2026年以来,VLA×智能车正在成为自动驾驶研究里最值得关注的一条新主线。一个明显变化是,研究目标已不再只是让模型看清道路、输出轨迹,而是进一步要求系统能够理解语言指令、推演未来结果、适应不同驾驶偏好,并在闭环场景中稳定执行。本文选取了四篇CVPR 2026代表性工作,对VLA这一新兴范式进行了系统性探索,反映出视觉模型行动化发展的核心技术脉络。此外,我们整理了20+篇 CVPR 2026 录取的相关方向前沿论文,可供大家学习参考。
1. NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning
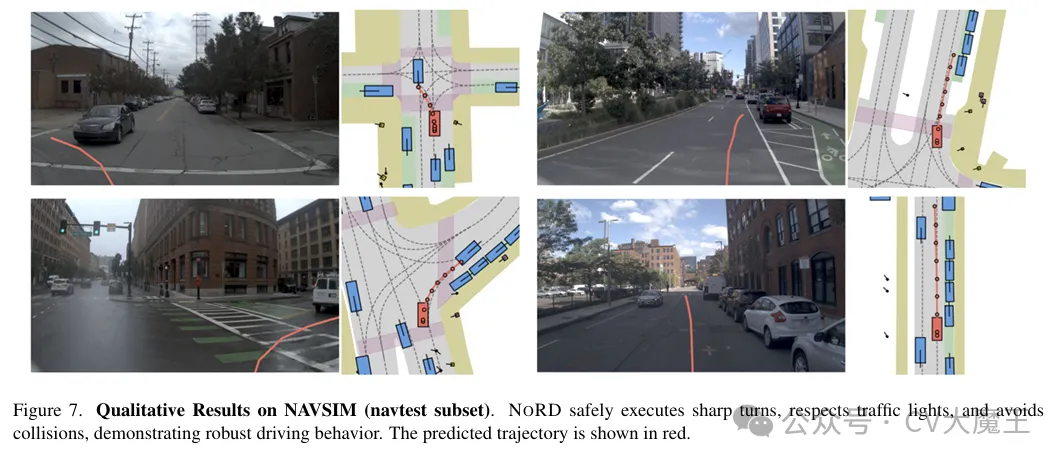
【主要内容】该工作关注自动驾驶场景中的 VLA 模型数据依赖问题。现有方法往往依赖大规模带 reasoning annotation 的数据(如轨迹解释、推理链),但获取成本极高。该论文提出一种无需显式推理标注的训练范式,使模型在低数据条件下仍能完成驾驶决策。通过弱化对显式 reasoning supervision 的依赖,直接从视觉输入到动作输出进行学习,同时引入隐式决策建模机制,让模型在不生成中间推理的情况下完成复杂决策。
【创新点】
【实验结论】NoRD 在自动驾驶相关基准测试中展现出了较强的数据效率优势。即使在训练数据规模受限、且不依赖显式 reasoning annotation 的条件下,该方法依然能够取得具有竞争力的驾驶决策性能,并在多个设置下优于依赖推理监督的对比方法。这说明,对于 VLA 驾驶模型而言,显式中间推理并不是获得高质量决策能力的唯一途径,更关键的是如何有效地从视觉输入中学习稳定的动作映射关系。论文的实验进一步验证了该方法在性能与训练成本之间取得了较好的平衡,说明低标注成本的 VLA 路线在自动驾驶场景中具有现实可行性。
2. Drive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving
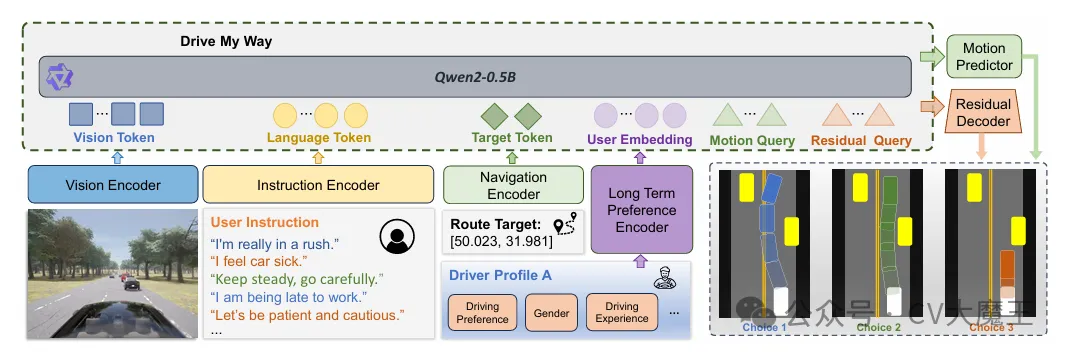
【主要内容】该工作关注 VLA 模型在自动驾驶中的个性化问题。传统驾驶模型默认单一最优策略,但现实中驾驶行为存在显著个体差异。 将人类驾驶偏好建模为可学习信号,引入偏好对齐机制,使 VLA 模型能够根据不同用户风格生成差异化决策。
【创新点】
首次系统性将偏好对齐引入 VLA 驾驶任务
构建驾驶偏好建模框架,将语言描述与行为策略对齐
设计可控策略生成机制,实现风格可调驾驶
【实验结论】Drive My Way 能够较为稳定地学习并区分不同用户的驾驶偏好,在个性化驾驶行为生成上明显优于传统单一策略模型。无论是在偏好一致性还是在行为差异化表达方面,该方法都表现出较强的可控性,说明模型不仅能够完成基本驾驶任务,还能够根据给定的风格偏好输出更符合用户预期的决策结果。更重要的是,论文的实验表明,这种偏好对齐并未显著削弱模型在安全性和任务完成度上的表现,反而展示出在保证驾驶可靠性的同时实现行为多样化的潜力,从而为个性化自动驾驶中的 VLA 建模提供了较强的实证支持。
3. SaPaVe: Towards Active Perception and Manipulation in Vision-Language-Action Models for Robotics
【主要内容】该工作关注机器人 VLA 的一个关键缺陷:现有模型大多为被动感知 + 单步决策,缺乏主动探索能力。研究提出将主动感知(Active Perception)与操作(Manipulation)联合建模,使模型能够通过行动获取信息,而不是仅依赖已有视觉输入。
【创新点】
【实验结论】SaPaVe 在需要主动获取信息的机器人操作任务中具有明显优势,尤其是在遮挡严重、环境信息不完整或目标状态存在不确定性的场景下,相比被动感知式的 VLA 方法表现出更高的任务成功率和更强的鲁棒性。论文通过一系列操作任务验证了主动感知与操作联合建模的有效性,说明机器人在真实环境中并不能仅依赖静态视觉输入完成可靠决策,而需要通过动作主动补充关键信息。整体来看,这些实验结果支持了论文的核心判断,即主动感知能力不是附加选项,而是 VLA 模型从实验室设定走向真实机器人应用场景的重要基础能力。
4. ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
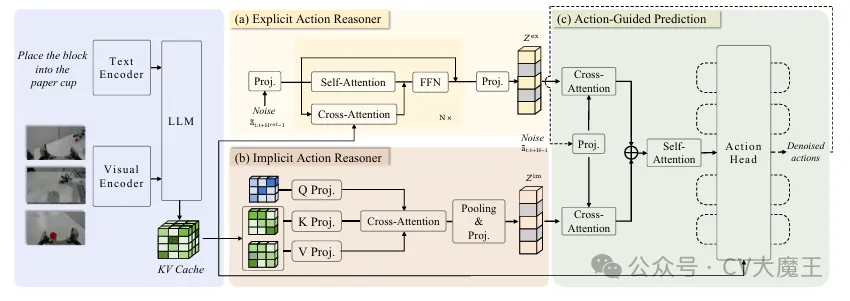
【主要内容】该工作关注 VLA 模型决策过程不可解释的问题。虽然一些方法引入 CoT,但主要集中在语言层,未直接作用于动作生成。提出Action Chain-of-Thought(ACoT),将推理链直接作用于动作序列生成,使模型在决策过程中显式建模多步动作逻辑。
【创新点】
【实验结论】ACoT-VLA 在长时序、多步骤的复杂任务中取得了比无推理建模或仅在语言层面使用 CoT 的方法更好的表现,尤其在动作执行成功率、决策稳定性以及长链条任务完成质量上体现出更明显的优势。论文的实验说明,将推理过程显式引入动作生成阶段,能够帮助模型更好地组织多步行为之间的逻辑关系,从而减少任务执行过程中常见的误差累积与策略偏移问题。同时,相关可视化分析也表明,该方法生成的动作序列具有更清晰的阶段性和更合理的决策路径,这进一步验证了 action-level chain-of-thought 在提升 VLA 可解释性与复杂任务执行能力方面的有效性。
科研资料大放送:
1.《申博咨询规划一次》
2.《1000+热门idea合集》
3.《往期大牛热点分析直播课》
4.《全方向顶会顶刊论文合集》








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
