文章地址:https://arxiv.org/abs/2604.09059
发表时间:2026年4月
写在前面
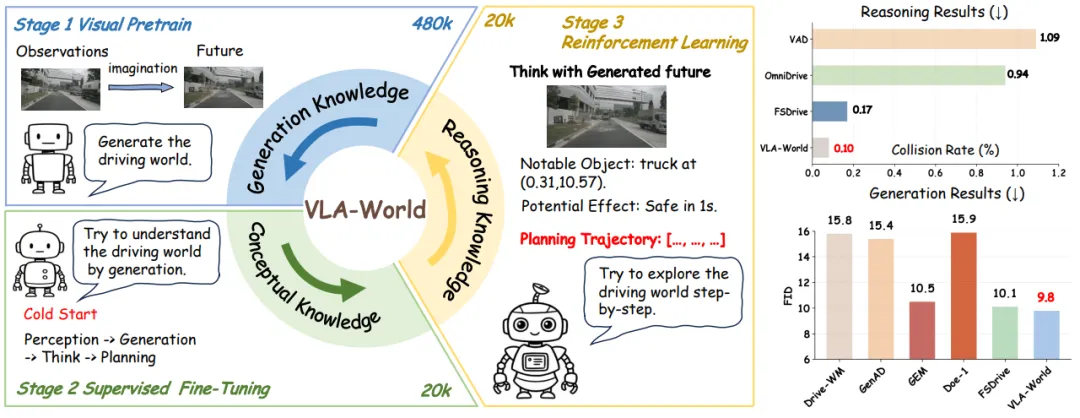
当前的端到端自动驾驶系统虽然在感知和动作映射上取得了进步,但往往缺乏对世界演变的显式预测能力,容易在复杂场景中产生“幻觉”或累积误差。上海交通大学与华为团队联合提出了 VLA-World,这是首个为自动驾驶设计的视觉-语言-动作世界模型。该模型不仅能直接输出驾驶动作,还能同步生成高保真度的未来驾驶画面,通过“生成驾驶世界”来“理解驾驶世界”。这种将生成知识与推理知识深度融合的架构,使自动驾驶系统能够像人类司机一样,在行动前先在脑中“演练”未来的场景,从而实现更安全、更精准的决策。
论文实现思路
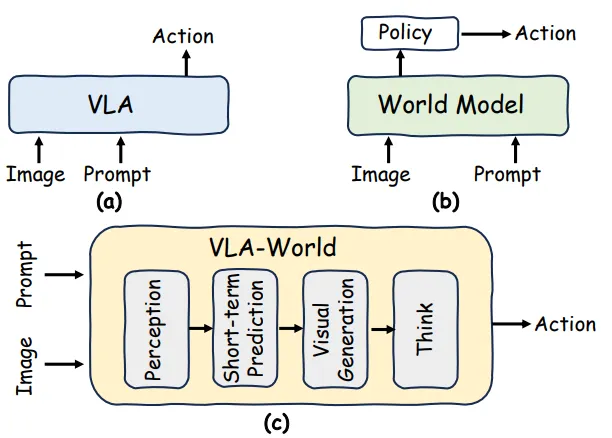
VLA-World 的实现通过一个三阶段的训练框架和创新的多模态主干网络展开,旨在弥合感知与生成之间的鸿沟:
图 1:VLA-World 系统架构与三阶段演进流程
- 三阶段学习范式: 该框架分为视觉预训练、指令微调(SFT)和强化学习优化三个阶段。在微调阶段,模型引入了“通过生成来思考”的逻辑,使模型能够根据当前的驾驶指令和感知输入,在生成未来画面的同时进行逻辑推理,从而建立起从感知到规划的完整闭环。
图 2:自动驾驶世界模型的时间演化与基准对比
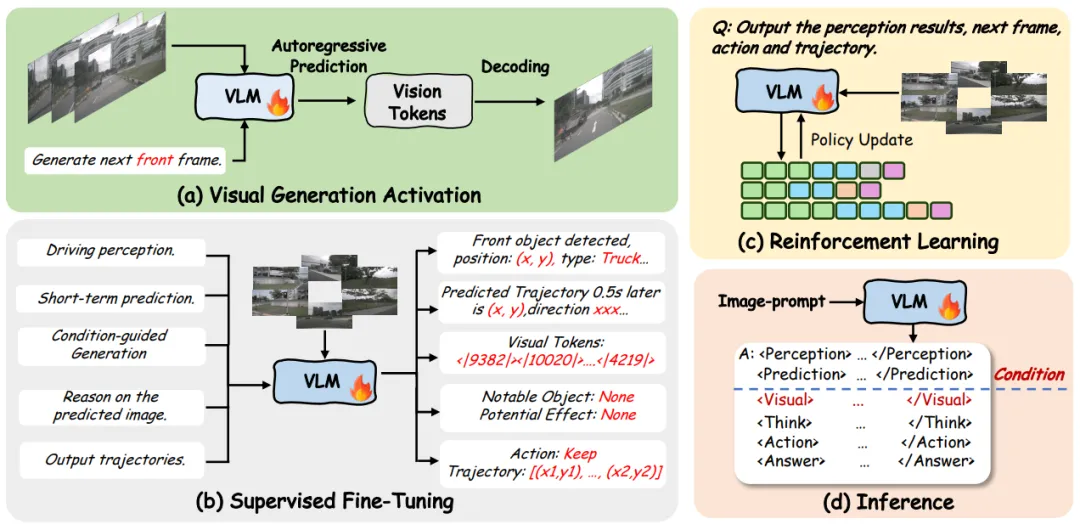
- 轨迹感知的生成机制: 不同于传统的纯视频预测,VLA-World 将预测的动作块作为生成的约束条件。模型先预测出长时的未来状态,再基于该状态生成短时的高质量未来帧。这种设计确保了视觉上的未来演变与物理规划的轨迹保持高度一致,有效避免了物理规律违背的问题。
图 3:VLA-World 的 Transformer 主干与多模态交互模块
- 深度推理与自我修正: 系统采用了先进的多模态交互模块,将视觉编码、文本指令和历史轨迹进行统一融合。通过生成的未来画面,模型能够进行“反思式”推理,例如观察想象中与障碍物的距离,从而在线修正当前的规划轨迹,大幅降低了潜在的碰撞风险。
图 4:VLA-World 在复杂路口与障碍物避让中的优化路径
效果
通过在大型自动驾驶数据集上的验证,VLA-World 展示了超越传统端到端模型的卓越性能:
- 极高的视觉保真度与物理一致性: 对比实验表明,VLA-World 生成的未来画面在结构完整性和物体一致性上表现出色。它能够精准保留动态车辆的刚性结构,即使在高速运动场景下也能维持画面稳定,验证了其短时预测在缓解“幻觉”方面的有效性。
图 5:VLA-World 与基准方法在未来帧生成质量上的对比
- 决策安全性显著提升: 得益于“先预测后决策”的机制,VLA-World 在实际规划中的碰撞率降至 0.10%,性能优于现有的多种端到端模型。在长时序的轨迹预测中,模型依然能保持极高的精度,成功解决了纯反应式系统常见的漂移问题。
图 6:不同驾驶场景下轨迹预测精度与时间的关系曲线
- 通用驾驶常识的习得: 模型展现出了对复杂交互场景(如窄路会车、避让卡车)的深刻理解。它不仅能感知当前的障碍物,还能预判未来数秒内的潜在冲突,并将这种推理转化为精准的驾驶动作。这种从像素生成到驾驶智能的飞跃,为构建高阶自动驾驶系统提供了强有力的技术支撑。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
