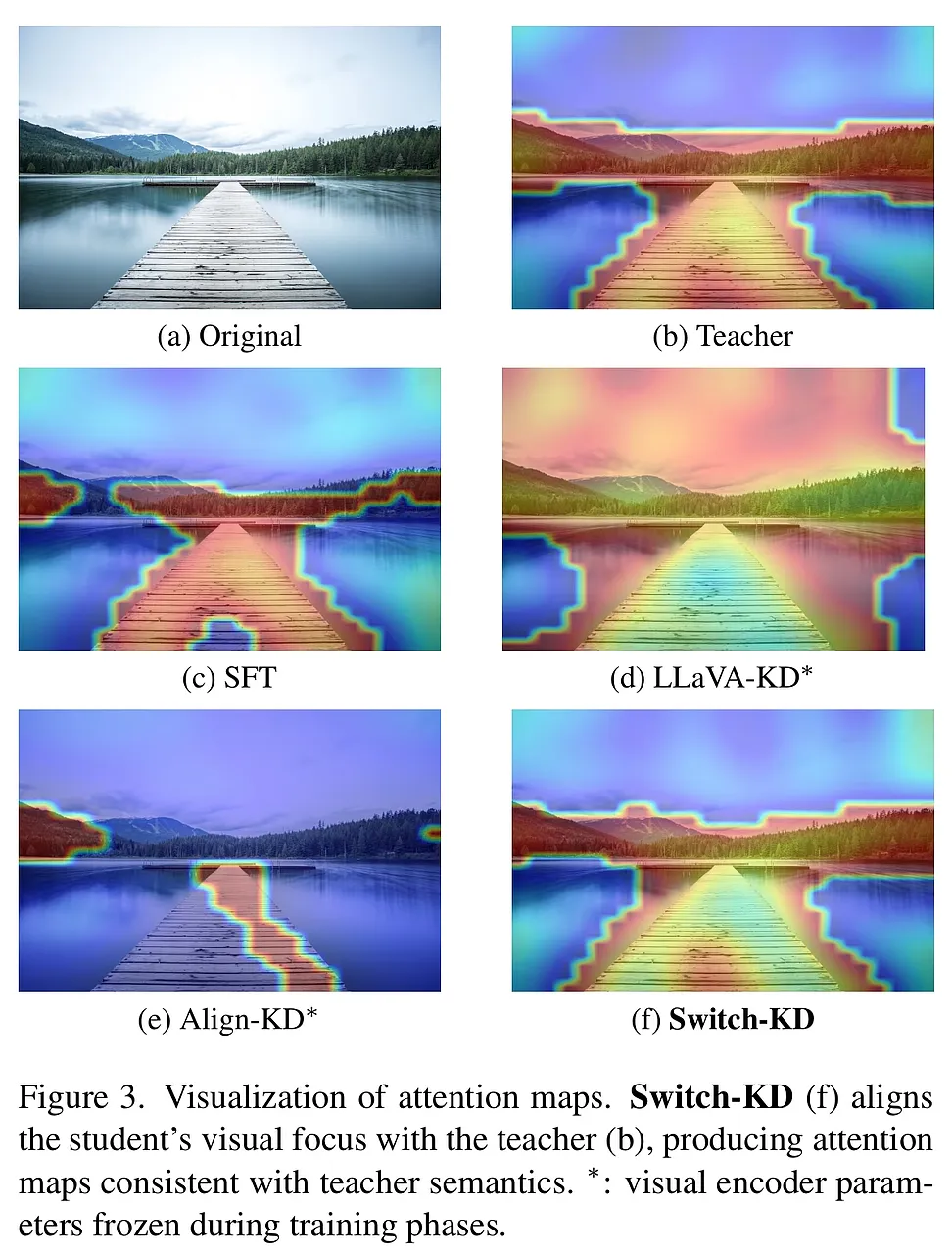
深度洞察: 通过可视化注意力图(Attention Maps),我们可以清晰地观察到:经过 Switch-KD 蒸馏的学生模型,其视觉关注点与教师模型高度一致。相比之下,传统的 SFT 或其他蒸馏方法,学生模型的注意力往往比较分散或偏离核心语义区域。这有力地佐证了 Switch-KD 确实让学生学会了像教师一样“观察”和“思考”。
结论与展望
研究贡献总结: Switch-KD 成功地为多模态大模型的轻量化开辟了新路径。它不仅提出了一个优雅的统一蒸馏框架,证明了在文本概率空间进行跨模态对齐的可行性,还通过动态双向损失函数解决了长尾分布下的蒸馏难题。该研究最核心的贡献在于:它证明了通过巧妙的架构设计,我们可以在不改变模型参数结构的前提下,通过“软知识”的传递,极大地挖掘小模型的潜能。
局限性分析: 尽管表现卓越,Switch-KD 目前仍存在一定的约束。它要求教师和学生模型在特征空间和词汇表上保持一致性,这在一定程度上限制了它在完全异构模型(如不同家族的 LLM 之间)的应用。
未来展望: 未来的研究方向可以聚焦于如何打破这种“架构依赖”。例如,引入轻量级的适配器(Adapter)来映射不同模型间的特征空间,从而实现跨家族、跨架构的通用多模态蒸馏。此外,将 Switch-KD 的思想扩展到视频理解或音频-语言等多模态领域,也将是一个充满潜力的探索方向。总而言之,Switch-KD 为实现“小而强”的边缘侧多模态智能迈出了坚实的一步。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
