当夜雨来临,自动驾驶还看得清路吗?这篇 IEEE RA-L 论文给出了一种新答案
- 2026-05-13 10:21:48

点击下方卡片关注我们,点亮星标⭐,优质好文第一时间送达^_^
Click on the card below to follow US

>>>戳我一下,加入智驾机器人学习交流群✨
最近读到一篇很有意思的论文:《DiffVecMap: A Robust Online Vectorized HD Map Construction Method With a Diffusion Model》。作者来自华南理工大学,论文发表于 IEEE Robotics and Automation Letters。这篇工作聚焦一个非常关键、但又常常被低估的问题:自动驾驶在夜晚、雨天等恶劣环境下,如何依然稳定地在线构建高精地图(HD Map)?
如果用一句话概括这篇论文的核心贡献,那就是:
作者把“扩散模型”的去噪与生成能力,从图像生成领域,带到了自动驾驶在线矢量地图构建任务里,用来增强 BEV 特征的鲁棒性。
这不是简单地“把 diffusion 套进来”这么直白,而是围绕在线地图构建的任务特性,设计出了一套兼顾精度、速度与恶劣天气鲁棒性的方法,名为 DiffVecMap。从结果来看,它确实打出了差异化优势。
论文标题: DiffVecMap: A Robust Online Vectorized HD Map Construction Method With a Diffusion Model
期刊: IEEE Robotics and Automation Letters
作者: Kai Wu, Haoyi Zhang, Mingyang Shi, Shiyi Tang

高精地图在自动驾驶系统中,不只是“地图”那么简单,它本质上承载着车辆对静态道路环境的精细理解。比如:
车道线在哪里 人行横道怎么分布 路边界如何延展 路口拓扑关系是否完整
这些信息对于定位、规划、决策都非常关键。论文在开篇就指出,传统依赖 SLAM 和人工标注的地图构建方式,存在两个明显问题:一是人工成本高,二是难以实时更新。因此,近年来大量工作开始探索:直接基于车载传感器做在线地图构建。
其中,主流方法已经逐渐从栅格化(rasterized)走向矢量化(vectorized)。因为矢量地图天然更适合表达实例级结构,例如连续的车道边界、折线型分隔线、带几何属性的道路元素等。

论文点出了现有在线矢量 HD Map 方法的一个痛点:视觉数据一旦在低光照、下雨等场景中退化,BEV 特征质量就会明显下降,进而导致地图元素误检、漏检。
这件事在自动驾驶里是很危险的。因为一旦把路边界看错、把车道线漏掉,后续规划和控制就可能出问题。
为了解决这个问题,过去大致有两类路线:
1. 多模态融合:相机 + 激光雷达
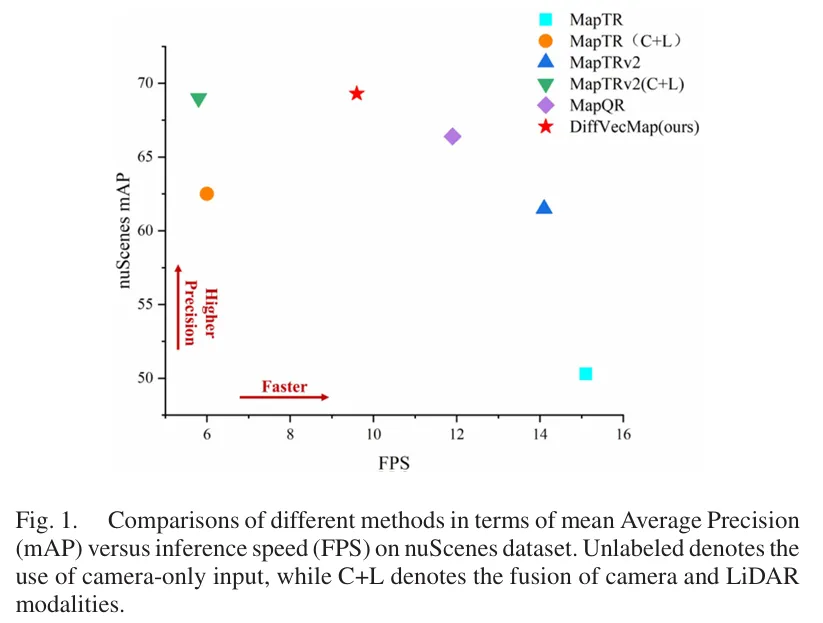
这样做确实能增强鲁棒性,但代价也很明显:推理延迟变大,实时部署更困难。 论文图 1 就展示了不同方法在 mAP 与 FPS 之间的权衡,说明多模态虽然更准,但常常更慢。
2. 加入地图先验:卫星图、SD Map 等
这类方法试图用“更干净的先验信息”来补足恶劣环境中的感知缺失,但问题在于:
先验地图和实时传感器特征难以精确对齐 GPS 一旦在高楼、树木遮挡环境下出现定位误差,方法效果会受影响
也就是说,现有思路要么“更贵更慢”,要么“依赖额外先验且容易错位”。

这篇论文最值得关注的地方,就在于它没有把扩散模型放在最终的地图元素生成端,而是把它用在了BEV 特征增强这一步。
作者的逻辑是:
夜晚、雨天等恶劣条件会污染视觉特征 扩散模型本身擅长从噪声中恢复高质量样本 那么,能不能让扩散模型来“去噪” BEV 特征,从而恢复地图构建能力?
于是,DiffVecMap 的目标非常明确:直接在 BEV 特征空间做扩散式去噪与增强,让下游地图解码器拿到更干净、更稳定的表示。
这个思路和一些将 diffusion 用在 query 级别的方法不同。论文特别强调,DiffVecMap 是直接作用于 BEV feature space,而不是只在查询层面做建模,也不依赖额外地图先验。

论文的创新并不只是“用了扩散模型”,而是围绕任务特点做了两个比较精巧的设计。
1. 时间自适应条件调制扩散块
(Time-Adaptive Conditional Modulation Diffusion Block)
这是全文最关键的模块之一。
作者先把输入的 BEV 特征做两件事:
一路按扩散过程逐步加噪,得到带噪特征 一路将 BEV 特征 + 时间信息 融合成条件输入,用来指导去噪过程
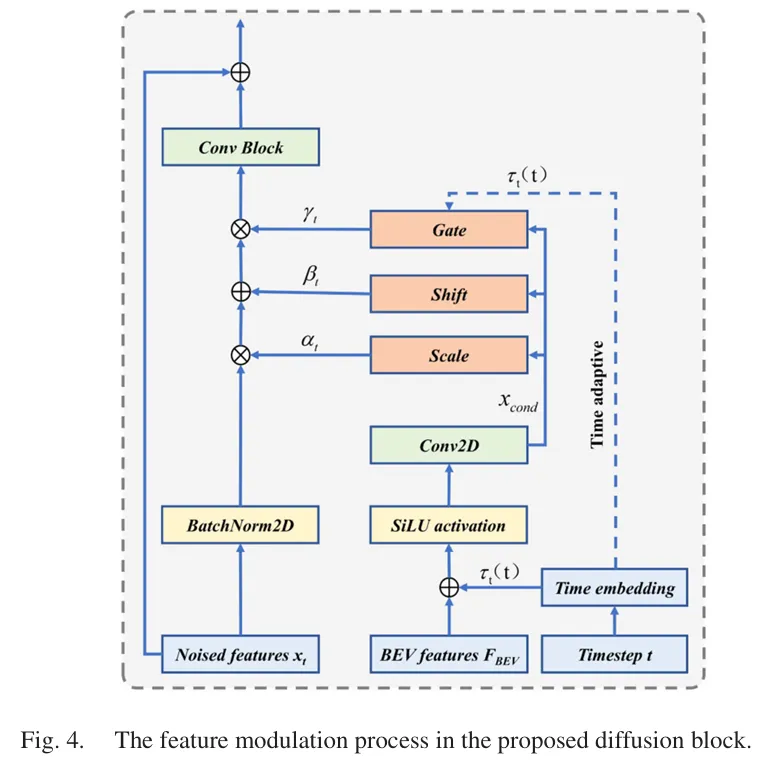
这里的关键在于,作者不是简单地把条件信息一股脑儿地注入每个扩散时间步,而是提出了一个时间自适应门控机制(time-adaptive gate)。
为什么这很重要?
因为扩散模型的去噪过程通常有明显的粗到细(coarse-to-fine)特征:
早期时间步:噪声很大,更适合先恢复全局结构 后期时间步:噪声较小,更适合修复局部细节
如果在早期就让条件分支过强地干预,反而可能破坏全局拓扑一致性;而到了后期,如果调制太弱,又难以补回细节。
所以作者引入门控参数 γt:
前期让 γt 较小,抑制过强调制,保护整体结构 后期让 γt 变大,增强修复能力,补足细节
这个设计本质上是在控制扩散去噪轨迹,让模型更符合在线地图构建任务的需求。论文图 4 对这个 feature modulation 过程做了非常直观的展示。
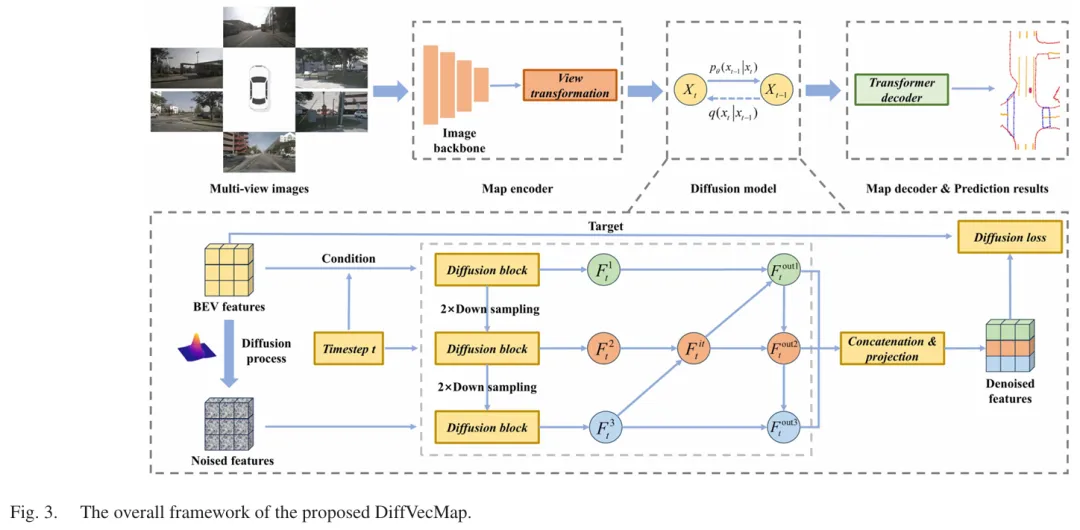
2. 轻量级分层 BiFPN 扩散架构
(BiFPN-Based Diffusion Architecture)
地图元素天然具有多尺度几何特性:
长距离车道分隔线、道路边界,更依赖低分辨率特征中的全局上下文 人行横道等局部几何,更依赖高分辨率特征中的细节纹理
因此,DiffVecMap 没有用一个单尺度扩散结构草草了事,而是用了一套轻量级层次化 BiFPN 来连接多个 diffusion block。
BiFPN 的好处主要有两个:
双向特征融合:既有 top-down,也有 bottom-up 自适应权重学习:模型自己学习不同尺度特征该怎么配比融合
这样既能保留全局拓扑,也能提升局部几何精度,同时避免复杂多尺度网络带来的大量冗余计算。论文图 3 展示了整体框架。

论文在训练与推理策略上也体现出很强的工程意识。
训练阶段
传统扩散模型通常预测噪声,但这篇工作做了一个很务实的改动:直接预测原始输入的 BEV 特征,并将其作为 diffusion loss。同时,还保留了基础地图构建损失,与 diffusion loss 联合训练。
推理阶段
为了控制速度,作者没有使用代价高昂的完整扩散采样,而是采用了 DDIM,并且只用 8 个采样步 来完成推理。这说明作者从一开始就没有把这个方法做成“实验室里很准但上不了车”的方案,而是在认真考虑在线部署条件。

这部分是整篇论文最有说服力的地方。
1. 在 nuScenes 和 Argoverse2 上都取得了强结果
论文在 nuScenes 和 Argoverse2 两个公开数据集上做了验证。在 nuScenes 原始验证集上,DiffVecMap 达到 69.4 mAP;在 Argoverse2 验证集上,达到 70.4 mAP。
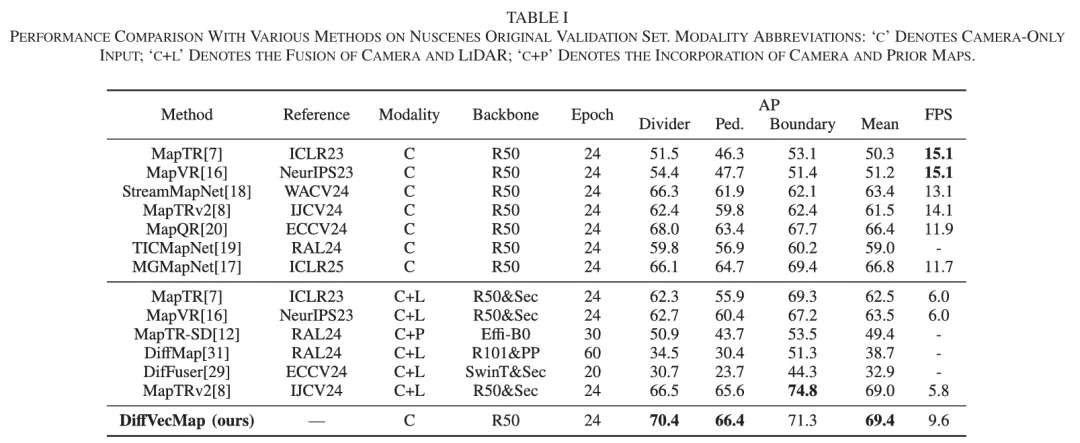
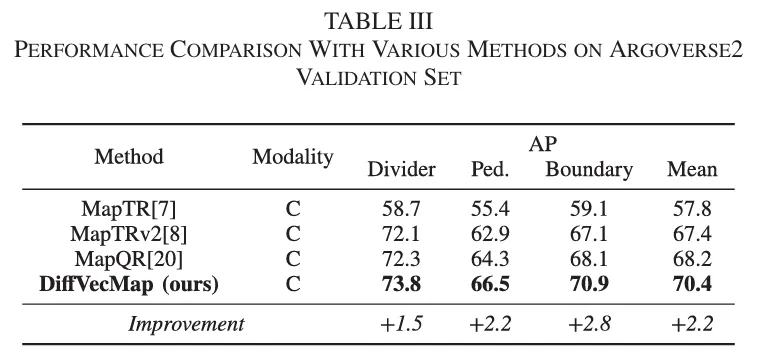
更关键的是,相比基线 MapQR,它在 nuScenes 上提升了 3.0 mAP,在 Argoverse2 上提升了 2.2 mAP。这意味着,它并不是只在某个特定数据集“碰巧有效”。
2. 夜晚、雨天场景下,优势更明显
作者专门把 nuScenes 验证集拆分出:
night split rainy split
这是这篇论文最亮眼的实验设置之一,因为它精准对应了方法所宣称要解决的问题。
结果非常直观:
在 夜间场景,DiffVecMap 比 MapTRv2 高 3.7 mAP 在 雨天场景,比基线 MapQR 高 5.2 mAP
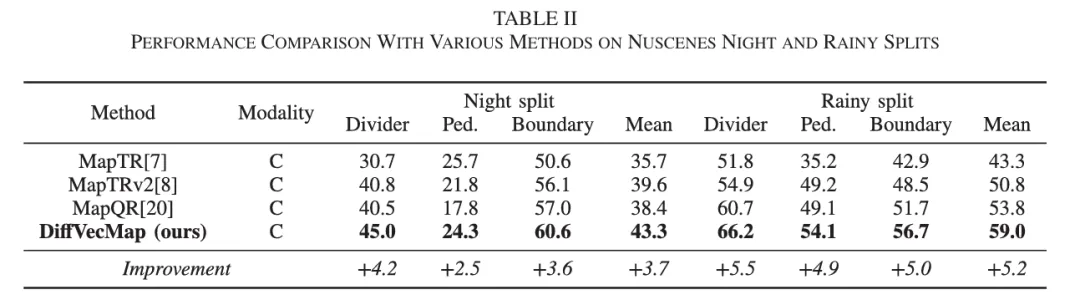
而且这个提升不是只体现在某一个类别上,论文表 II 显示,在 divider、pedestrian crossing、boundary 等不同地图元素类别上都有一致改进。
这很说明问题:DiffVecMap 不是单纯提高了平均精度,而是真正提升了恶劣环境下的鲁棒性。
3. 速度也没有“塌掉”
很多方法一旦引入 diffusion,直觉上就会担心“是不是太慢了”。
这篇工作给出的答案是:慢了一点,但仍在可接受范围,而且换来了可观的鲁棒性收益。
论文报告其推理速度为:
RTX 3090:9.6 FPS Jetson AGX Orin:2.1 FPS
作者还分解了 3090 上的耗时:
特征提取:52.6 ms 8-step diffusion:31.3 ms 解码:20.1 ms
与多模态 MapTRv2 相比,DiffVecMap 反而还快一些;相比更简单的纯视觉基线虽然慢,但带来了超过 19 mAP 的显著提升。

这说明它在“精度—效率”之间,确实找到了一个比较有竞争力的位置。

论文图 5 给出了不同场景下的可视化对比,包括常规、夜间、雨天等情况。

从图中可以看到,相比 MapTRv2 和 MapQR,DiffVecMap:
对道路几何形状的建模更完整 漏检、误检现象更少 在夜间和雨天中,与 GT 的一致性更高
这类可视化很重要,因为自动驾驶地图构建不是只看一个分数,更要看几何结构是否真的“画对了”。从论文展示来看,DiffVecMap 在结构完整性和细节恢复上都做得更稳。

一篇方法论文值不值得看,往往要看消融实验。
这篇论文的消融做得比较扎实,至少说明两个结论:
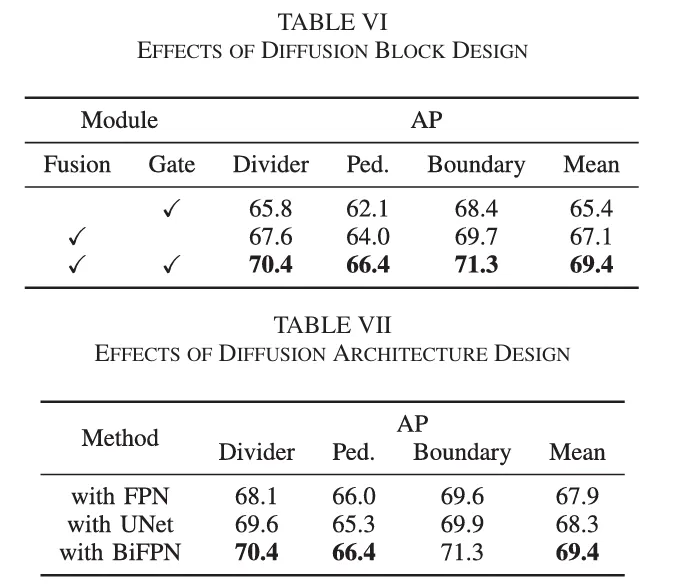
1. 条件特征真的重要
如果只用时间信息引导去噪,不使用融合后的条件特征,性能会下降 4.0 mAP。说明 BEV 特征本身对去噪过程的指导是关键的。
2. 时间自适应 gate 不是摆设
如果去掉 gate 机制,性能会下降 2.3 mAP。说明“按时间步动态控制调制强度”确实有效。
3. BiFPN 也不是随便换的
当作者把 BiFPN 换成普通 FPN-like 或 U-Net-like 架构后,mAP 分别下降 1.5 和 1.1。说明它在多尺度特征融合上的设计是有实际贡献的。
4. 对不同 decoder 也有泛化性
即使把默认的 MapQR 风格 decoder 换成 MapTRv2 的 decoder,DiffVecMap 依然能带来明显提升。这说明作者提出的增强机制不依赖单一解码头,而是对上游 BEV 表征质量有普遍帮助。

在我看来,DiffVecMap 最值得肯定的,并不只是它拿到了更高的 mAP,而是它代表了一种更实用的思路:
1. 不再执着于“加更多传感器”
很多鲁棒性问题,过去第一反应是“上 LiDAR”“做多模态融合”。但 DiffVecMap 展示了一种更节制的路线:
先把已有视觉 BEV 表征修复好,再谈下游建图。
这对于成本敏感、算力敏感的自动驾驶系统,其实很有现实意义。
2. diffusion 不一定只用于生成图像
这篇论文把 diffusion 放在 BEV 特征增强而非最终输出建模上,体现了一种更贴近任务本质的思考。它不是为了“蹭 diffusion 热点”,而是把 diffusion 的“去噪恢复”能力,真正用于解决感知退化问题。
3. “在线地图构建”正在进入更强调鲁棒性的阶段
过去大家更多比拼的是常规天气、白天环境下的精度。而这篇论文表明,夜晚、雨天等长尾场景已经成为下一阶段的重要竞争点。谁能在这些场景下保持地图结构稳定,谁才更接近真实自动驾驶落地需求。

虽然论文结果很亮眼,但从研究视角看,仍有几个值得后续继续关注的问题:
1. 扩散带来的推理开销仍然存在
即便作者已经把采样步数压到 8 步,diffusion 仍然是一块不小的开销。在更严格实时要求的平台上,是否还能进一步压缩,是后续工程化的关键。
2. 当前主要面向静态地图元素
这篇工作聚焦 lane divider、pedestrian crossing、road boundary 等静态元素。后续如果要进一步扩展到更复杂的道路结构或与动态交通要素联合建模,还需要更多验证。
3. 鲁棒性验证仍集中于公开数据集划分
论文已经做了针对夜间、雨天的专门切分,这是优点;但如果进入更复杂真实道路环境,比如强反光、积水遮挡、施工改道等场景,方法稳定性还值得继续检验。

总的来看,DiffVecMap 给我的感觉是:不是那种只为了堆复杂模块而复杂的论文,而是一篇问题意识很明确、系统设计很扎实的工作。
它抓住了自动驾驶在线地图构建里的一个真实难点——恶劣环境下视觉特征退化;然后用扩散模型做特征级去噪增强,再配合时间自适应调制和轻量级 BiFPN,最终把效果落到了实打实的实验结果上。
如果你关注这些方向:
自动驾驶感知与建图 BEV 表征学习 diffusion 在感知任务中的应用 恶劣环境鲁棒性提升
那么这篇论文非常值得一读。


智驾 & 机器人学习交流圈

学
起
来



收藏

点赞

在看

收藏

点赞

在看
(1)自动驾驶可指导方向:CUDA编程,高性能计算HPC,CV/感知算法,端到端自动驾驶,决策规划,显著性分析,图像分割,LLM,自动驾驶,雷达感知,自动驾驶感知,毫米波雷达,深度学习,滤波算法,预期功能安全,自动驾驶基础共性技术研究,自动驾驶模拟仿真技术研究,自动驾驶安全性设计及验证,仿真与测试,场景生成,强化学习,预期功能安全,自动驾驶点云处理,行为识别,目标检测,视觉感知,BEV感知,边缘计算,数据处理,驾驶行为研究,点云,多模态,自动驾驶决策规划,英伟达平台模型部署优化,自动驾驶安全方向等。
(2)机器人可指导方向:机器人路径规划及算法,AI 集中在ROS机器人和CV NLP,计算机视觉,机器学习,机器人,三维视觉, 图像融合 ,图像理解 ,机器人算法,SLAM,点云处理,信号处理,具身智能,智能控制,机器人柔顺控制,分数阶控制,自适应反步,产业机器人,电力检测机器人,海洋机器人,进化计算,移动机器人定位导航,位姿估计,轮式机器人,仿生足式机器人,机器人感知,语义分割,深度学习,机器视觉,工业机器人,移动机器人,机器人模仿学习,控制算法设计,多模态智能等。
我们专注自动驾驶和机器人等前沿领域,提供选题创新性评估、实验设计、论文写作与顶级会议/期刊投稿指导。团队源自全球顶尖实验室及企业研究院,强化创新点与工程实现,不仅保证论文产出,更传授科研思维与方法,助你掌握独立发表高水平论文的能力。提供专利挖掘、技术交底书撰写、国内外专利申请(发明专利/实用新型)全流程服务。结合产业需求,强化权利要求的保护范围与商业价值,助力成果转化与竞争力提升。




随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 自动驾驶不是'代驾':一个动作,让你从司机变罪人
- 30万级六座SUV天花板说的就是ID.ERA 9X吧
- 15万级四驱中型SUV,配置拉满,哈弗大狗PLUS能买吗?
- 零跑D19深度体验:30万级大型SUV,把舒适与实用拉满
- 4.24汽车早讯|岚图汽车大型 SUV“泰山 X8”开启预售,30.29 万元起,东风本田思域中国 20 年限定版车型上市,11.39 万元...
- 40 万预算买大六座 SUV,最怕发布会吹满实配却货不对版
- 劝你别乱加钱上四驱!家用SUV真正该选的,其实是它
- 极氪8X新品上市,国内SUV市场会不会重塑?
- 自动驾驶核心投资标的——地平线机器人的——的关键问题思考
- 宋Pro DM-i飞驰版A级插混SUV 9.99万起!301km纯电+云辇-C+可选激光雷达
