 小米研究团队开源 OneVL 视觉-语言-动作(VLA)自动驾驶框架,4B 模型横扫四大基准,推理延迟比传统思维链快 1.5-2.3 倍。
小米研究团队开源 OneVL 视觉-语言-动作(VLA)自动驾驶框架,4B 模型横扫四大基准,推理延迟比传统思维链快 1.5-2.3 倍。///
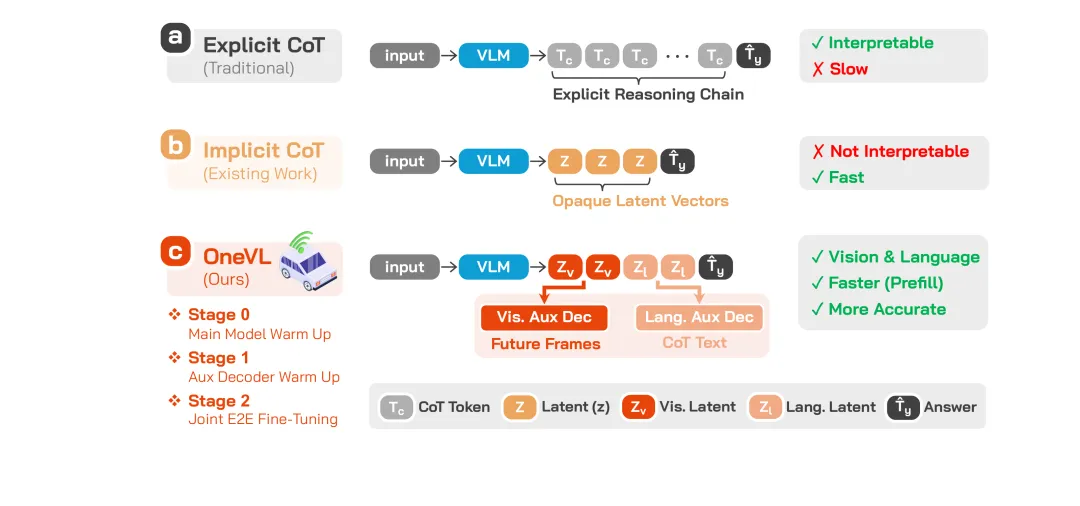
让 AI 开车,目前主流方案有三种思路:
方案一:显式思维链(Explicit CoT) —— AI 先「想」出完整的推理过程,再输出驾驶决策。效果好、可解释,但太慢了,延迟高。
方案二:隐式思维链(Implicit CoT) —— 把推理压缩成不透明的隐向量。速度快,但完全是个黑箱,没人知道它怎么想的。
方案三:OneVL(小米提出) —— 两全其美。用双模态辅助解码器分别监督视觉和语言的隐式 token,推理时直接预填入 prompt,速度和纯推理一样快,同时保留视觉和语言的可解释性。
///
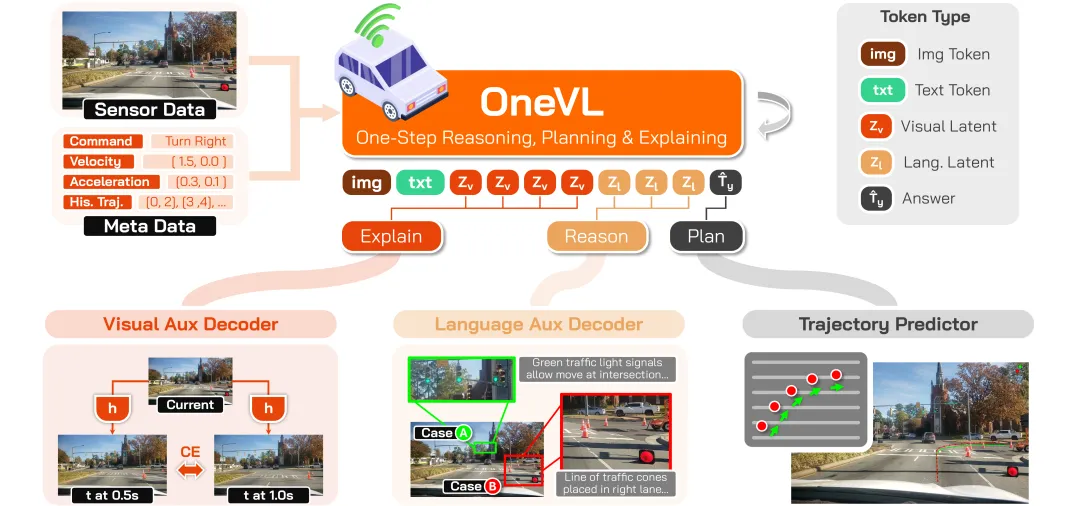
OneVL 基于 Qwen3-VL-4B-Instruct 改造,核心架构非常精巧:
1. 隐式 Token 接口
- 在 AI 回复中插入 4 个视觉隐式 token + 2 个语言隐式 token
- 复用现有词表 token,无需新增特殊 token
2. 视觉辅助解码器(Visual Auxiliary Decoder)
- 从视觉隐式 token 预测未来 0.5s 和 1.0s 的场景画面
- 本质上充当了一个「世界模型」,让 AI 不仅会想,还能「看到」未来
3. 语言辅助解码器(Language Auxiliary Decoder)
- 从语言隐式 token 重建思维链推理文本
- 让你看得懂 AI 为什么这么开
4. 预填推理(Prefill Inference)
- 推理时两个辅助解码器全部丢弃
- 隐式 token 一次性并行处理,只有轨迹预测走自回归
- 速度几乎等于纯推理模型
///
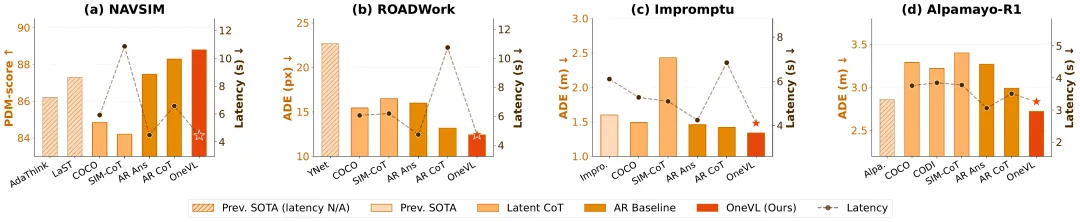
在四大自动驾驶基准测试上,OneVL 全部取得 SOTA:
NAVSIM 基准
| 方法 | 模型大小 | PDM 分数 ↑ | 延迟 (s) ↓ | 可解释性 |
|---|
| AR Answer(纯推理) | 4B | 87.47 | 4.49 | ❌ |
| AR CoT+Answer(显式思维链) | 4B | 88.29 | 6.58 | ✅ 语言 |
| COCONUT | 4B | 84.84 | 5.93 | ❌ |
| CODI | 4B | 83.92 | 8.62 | ❌ |
| OneVL | 4B | 88.84 | 4.46 | ✅ 视觉+语言 |
OneVL 比显式思维链更快、更准,比纯推理更准,而且是唯一同时兼顾速度和可解释性的方案。
ROADWork 基准(施工区域导航)
| 方法 | ADE (px) ↓ | FDE (px) ↓ | 延迟 (s) ↓ |
|---|
| AR Answer | 15.98 | 40.29 | 4.74 |
| AR CoT+Answer | 13.18 | 29.98 | 10.74 |
| OneVL | 12.49 | 28.80 | 4.71 |
施工区域这种高难度场景,OneVL 的轨迹预测误差比显式思维链还低,延迟只有它的一半不到。
///
PART 04
实际效果:能看到 AI 的「思考过程」
OneVL 不仅能预测轨迹,还能可视化 AI 的决策依据:
- 视觉可解释: 辅助解码器生成未来 0.5s 和 1.0s 的场景预测画面
- 语言可解释: 辅助解码器输出类似人类司机的推理文本
语言辅助解码器恢复了 97% 的显式思维链质量,但运行速度只有原来的 1/1.5。
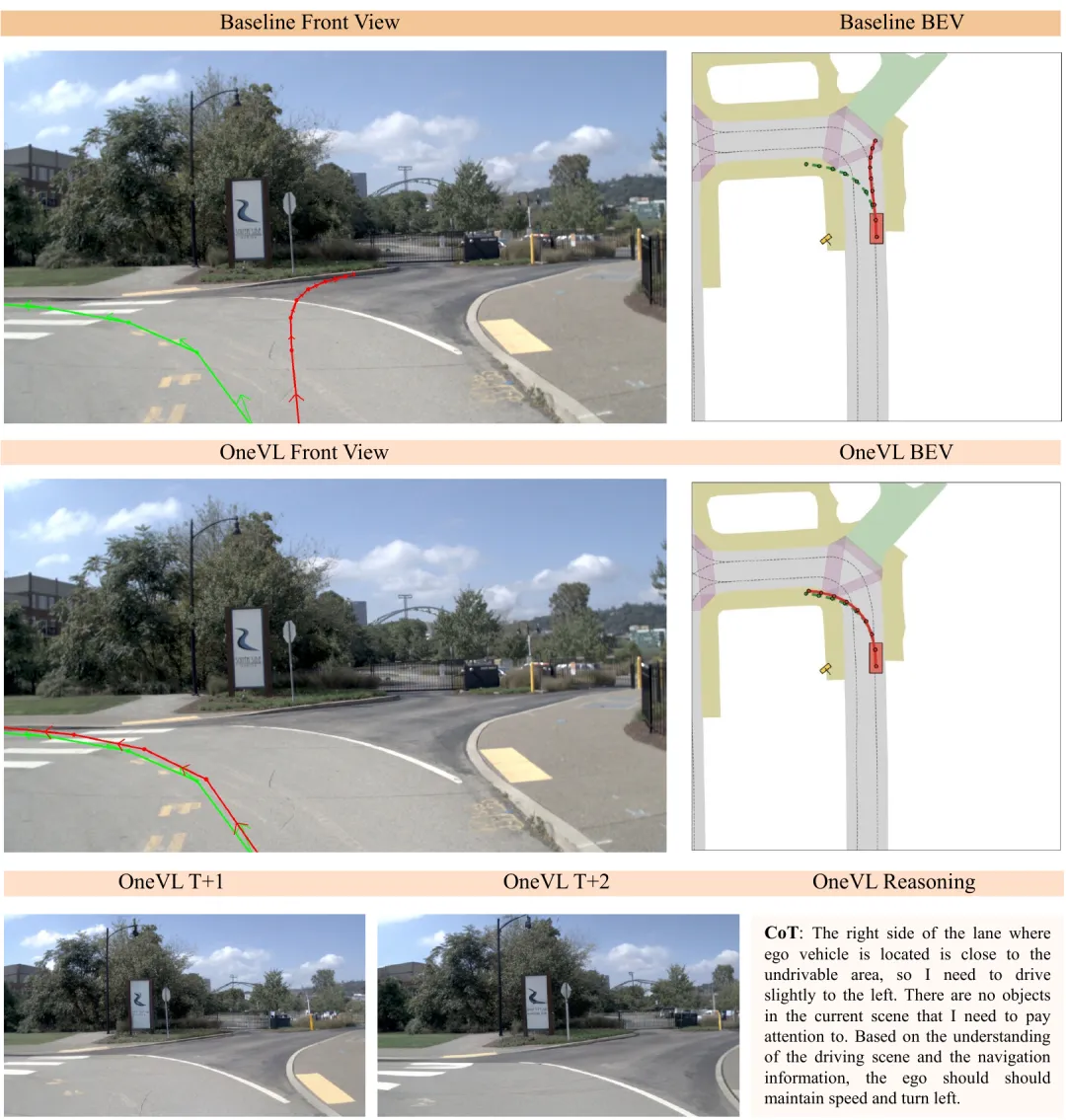

///
为什么以前的隐式 CoT 方法在自动驾驶上全军覆没?
COCONUT、CODI、SIM-CoT 这些方法在驾驶任务上甚至不如纯推理基线。OneVL 的研究揭示了关键原因:
- 双模态监督是刚需 —— 只用语言监督是不够的,自动驾驶需要视觉层面的世界模型理解
- 分阶段训练至关重要 —— 论文消融实验显示,去掉分阶段训练,性能从 88.84 暴跌到 67.13
- 压缩驱动泛化 —— OneVL 是唯一在隐式 CoT 上超越显式 CoT 的方法
///
| 组件 | 状态 |
|---|
| 📄 技术论文 | ✅ arXiv |
| ⚖️ 模型权重 | ✅ HuggingFace |
| 🔍 推理代码 | ✅ GitHub |
| 🏋️ 训练代码 | ✅ GitHub |
论文 + 模型 + 推理 + 训练代码全开源,Apache 2.0 协议。
///
# 环境要求:Python 3.10+, CUDA GPU (≥16GB)
# 创建虚拟环境
uv venv venv/onevl --python 3.12
source venv/onevl/bin/activate
pip install -r requirements.txt
# 快速推理(最快,预填模式)
python infer_onevl.py \
--model_path /path/to/OneVL-checkpoint \
--test_set_path test_data/navsim_test.json \
--output_path output/navsim/results.json \
--device cuda:0 \
--num_latent 2 --num_latent_vis 4 \
--max_new_tokens 1024 --answer_prefix "["
核心依赖:
torch==2.10.0
transformers==4.57.0
safetensors==0.7.0
///
OneVL 解决了自动驾驶 AI 推理中的核心矛盾:要快还是要能解释?
小米团队给出的答案是:都要。
4B 参数量横扫四大基准,延迟比传统思维链快 1.5-2.3 倍,同时提供视觉和语言双模态的可解释性。完整开源,论文、模型、代码一个不少。
对于自动驾驶研究者和工程师来说,这是今年最值得关注的开源项目之一。
///
*来源:GitHub xiaomi-research/onevl · 论文 arXiv:2604.18486*
THANKS FOR READING
🦐 龙虾 · OpenClaw 技术分享
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
