文章末尾有顶会级idea分享
⚡️《DeepSight: Long-Horizon World Modeling via Latent States Prediction for End-to-End Autonomous Driving》
📖 导读
在端到端自动驾驶(End-to-End Autonomous Driving)领域,视觉语言模型(VLM)的引入正成为提升决策鲁棒性的新范式。然而,现有的世界模型大多是将通用领域的方法直接套用,存在两大“硬伤”:一是过度关注图像纹理的短时重构(如未来0.5秒的像素预测),导致“目光短浅”且丢失关键语义;二是仅依赖前向视角,缺乏对周围交通参与者的全方位空间感知,极易在复杂交互中引发安全隐患。
为了赋予自动驾驶系统人类级别的认知能力,清华大学、阿里高德与南洋理工大学的研究团队联合提出了 DeepSight。该模型摒弃了传统的像素重建路线,创新性地在鸟瞰图(BEV)空间中对连续未来帧的“隐式语义特征”进行并行预测,实现了真正的长时序世界建模。此外,DeepSight 引入了自适应思维链(Adaptive CoT)机制,在遇到长尾复杂场景时,能动态激活大模型的常识推理能力。在极具挑战的 Bench2Drive 闭环测试中,DeepSight 狂砍 86.23 的驾驶得分(DS)与 71.36% 的成功率(SR),以压倒性优势刷新了 SOTA 纪录!
📷 核心图表
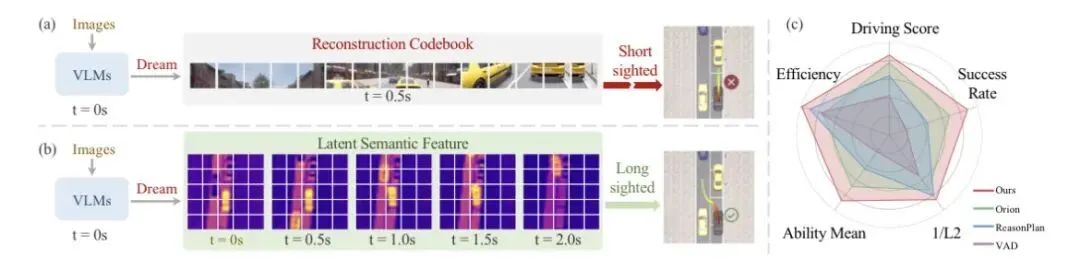
图1 | 不同统一世界模型范式的对比
注:传统的 VLM 世界模型(图a)通过显式输出密码本(Codebook) token 来预测未来的单帧图像,这种“短视”阻碍了长程轨迹规划。而 DeepSight(图b)通过预测未来多帧的 BEV 隐式语义特征,实现了长时序的世界建模,从而能够规划出更安全的未来轨迹。
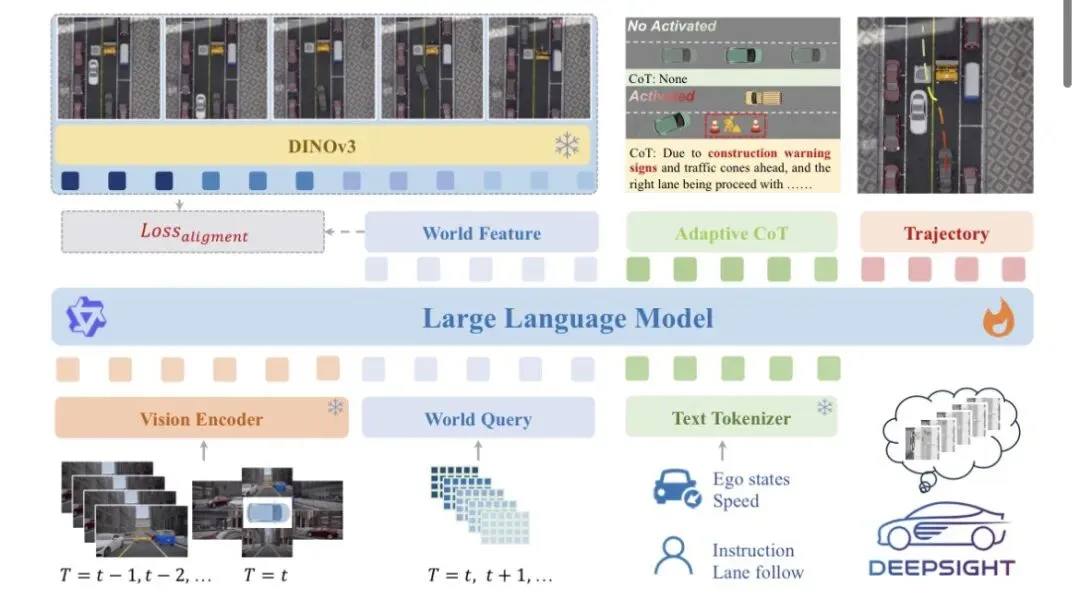
图2 | DeepSight 整体架构蓝图
资料来源:论文 Figure 2。DeepSight 包含两个核心模块:一是长时序驾驶世界模型,在训练时通过 DINOv3 提取未来多帧 RGB 图像的 BEV 语义特征进行对齐;二是自适应 CoT 模块,在长尾场景下动态整合外部知识(如识别施工标志、消防车等)以增强推理和决策。
📑 核心信息提炼
- 文献题目: DeepSight: Long-Horizon World Modeling via Latent States Prediction for End-to-End Autonomous Driving(《DeepSight:基于隐式状态预测的端到端自动驾驶长时序世界建模》)
- 作者团队: Lingjun Zhang, Changjie Wu, Linzhe Shi, Jiangyang Li, Jiaxin Liu 等(清华大学,阿里高德,南洋理工大学)
- 核心数据/指标:
- 闭环测试霸榜:在 Bench2Drive 评测中,驾驶得分(DS)达到 86.23(较前SOTA提升 7.39),成功率(SR)达 **71.36%**(较前SOTA提升 13.63%)。
- 极低推理延迟:强大的自适应 CoT 机制仅带来了约 4.12% 的额外推理延迟。
- 开环轨迹预测:在 nuScenes 数据集上,L2 误差降低至 0.58 米。
- 核心发现/战绩:
- 相比于基于 VAE 重建未来图像纹理的模型,预测隐式语义特征(DINOv3)能带来 +47.04 DS 的恐怖性能飞跃。
- 将单视角感知升级为 BEV 多视角并行预测,能使系统驾驶得分显著提升 +8.8 DS。
- 核心创新点:
- 长时序语义预测:利用可学习的 World Queries 并行推理未来多帧的隐式状态,彻底摆脱了自回归生成像素的高昂代价。
- 自适应思维链(Adaptive CoT):赋予模型自主判断场景复杂度的能力,仅在需避让紧急车辆、复杂交通灯等长尾场景激活大语言模型的常识推理,平衡了智商与速度。
- 核心主题: 世界模型 (World Models)、端到端自动驾驶 (End-to-End Autonomous Driving)、视觉语言模型 (VLMs)、鸟瞰图 (BEV)、自适应思维链 (Adaptive CoT)
- 核心受众: 自动驾驶算法工程师、具身智能研究员、大视觉语言模型 (MLLMs) 开发者
❓ 行业发展的 4 大“核心痛点”
- 沉迷“画图”,丢失语义: 现存的大量端到端世界模型使用 VAE/密码本来重建未来画面的像素纹理,过度拟合天气、光照等无用细节,反而忽略了对驾驶至关重要的底层语义结构。
- “目光短浅”的致命伤: 大多数统一架构模型只能预测未来极短时间(如 0.5 秒)的单帧观察,无法为高速行驶或复杂动态环境中的车辆提供足够的避险前瞻时长。
- 前视视角的空间盲区: 目前大量研究仅局限于前向摄像头视角的预测,缺乏对自车周围全方位移动智能体(Agent)的建模,极易在变道或路口博弈中引发碰撞。
- 长尾场景的推理黑盒: 基于纯模仿学习的模型在面对训练数据中极少出现的场景(如前方施工、警车逆行)时极易崩溃,缺乏调用人类社会常识进行逻辑推理的机制。
🔧 核心真相:终极拆解“DeepSight 落地的四大现实逻辑”
1. 表征真相:用 DINOv3 提取高级语义,抛弃像素级重建
- 自动驾驶世界模型不需要知道未来天上的云是什么形状。DeepSight 使用具有强大自监督表征能力的 DINOv3 提取未来环境的语义特征图(Semantic Feature)作为预测目标(Ground Truth)。
- 实验证明,这种隐式语义建模比 VAE 像素级预测的驾驶得分高出近一倍。
2. 架构真相:在 BEV 空间并行预测,打破自回归的速度诅咒
- 模型通过接收一组可学习的 World Queries [q_0, q_1, ..., q_4],在单次前向传播中并行解码出未来多个时间节点(最高预测至 2.0s)的鸟瞰图隐式特征。
- BEV 空间自带的 3D 几何先验,加上免去了自回归生成的排队等待,使得 DeepSight 在实现长时序感知的同时,仅比原生 VLM 增加了 3.57% 的延迟。
3. 推理真相:好钢用在刀刃上,自适应 CoT 兼顾“快”与“智”
- 大语言模型的文本推理(CoT)非常耗时。DeepSight 设计了“按需激活”的机制:模型先观察环境,如果判断是跟车直行等简单场景,则直接输出轨迹并生成一个占位符 T_{\emptyset} 省略推理。
- 只有在识别到 STOP 标志、施工锥桶等复杂长尾场景时,才会触发生成详细的文本分析,这使得平均推理延迟仅微增 4% 左右。
4. 训练真相:闭环能力来源于海量高质量 CoT 标注
- 为了让模型学会“何时思考”,团队利用千亿级开源大模型(Qwen3-VL-235B)打造了一条全自动的高精度标注流水线。
- 经过“场景复杂度评估”到“驱动行为判定”的漏斗过滤,系统为 Bench2Drive 合成了约 130 万条精准的结构化思维链数据,赋予了小模型(3B级别)越级的逻辑判断力。
📊 关键内容与数据看板
表1:Bench2Drive 核心路线闭环评测结果对比(Base Set)
| 模型/架构方案 | 所属范式 | 驾驶得分 (DS) ↑ | 成功率 (SR) ↑ | 效率评分 (Efficiency) ↑ |
|---|
| VAD | 纯端到端 (E2E) | 42.35 | 46.01% | 157.94 |
| ReasonPlan | 视觉语言模型 (VLM) | 64.01 | 25.63% | 180.64 |
| Auto VLA | 视觉语言模型 (VLM) | 78.84 | 57.73% | 146.93 |
| DeepSight (Ours) | 隐式长时序 VLM | 86.23 | 71.36% | 201.71 |
| 注:在完全一致的 Think2Drive 专家数据协议下,DeepSight 以极大的断层优势超越了此前所有的端到端模型及大模型方案。 | | | | |
| 表2:世界模型核心设计消融实验(Dev 10 routes) | | | | |
| 世界模型设计 | 预测时序 | 路线完成度 (RC) ↑ | 驾驶得分 (DS) ↑ | 核心结论 |
| --- | --- | --- | --- | --- |
| VAE 重建 | 预测单帧 | 47.56 | 27.75 | 强行预测像素导致系统决策崩溃 |
| DINOv3 语义 | 预测单帧 | 90.49 | 74.79 | 语义特征对驾驶决策的贡献具有压倒性优势 |
| VAE 重建 | 预测连续五帧 | 27.02 | 14.66 | VAE 根本无力支撑长时序动力学建模 |
| DINOv3 语义 | 预测连续五帧 | 95.95 | 86.57 | 隐式语义 + 长时序 = 完美的闭环世界模型 |
💬 深度 Q&A
- Q1:既然大语言模型(LLM)已经具备了推理能力,为什么还要单独耗费算力去预测 BEV 空间的隐式特征?
A: LLM 的强项是常识推理(比如“看到救护车要让行”),但它的弱项是精确的三维空间定位与动力学推演。如果我们把自动驾驶比作人类驾驶员,LLM 相当于“大脑”,而 BEV 隐式预测则相当于小脑和视觉皮层建立的“时空直觉”。只有并行预测未来多帧的隐式状态,系统才能规划出物理上安全、轨迹平滑的规控动作。 - Q2:增加 CoT 思维链输出,会不会导致自动驾驶系统在危险时刻“思考过载”,反应太慢导致车祸?
A: 这正是传统 CoT 方法在自动驾驶落地的死穴。DeepSight 采用的 Adaptive CoT(自适应思维链) 完美避开了这个问题。系统在绝大多数常规行驶(如直行跟车)时,会跳过繁琐的文字生成,直接输出轨迹;仅在面临复杂路权博弈或长尾事件时介入。数据表明,该模块在低于 30% 的帧中被激活,整体推理延迟只增加了 4.12%。 - Q3:与预测前视相机画面(Front-view)相比,在鸟瞰图(BEV)下做世界模型有什么不可替代的优势?
A: 视角的选择直接决定了安全的上限。前视画面受限于透视投影,存在严重的遮挡问题且难以表达深度;而 BEV 俯视图能无死角地呈现自车与周边所有动态目标(行人、车辆)的空间位置关系。消融实验证实,从前视切换到 BEV 空间预测,能让闭环驾驶得分硬生生提高 8.8 分。
🎯 深度点评
核心贡献: 本文精准地切中了 VLM 在自动驾驶领域落地的“痛点”——空有常识但缺乏空间直觉。DeepSight 通过在统一模型内解耦“空间时序动力学(BEV隐式预测)”与“长尾社会常识(自适应CoT)”,为下一代具有高泛化能力、强可解释性的端到端自动驾驶指明了技术路径。
- 亮点总结:
① 克制的“世界模型”:坚决不卷像素重建,使用 DINOv3 提取纯语义信息,用极低的计算代价换取了对长时序的高效拟合。
② 高情商的算力分配:自适应思维链机制打破了 LLM 引入必致高延迟的魔咒,是极具工程落地价值的巧思。
③ 数据工程的胜利:利用两千亿参数大模型自动化构造超百万条闭环思维链数据,展现了强大的数据飞轮潜力。 - 不足与局限:
尽管在仿真测试(Bench2Drive)中表现优异,但 VLM 本身庞大的参数量(即便基础模型只有 3B)在部署至真实车端芯片(如 Orin-X)时,其内存占用、KV Cache 调度与极致的实时性要求,仍将是阻碍其大规模上车的严峻挑战。
🌟 总结金句
真正的自动驾驶世界模型,不在于完美地“画”出未来的每一颗像素,而在于精准地“预判”时空演变中的物理语义与因果法则。
📌 互动引导
在端到端自动驾驶演进的过程中,您认为决定系统“安全性”天花板的最关键因素是什么? ✅ A. 模型对多模态传感器数据的原生融合能力
✅ B. 类似 DeepSight 这种对未来连续时空状态(世界模型)的预判能力
✅ C. 利用人类常识与自然语言处理长尾事件的逻辑推理能力
✅ D. 别整花里胡哨的,闭环强化学习(RL)疯狂试错才是硬道理!
欢迎在评论区留下你的真知灼见! 👇
🧩 研究方向展望
针对冲刺 CVPR / ICCV / ICLR 等顶会的自动驾驶、世界模型及多模态大模型研究者,基于本文提供以下延伸思路:
- 融合 3D Gaussian Splatting (3DGS) 的下一代世界模型: 尽管 DeepSight 的 DINOv3 BEV 语义特征大幅提升了决策表现,但二维 BEV 仍然丢失了高度信息。可尝试在 VLM 的隐式预测分支中引入 3DGS 表征,在无需高昂渲染开销的前提下,构建具备高度感知的 3D 隐式世界模型,以应对立交桥、陡坡等复杂三维结构的轨迹规划。
- 基于异构大模型协作的云端-车端自适应 CoT 蒸馏: 论文中的 Adaptive CoT 仍然依赖车端(本地)的小型 VLM 执行。可探索构建一种异构多智能体架构:日常行驶由纯视觉极简网络控制;一旦触发长尾不确定度阈值,则将场景切片实时回传至云端的“超级大模型”(如 Qwen-Max),由其在云端进行深度的规则链(Rule-based CoT)推理并下发指令,同时将此过程在线蒸馏给车端小模型。
- 面向多智能体博弈(Multi-Agent Interaction)的共享隐式 BEV 演演: 论文目前的预测主要以自车(Ego)为中心。在无保护左转或狭窄路段会车时,可研究在 DeepSight 框架内加入多 Agent 意图推演机制:让模型在潜在空间中并行预测周围关键车辆的“多模态可能轨迹”,并通过计算这些隐式轨迹的碰撞概率,输出纳什均衡意义下最优的非侵略性驾驶决策。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
