封面图资源导航
- • 论文链接:https://arxiv.org/abs/2605.05765
- • 项目主页:https://github.com/OPPO-Mente-Lab/X-OmniClaw
- • GitHub Repo:https://github.com/OPPO-Mente-Lab/X-OmniClaw
- • APK下载:https://github.com/OPPO-Mente-Lab/X-OmniClaw/releases/latest
- • 发布机构:OPPO AI Center · Multi-X Team
- • 开源协议:Apache License 2.0
OPPO这次,把AI Agent直接装进了手机里
过去一年,AI Agent被讲得太多了。
有人让它操作电脑,有人让它接管浏览器,有人把它塞进云手机里,让它帮你订票、点外卖、查资料。
但大多数方案都有一个问题:
AI看起来很会干活,但它离你的真实手机还很远。
云手机里的Agent再聪明,也摸不到你的本地相册;电脑端的Agent再强,也调不动你的手机摄像头;网页里的助手再方便,也很难真正跨App替你完成复杂操作。
而这一次,OPPO AI Center开源的 X-OmniClaw,选择了一条更直接的路:
不绕云手机,不装远程环境,直接运行在真实安卓手机上。
简单说,它想做的不是一个“聊天机器人”,而是一个能在手机里真正干活的AI管家。
它能看摄像头,能听语音,能读屏幕,还能跨App执行任务。
这件事,可能会让移动端AI Agent往前走一大步。
01 它到底是什么?
 系统架构图风格配图
系统架构图风格配图X-OmniClaw,是 OPPO AI Center · Multi-X Team 开源的一个安卓端多模态Agent。
它支持 Android 8.0 及以上系统,用户可以直接安装 APK 体验,不需要额外搭服务器,也不需要另开云手机。
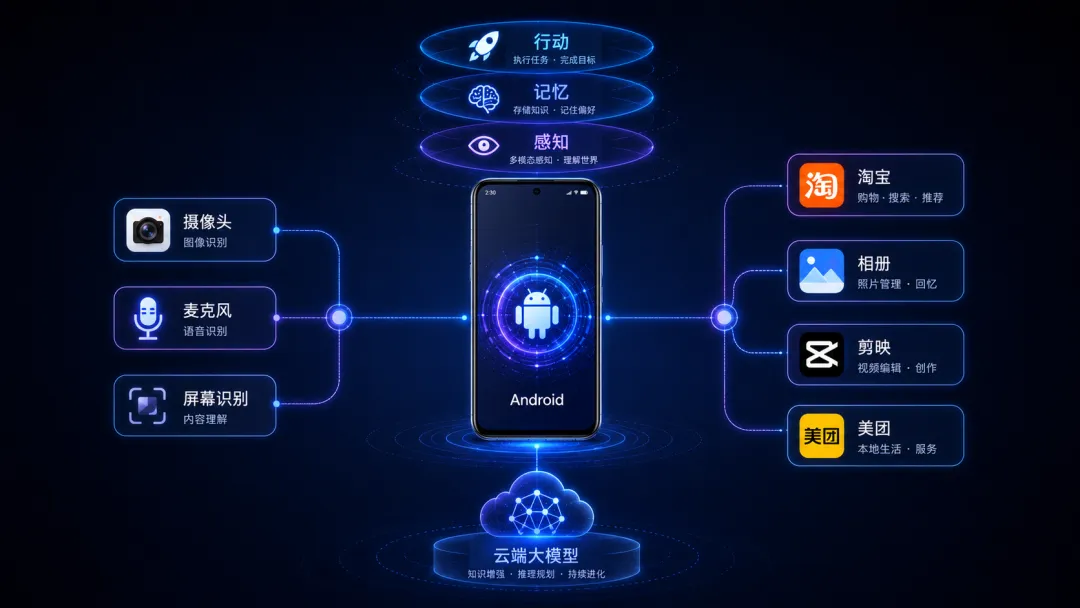
它的核心能力,可以拆成三个关键词:
第一,能感知。它不只看屏幕,还能调用摄像头、麦克风,理解你当前所处的真实场景。
第二,能记忆。它可以记录任务上下文,也可以从本地相册、使用轨迹中提炼长期记忆,方便之后按主题检索和复用。
第三,能行动。它能把一句自然语言指令,拆解成点击、滑动、输入、切换App等一连串安卓操作。
也就是说,它不是只负责“回答你”,而是试图帮你“把事做完”。
这就是 X-OmniClaw 和普通AI助手最大的区别。
普通AI助手停在对话框里;X-OmniClaw想进入手机系统里。
02 最有意思的是:它能连接现实世界和手机App
 真实手机AI管家场景图
真实手机AI管家场景图先看一个很直观的场景。
你拿起手机,对准一瓶矿泉水,然后说:
“这瓶水在淘宝上卖多少钱?”
正常情况下,你需要自己识别品牌,打开淘宝,输入关键词,翻商品列表,再对比价格和销量。
但 X-OmniClaw 的流程是:
它先通过摄像头识别眼前物体;再自动打开淘宝;搜索对应商品;读取搜索结果;最后把价格信息整理给你。
这个过程的关键,不是“识别一瓶水”有多难,而是它把两个世界打通了:
现实世界里的物体和手机App里的操作结果
过去你需要自己从现实走到App里搜索,现在AI可以替你完成这个跳转。
这就是移动端Agent真正有想象力的地方。
它不只是一个问答工具,而像一个能看见现实、理解App、再动手执行的中间层。
04 它还能做题、找照片、剪视频、打开深层页面
X-OmniClaw官方展示的几个典型场景,每一个都指向一个真实痛点。
场景一:屏幕伴侣
你在手机上看题、看页面、看任务,只需要说一句:
“开始做题吧。”
它会结合当前屏幕内容和你的语音指令,理解你到底想让它做什么。
重点在于,它不是单纯听你说话,也不是单纯截图识别。
它会把你说话那一刻的屏幕状态一起纳入理解。
这意味着,当你说“这个怎么选”“帮我继续”“开始吧”这类含糊指令时,它有机会通过屏幕上下文判断你的真实意图。
场景二:相册主题检索 + 一键成片
比如你说:
“帮我找到与鹦鹉主题相关的照片,并一键成片。”
它会先在相册里查找相关照片,再把这些照片归集起来,然后跳转到剪映完成一键成片流程。
这个场景很典型。
因为它不只涉及一个App,而是涉及:
相册检索 → 照片整理 → 剪映导入 → 批量选择 → 视频生成
这是普通语音助手很难稳定完成的长链路任务。
而移动端Agent真正要突破的,正是这种跨App、多步骤、随时可能被弹窗打断的操作。
场景三:录一次,以后一句话直达
很多App都有一个让人头疼的问题:
入口太深。
比如某个秒杀页、活动页、会员页、隐藏功能页,你每次都要点好几层才能进去。
X-OmniClaw提供了一个“行为克隆”的思路。
你先手动操作一遍,它把路径记录下来,变成一个可复用技能。下次你只要说:
“打开美团秒杀。”
它就尝试复现这条路径,直接帮你跳到目标页面。
这个功能听起来不炫,但非常实用。
因为对普通用户来说,真正高频的自动化,不一定是“帮我完成一个复杂项目”,而是:
把每天重复点十几次的路径,压缩成一句话。
05 它和云手机Agent最大的区别:跑在真实手机上
现在很多AI Agent方案,其实是跑在云端虚拟手机里。
这种方式有优势:
上手简单,环境统一,厂商更容易控制执行过程。
但问题也明显:
它访问不到你真实手机里的摄像头、麦克风、本地相册、系统设置。
换句话说,云手机Agent能操作“那台云端手机”,但不一定能真正服务“你手里这台手机”。
X-OmniClaw的路线不同。
它直接装在真实安卓机里,通过本地权限调用系统能力,再结合云端大模型做推理。
你可以把它理解成:
手机是身体,云端大模型是大脑,X-OmniClaw是神经系统。
本地负责感知和执行;云端负责理解和决策;两者合起来,才形成完整的行动闭环。
这条路线的能力边界更大。
因为它真的能触碰你的本地数据和硬件。
但同时,它的挑战也更大:
权限更多,配置更复杂,执行稳定性也更容易受到不同手机系统、App弹窗、后台限制的影响。
06 三大核心能力:看懂、记住、会操作
第一层:全感知
它的输入不只有文字。
它可以接收语音,可以读取屏幕,可以调用摄像头,也可以理解当前App界面。
比如你一边看手机页面,一边按住语音说“帮我处理一下这个”,它需要知道:
你说了什么;你说话时屏幕上是什么;当前页面有哪些按钮、文本和可点击区域;这个任务到底是要回答,还是要真正操作App。
所以它不是简单地把语音转文字,而是做多模态理解。
这也是为什么移动端Agent比普通聊天机器人难得多。
手机界面不是一段干净的文字,而是按钮、图片、弹窗、滑动列表、广告、权限框混在一起的复杂场景。
AI必须先看懂,才谈得上动手。
第二层:全记忆
Agent执行长任务时,很容易遇到一个问题:
做到一半忘了前面干了什么。
X-OmniClaw引入了工作记忆,用来保存当前任务进度、截图证据和操作上下文。
这样即使切换App,或者流程中断,它也有机会继续接上。
更进一步,它还支持长期个人记忆。
比如相册里的照片,可以被整理成结构化语义记录:
这张图里有什么;是什么主题;大概是什么场景;和哪个时间段有关。
这样之后你说“找我上次拍的鹦鹉照片”,它就不是从零开始盲翻相册,而是可以基于已有记忆快速检索。
第三层:全行动
 跨App自动化流程图
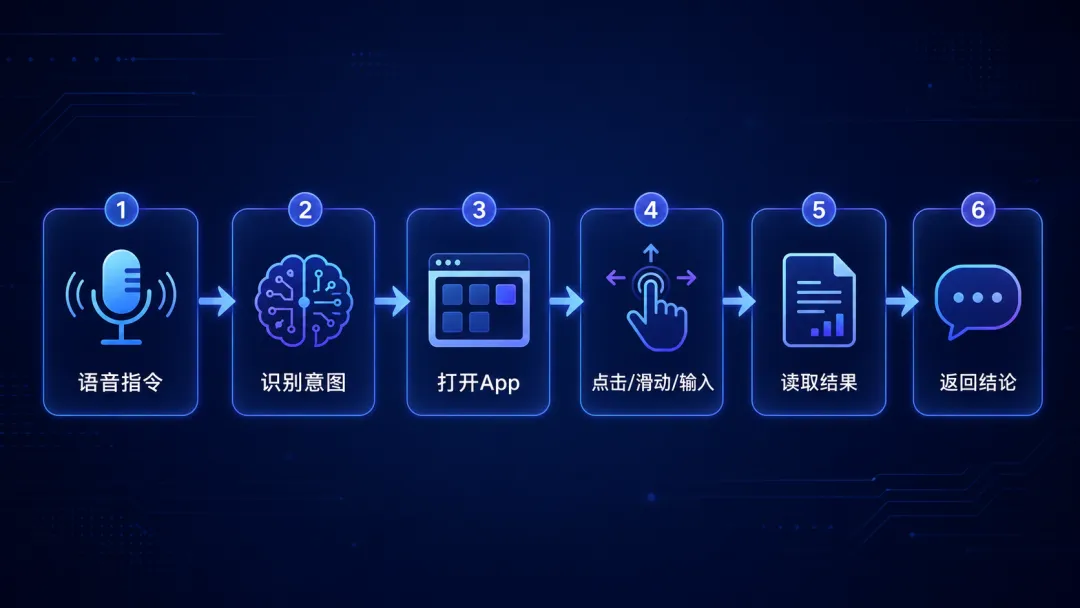
跨App自动化流程图看懂之后,才是执行。
X-OmniClaw执行任务时,大致遵循一个循环:
观察当前页面;理解页面状态;决定下一步动作;执行点击、输入、滑动、切换App;再观察结果;直到任务完成。
为了提高稳定性,它不是只依赖一种界面信息。
一方面,它会使用Android无障碍服务提供的结构化信息;另一方面,它也会结合视觉识别和OCR,处理那些结构信息缺失的页面。
这点非常关键。
因为很多App页面并不“规整”。
有些按钮在XML里不明显,有些广告弹窗是图片,有些活动页全是图形化元素。
如果只靠结构化信息,很容易点错;如果只靠视觉,又容易不稳定。
所以混合识别,是手机Agent落地绕不开的一步。
07 普通用户怎么用?
根据项目资料,X-OmniClaw目前可以直接从 GitHub Releases 下载 APK 安装。
安装之后,需要做几件事。
第一,配置大模型API。它本身不是完全离线运行,推理层需要调用云端模型。
第二,配置语音识别和视觉模型。因为它需要听懂语音,也需要理解截图和摄像头画面。
第三,授予相关权限。包括无障碍、悬浮窗、录屏、相册、文件访问、摄像头、麦克风等。
这些权限决定了它能不能真正完成“看、听、操作”的闭环。
对技术用户来说,这套配置不算难;但对普通用户来说,仍然有一定门槛。
这也说明,当前移动端Agent还处在早期阶段。
它已经从“论文概念”走向“可安装应用”,但距离真正像系统功能一样无感可用,还有一段路要走。
08 这件事为什么值得关注?
因为手机,是AI Agent最应该进入的地方。
我们每天真正花时间最多的,不是电脑,而是手机。
查资料在手机上;购物在手机上;订票在手机上;修图剪视频在手机上;支付、聊天、办公、刷内容,也都在手机上。
如果AI只能停留在聊天窗口,那它最多是一个“会说话的工具”。
但如果AI可以理解手机界面,并且跨App执行任务,它就会变成一个真正的“数字执行者”。
比如:
看到实物,自动查价;看到题目,自动辅助解答;看到一堆照片,自动分类成片;每天固定时间,自动搜索信息并总结;一句话,打开某个App深层页面;重复操作,录一次之后永久复用。
这些场景不一定科幻,但足够高频。
而高频,才是AI产品真正落地的关键。
09 但它也不是万能的
 隐私与权限提示图
隐私与权限提示图当然,X-OmniClaw目前还不是一个成熟到可以完全托管手机的产品。
它仍然面临几个现实问题。
第一,跨App操作很容易被打断
App更新、广告弹窗、登录状态、权限提示、页面改版,都可能让执行链失败。
这不是某一个项目的问题,而是整个移动端Agent都会遇到的问题。
手机App生态太复杂了。
第二,云端依赖仍然存在
X-OmniClaw的本地端负责感知和执行,但推理仍需要调用云端大模型。
这意味着网络、API稳定性、模型能力、调用成本,都会影响最终体验。
第三,隐私问题必须重视
它能访问相册、摄像头、麦克风,也可能需要把截图或文本描述发给云端模型。
所以在体验这类工具之前,用户必须清楚:
什么权限被打开;哪些数据会被读取;哪些信息可能离开本机;是否可以关闭长期记忆和个人画像注入。
AI Agent越接近系统底层,隐私边界就越重要。
能力越强,权限越敏感。
这句话,放在移动端AI Agent身上尤其成立。
10 OPPO这次开源,意义不小
X-OmniClaw采用 Apache License 2.0 协议,意味着开发者和研究者可以在保留声明的前提下进行修改、商用和二次开发。
这点很关键。
因为移动端Agent过去更多停留在演示、论文、封闭产品里。
但一个手机厂商愿意把完整工程实现开出来,本身就说明这个方向开始进入更务实的阶段。
它不再只是“AI能不能操作手机”的概念讨论,而是开始回答更具体的问题:
真实安卓机怎么接入?多模态输入怎么融合?跨App操作怎么稳定?本地记忆怎么管理?用户行为怎么变成可复用技能?权限和隐私怎么平衡?
这些问题,才是移动端Agent真正落地必须解决的问题。
11 总结:手机AI管家的第一步,已经迈出来了
X-OmniClaw最让人兴奋的地方,不是它现在已经多完美。
而是它把一个重要方向摆到了桌面上:
未来的AI,不应该只会聊天。
它应该能看见你正在看的东西;听懂你随口说出的指令;理解手机里正在发生什么;然后真的替你把操作做完。
从这个角度看,X-OmniClaw更像是一个信号。
它告诉我们:
移动端AI Agent不再只是云端虚拟机里的演示,也不只是实验室里的论文框架。
它开始进入真实手机,开始调用真实硬件,开始处理真实App,开始面对真实用户的复杂场景。
当然,它还有很多问题要解决。
稳定性、隐私、权限、成本、模型选择、普通用户上手门槛,每一个都是硬骨头。
但至少这一次,OPPO把一个可运行、可安装、可二次开发的工程方案放了出来。
这可能不是手机AI管家的终点。
但很可能,是一个真正开始的信号。
互动话题
你觉得手机里的AI Agent,未来会成为标配吗?
是“效率神器”,还是“权限怪兽”?
欢迎留言聊聊。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
