一个自动驾驶从业者结合 Andrej Karpathy 的"Software 3.0"框架,对 Physical AI 范式转移的观察与思考。
我在自动驾驶领域工作多年,一个越来越强烈的感受是:这个领域的技术突破,正在系统性地从学术界向工业界转移。
这并不是说学术界变得不重要,而是游戏规则变了。当我读完 Andrej Karpathy 关于 Software 3.0 的论述后,这种直觉被进一步印证——自动驾驶以及整个 Physical AI 领域,正在经历一场从"人工设计算法"到"端到端数据转换"的根本变革。掌握"数据原材料"和"算力熔炉"的一方,自然成为定义技术边界的主导力量。
下面我想从四个维度展开这个判断,再回过头来谈一个更值得思考的问题:在这种格局下,学术界还能做什么?
---
一、范式之变:从"算法设计"到"信息转换"
要理解为什么突破点在转移,首先要看清楚我们正处在什么样的范式切换中。
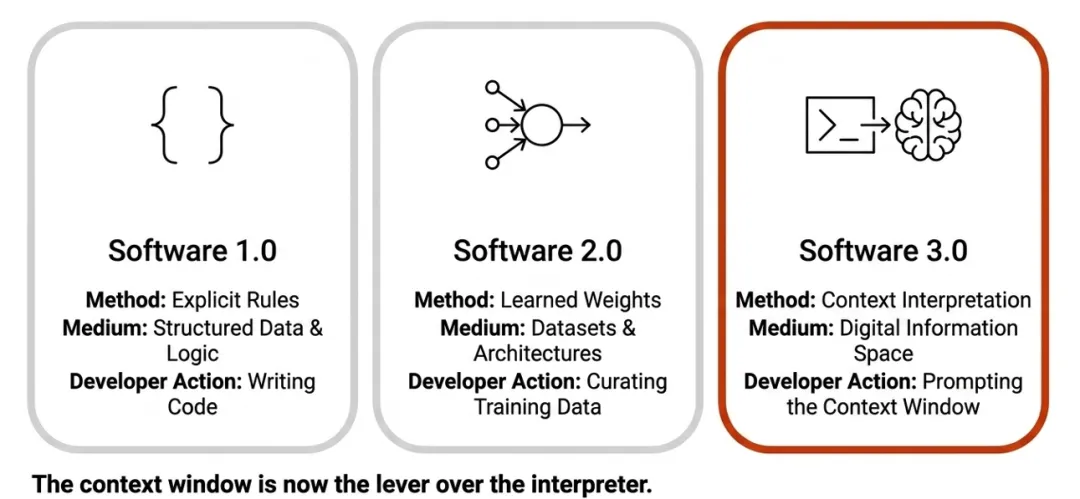
- Software 1.0:程序员编写显式规则;
- Software 2.0:通过整理数据集来训练神经网络权重;
- Software 3.0:将大模型本身视为一种可编程计算机,"编程"行为变成了 Prompting 和上下文构建。
Karpathy 的核心洞察是:Software 3.0 并不是简单的代码加速,而是"信息转换本身方式的变化"。
放到自动驾驶语境里,这个变化具体表现为:
计算原生的演进:新一代架构(如 World Models 和 VLA 模型)本质上不再是一系列算法的堆砌,而是多模态到多模态的端到端信息转换。原始视频、雷达、IMU 输入直接进入神经网络,输出动作决策——中间那一层曾经被视为"自动驾驶核心"的感知-预测-规划算法栈,正在被压缩、吞并、最终消失。
护城河的位移:在这种范式下,传统的"算法驱动"已经失去了大部分优势。数据集的规模、质量,以及计算资源本身,成为系统真正的壁垒。海量真实驾驶数据和大规模训练算力几乎只存在于工业界——这是一个学术界在"暴力美学"和规模效应维度上几乎无法竞争的赛场。
---
二、"神经网络宿主化":CPU 退化为协处理器
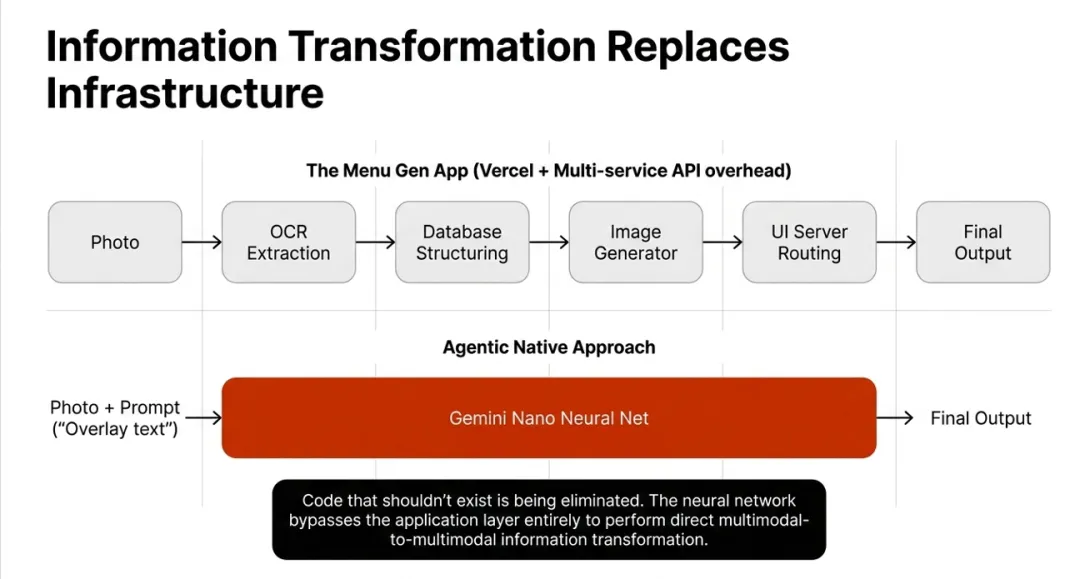
Karpathy 用一个很形象的例子——"Menu Gen"应用——说明了 Software 3.0 的颠覆性:传统应用里 OCR、图像生成等中间层代码在新范式下都是多余的,因为模型可以直接完成从原始图像到最终结果的转换。
这个逻辑放到自动驾驶上,结论更加激进:
- 原始数据直达动作:未来的系统可能像"神经计算机"一样,直接将原始视频/音频流输入神经网络,并通过扩散模型等技术渲染出驾驶决策乃至 HMI 界面。复杂的中间算法层不再必要。
- CPU 转为协处理器:神经网络成为处理大部分重体力劳动的"主进程",而传统的确定性算法退化为处理特定任务(坐标变换、安全冗余、底层通信)的"历史附件"。
这就是我所说的"神经原生"阶段——神经网络不再是系统的一个模块,而是系统本身的"主进程"。
这种架构层面的重构,决定了过去围绕"算法即资产"建立起来的学术研究路径,在自动驾驶这个赛道上正在快速贬值。
---
三、"可验证性"是工业界的天然主场
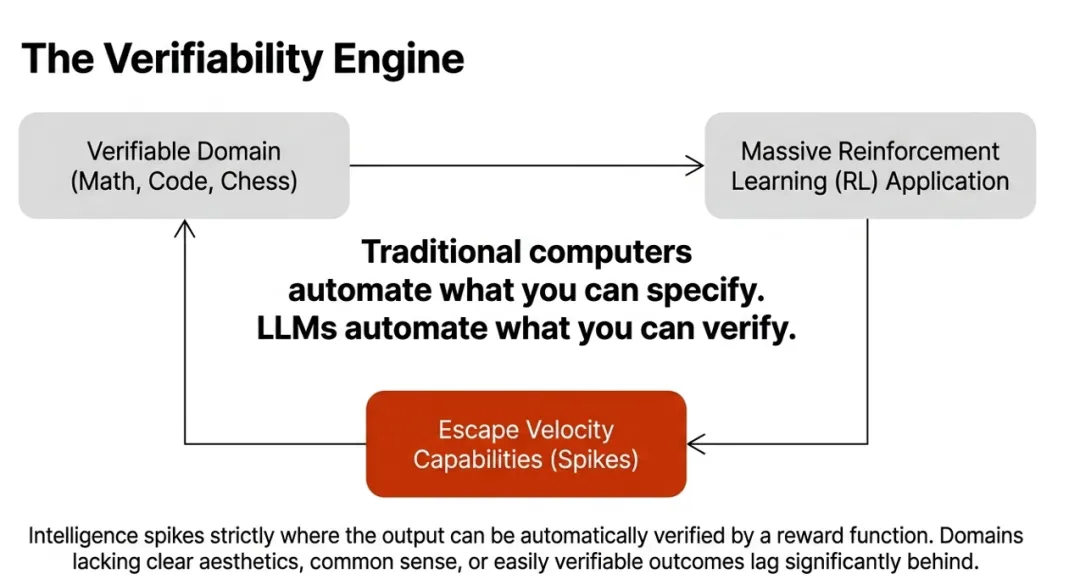
Karpathy 反复强调一个判断:AI 进步最快的地方,是那些结果可验证(Verifiability)的领域。这是一个非常关键的视角。
为什么这点对学术界不利?
从实验室到现实:判断一个驾驶模型的输出是否达到"可信任、可接受、可实操"标准,这种验证只能在工业生产的一线完成。学术界的 Benchmark——无论 nuScenes 还是 Waymo Open——都无法模拟真正复杂的长尾场景。Benchmark 上的 SOTA,与一辆能上路的车之间,差着整个工业体系的距离。
强化学习的回路:工业界能够构建巨大的 RL 环境,并根据真实的经济价值和安全需求设定奖励信号。通过 RL 推动模型跨越"智能锯齿"的过程,需要实时、海量的反馈回路——这只有掌握真实业务场景的工业界才能闭环。
数据分布的主动权:Karpathy 把模型形容为被数据"召唤"出来的幽灵,其能力跃迁往往源自实验室决定将特定数据加入预训练集。工业界的优势在于:当发现模型在某个特定工况下表现不佳时,可以迅速通过车队回传数据进行定向强化。这种闭环迭代速度,是学术研究无法企及的。
一句话:当能力边界由"数据分布"决定,而数据分布的主动权在车队手里时,学术界就只能做"看到的研究",而不是"决定方向的研究"。
---
四、工程师角色的重新定义
Software 3.0 视角下,工程师的工作已经从"写代码"转向了"智能体工程(Agentic Engineering)"。
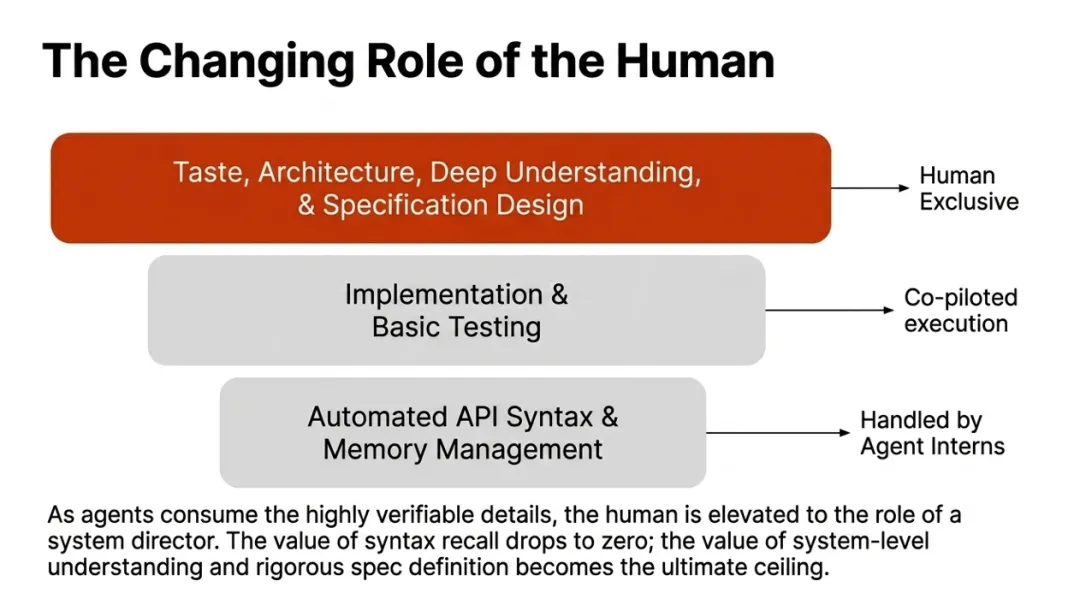
导演而非演员:工业界的工程师现在更像一位"导演"——负责设定愿景、判断美学、进行质量把控和架构监督,而具体的"填空"工作由模型完成。这是一种角色的根本性升级。
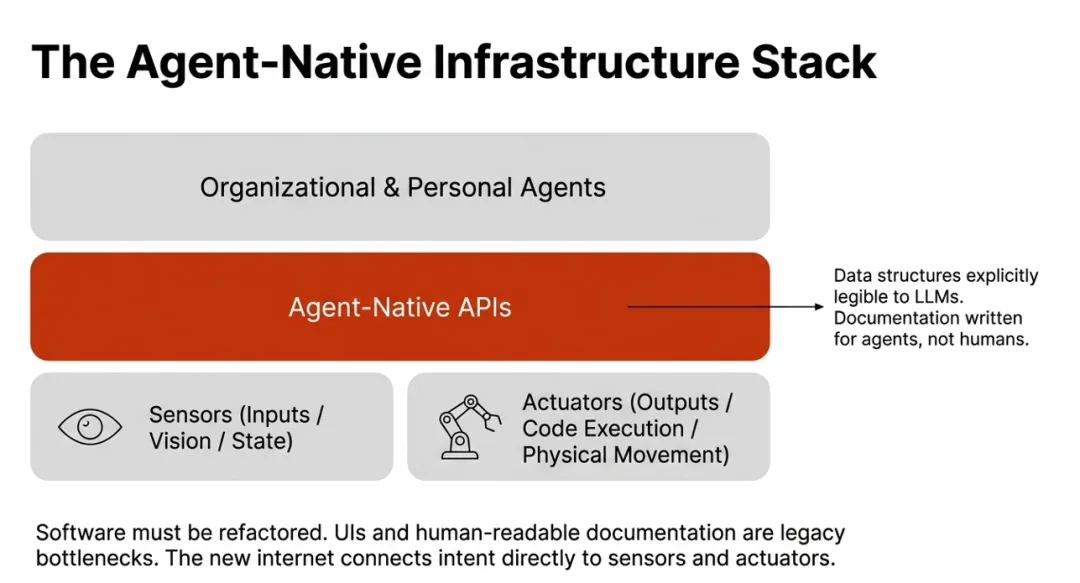
基础设施的代差:工业界正在重构"智能体原生(Agent-native)"的基础设施——把世界视为传感器(Sensors)和执行器(Actuators)的组合。这种在大规模生产环境中进行的底层架构重构,正在悄悄定义未来五到十年的技术标准。学术界往往在用"为人类设计的工具"研究"为 AI 设计的世界",这本身就构成了代差。
---
五、那么,学术界还能做什么?
写到这里,需要明确一点:承认突破点转移,并不意味着学术界没有价值。事实上,恰恰因为工业界全力扑在"可规模化"的方向,留给学术界的反而是一些更深刻、更难、但也更基础的问题。
我认为以下五个方向是学术研究在 Physical AI 时代真正的价值锚点:
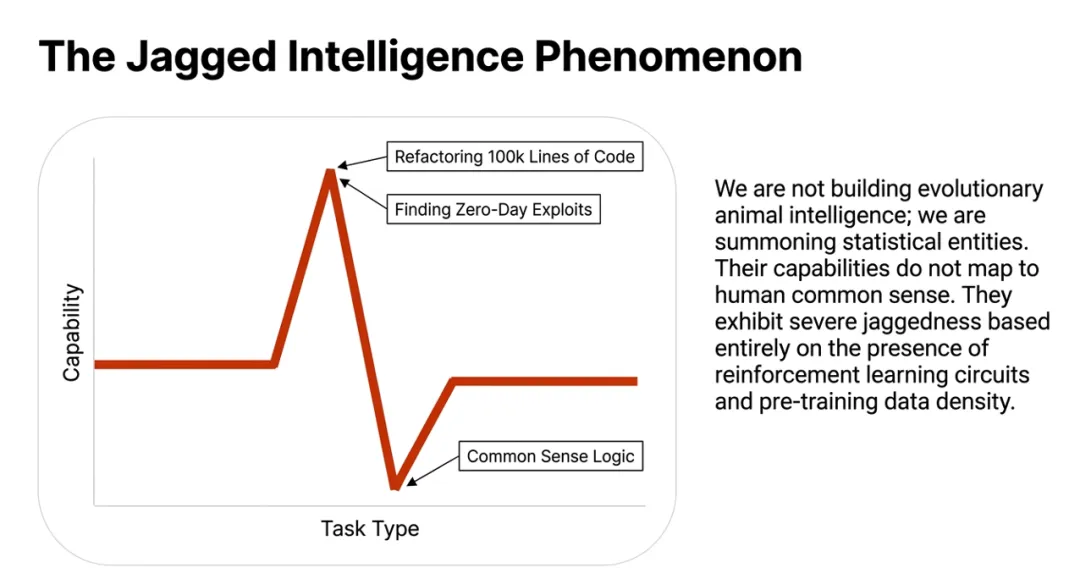
1. 破解"参差不齐的智能"(Jagged Intelligence)的底层原理
当前模型表现出极强的非线性能力——可以重构复杂代码,却可能在"洗车房应该开车还是步行"这类常识问题上出错。
工业界的解法很简单粗暴:塞数据。但学术界可以问一个更本质的问题:为什么智能会"参差不齐"? 能否通过非暴力堆砌数据的方式,系统性地修复这些认知锯齿?这是学术研究不可替代的位置。
2. 拓展"可验证性"的理论与边界
既然可验证性是 RL 进步的前提,那么让更多领域变得"可验证"本身就是一项基础工程。
- 对于难以验证的领域(审美、品味、复杂的道德判断),如何构建"智能体法官会议"或新的奖励函数?
- 哪些对社会有价值、但尚未被大型实验室纳入训练分布的可验证环境,值得被定义和开源?
这是学术界可以主导议程的领域。
3. 定义"软件 3.0"时代的计算架构
工业界忙于在现有基础设施(Vercel、DNS、HTTP)上打补丁——而这些设施本质上是为人类设计的。
学术界完全可以从底层重新构思 Agent-native 的基础设施:研究如何将世界建模为传感器和执行器的组合,开发一套完全面向 AI 而非人类阅读的协议和数据结构。这是一次类似 TCP/IP 早期那样的"协议层"机会窗口。
4. 探索"理解力"与"品味"的机器实现
Karpathy 强调:思维可以外包给 AI,但理解力(Understanding)目前仍是人类的专利。
模型生成的代码往往非常臃肿(bloaty),缺乏优雅的抽象。如何让模型习得"简洁"和"美感" 这些高阶特征?人类的"品味"如何被形式化、被注入训练目标?随着工程师角色转向"导演",人机协同的理论基础
亟需被建立。
5. 跨越"模拟"与"现实"的哲学与技术鸿沟
目前的 AI 更多像是被数据召唤出来的"幽灵",而非具备内在驱动力的"动物"。
研究如何赋予 Physical AI 类似生物进化的内在动机(Intrinsic Motivation)——好奇心、赋能感、趣味性——而不仅仅是响应外部奖励,这是 Physical AI 真正走向通用智能必须跨越的门槛。这类研究在工业界很难找到 KPI 对应位,正是学术界的天然位置。
---
结语
回到最初的判断:自动驾驶已经进入"神经原生"阶段,神经网络成为系统的主进程,传统 CPU 逻辑退化为附件。
在这种背景下,掌握"数据原材料"和"算力熔炉"的工业界,确实成为了定义技术边界的主导力量。这是范式本身的逻辑结果,不是谁的胜利或失败。
但这也意味着,学术界的价值需要重新定位——从"和工业界比谁的模型更准",转向"研究工业界无法用数据解决的问题"。底层原理的破解、新型验证框架的开发、Agent-native 协议的设计、人类理解力与机器智能的互补关系——这些才是 Physical AI 时代留给学术研究真正有意义的舞台。
工业界负责让事情发生,学术界负责让事情有意义。两者从来不是替代关系,只是分工正在被重新书写。
---
本文是个人在自动驾驶一线的观察与思考,欢迎讨论与拍砖。