Filecoin在自动驾驶与机器人数据标注中的定位
- 2026-05-10 14:55:15
引言
自动驾驶汽车和先进机器人技术依赖于机器感知和解读物理世界的能力。为了训练这些系统,企业从摄像头、激光雷达及其他传感器中收集了海量的原始数据。随后,必须对这些数据进行标注,以便模型能够准确地学习识别物体、运动轨迹、距离、路况、障碍物以及其他现实世界的信号。
这正是数据标注公司发挥作用的地方。在自动驾驶和机器人领域,它们的核心职责并不仅仅局限于对少量图像进行打标处理。其更深层次的价值在于如何实现海量数据集在长期维度下的摄入、组织、留存与检索。
数据摄入 (Ingesting):从自动驾驶或机器人团队接收海量原始数据集,例如路测视频、激光雷达文件、摄像头馈送数据以及其他机器捕获的数据。
数据组织 (Organizing):对数据进行分类整理,使其具备可操作性。例如,按车辆行驶记录、地理位置、传感器类型、场景、项目、边缘案例或标注状态进行划分。
数据留存 (Retaining):在完成首次标注后继续保留数据。这些数据在后续的质检(QA)、重新标注、模型再训练、审计或处理罕见的边缘案例时可能仍需使用。
数据检索 (Retrieving):在需要时调取历史数据,例如重新查看夜间行人片段,或核查已完成标注集背后的原始序列。
以此视角来看,自动驾驶与机器人的数据标注不仅是一项标注任务,更是一个数据处理与存储的挑战。在本文中,我们将重点探讨影响该细分领域的三个现状:
数据规模庞大:自动驾驶与机器人标注所涉及的数据集规模和体量,远超大多数人的想象。 工作流高度复杂:针对视频、激光雷达及多模态数据的标注,其复杂程度远高于标准的标注工作流。 信任超越存储:在大规模应用场景下,归档数据的核心挑战将从“如何存储”演变为“如何建立信任”。
最后,我们将总结 Filecoin在这一技术栈中的定位,以及为什么对于那些需要长期保持持久性、具备经济效益的可检索性、且随时间推移依然真实可信的留存数据而言,Filecoin正变得愈发不可或缺。
1. 数据集规模之大、体量之重,远超初见
理解自动驾驶与机器人标注的首要一点是:其工作流始于海量的机器生成原始数据。在标注工作正式开始前,团队就已经需要处理庞大的视频和传感器数据,并完成上传、组织以及评审准备工作。此时,挑战已不再仅仅是“如何标注”,而演变成了从源头开始搬运和管理这些大体量数据集的运维实操问题。
“自动驾驶汽车(AV)正在演变成为移动计算平台,配备了强大的处理器和多种传感器,产生着海量的异构数据(Heterogeneous Data),例如每天产生的数据量可达 14 TB。” —— 摘自 arXiv 2025 年 11 月发表的AVS 论文。
这绝非仅是理论上的担忧。开发自动驾驶功能的电动汽车制造商 Rivian(https://rivian.com/)已经从运营角度描述了这一难题。在 2025 年的一项 AWS 案例研究中(https://aws.amazon.com/blogs/industries/aws-professional-services-and-bmw-collaborate-to-optimize-petabyte-scale-storage-costs-for-automated-driving-data),AWS 表示Rivian 的数据采集测试车队每天产生数以 TB 计的传感器和摄像头数据,这给数据上传、存储和处理带来了严峻挑战。
宝马(BMW) 则是另一个“存储成本介入工作流”的典型案例。2025 年,AWS 披露其正与宝马合作构建一个 PB级(Petabyte-scale)自动驾驶数据湖,并开发了一种基于访问模式识别记录的方法,以实现更快速的归档。此举的目的不仅是为了存储更多数据,而是为了将活跃度较低的记录更早地迁移到成本更低的归档存储中——通常在数据到达几天内即可完成迁移,而无需等待标准的 30天生命周期转换期。
这一点至关重要,因为甚至在标注、质检(QA)或重新处理开始之前,原始数据的规模就已经极其可观。对于致力于自动驾驶和机器人工作流的团队来说,单是原始数据的体量,就已经让这项工作脱离了“轻量级标注”的范畴,转而变成了一场以存储为中心的数据运维战。
2. 视频、激光雷达及多模态标注的难度远超标准标注
第二个现状是,自动驾驶与机器人工作流中的“标注”并非单一任务。根据模型学习需求的不同,各类系统所需的标注类型也大相径庭。有些任务涉及在长视频序列中识别物体,有些涉及对三维激光雷达数据进行标注,还有些则要求将同一场景下多个传感器的视角进行对齐。
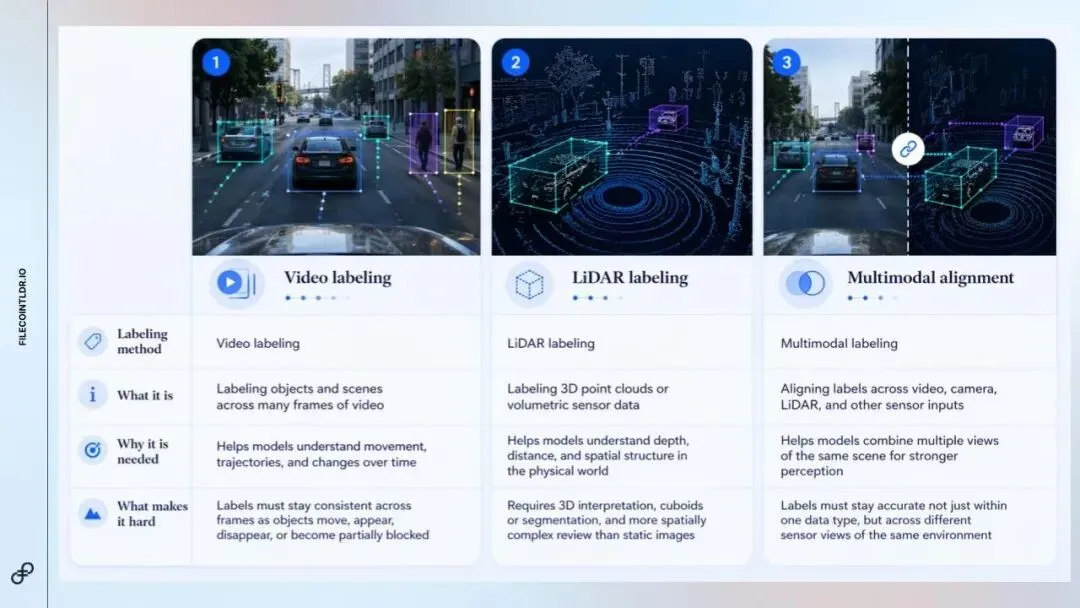
综合来看,这些方法使得此类工作比标准标注更具挑战性:
视频标注:要求具备“时序一致性”。
激光雷达标注:要求具备三维空间理解能力。
多模态工作流:要求标注信息在同一环境的不同传感器视角之间保持对齐。
例如,Waymo 的公开感知数据集(https://waymo.com/intl/fil/open/data/perception/)包含了摄像头和激光雷达数据,并涵盖了 2D/3D 追踪以及 3D 语义分割(3D semantic segmentation)等任务。
这有力地提醒了我们:该领域处理的绝非简单的一次性标注任务,而是更丰富的感知数据。这些数据通常需要更专业的工具、更严格的审核,并需要对同一底层数据集进行反复的回溯与调用。
因此,存储层在这里的重要性远高于轻量级标注工作流。因为数据往往需要长期保持可用,以备评审、重新标注以及未来的模型迭代之需。
3. 在大规模场景下,归档数据将变成一种“未经验证的负债”
一旦自动驾驶与机器人数据集开始堆积,挑战将不再仅仅是“存放在哪里”,而在于团队是否能够信任这些数据在未来需要时依然可用。
历史数据虽然并不总是处于活跃状态,但极少会变得毫无用处。团队可能需要还原过去的视频片段、激光雷达扫描件、传感器日志或已标注的数据集,用于质检(QA)、重新标注、模型迭代、边缘案例分析、审计支持或事故调查。
这就产生了一个“恢复信心鸿沟”(Restore Confidence Gap):即“主观认为归档数据安全”与“能够客观验证数据依然完整、可恢复且能溯源至正确原始素材或版本”之间的差距。这一鸿沟至关重要,因为许多系统将归档的完整性视为一种“默认假设”——即数据写入、留存,就理应在以后可用。但在高风险的自动驾驶和机器人工作流中,团队最终可能需要证明:
原始数据是否可以被还原?
还原的数据是否与最初存储的数据一致?
它是否关联到了正确的版本、标签或模型工作流?
随着时间的推移,它是否依然保持完整无损?
正是在这种背景下,存储不再仅仅是一个“成本中心”。虽然成本、检索费和检索速度依然重要,但更深层次的运营问题在于信心。如果归档数据难以验证、恢复昂贵或在需要时变得不可靠,那么再便宜的存储也毫无意义。
一个简单的对比可以使这一问题更加具体。考虑将 AWS S3 标准存储与 Akave Cloud(一个由 Filecoin 提供后端支持、兼容 S3协议的存储服务,https://akave.com/)进行对比:

Akave Cloud 展示了如何将基于 Filecoin的存储封装在熟悉的云服务界面中。但其核心优势不仅在于成本,更在于验证。Filecoin的设计围绕“基于证明的模型”展开——即数据的存在和完整性在存储期间是可以随时校验的,而不仅仅是在上传后进行盲目假设。
对于自动驾驶和机器人标注而言,这种区别意义重大。内容寻址和溯源可以帮助将数据精准关联到特定文件、版本或数据集状态。此外,去中心化存储网络还能降低对单一供应商或内部系统的依赖。
因此,问题的核心不仅在于存储规模扩大带来的难度,而在于:除非团队能够验证归档数据依然可检索、完整且可用,否则这些数据就会变成一种“未经验证的负债”。这正是Filecoin 的价值所在:它解决的是“证明”问题,而不仅仅是“存储”问题。
总结
综上所述,当我们将自动驾驶与机器人标注的工作流视为长期数据基础设施挑战,而非单纯的标注任务时,Filecoin 的重要性便愈发凸显。
每一段视频剪辑、激光雷达扫描、传感器日志以及标注好的边缘案例,在首次模型训练运行结束后的很长一段时间内依然具有极高的价值。团队可能需要回溯旧标签、重现过去的数据集、调查模型行为,或为了安全、质检和审计目的而保留历史存证。在此背景下,问题的核心不再仅仅是数据存放在何处,而是团队是否能够可靠地(且满怀信心地)还原数据。
这正是 Filecoin 发挥特定作用的地方。它的目的并非取代自动驾驶或机器人数据技术栈中的每一个环节,而是为数据留存层提供支撑——在这一层,数据的持久性、可检索性和可验证性至关重要。通过基于证明的存储、内容寻址以及像 Akave Cloud 这样由Filecoin 提供后端支持的服务,团队可以将长期数据留存从一种“盲目假设”转变为一种可以随时间推移进行随时检查与验证的确定性资产。
随着自动驾驶和机器人数据集的持续增长,那些能够管理好其数据根基的团队将占据竞争优势。未来不仅取决于谁能更快地标注数据,更取决于谁能更有效地保存、还原并信任那些模型赖以生存的核心数据。
持续探索 Filecoin
关注 FilecoinTLDR(https://x.com/FilecoinTLDR),获取生态深度解析与最新动态。 加入 Filecoin Discord(https://discord.com/invite/filecoin?utm_medium=social&utm_source=linktree&utm_campaign=filecoin+discord),与全球社区建立联系。 开启 Filecoin Quest Hub (https://filecointldr.io/quest)任务之旅,学习知识、完成任务并深度参与。 订阅通讯(https://filecointldr.io/signup),获取未来深度文章与洞察。
欢迎了解更多内容👇:
FIL:作为去中心化存储领域的开创者和龙头项目,市场份额如何变化
关于Filecoin:
Filecoin Network是一个旨在为人类信息打造分布式、高效且强大基础的开源项目。其构建的并非只是一个存储网络,而是将云存储转变为算法市场的全球性去中心化存储网络。存储提供商通过提供可靠服务获得激励,用户则以极具竞争力价格享受安全、可验证的数据存储。
获取更多信息:https://filecoin.io
如果这篇内容对你有用,喜欢的话,点个赞,分享给更多人吧~
素材来源官方媒体/网络新闻
严正声明:请读者严格遵守所在地法律法规,本文不代表任何投资建议。
风险提示与免责声明:
发布的所有内容,包括但不限于市场分析、数据测算、产品介绍及观点分享,均仅供信息参考与交流学习之用,不构成任何形式的投资建议、承诺或保证。
投资涉及市场、信用、流动性等多种风险,可能导致本金损失。您应基于自身独立判断进行决策,并自行承担全部风险与后果。
我们不对任何因依赖本账号内容进行投资所导致的直接或间接损失承担责任。请您理性投资,谨慎决策。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 纯电轿车底价被击穿!极狐S3充电版9.28万,续航最高660km且电耗极低;换电版仅需6.48万,99秒满电复活彻底治愈你的里程焦虑
- 2.0T燃.油.SUV 超2.8米轴.距. 双14.6.英寸大屏 12万出头拿.下?
- 38万左右落地车型冠军:燃油SUV守擂成功,月销依旧有14550台
- 广州到五家渠轿车托运 广州到五家渠物流公司 五家渠到广州轿车托运
- 丰田这款7万级SUV,一年油费不到6000?30天热销的秘密我找到了!
- 东风奕派M8:大六座SUV市场迎来硬核玩家
- 10万出头买B级插混轿车!秦L DM-i智驾版真的把性价比焊死了
- 中国自动驾驶新突破!不用司机跑赢特斯拉,北京车展首发600米神车
- 限时置换价14.98万起!旗舰大六座SUV华境S上市,华为全家桶普及
- 20万出头买纯电SUV,小鹏G7是好选择吗?你得先想清楚自己能不能真用上它的智能
