近日,为期10天的2026北京国际汽车展览会正式闭幕。本次车展集中展示了最新智能驾驶系统(如华为乾崑ADS 5.0)、自研车载芯片(如理想马赫100芯片、小鹏图灵AI芯片)及高阶智驾模型算法(如Momenta R7)等在内的前沿成果。其中,智能驾驶与AI大模型的深度融合落地成为核心议题。
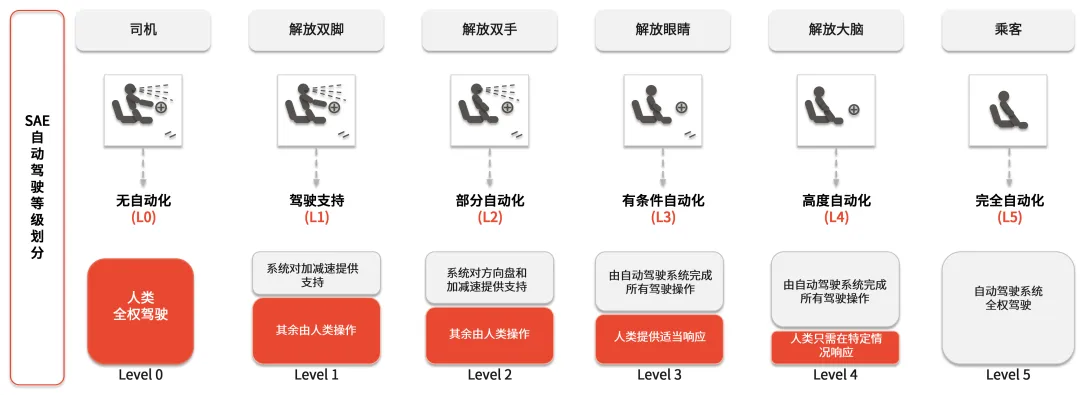
而就在北京车展前夕,业内爆发了一场关于自动驾驶技术发展路径的讨论,华为、吉利力挺“必经L3”,小鹏主张直接“跳跃”直达L4。无论如何,自动驾驶从概念走向现实,已进入新的发展阶段。
全新一代问界M9,搭载华为最新一代ADS高阶智驾系统;图片来自北京国际汽车展览会公众号
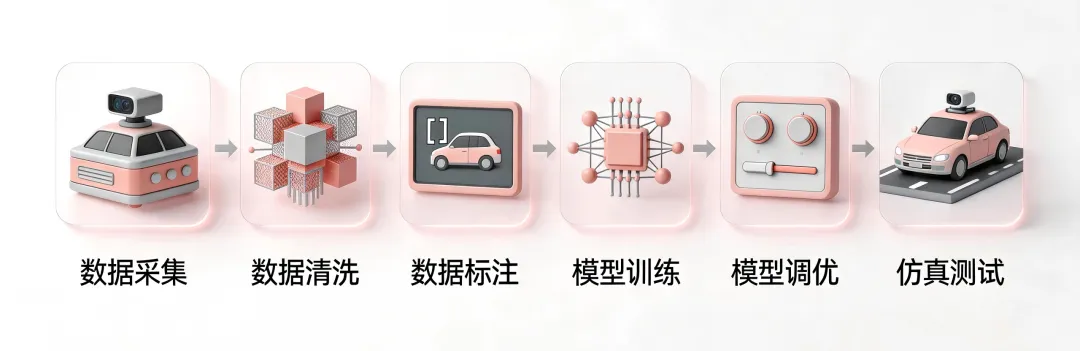
自动驾驶的研发是一个迭代链路极长、环环相扣的系统工程。其核心流程通常包括数据采集、清洗、标注、训练、调优、仿真、测试、整车ECU部署、持续数据回流与模型监控等多个环节。在不同环节,数据形态与处理负载有着本质差异。
采集与传输阶段:每辆车通过超50个各类传感器(各类摄像头、激光雷达、毫米波雷达等),每日约上传十几 GB 数据,随着车辆规模扩大,总数据量迅速攀升至数十PB甚至上百PB。车队产生的多路同步原始流需回传至数据中心。
清洗与标注阶段:ETL管道需对PB级数据集进行去重、异常值清洗、时间对齐,并依据场景库调用2D/3D标注工具进行像素/点云级的语义分割、物体跟踪等。
训练与仿真阶段:数千个GPU节点需要读取海量的已标注样本(如图像-标签对)进行模型训练。仿真验证则需要将真实采集的场景数据(尤其是长尾corner case)注入数字孪生平台进行高并发回放。
当前,自动驾驶正从辅助驾驶(L2/L2+)向有条件自动驾驶(L3)跨越,随着传感器数量和精度的大幅提升,以及端到端大模型的应用,海量的多模态数据、差异化的场景与高频率的训练需求,不仅驱动了算力需求,更对数据存储的性能、可扩展性与系统级稳定性构成了严峻挑战。根据相关报告,自动驾驶要达到高级别(SAE 5级)安全水平,需要在真实世界抓取约2.4亿公里的验证数据,由此产生的存储需求将达到惊人的50-100 EB级别。
而在自动驾驶研发训练过程中, 数据是这个闭环的“血液”。任何环节的数据瓶颈,都将直接影响整个研发进程。正是在这样的系统性压力下,行业普遍面临着规模化数据带来的多重现实困境。
自动驾驶数据的“海量”是指EB级别的总容量增长,而“异构”则表现为从高吞吐的视频流、高密度的激光雷达点云到稀疏的毫米波雷达点云的混合形态。头部车企日处理数据量已达PB级,并需支持数百并发任务同时处理。同时,在训练阶段需频繁访问大量小文件,带来严重的元数据操作压力。元数据处理能力成为小文件并发读取的关键瓶颈。
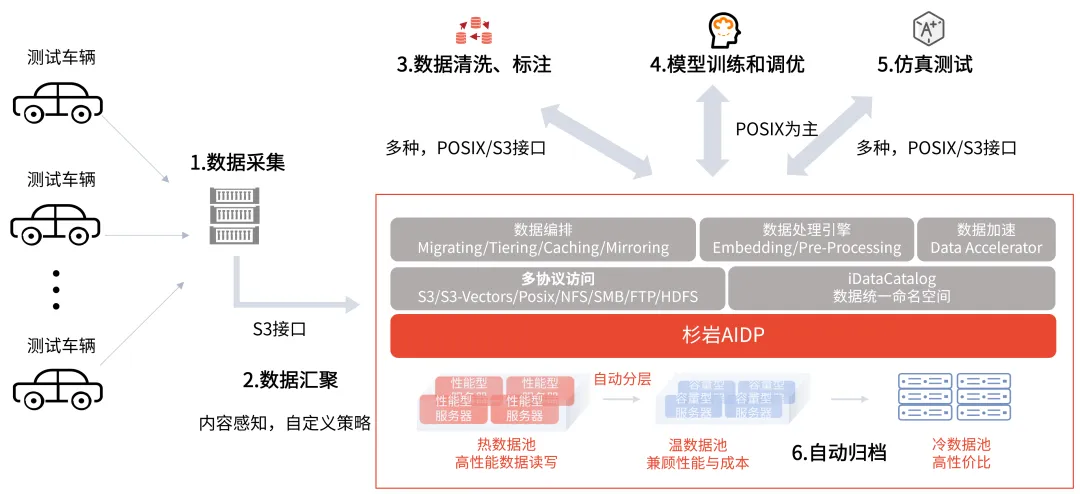
从采集车的实时数据回传(对象接口),到AI训练时千万级文件的并行高速读取(POSIX接口为主),再到云端仿真测试时的对象化访问(多种协议接口,POSIX文件/对象接口),不同研发环节对数据访问的协议和性能指标要求大相径庭,导致数据需在不同存储系统间来回导出、转换、导入,不仅技术栈复杂、运维成本剧增,更在跨系统数据迁移时形成流程断层,严重拖慢算法迭代速度。
在万亿参数大模型训练中,数据供给速度必须与GPU计算能力匹配,一旦存储I/O成为瓶颈,昂贵的GPU算力将大量闲置,研发成本急剧上升。为应对此挑战,常需过度配置高性能全闪存储来保障热数据访问,但这将大量温、冷数据(如历史场景包、旧版本模型)也存储于昂贵介质中,导致TCO(总体拥有成本)过高。反之,若采用人工或简单策略将数据归档至低性能介质,又会使数据“冻结”,难以被快速检索和复用,违背数据价值最大化原则。当前割裂的存储体系使得数据生命周期管理策略难以统一实施和数据一致性难以保证。
自动驾驶数据的全流程涉及采集、标注、训练、仿真与归档等多个异构环境,导致运维架构极其复杂。具体表现为:数据管道跨多个集群与存储后端,版本及依赖管理混乱,故障排查需穿透多个系统层级。这不仅大幅增加了运维人力投入,更因其链路冗长、缺乏统一视图,导致线上问题定位缓慢,直接影响算法迭代周期。
针对上述挑战,杉岩数据构建了新一代AI数据平台——杉岩AIDP(SandStone AI Data Platform)。该平台以对象存储为基础,深度融合多协议访问、智能分层、存算融合与全局统一命名空间技术,为智能驾驶研发提供坚实的数据底座。
核心架构与关键能力:
● 全协议无损互通,消除数据孤岛:一套系统同时提供标准POSIX、S3等多种协议接口,无缝覆盖从数据采集、预处理到模型训练、仿真的全流程各环节,实现数据平滑流转,无需在多套存储系统间手动迁移。消除传统数据迁移导致的性能损耗。
● EB级容量与千亿文件,支撑海量数据存储:基于分布式架构,平台支持EB级容量弹性扩展,单桶即可承载千亿级对象。读写性能随节点增加线性提升,满足机器人或测试车集群对海量多模态数据的实时存取需求。
● 智能分层与全生命周期管理,大幅降低TCO:平台提供面向数据全生命周期的智能分层存储方案,自动根据数据访问频率(热、温、冷属性)在SSD、HDD、磁带库等多种介质间分级存储。通过精细化生命周期管理策略,在保障核心训练性能的同时,可帮助企业整体TCO降低超过55%。
● 性能优化与缓存加速,极致释放GPU算力:内置多级缓存架构(包括NVMe SSD与MEM层级),实现热点数据智能识别与加速,将极致响应时延降至μS级,确保训练任务持续高吞吐,充分释放昂贵GPU算力潜能。
● 一站式数据管理,大幅提高训练效率:自动规整多模态数据,高效构建训练集。元数据存储于高性能SSD,实现训练集秒级检索、样本毫秒级浏览与在线预览标注,为AI模型快速迭代提供高质量数据基础。数据查询后可直接通计算集群进行处理,免去下载拷贝环节,显著缩短“大脑”学习周期。
如今,中国自动驾驶正处于从技术验证迈向规模化商业落地的关键阶段,下半场拼的是数据和将数据点石成金的能力,即数据闭环能力。面对体量爆发、类型庞杂、存储割裂的“数据新三座大山”,唯有夯实底层的数据基础设施,才能解锁AI模型的迭代潜力。
杉岩AIDP通过构建高性能、弹性、智能的统一数据基座,解决数据存、管、用的核心难题,将数据资产系统地转化为模型燃料,为自动驾驶企业构筑了扎实而关键的竞争优势。
▼ 戳“阅读原文”,前往杉岩数据官方网站。