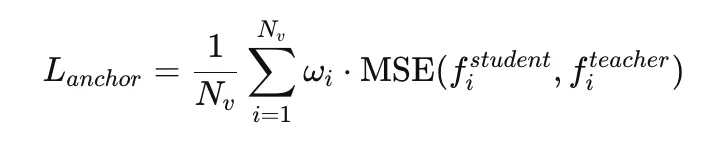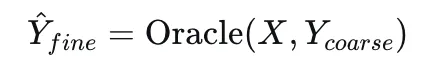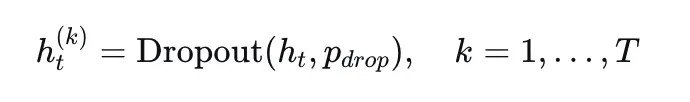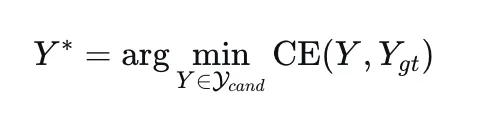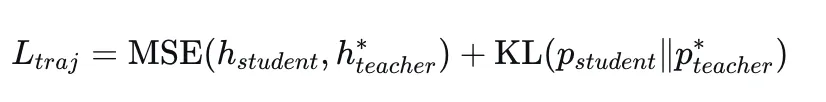视觉-语言-动作模型(VLA)无疑是当前自动驾驶领域最火的研究方向之一。它不仅能输出轨迹,还能理解导航指令、进行场景问答,甚至用上思维链推理解决复杂驾驶问题。
然而,VLA模型的训练存在两个让人头疼的问题:解冻视觉编码器后感知性能退化,以及长程规划中轨迹稳定性的累积衰减。
简单来说,你越想让它“看懂”复杂路况,它就越容易忘记原本会看的东西;你越想让它“规划得远”,它就越容易在中途跑偏。
如何在不牺牲感知能力的前提下提升规划性能?北大与小鹏联合团队给出了一个漂亮的答案——EvoDriveVLA,一种融合自锚定蒸馏与Oracle引导蒸馏的协同感知-规划框架。
第一个问题:为什么解冻视觉编码器会导致感知退化?
VLA模型通常基于预训练的视觉语言模型(VLM)构建。在微调阶段,研究者面临一个选择:要不要解冻视觉编码器?
这就是所谓的退化-适配困境。
第二个问题——长程规划的累积衰减,则更加直观。VLA模型在预测未来轨迹时,每一步的微小误差都会随着时间步长累积放大。时间越长,轨迹偏差越严重,甚至出现违反物理规律的情况。
现有的知识蒸馏方法试图解决这些问题,但它们存在三个明显短板:
视觉编码器被忽视:大多数蒸馏方法只关注规划轨迹,对视觉感知模块关注不足。
教师模型不够“强”:教师模型与学生模型在同一设置下训练,能力上并无本质优势,难以提供高质量知识。
轨迹多样性不足:多轨迹方法依赖预定义的规划词汇表,难以覆盖真实驾驶的动态变化。
EvoDriveVLA正是针对这三个短板,提出了系统的解决方案。
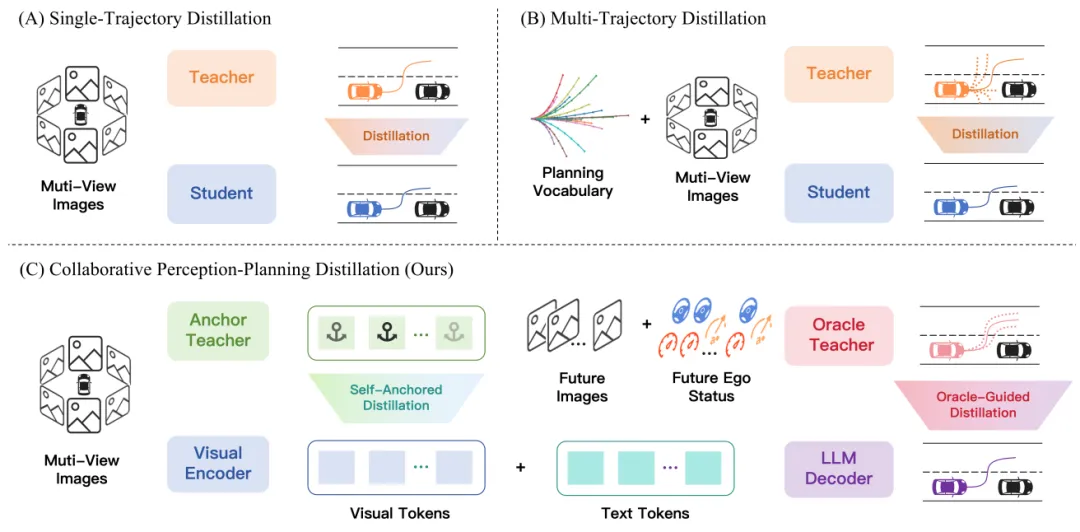
EvoDriveVLA核心思想:双管齐下的协同蒸馏EvoDriveVLA的核心理念可以用一句话概括:让感知守住底线,让规划仰望上限。
它包含两个并行模块:
两者协同作用,让VLA模型在保留通用视觉知识的同时,学会更精准、更稳定的长程规划。
下面是2个模块的详解:
3.1 核心思路
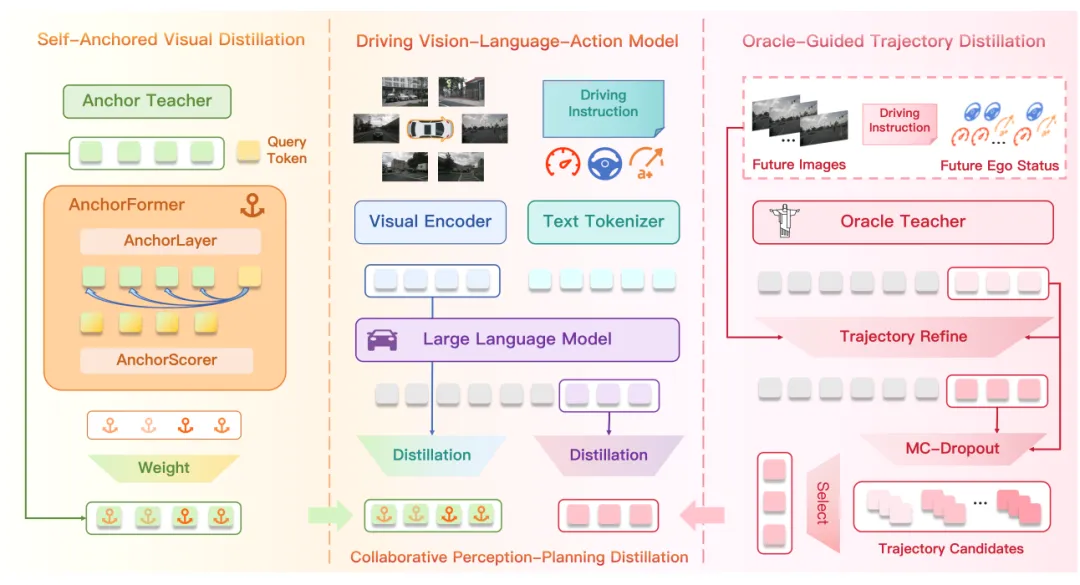
自锚定视觉蒸馏的做法非常巧妙:用学生模型自身的“过去版本”作为教师。
具体来说,在微调开始前,团队复制了一份学生模型的视觉编码器,将其冻结作为自锚定教师模型。训练过程中,这个教师模型提供稳定的视觉特征作为“锚定约束”,防止学生模型的视觉编码器在适配自动驾驶数据时偏离太远。
通俗理解:你可以学习新知识,但不能忘了老本行。锚定约束就是那个“提醒你保持基本功”的教练。
3.2 AnchorFormer:轨迹引导的令牌级锚定
但简单的全局特征约束粒度太粗。不同区域对驾驶任务的重要性不同——车道线、交通标志、行人显然比远处的天空更重要。
为此,团队设计了AnchorFormer模块,它由两部分组成:
最终,模型会为每个视觉令牌分配一个锚定权重ω_i,权重越高,该区域受到的特征约束越强。而权重的分配依据是:该区域与规划轨迹的相关性。
这意味着,靠近规划路径的关键区域(如前方路口的行人)会被施加更强的锚定约束,而无关区域(如路边树木)约束较弱。
3.3 蒸馏损失
最终的自锚定视觉蒸馏损失采用加权MSE:
其中ω_i是令牌级锚定权重,f_i是视觉特征。这个设计既保留了全局特征结构,又强化了任务相关区域的约束。4.1 什么是Oracle教师模型?
传统蒸馏中,教师模型与学生模型看到的信息完全相同,能力天花板被锁死。
EvoDriveVLA的做法是:给教师模型开“时间作弊器”。
Oracle教师模型除了当前的图像和自车状态,还能看到未来τ秒的图像和自车状态作为条件输入。这相当于让教师模型拥有“预知未来”的能力,自然能做出更精准的轨迹预测。
当然,这仅在训练阶段使用,学生模型推理时仍只依赖当前观测。但教师模型学到的精细推理路径,可以通过蒸馏迁移给学生。
4.2 由粗到精的轨迹优化
有了未来信息,如何最大化利用?
团队提出由粗到精的轨迹优化:Oracle教师先生成一个粗轨迹预测,然后将这个粗预测作为额外输入,重新输入模型进行细化修正。
这个过程可以递归进行,每轮修正都利用未来信息对轨迹进行时空一致性约束,生成更平滑、更符合物理规律的优化路径。
数学上可以表示为:
其中X包含当前和未来的观测,Y_coarse是粗轨迹,Y_fine是优化后的精细轨迹。
这种“生成-修正”的递归过程,本质上模拟了人类驾驶中的持续预判与微调机制。
4.3 蒙特卡洛丢弃采样:低成本高多样性
由粗到精的优化虽然精度高,但多样性有限。为了给学生模型提供更丰富的轨迹分布,团队引入了蒙特卡洛丢弃采样。
具体做法:对候选集中的每个隐藏状态,在固定模型参数的前提下,施加T次随机丢弃扰动,生成多样化的隐藏状态样本:
由于丢弃只作用于隐藏状态,且后续的语言模型头计算量极小,这种方法在引入极小计算开销的同时,显著提升了轨迹候选集的多样性。
4.4 最优轨迹筛选与蒸馏损失
从候选集中,团队计算每条轨迹与真实轨迹的交叉熵损失,选出最优轨迹:
然后,用这条最优轨迹对应的隐藏状态和对数几率作为软目标,对学生模型进行双层级对齐:
特征层对齐:学生模型的隐藏状态向教师模型对齐
输出层对齐:学生模型的预测分布向教师模型对齐
最终的轨迹蒸馏损失为:
这种设计让学生模型不仅能复刻教师的输出,还能内化复杂轨迹优化所需的底层推理能力。5.1 开环评估:nuScenes SOTA
在nuScenes数据集上,EvoDriveVLA与三类基线方法进行了对比:传统方法、基于LLM的方法、基于蒸馏的方法。
结果:在所有对比方法中取得SOTA。
具体数据:
这是首个在感知和规划两个维度上都显著超越强基线的蒸馏方法。
5.2 闭环评估:NAVSIM全面领先
在NAVSIM闭环仿真评估中,EvoDriveVLA同样取得最佳成绩。
一个非常有意思的发现:蒸馏后的3B模型性能甚至超过了Qwen2.5-VL 8B和InternVL3-8B,PDM分数领先2.0分(相对提升2.4%)。
所以,好的蒸馏方法可以用更小的模型尺寸,达到甚至超越更大规模模型的效果。对于车载计算资源受限的场景,这无疑是个好消息。
5.3 消融实验:每个模块都不可或缺
消融实验验证了各组件的有效性:
核密度估计可视化显示,由粗到精优化使轨迹损失分布向低数值区域显著偏移,异常值的长尾分布得到大幅缓解。而MC-Dropout则让近30%的教师预测轨迹与真实轨迹的损失小于0.1。
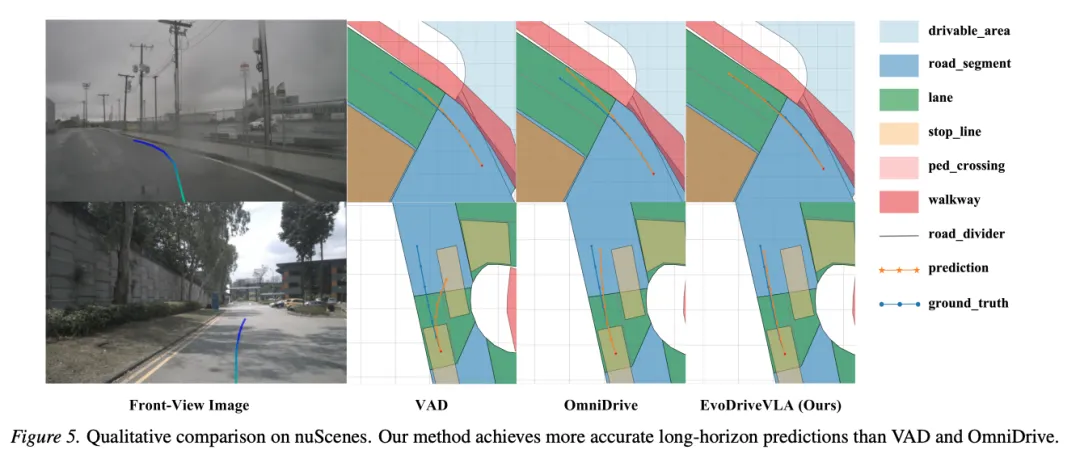
5.4 定性结果:长程规划明显更稳
可视化对比显示:在晴天/阴天、直道/弯道等不同场景下,EvoDriveVLA的长时域轨迹预测显著优于VAD和OmniDrive。
EvoDriveVLA的价值不仅在于性能提升,更在于它为VLA模型的训练提供了一个新范式:
1. 感知与规划不能割裂:自锚定视觉蒸馏证明了,规划蒸馏需要与感知蒸馏协同进行,单独优化任何一方都会遇到瓶颈。
2. 教师模型需要“特权信息”:Oracle教师的设计表明,一个好的教师模型不应与学生模型“同质化”。引入额外的特权信息(哪怕是训练阶段不可用的),可以显著提升蒸馏质量。
3. 多样性采样是低成本高回报的策略:MC-Dropout以极小的计算开销换来了轨迹多样性和质量的双重提升,这个思路可以推广到更多生成任务中。
4. 小模型+强蒸馏 > 大模型+弱训练:3B蒸馏模型超越8B原始模型的结果,再次印证了“蒸馏比堆参数更高效”的观点。
当然,EvoDriveVLA也有其局限性。目前的开环和闭环评估仍基于nuScenes和NAVSIM等离线数据集或简化仿真,距离真实的实车部署还有距离。另外,Oracle教师依赖未来信息,如何将这种“预见能力”更高效地蒸馏给学生,仍有优化空间。
但无论如何,这项工作为VLA模型的演进提供了一个极具价值的思路:在感知与规划之间找到平衡点,通过协同蒸馏让两者共同进化。