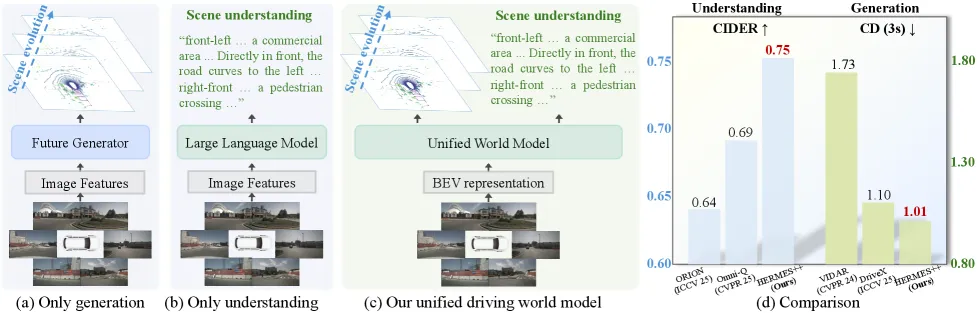
HERMES++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
你有没有发现,自动驾驶的感知系统要么“只会看不会想”,要么“能想但看不准”?它要么能精准预测未来的3D点云变化,却答不上来“前面这辆车为什么减速”;要么能像人类一样用语言描述复杂场景,却对接下来几秒的几何演化一无所知。这就像一个人蒙着眼画地图,或一个盲人在白板上高谈阔论——总有一环是缺的。HERMES++这篇论文,就是要把这关键的一环补上,造一个既能看懂、又能算命的“全才”。
当‘预言家’遇见‘解说员’
自动驾驶的世界模型(World Model)是个好东西,它试图让车辆拥有“想象力”,能模拟环境未来的变化。但现有的大多数模型,要么专注于生成未来的2D视觉外观(比如DriveDreamer),要么预测3D几何变化(比如ViDAR预测点云)。它们是优秀的“预言家”,能告诉你“接下来会怎样”,却解释不了“为什么会这样”。与此同时,以LLM为核心的视觉语言模型(VLM),如OmniDrive、DriveLM,则是出色的“解说员”。它们能理解复杂的交通场景,回答关于物体关系、场景语义的问题,但缺乏对物理世界未来如何演变的预测能力。
这种割裂在安全关键场景中是致命的。一个真正可靠的系统,必须在理解“现在发生了什么”的同时,能可靠地预测“接下来几秒会发生什么”。HERMES++要做的,就是把“解说员”和“预言家”捏合成一个人。它的核心洞见是:对场景的语义理解(理解)应该能指导未来的几何演化(生成);而对未来的几何预测,又能为语言理解提供坚实的物理基础。
图1: 之前方法要么只做理解(b),要么只做预测(a),HERMES++(c)首次在统一框架中结合两者,并定量超越专家模型(d)。
如上图所示,之前的工作就像两条平行线,各自发展。HERMES++则搭建了一座桥梁,让信息可以双向流动。它的目标很明确:一个模型,同时搞定理解和生成,并且两个任务互相增益,性能超越那些各自为战的“专家模型”。
核心方法:用一张“地图”连接两个世界
实现统一的第一步,是找到一个能让LLM“看懂”的3D表示。直接把多视图图像拍平成token喂给LLM?论文证明了这行不通。因为图像在LLM处理过程中会丧失宝贵的空间结构信息,导致几何预测一塌糊涂(后面实验会细说)。HERMES++的答案是:BEV(鸟瞰图)表示。
BEV就像一张统一的“作战地图”,它把来自多个摄像头的透视视图信息,压缩到一个俯视视角的二维网格上。这个网格的每个位置都编码了该地点的视觉语义和几何信息。更关键的是,BEV的网格结构天然适合与token化的LLM交互。论文通过一个BEV视觉分词器(Visual Tokenizer),先将图像特征转换到BEV空间,再经过下采样、展平,变成一系列能被LLM消化的视觉token。这样,既保留了关键的几何拓扑,又控制了token长度。
图2: Hermes++整体流程:BEV输入经LLM处理后,通过世界查询和当前到未来链接生成未来点云,并联合优化几何一致性。
这张整体流程图清晰地展示了信息如何流动。BEV token和用户问题(文本token)被拼接后送入LLM。LLM在生成文本回答的同时,其处理过程会“熏陶”一组特殊的世界查询(World Queries)。这些查询就像派往LLM内部的“特工”,它们的任务是窃取(聚合)LLM通过海量预训练获得的“世界知识”和当前场景的语义上下文。
那么,这些被赋予了语义理解的“特工”(世界查询)如何指导未来预测呢?这就需要当前到未来链接(Current-to-Future Link)。这个链接模块接收当前的BEV特征,并以世界查询和文本嵌入作为“条件信号”,通过交叉注意力机制,引导BEV特征向未来时间步演化。这里还有一个精巧的设计:自车运动调制(Ego Modulation)。它根据车辆未来的运动轨迹(如转弯、加速),动态调整特征的空间分布,从而将相机自身运动与场景固有动态解耦,让预测更可控。
联合几何优化:约束未来的“双重枷锁”
仅仅依靠渲染点云来监督未来预测,容易产生结构模糊、深度歧义的问题。想象一下,如果只告诉你“画一个3秒后的场景”,你画出的东西可能在透视上合理,但在物理结构上是拧巴的。HERMES++提出了联合几何优化策略(Joint Geometric Optimization),给预测过程加上了“双重枷锁”。
第一重是显式约束:直接计算预测点云与真实点云之间的L1距离(公式9)。这是在像素级别(深度图)的硬约束。
第二重是隐式正则化,这才是创新所在。它不直接监督输出,而是约束内部表示的“气质”。具体做法是:先用一个自监督的点云编码器(训练后冻结)提取出“几何感知”的特征(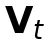 ),然后要求模型生成的特征(
),然后要求模型生成的特征( )与之对齐。对齐通过两个损失实现:
)与之对齐。对齐通过两个损失实现:
1. 余弦相似度损失(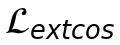 ,公式10):保证每个空间位置的局部特征方向一致,像是在微观层面确保每个“零件”的朝向正确。
,公式10):保证每个空间位置的局部特征方向一致,像是在微观层面确保每个“零件”的朝向正确。
2. Gram矩阵损失(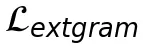 ,公式12):在HW、HZ、WZ三个正交平面的投影上,计算特征相关性的Gram矩阵,并要求预测与目标矩阵一致。这捕获了全局的结构模式和内部相关性,像是在宏观层面确保“整体布局”的合理性。
,公式12):在HW、HZ、WZ三个正交平面的投影上,计算特征相关性的Gram矩阵,并要求预测与目标矩阵一致。这捕获了全局的结构模式和内部相关性,像是在宏观层面确保“整体布局”的合理性。
可以这样比喻:显式约束好比用GPS坐标点严格测绘一栋楼的轮廓;隐式正则化则像是用物理规律(如重力、应力)作为先验,确保你设计的楼即使在没有精确坐标时,其内部结构也必然是稳定、合理的。两者结合,才能生成既精确又结构完整的未来场景。
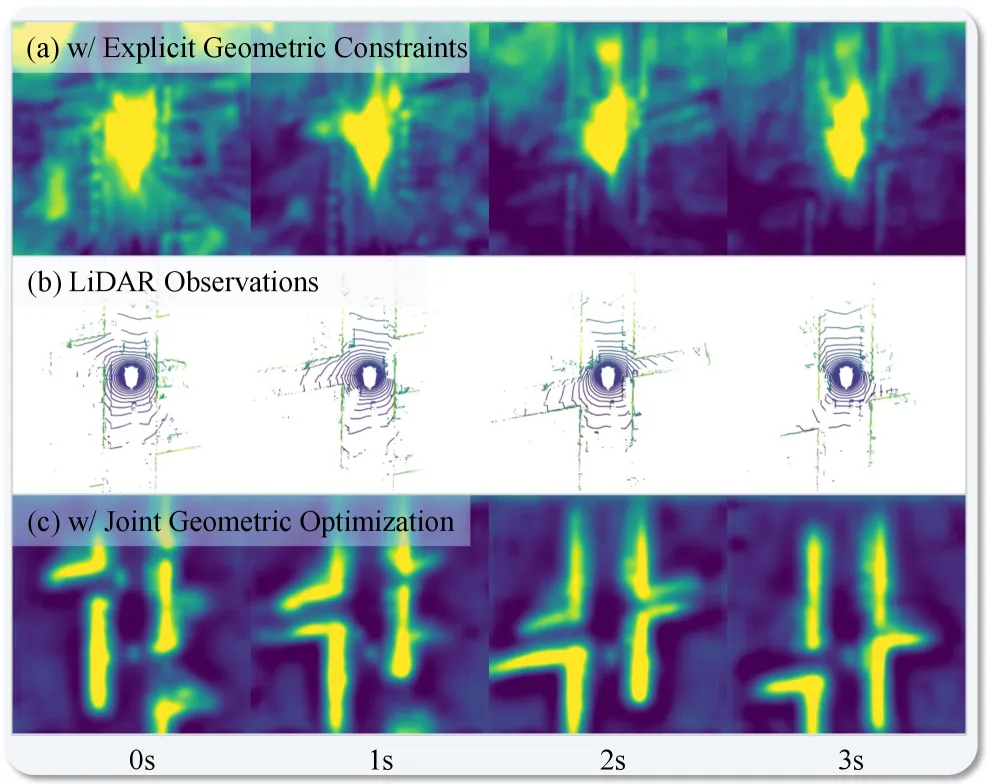
图5: 仅用显式约束时,特征有明显投影伪影和中心偏差(a);联合优化后,特征更纯净、符合点云几何(c)。
如上图可视化结果所示,仅靠显式约束,学到的BEV特征会带有很多来自相机投影的“放射状”伪影和中心高亮(图a)。而引入隐式正则化后,特征变得更“干净”、更紧凑,与真实点云的几何结构(图b)高度吻合(图c)。这直接证明了联合优化对学习几何感知表示的有效性。
实验:统一模型如何“干翻”专家
HERMES++在多个基准上进行了狂轰滥炸式的评估,核心结果集中在Table II。它同时挑战了“未来点云生成”和“3D场景理解”两个任务的专家模型。
TABLE II: 与理解/生成专家模型的对比(在OmniDrive-nuScenes验证集上)。
| | 生成任务 (Chamfer Distance ↓) | | | | | | |
|---|
| | | | | | | | |
| 生成专家 | | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| 理解专家 | | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| | | | | | | | |
| 统一模型 | | | | | | | | |
| | | | | | | | |
| Hermes++ (Ours) | | | | | | | | |
| Hermes++ (3.8B) | | | | | 0.97 | | | 0.772 |
解读:
• 在生成任务上全面领先:HERMES++以 0.97 的3秒Chamfer Distance(CD)大幅超越了前冠军DriveX(1.10),误差降低了约8.2%。这意味着它的未来点云预测精度最高。更值得注意的是,这些生成专家模型无法回答任何场景理解问题(表中“Unsupported”)。
• 理解任务不输专家:在不需要任何辅助监督(如3D检测框、车道线)的情况下,HERMES++(1.8B)的CIDEr分数(0.749)已经超过了大多数需要辅助监督的理解专家模型(如Omni-Q的0.686)。这证明了BEV表示本身蕴含了强大的语义和几何信息,足以支撑高质量的理解。
• 统一带来增益:与上一版Hermes(ICCV 25)相比,HERMES++通过引入联合优化和文本注入等新技术,将3秒生成误差降低了13.7%,理解指标也全面提升。这说明更深、更精细的任务交互设计确实有效。
• 大力出奇迹:将LLM从1.8B扩大到3.8B,模型在两项任务上都获得了稳定提升。这证明了HERMES++架构的可扩展性,更大的模型意味着更强的世界知识和推理能力,能被框架有效利用。
另一个有趣的发现来自对BEV表示有效性的消融实验(Fig. 4及Table III)。当使用直接展平的多视图图像token作为输入时,虽然理解性能差别不大(METEOR差0.001),但生成任务的3秒CD从1.436暴涨到2.012,劣化超过30%。定性分析发现,多视图输入会导致模型在生成时产生严重的“空间结构崩溃”,例如错误地预测车辆转弯(图4中红色箭头)。而BEV表示保持了空间拓扑的连贯性,预测结果与真实行驶轨迹一致。
图3: 模型定性结果:能正确回答关于场景的文本问题,并精准预测物体在未来时序的几何形状演化。
如上图定性结果所示,模型不仅能识别出路牌上的“Shaw Foundation Alumni House”并推断出场景在校园,还能在预测的未来点云序列中,精确跟踪红圈内车辆的几何形状变化,保持了高度的结构一致性。
图4: 多视图输入在空间结构上崩溃(如错误预测转弯),而BEV表示保持了空间拓扑一致性,生成结果更准。
这张对比图直观地说明了为什么BEV表示是统一理解与生成的更优选择。多视图输入在LLM处理过程中丢失了关键的空间关系,导致预测违反物理常识;而BEV的结构化表示像一个稳定的“锚点”,牢牢锁住了几何信息。
个人视角:贡献、隐含信息与未来
HERMES++的贡献是扎实且有启发意义的。它用一个简洁而有效的架构,首次在单一框架内实现了与顶尖专家模型媲美、甚至超越的3D场景理解和未来几何生成能力。这为“世界模型”的范式提供了新思路:未来的世界模型不应只是“生成器”,更应是一个“理解-生成一体化”的认知引擎。
论文中透露出一些行业的潜台词:
1. BEV成为统一表征的优选:在LSS、BEVFormer等工作奠定BEV在感知中的地位后,HERMES++证明了它也是连接LLM与3D世界的理想桥梁。未来围绕BEV的优化(如更高分辨率、更高效编码)仍有空间。
2. LLM是知识库,更是优化器:LLM不仅用于输出文本,其内部蕴含的世界知识通过“世界查询”被显式地提取并用于指导几何生成。同时,生成任务的梯度也会反向传播优化LLM的文本理解能力,形成了双向增强的闭环。
3. 显式+隐式的几何监督是关键:单纯依靠渲染损失无法保证高质量的内部表示。论文提出的联合几何优化策略,特别是隐式的Gram损失,为学习物理一致的潜空间提供了新工具,这一思想可推广到其他3D生成任务。
当然,这项工作也存在局限和挑战:
• 信息瓶颈:BEV表示在压缩多视图信息时,不可避免地会损失部分细节。如何设计更精细的BEV编码器,或引入多尺度BEV,是提升理解细粒度的关键。
• 长时序预测的衰减:实验显示,随着预测时间增长(从1s到3s),Chamfer Distance的增长并非线性,说明远期预测的不确定性累积效应依然显著。如何建模更长期的物理动力学是难题。
• 模态的局限:目前主要预测点云。将生成模态扩展到视频、Occupancy等,构建更全面的“世界模拟器”,是自然的延伸方向。
总而言之,HERMES++不仅仅是一个新模型,它更像一个宣言:自动驾驶的“眼睛”和“大脑”应该而且能够长在一起。它为后续研究——无论是追求更高精度、更强泛化,还是向闭环控制、决策规划延伸——都铺设了一块坚实的基石。当感知与预测在同一个认知框架下协同进化时,我们离真正可靠的自动驾驶系统,就又近了一步。
❤️❤️❤️如果这篇内容对你有帮助,欢迎点个赞、点个在看,也欢迎转发给更多有需要的朋友。你的每一次互动,都是我持续更新的动力。❤️❤️❤️
论文原文: https://arxiv.org/abs/2604.28196