
🐉 龙哥读论文知识星球来了!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
端到端自动驾驶的“黑盒”问题一直是落地瓶颈,归因方法通常是马后炮,但这篇文章反其道而行之,首次系统性论证了归因图本身就能作为风险预警信号。该方法不修改原模型,实验设计严谨,泛化能力不错,碰撞预测AUROC达到0.77,创新性和实用价值俱佳。
原论文信息如下:
论文标题:
Can Attribution Predict Risk? From Multi-View Attribution to Planning Risk Signals in End-to-End Autonomous Driving
发表日期:
2026年05月
发表单位:
中山大学, 中国科学院大学, 南洋理工大学
原文链接:
https://arxiv.org/pdf/2605.06264v1.pdf
1. 端到端规划的黑盒困境:不仅要知道轨迹错了,更要看到它凭什么错
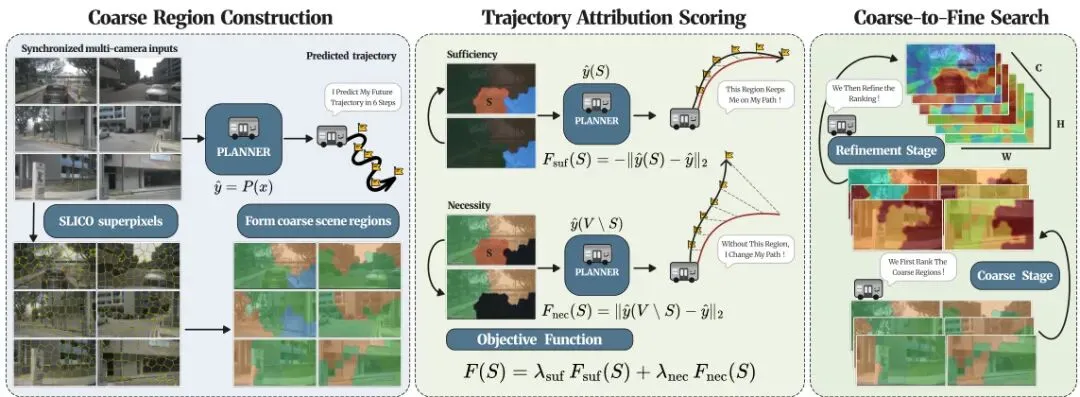
如今的自动驾驶圈,端到端(End-to-End)已经成为最火的方向。特斯拉 FSD V12 直接抛弃了传统的“感知-预测-规划”多模块流水线,让一个大模型从摄像头原始图像一路输出方向盘、油门、刹车指令。看起来挺酷,但问题也随之而来——这个黑箱里到底发生了什么?如果它做了一个错误的变道决策,我们不仅要知道轨迹错了,更要搞清楚它到底是看了什么“鬼东西”才做出这个判断。现有的可解释方法,要么是用语言模型生成一段文字描述(比如 DriveGPT4),要么是训练一个额外的监控模型来检测风险。但语言解释本身也很黑箱,你根本不知道它是不是在瞎编;而辅助监控模型与规划器是脱钩的,它看到的只是场景层面的风险,而不是规划决策本身的风险——危险的场景不一定会导致规划失败,看似无害的场景也可能埋下隐患。所以,真正要分析风险,必须从规划器自己的行为入手。归因(Attribution)是一种非常自然的思路:它通过衡量输入图像的哪个区域对输出有多大贡献,来揭示决策依据。以往的工作已经用归因来分析分类模型,但端到端规划完全不同——输入是六个摄像头(前、后、左、右等)的高清图像,输出是连续的多步轨迹,而不是一个类别分数。这就对归因方法提出了全新的挑战。本论文要回答一个核心问题:归因不仅能解释多视图的端到端规划,还能预测潜在的风险吗?为了回答这个问题,来自中山大学、中国科学院大学和南洋理工大学的研究团队,提出了一套层次化归因框架,并在此基础上提炼出三个统计信号,能够用归因图来预测规划风险。2. 核心创新:一个“粗到细”的层次化归因框架,高效定位决策依据
传统归因方法(比如 RISE)需要随机采样大量的区域掩码,然后看模型输出的变化。但端到端规划器推理一次就要几毫秒,六视图下采样几千次,时间成本直接爆炸。所以,本文设计了一个巧妙的“粗到细”(Coarse-to-Fine)层次化搜索策略,大幅降低计算量,同时保持归因的准确度。图1:层次化归因流水线。多相机输入被分割成SLICO超像素并分组为粗区域(左)。候选子集由规划器预测轨迹上的目标函数评估(中)。粗到细的贪婪搜索先选择粗区域,再细化子区域,最终产生每像素的显著度张量(右)。具体来说,本文先把每张相机的图像用 SLICO 超像素分割成一个个小区域(subregions),然后把这些小区域按空间相邻关系合并成“粗区域”。在粗阶段,只对粗区域进行贪婪选择:每次挑出对轨迹影响最大的那个粗区域;在粗阶段确定顺序后,再进入精炼阶段,在每个粗区域内部对子区域进行进一步的贪婪排序。这种方法充分发挥了驾驶场景的自然层级结构——规划器通常先关注一个大的空间区域(比如前方的交叉口),然后才聚焦到其中的细节(比如车道线、前车轮廓)。归因的目标函数设计也很关键。本文同时考虑了充分性(Sufficiency)和必要性(Necessity):
充分性:如果只保留选中的区域,规划器的输出应该和原始输入下的轨迹尽可能接近。
必要性:如果移除选中的区域,规划器的输出应该发生显著变化。
二者结合,才能找到真正关键的视觉证据。目标函数定义如下: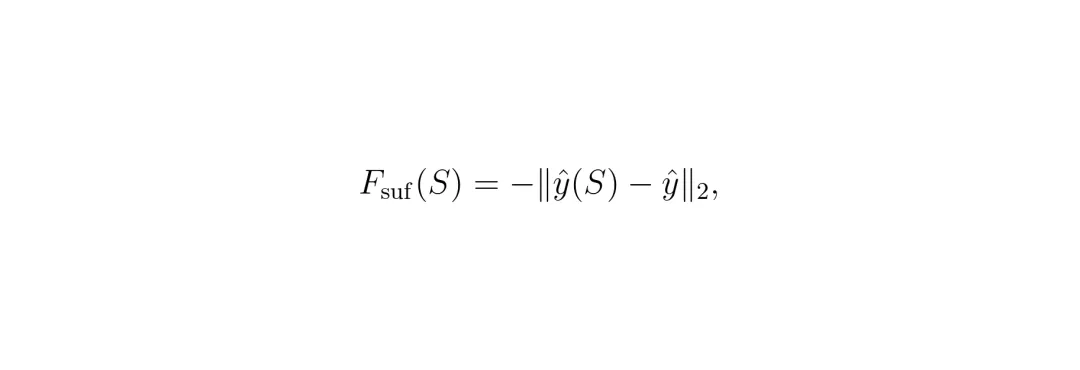 充分性分数:Fsuf(S) = -∥ŷ(S) - ŷ∥₂,其中 ŷ(S) 是只保留S区域时规划器输出的轨迹,ŷ 是原始输入下的轨迹。
充分性分数:Fsuf(S) = -∥ŷ(S) - ŷ∥₂,其中 ŷ(S) 是只保留S区域时规划器输出的轨迹,ŷ 是原始输入下的轨迹。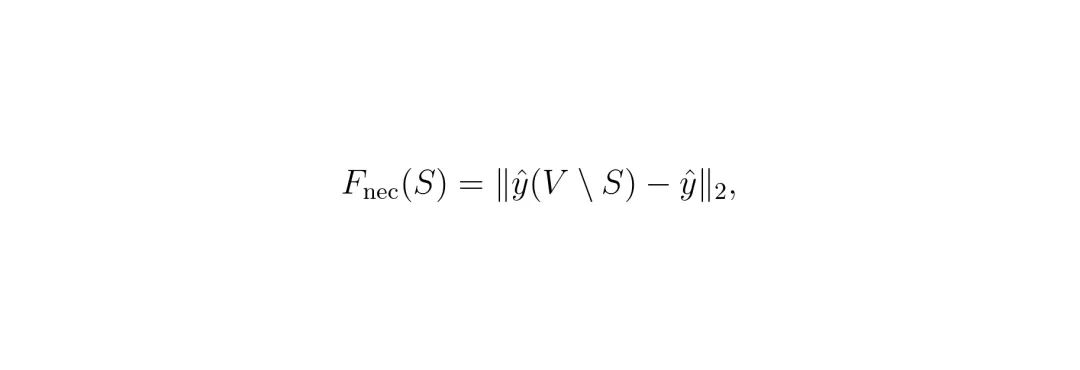 必要性分数:Fnec(S) = ∥ŷ(V\S) - ŷ∥₂,其中 V\S 表示移除S区域后剩下的部分。
必要性分数:Fnec(S) = ∥ŷ(V\S) - ŷ∥₂,其中 V\S 表示移除S区域后剩下的部分。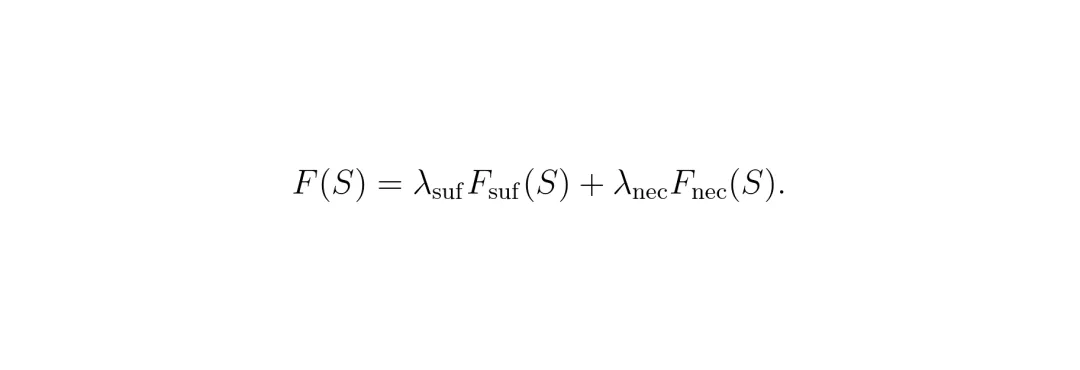 组合目标:F(S) = λsuf Fsuf(S) + λnec Fnec(S) ,两个超参数平衡充分性和必要性的权重。看到这里,你可能会觉得:这不就是一个经典的子集选择问题吗?而且优化这个目标函数是NP-hard的。没错,但是本文的粗到细策略非常优雅:先将相邻子区域聚合成粗区域,在粗区域级别上进行贪婪搜索,得到粗区域排序和边际增益;然后以粗区域的前序集合为条件,在各自内部对子区域进行独立的贪婪排序。这大大减少了搜索次数,同时保持了接近全贪婪搜索的忠实度(faithfulness)。
组合目标:F(S) = λsuf Fsuf(S) + λnec Fnec(S) ,两个超参数平衡充分性和必要性的权重。看到这里,你可能会觉得:这不就是一个经典的子集选择问题吗?而且优化这个目标函数是NP-hard的。没错,但是本文的粗到细策略非常优雅:先将相邻子区域聚合成粗区域,在粗区域级别上进行贪婪搜索,得到粗区域排序和边际增益;然后以粗区域的前序集合为条件,在各自内部对子区域进行独立的贪婪排序。这大大减少了搜索次数,同时保持了接近全贪婪搜索的忠实度(faithfulness)。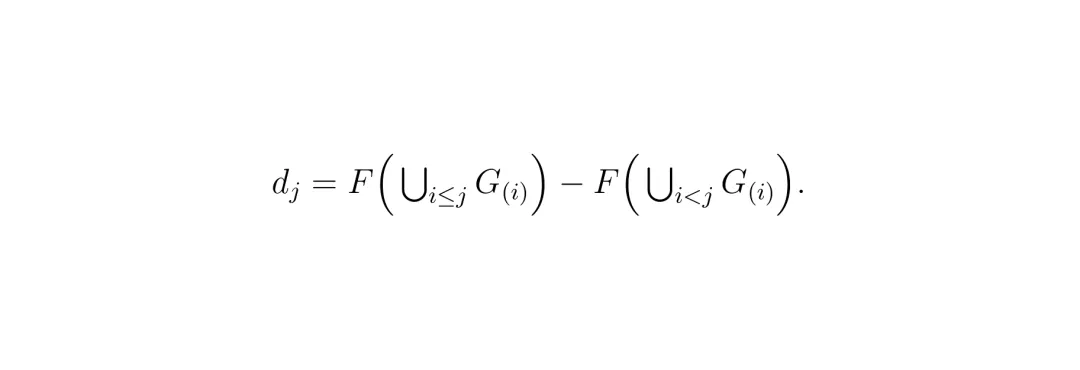 粗阶段边际增益:dj = F(∪i≤j G(i)) - F(∪i<j G(i))。
粗阶段边际增益:dj = F(∪i≤j G(i)) - F(∪i<j G(i))。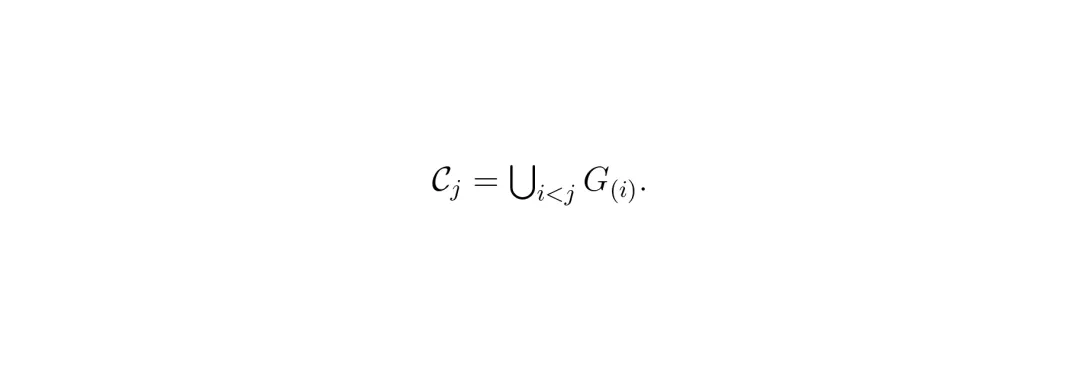 最终,每个子区域在序列中的边际增益就是它的归因分数,映射回对应相机的像素位置,就得到了规划显著度张量 T(维度 C×H×W)。这个张量就是后续风险信号的基础。
最终,每个子区域在序列中的边际增益就是它的归因分数,映射回对应相机的像素位置,就得到了规划显著度张量 T(维度 C×H×W)。这个张量就是后续风险信号的基础。3. 三大风险信号:全局熵、视图内方差、跨相机基尼系数,量化“过度依赖”
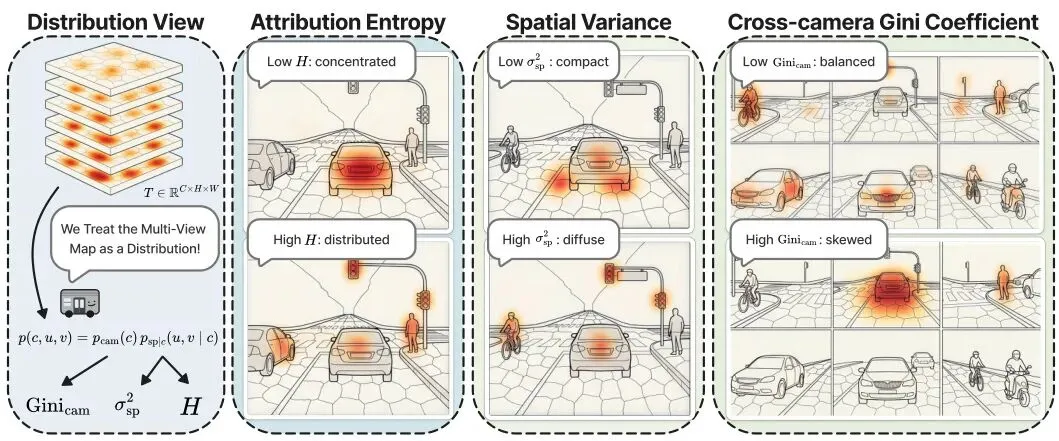
有了归因图之后,怎么用它来判断风险呢?直觉上,如果规划器过度依赖少数几个区域,一旦那些区域被遮挡或出现异常,规划很可能会出错。换句话说,稳健的规划应该避免对有限视觉证据的过度依赖。基于这个启发,本文从三个层次定义了量化指标: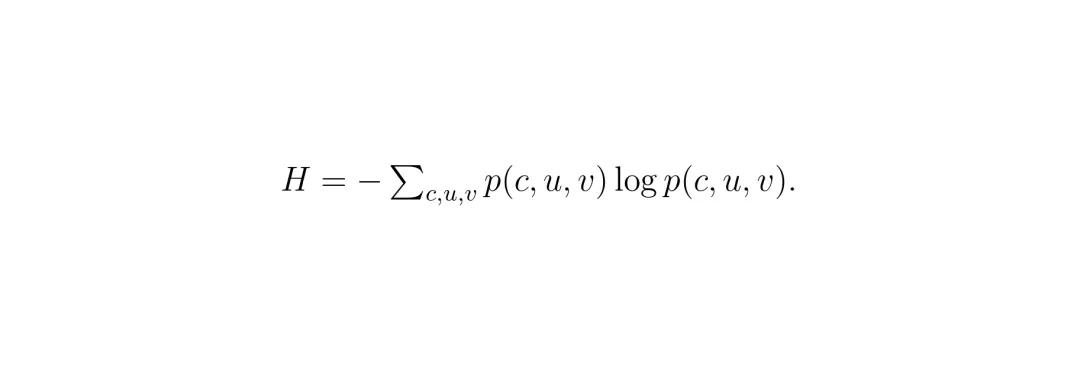 归因熵(Attribution Entropy):衡量全局上归因分布是否集中在整个多视图像素空间的很小一部分。熵越小,表示规划器只依赖非常有限的视觉位置,意味着更强烈的全局过度依赖。其中 p(c,u,v) 是归一化后的归因概率。
归因熵(Attribution Entropy):衡量全局上归因分布是否集中在整个多视图像素空间的很小一部分。熵越小,表示规划器只依赖非常有限的视觉位置,意味着更强烈的全局过度依赖。其中 p(c,u,v) 是归一化后的归因概率。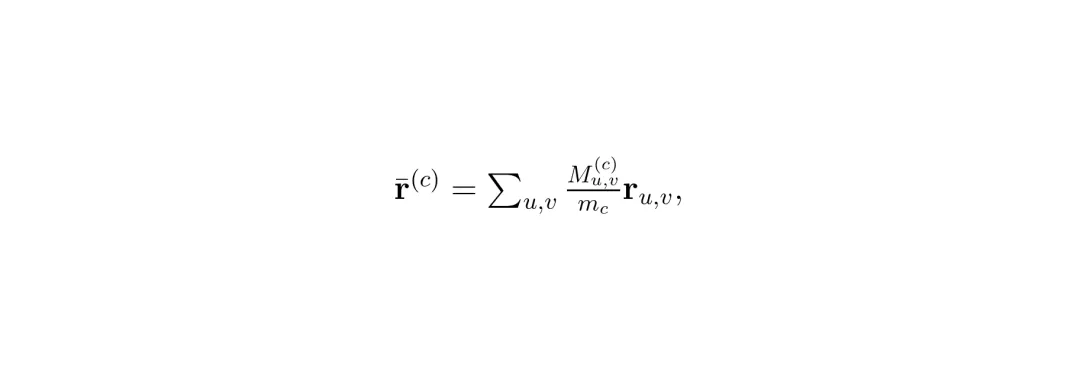
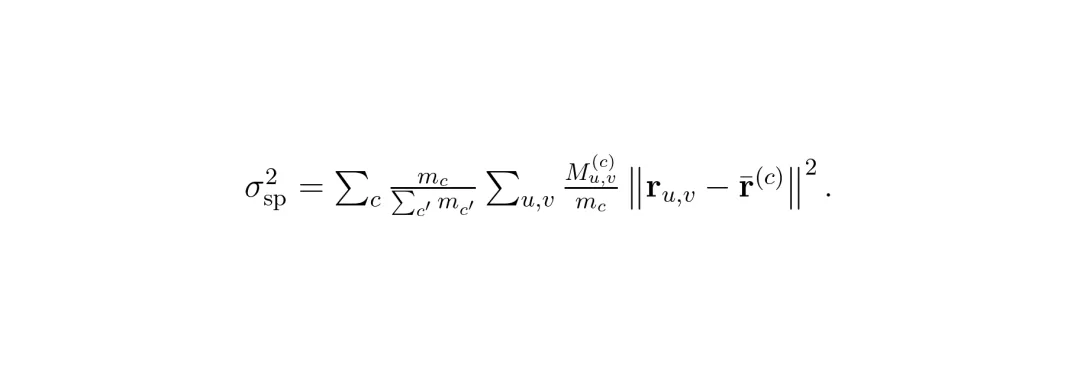 视图内空间方差(Within-camera Spatial Variance):在每个相机视图内部,归因是否集中在一个小区域。先计算每张图的归因质心,再计算像素围绕质心的平均距离的加权平均。方差越小,表示归因在视图内越集中,意味着更强的视图内过度依赖。
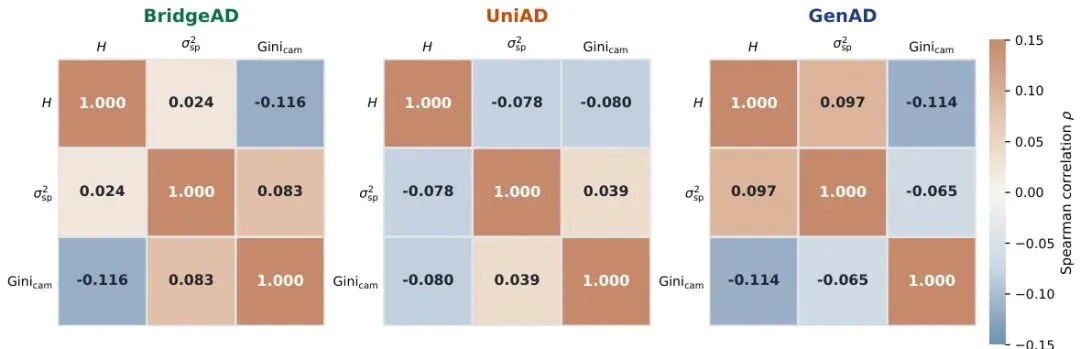
视图内空间方差(Within-camera Spatial Variance):在每个相机视图内部,归因是否集中在一个小区域。先计算每张图的归因质心,再计算像素围绕质心的平均距离的加权平均。方差越小,表示归因在视图内越集中,意味着更强的视图内过度依赖。 跨相机基尼系数(Cross-camera Gini Coefficient):衡量归因在所有六个相机之间分配的不均匀程度。基尼系数越高,表示规划器过度依赖某一个或某几个相机,而忽略其他视角。图2:从多相机显著度的分布视角看三个归因统计量。归因熵衡量全局集中度,视图内空间方差衡量每个视图内的空间离散度,跨相机基尼系数衡量跨视图的不平衡度。这三个统计量相互之间几乎不相关(论文做了相关性分析,斯皮尔曼相关系数绝对值不超过0.12),说明它们捕获了归因分布的不同维度,互补性很强。图3:三个归因统计量之间的两两斯皮尔曼相关性,在BridgeAD、UniAD和GenAD上分别展示。所有非对角线条目绝对值不超过0.12。
跨相机基尼系数(Cross-camera Gini Coefficient):衡量归因在所有六个相机之间分配的不均匀程度。基尼系数越高,表示规划器过度依赖某一个或某几个相机,而忽略其他视角。图2:从多相机显著度的分布视角看三个归因统计量。归因熵衡量全局集中度,视图内空间方差衡量每个视图内的空间离散度,跨相机基尼系数衡量跨视图的不平衡度。这三个统计量相互之间几乎不相关(论文做了相关性分析,斯皮尔曼相关系数绝对值不超过0.12),说明它们捕获了归因分布的不同维度,互补性很强。图3:三个归因统计量之间的两两斯皮尔曼相关性,在BridgeAD、UniAD和GenAD上分别展示。所有非对角线条目绝对值不超过0.12。4. 实验效果惊人:碰撞预测AUROC达0.77,且能泛化到未见场景
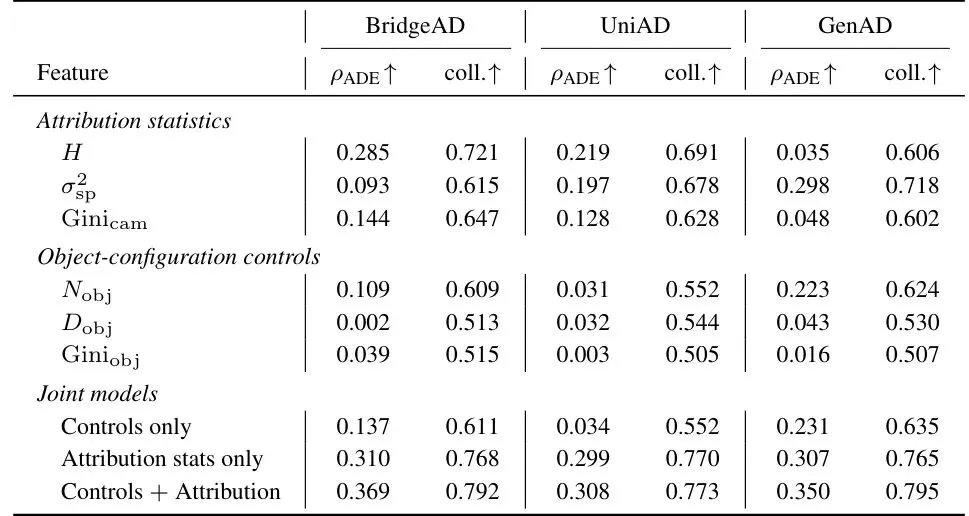
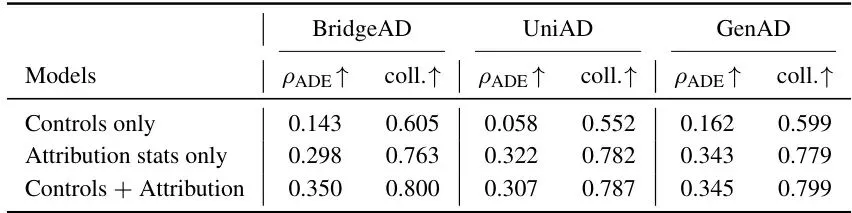
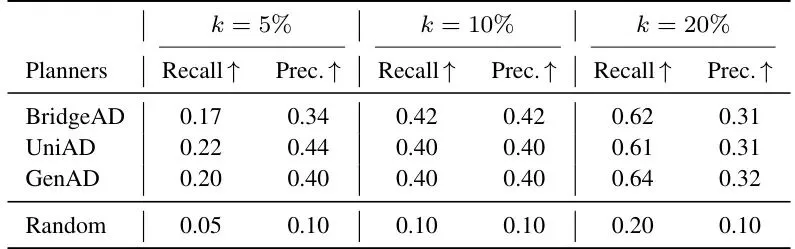
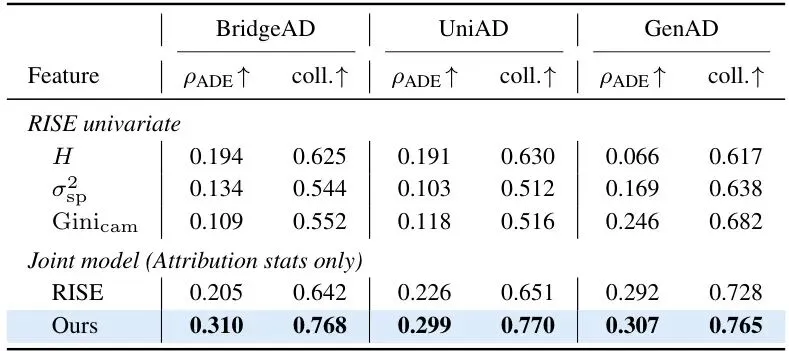
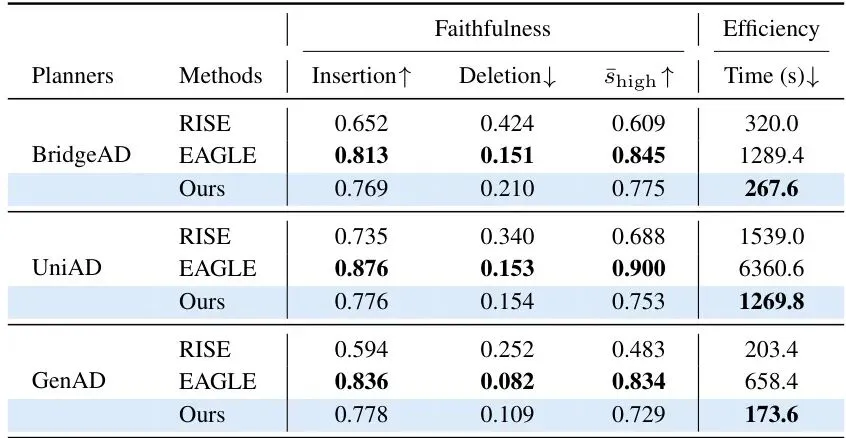
论文在 nuScenes 验证集上对三种代表性端到端规划器(BridgeAD、UniAD、GenAD)进行了全面测试。风险指标有两个:轨迹误差(平均位移误差 ADE)作为连续风险指标,碰撞(collision_any)作为二分类指标。他们用三个归因统计量作为特征,对ADE做岭回归,对碰撞做逻辑回归,评估斯皮尔曼相关系数和AUROC。表1:归因统计量与规划风险之间的关联。ρADE表示与ADE的斯皮尔曼相关系数,coll.表示对碰撞的AUROC。可以看到,单个统计量中,归因熵 H 在 BridgeAD 和 UniAD 上表现最好,视图内空间方差 σ²sp 在 GenAD 上领先,跨相机基尼系数虽然弱一些但方向一致。更关键的是,三个统计量联合起来(Attribution stats only)在三个规划器上表现几乎相同:ρADE 约为0.31,碰撞AUROC约为0.77。这说明归因信号本身携带了与风险相关的信息。而且,这种关联不是场景目标布局的替代表述。论文设计了三个与归因统计量结构匹配的控制变量(目标数量 Nobj、目标空间散布 Dobj、跨相机基尼 Giniobj),单独用这些控制变量预测风险时效果很差(碰撞AUROC仅为0.55-0.64),而加入归因统计量后AUROC提升到0.77-0.80,说明归因信号提供了无法从目标布局中获得的额外信息。更让人兴奋的是泛化测试。论文将 nuScenes 的150个场景按80%/20%随机分割,在训练场景上拟合模型,在未见过的场景上评估。结果如下:表2:80%/20%场景分割下三个联合模型的跨场景预测能力,在20次随机分割上平均。联合归因统计量在未见场景上依然保持 ρADE 约0.30-0.34,碰撞AUROC约0.76-0.78,几乎没降!而仅用控制变量的模型直接掉到接近随机水平。这说明归因信号具有很好的跨场景泛化能力。进一步的,论文还测试了在持有场景中识别高ADE样本的能力(Table 3):表3:在持有场景中按三个预算水平识别高风险样本。Random是分析均匀采样基线。当预算为10%时(与高风险样本的基础概率一致),Recall和Precision都达到0.40-0.42,是随机基线的4倍。这意味着你可以用这个信号来筛选出最可能出错的样本,做进一步分析。为了验证这些信号不依赖于特定的归因方法,论文用另一种归因方法 RISE 替换了层次化归因,重新计算三个统计量。结果(Table 4)显示:表4:归因图消融。用RISE替换提出的层次化归因,保持相同的统计量、度量标准和符号约定。用RISE得到的信号虽然弱一些(AUROC在0.64-0.73之间),但方向一致,说明风险信号不是某个特定归因算法的产物,而是归因分布本身固有的特性。最后,论文还比较了不同归因方法的忠实度和效率(Table 5):表5:不同归因方法之间的忠实度和效率。所有方法共享相同的区域划分和掩膜操作。本文提出的层次化归因在忠实度上远超RISE,接近精确贪婪搜索(EAGLE),但在效率上却是最快的(甚至比无搜索的RISE还快一点点,因为RISE需要大量随机掩膜前向传播)。在GenAD上,本文方法每样本仅需173.6秒,而EAGLE需要658.4秒,RISE需要203.4秒。5. 局限性讨论:尚不支持实时监控,但开辟了归因用于风险评估的新方向
目前的方法还不能做到实时监控——计算一次归因图需要大约几分钟(在GPU上),因此无法在行驶过程中在线使用。但它的核心价值在于离线分析:可以用它来筛选大量数据中的高风险场景,进行针对性验证或数据增强。而且,这是第一篇系统性地证明归因图可以用于规划风险预测的工作,为后续研究开辟了一个全新方向。未来如果能设计出更高效的归因近似方法,或者直接用注意力头来近似归因,或许能实现在线风险预警。龙迷三问
这篇论文解决什么问题?这篇论文要解决端到端自动驾驶规划器的可解释性和风险预测问题。它提出可以用归因图(attribution map)来揭示规划器依赖哪些视觉区域输出轨迹,并且证明归因图的分布特征(熵、方差、基尼系数)本身就能作为风险预警信号,比如预测会不会发生碰撞。
文章中的SLICO超像素是什么意思?SLICO是简单线性迭代聚类(Simple Linear Iterative Clustering)的优化版本,是一种图像分割算法。它将图像分割成大小相近、形状不规则的超像素块,每个超像素内的像素在颜色和空间上比较一致。在这篇文章中,SLICO用于将每一帧相机图像分割成许多小区域(subregions),作为归因分析的基本单元。
什么是归因图的忠实度(faithfulness)?忠实度是指归因图反映模型真实决策依据的程度。一个高忠实度的归因图,当保留高归因区域时,模型输出应该基本不变;当移除高归因区域时,模型输出应该大幅改变。论文用了插入(Insertion)和删除(Deletion)AUC以及Shigh等指标来衡量。层次化归因在忠实度上远高于随机采样的RISE,接近最优的EAGLE。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★✰✰
将归因从“事后解释”拓展到“风险预测”,想法新颖。三个统计量的设计合理且互补。但本质上还是对现有归因技术的应用,并非开创性理论突破。实验合理度:★★★★★
实验极其扎实。在三种不同架构的规划器上验证,控制了场景目标布局等混淆变量,做了跨场景泛化测试,还换了归因方法做消融。置信区间、多重随机分割都交代得很清楚。学术研究价值:★★★★✰
开创了归因用于规划风险评估的新方向,为后续如何设计更高效的归因-风险连接提供了基准。论文的统计量设计可以启发其他多传感器任务的风险监测。稳定性:★★★✰✰
归因计算本身对超参数(如粗区域大小、权重λ)比较敏感,但论文没有深入讨论鲁棒性。不过三个统计量在不同归因方法下趋势一致,说明信号本身是稳定的。适应性以及泛化能力:★★★★✰
在三种不同架构上表现一致,跨场景泛化能力好。但仅限于nuScenes数据集,且只测试了开环(open-loop)设置,闭环(closed-loop)泛化未知。硬件需求及成本:★★✰✰✰
计算归因图需要大量前向传播(尽管做了粗到细优化),每样本仍需数分钟,不适合实时部署。但作为离线分析工具是可以接受的。复现难度:★★★✰✰
方法描述清晰,算法流程详细,但需要了解SLICO分割和端点轨迹规划器的前向过程。论文没有提供开源代码,一定程度上增加了复现门槛。产品化成熟度:★★✰✰✰
目前属于研究原型,离产品化还有距离。主要瓶颈在计算速度。未来如果有更高效的归因近似方法,可以集成到数据平台中做自动高风险场景挖掘。可能的问题:论文对归因统计量与风险的因果机制探讨不足,只是发现了相关性。另外,风险代理指标(ADE和碰撞)本身有噪声,归因信号与它们相关但不代表能真正检测到所有风险场景。[1] Hu, Y., et al. Planning-oriented autonomous driving (UniAD). CVPR 2023.[2] Jia, X., et al. BridgeAD: End-to-end interactive driving with bridging attention. CoRL 2023.[3] Li, J., et al. GenAD: Generalizing end-to-end driving. NeurIPS 2023.[4] Petsiuk, V., et al. RISE: Randomized Input Sampling for Explanation of Black-box Models. BMVC 2018.[5] 原论文链接:https://arxiv.org/pdf/2605.06264v1.pdf*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

归因图还能拿来当安全信号?风险预测新范式,扫码加群和龙哥一起聊聊~ 🚀
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 端到端规划+上海+中山大学+小明),根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
