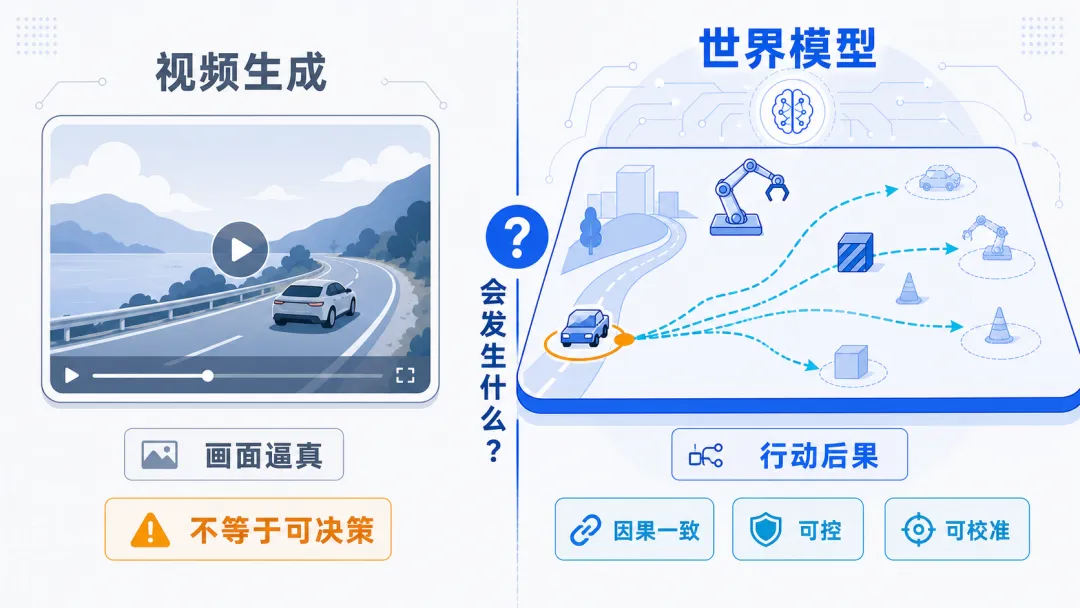
如果说大语言模型擅长“接下一句话”,世界模型更像是在回答另一个问题:
如果我现在这样做,接下来会发生什么?
这听起来像一句很朴素的话,但它正是机器人、自动驾驶、游戏 AI 和具身智能绕不开的核心能力。一个系统如果只能识别眼前画面,却不能预判动作的后果,就很难真正做决策。它也许能“看懂”杯子在哪里,却不知道伸手太快会把杯子碰倒;能“生成”一段驾驶视频,却未必知道前车急刹时自己应该怎样安全减速。
世界模型不是某一个算法,而是一类让 AI 学会预测、想象和决策的技术范式。它的目标不是复制整个宇宙,而是学出一个对任务有用的“内部世界”:看见现在,压缩关键信息,推演未来,然后选择更好的行动。
误区解释
今天讨论世界模型,最容易误解的地方有三个。
第一,世界模型不等于视频生成模型。视频生成可以让未来画面看起来更真实,但“看起来真”不代表“能指导行动”。对机器人和自动驾驶来说,更重要的是因果关系是否可靠:我踩刹车,车距会怎样变化;机械臂往左推,物体会不会滑落。
第二,世界模型不一定要重建完整世界。很多成功算法只保留对任务有用的信息。例如 MuZero 并不试图还原真实画面,它只学习哪些信息对搜索和赢得游戏有用。
第三,世界模型的核心瓶颈不是短视频是否逼真,而是长期推演是否稳定、可控、可校准、能安全用于真实决策。模型一旦在“脑内模拟”中犯错,策略就可能学会利用模型漏洞,而不是学会真实世界规律。
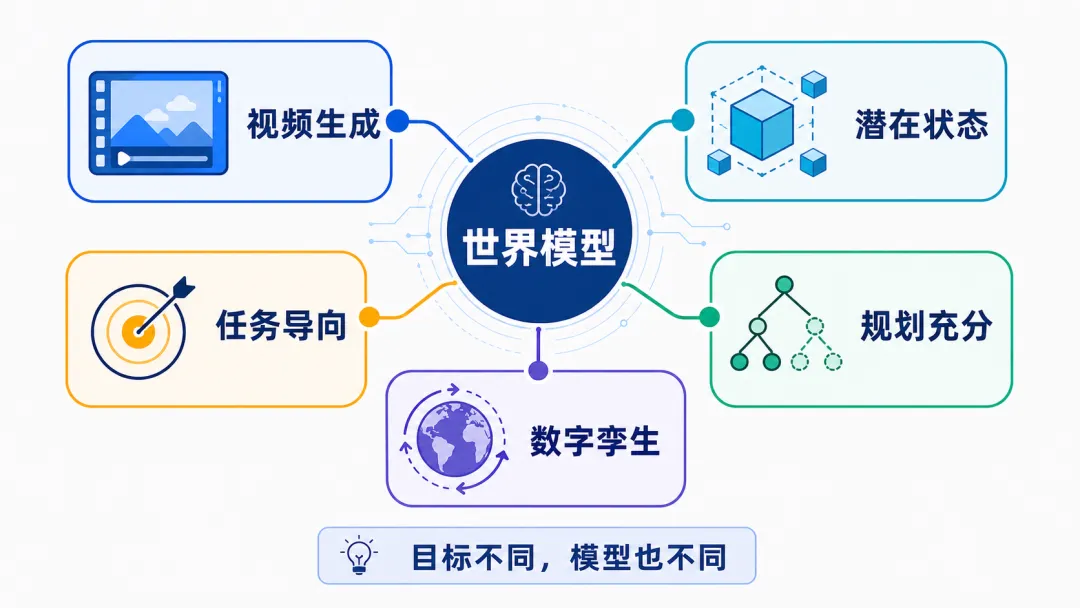
什么是世界模型?
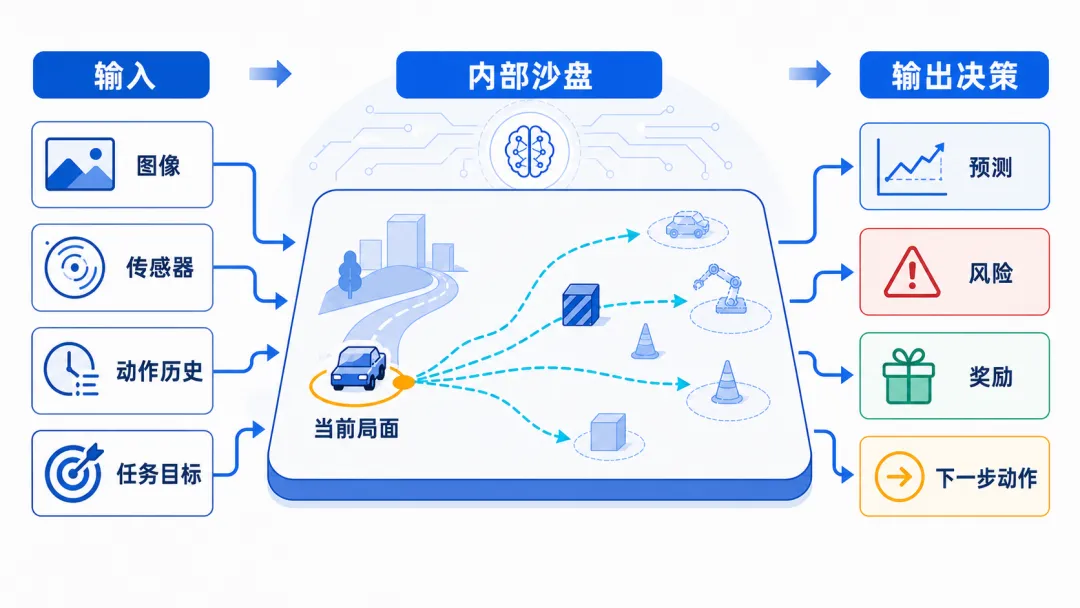
可以把世界模型想成 AI 内部的“沙盘”。
真实世界给它输入:图像、视频、传感器、动作历史、任务目标。世界模型把这些信息压缩成一个更小、更容易推演的状态。之后,它会回答一连串问题:
这就是“预测”和“想象”的来源。
但这里有个关键点:世界模型学到的不是百科全书式的完整世界,而是对行动有帮助的世界。下棋时,它不需要理解棋盘木纹;驾驶时,它不需要生成路边每片树叶的细节;机器人抓杯子时,它最需要知道杯子、手、桌面、摩擦和碰撞之间的关系。
所以,世界模型比传统的“环境模型”更宽。传统环境模型通常关心“状态如何转移、奖励是多少”;世界模型还可能关心视觉、语义、物理、几何、多主体互动,甚至用来生成训练数据。数字孪生则更进一步:它不仅要能模拟,还要尽量和现实世界保持同步,并支持持续校正。
为什么世界模型突然变重要?
因为 AI 正在从“识别和生成”走向“行动”。
只会识别的 AI,可以告诉你前方有障碍物;会做世界模型的 AI,还要能预判自己转向、刹车、加速之后,障碍物和车辆会怎样变化。
只会生成视频的 AI,可以画出一个机器人移动的片段;会做世界模型的 AI,还要知道这个动作在物理上是否成立,机器人会不会失衡,物体会不会被推到桌子外面。
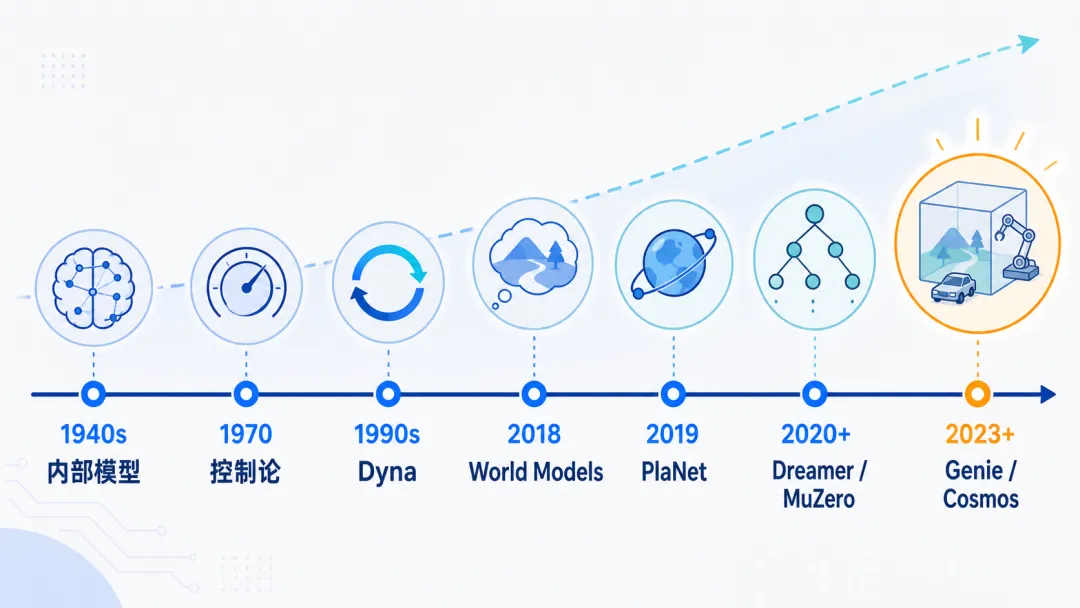
这条路线其实并不新。它背后有一条很长的发展脉络:
| | |
|---|
| | |
| | |
| | |
| | |
| | |
| | 世界模型开始在游戏、控制和机器人任务中展现效率优势 |
| GAIA-1、DriveDreamer、Genie、DreMa、Cosmos | 世界模型扩展到自动驾驶、交互环境、数字孪生和 physical AI |
这条线的变化可以概括为一句话:
从“控制需要模型”,走向“AI 需要一个可推演、可规划、可校正的内部世界”。
它到底怎么工作?不用公式讲清楚
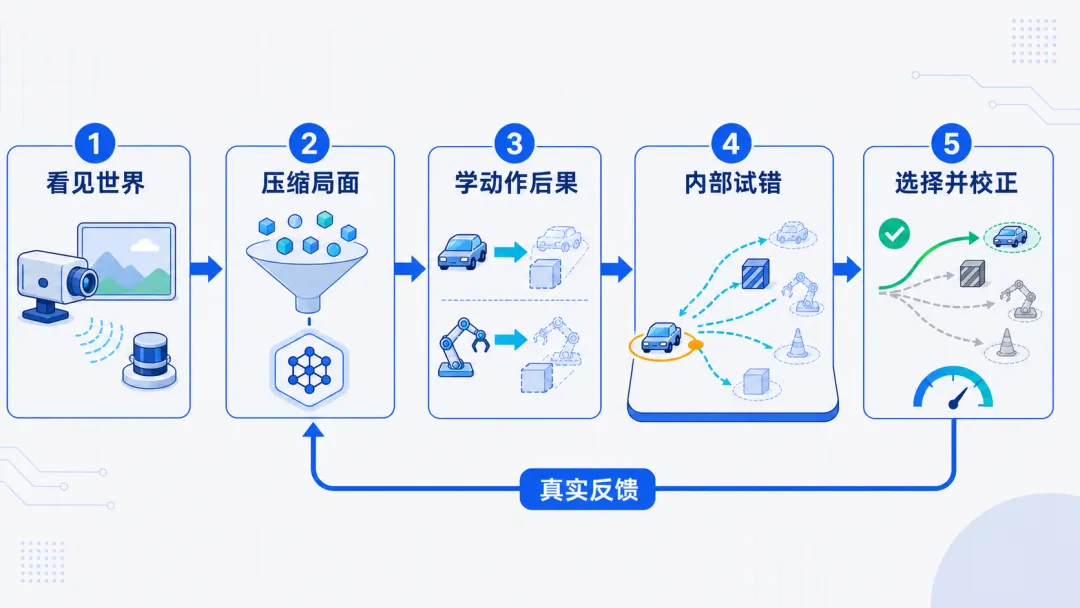
一个典型世界模型系统,大致分成五步。
第一步:看见世界
模型先接收观测。观测可以是摄像头画面、游戏屏幕、雷达点云、机器人关节状态,也可以是文本目标或导航指令。
这里的问题是:原始观测通常太大、太乱。直接拿像素做规划,既慢又容易被无关细节干扰。
第二步:压缩成“局面”
世界模型会把高维观测压缩成一个内部状态。这个状态不一定能被人直接读懂,但它应该保留对任务有用的信息。
比如机器人抓杯子时,内部状态最好包含:杯子在哪里,手在哪里,桌面在哪里,当前动作可能导致什么接触。它不需要完整记住桌布花纹。
这一步的关键是平衡:信息太少,模型无法决策;信息太多,模型很难稳定预测。
第三步:学习动作会怎样改变未来
世界模型不是只看静态画面。它要学习“动作”和“后果”之间的关系。
例如:
这就是世界模型和普通感知模型的区别。感知模型回答“现在是什么”;世界模型还要回答“如果我这样做,接下来会怎样”。
第四步:在内部世界里试错
有了内部模型,AI 就可以先在“脑内”试几种动作,而不是每次都去真实世界冒险。
这对机器人尤其重要。真实机器人试错很贵,也可能损坏设备;自动驾驶更不可能靠真实事故来学习。世界模型提供了一种更安全、更省样本的训练方式:先模拟,再行动。
第五步:选择动作,并不断校正
世界模型最终要服务于决策。系统会比较不同动作序列的结果,选择最有希望的一步先执行。执行之后,再拿真实反馈修正模型。
所以,一个靠谱的世界模型不是“一次训练完就万事大吉”,而是应该在真实交互中持续被验证、被校准、被约束。
五条主流技术路线
世界模型不是一条单线技术。按工程目标看,今天大致有五类路线。
| | | |
|---|
| | | |
| | | |
| | | |
| | | |
| 用大规模视频、多模态、几何和物理信息构造可交互世界 | | |
这几条路线不是互斥的。未来更可能出现混合系统:既有大模型的生成能力,也有几何和物理约束;既能合成场景,也能服务闭环控制。
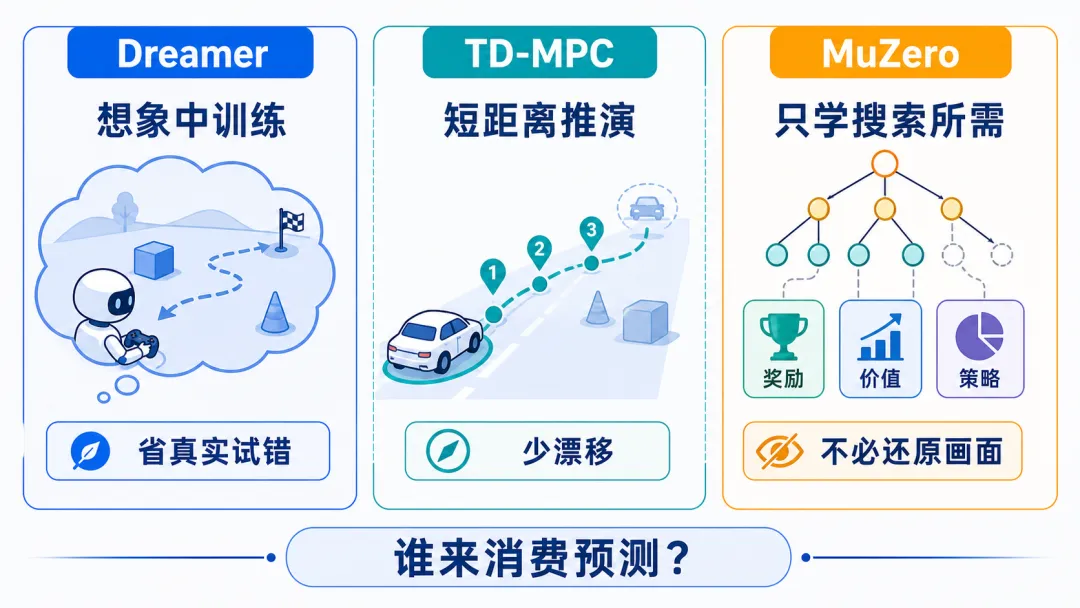
Dreamer、TD-MPC、MuZero 的差别
如果只记三个代表算法,可以这样理解。
Dreamer:在想象中训练行动者。
Dreamer 先学习一个内部世界,再让智能体在这个内部世界里“想象”很多未来轨迹。它不必每一步都去真实环境中试错,因此样本效率更高。它的核心思想是:真实经验很珍贵,能在内部世界里练的,就尽量先在内部世界里练。
TD-MPC:短距离推演,加上终点判断。
TD-MPC 更像一个务实的规划器。它不会幻想特别长的未来,而是在内部状态里看短短几步,再估计走到某个局面之后大概值不值得。这样既控制了计算成本,也减少了长时间推演带来的误差。
MuZero:不还原世界,只学会搜索所需的信息。
MuZero 的厉害之处在于,它不需要知道真实规则的完整形式,也不需要重建画面。它只学习搜索最需要的三类东西:走一步会得到什么回报,下一步有哪些动作值得考虑,这个局面大概有多好。
这三者的分歧,不在于“要不要预测未来”,而在于:
- 未来是在像素里预测,还是在压缩后的内部状态里预测?
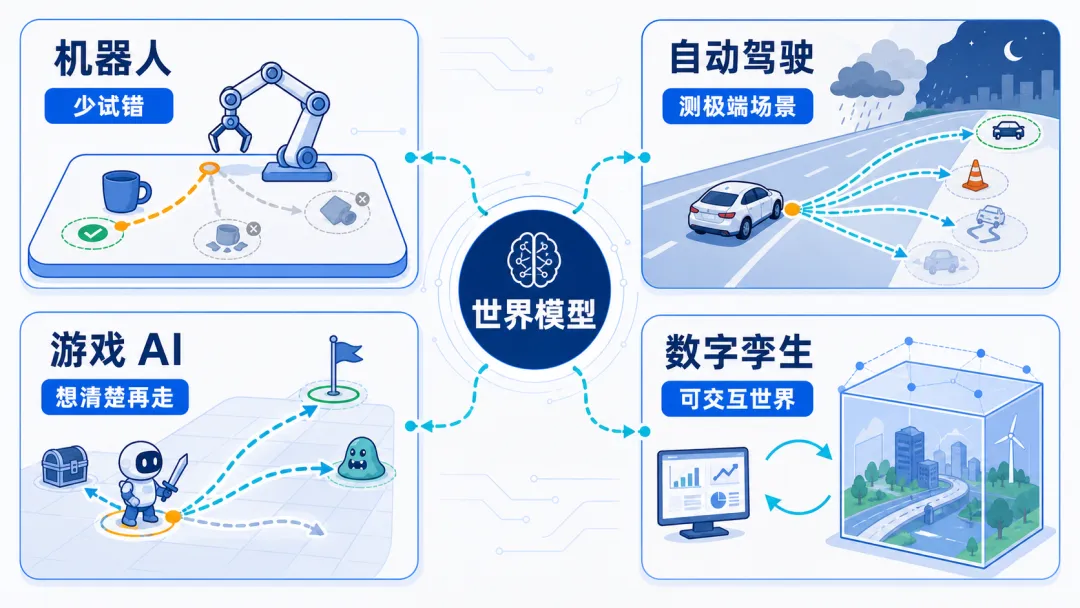
应用场景:世界模型最先改变哪里?
机器人:少摔几次,少试几次
机器人学习最怕两件事:真实试错太慢,失败代价太高。
世界模型的价值,是让机器人先在内部世界里预演。比如推物体、抓取、行走、避障,模型可以先推演动作后果,再选择更稳妥的动作。DayDreamer 这类工作展示了一个方向:让真实机器人通过较少的在线交互学到可用策略。
但机器人场景也最残酷。接触、摩擦、形变、遮挡、传感器噪声,都会让世界模型出错。因此真实机器人往往需要把世界模型和安全探索、示范数据、约束规划结合起来。
自动驾驶:生成场景还不够,必须能闭环验证
自动驾驶非常需要世界模型。因为真实路测覆盖不了所有极端情况,世界模型可以生成雨天、夜间、急刹、加塞、施工、鬼探头等场景,用来训练和测试系统。
但自动驾驶也最容易暴露世界模型的短板:一个视频看起来像真实道路,不代表车辆运动、交通规则和多车互动都合理。真正有用的驾驶世界模型,必须同时满足可控、长时一致、多主体合理和安全可验证。
游戏 AI:从“试很多次”到“想清楚再走”
游戏是世界模型最早展示威力的地方之一。
World Models 证明了智能体可以先学习环境的内部动态,再在“梦境”中训练控制器。MuZero 则进一步说明:模型不必重建完整环境,只要学到足够支持搜索的信息,也能在围棋、国际象棋、将棋和 Atari 游戏中取得强表现。
游戏的好处是反馈清晰、环境可重复、安全成本低,所以它一直是世界模型的重要试验场。
仿真与数字孪生:从生成视频到生成可交互世界
Genie、DreMa、Cosmos 这一类工作,把世界模型推向更大的方向:不是只让 AI 预测下一帧,而是构造一个可交互、可控制、可用于训练和验证的世界。
这里的目标不只是“生成好看的未来”,而是让模型成为 physical AI 的基础设施:提供合成数据,构造仿真环境,评估策略风险,帮助机器人和自动驾驶系统在真实部署前先经过大量检验。
最难的部分:不是想象,而是想得对
世界模型听起来很美,但真正难的地方也很清楚。
第一,长期预测会漂。
一步预测错一点,十步之后可能完全偏离真实世界。对需要长程规划的任务来说,这是非常大的问题。
第二,视觉真实和物理正确经常冲突。
有些模型能生成很漂亮的视频,但物体运动不守物理;有些专用模型更符合运动规律,但画面没那么惊艳。对决策系统来说,后者常常更有价值。
第三,真实数据贵,而且失败有风险。
机器人坏一次可能很贵,自动驾驶更不能靠事故学习。世界模型必须在不完美数据下保持保守和可靠。
第四,世界并不总是完全可见。
被遮挡的车辆、看不见的抓取接触、其他人的意图,都会让模型面对不确定性。一个好模型不能只给出“最可能发生什么”,还要知道自己什么时候不确定。
第五,评估标准还不统一。
只看视频指标,很容易把生成能力误当成决策能力。不同论文的任务、数据、预测时长和控制协议也常常不同,导致结果难以直接比较。
第六,成本正在上升。
世界基础模型需要大数据、大算力和复杂工程。它们可能成为平台级能力,但也会提高研究和应用门槛。
怎么判断一个世界模型是否真的有用?
不要只问“它生成的视频像不像”。
更好的评估应该分四层看:
| |
|---|
| |
| |
| |
| 它在真实机器人、真实驾驶或高风险场景中是否可校准、可解释、可约束? |
这也是为什么 WorldModelBench、WorldPrediction、DrivingGen 等新评测开始强调物理一致性、可控性、长期规划和驾驶生成质量。世界模型的价值,最终要回到行动结果上,而不是停留在视觉观感上。
如果要做项目,应该怎么选路线?
可以用一个简单判断:
如果目标是闭环控制,优先考虑潜在状态模型或任务导向潜空间模型。
比如 Dreamer、TD-MPC 这一类路线,重点是让模型帮助智能体更省样本地学习行动。
如果目标是合成数据、构造场景或交互环境,优先考虑生成式世界模型。
自动驾驶场景生成、游戏式交互环境、视频条件仿真,更需要多模态和视频生成能力。
如果目标是真实部署,必须加入安全机制和现实校正。
单独一个世界模型远远不够。还需要不确定性估计、约束规划、在线校准、数字孪生、真实环境回查,以及明确的安全边界。
一个务实的实验顺序是:
- 最后再谈长时生成、视觉真实、多模态交互和真实部署。
很多项目失败,不是因为模型完全不会生成,而是因为把顺序做反了:先追求好看的世界,再回头发现它不能指导行动。
安全问题:世界模型也会“想错”
世界模型比静态感知模型更敏感,因为它不只是看世界,还会影响行动。
第一类风险是模型漏洞被策略利用。如果内部世界错误地低估风险,策略可能会在模拟中找到一条“高回报路径”,但这条路径在真实世界里根本不安全。
第二类风险是数据偏差被放大。驾驶世界模型可能继承某些地区、天气、交通习惯和事故样本不足带来的偏差;数字孪生也可能涉及隐私、授权和场景重建合规问题。
第三类风险是潜在状态难解释。很多高效算法学到的是“对任务有用”的内部表示,而不是“人能看懂”的解释。部署时需要额外的可解释工具、反事实测试、不确定性校准和任务化评测。
所以,世界模型越接近真实行动,就越不能只看性能数字。它必须和安全约束、审计机制、数据治理一起设计。
世界模型是可用的预演能力
世界模型最有前景的方向,不是把视频生成器包装成“会思考的世界”,而是把几件事真正结合起来:
当一个模型既能在游戏和仿真里表现出长期策略能力,又能在机器人和自动驾驶中经得住闭环验证,它才真正接近“可用的世界模型”。
换句话说,世界模型的终点不是让 AI 做一场漂亮的梦,而是让它在行动之前,先有能力把后果想清楚。