
⚡️《CLOVER: Closed-Loop Value Estimation & Ranking for End-to-End Autonomous Driving Planning》
📖 导读
当前端到端自动驾驶的训练范式正面临一个极其尴尬的悖论:模型在训练时拼命“模仿(Imitation Learning)”人类司机的单一历史轨迹,但在上车评测时,却要接受安全性、可行性、通行效率和舒适度等复杂“规则指标”的严苛考核。这就导致了致命的“训练-评测不匹配(Training-evaluation mismatch)”——那些死死贴合人类演示的轨迹可能在物理上是违规的,而那些偏离了演示但在物理和规则上极其优秀的替代轨迹,却被模型给忽略了。
为了彻底粉碎这一死锁,清华大学智能产业研究院(AIR)、中国科学技术大学与北京航空航天大学的联合团队重磅推出了 CLOVER(Closed-Loop Value Estimation & Ranking) 框架。该研究采用极简优雅的“生成器-打分器(Generator-Scorer)”架构,不仅能生成覆盖面极广的多样化候选轨迹,还能在推理时预测规划指标的子分数,进行闭环价值排名。实验证明,CLOVER 成功打破了单一轨迹模仿的“狭窄模式(Narrow mode)”,大幅提升了高质量候选轨迹的多样性与可行性覆盖率。这是了解下一代端到端自动驾驶生成与重排序架构不可不读的纲领性指引。
📷 核心图表
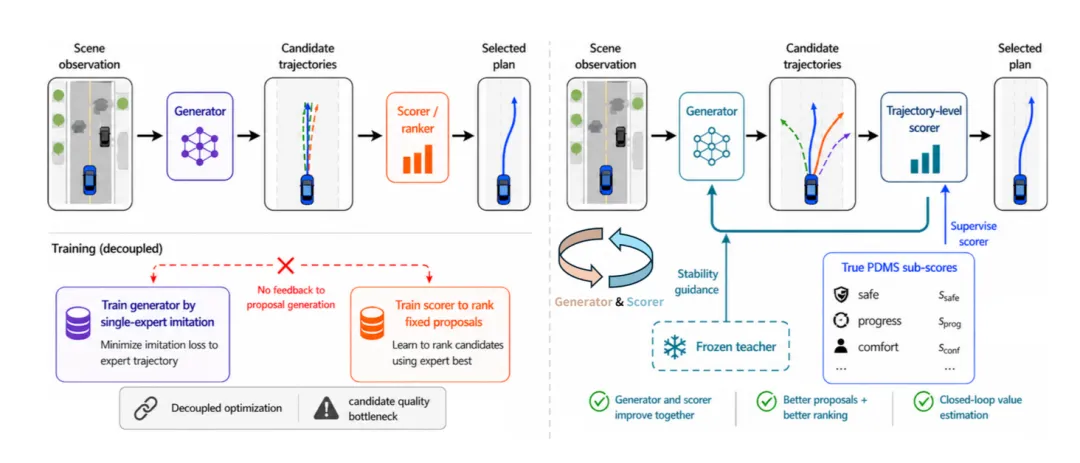
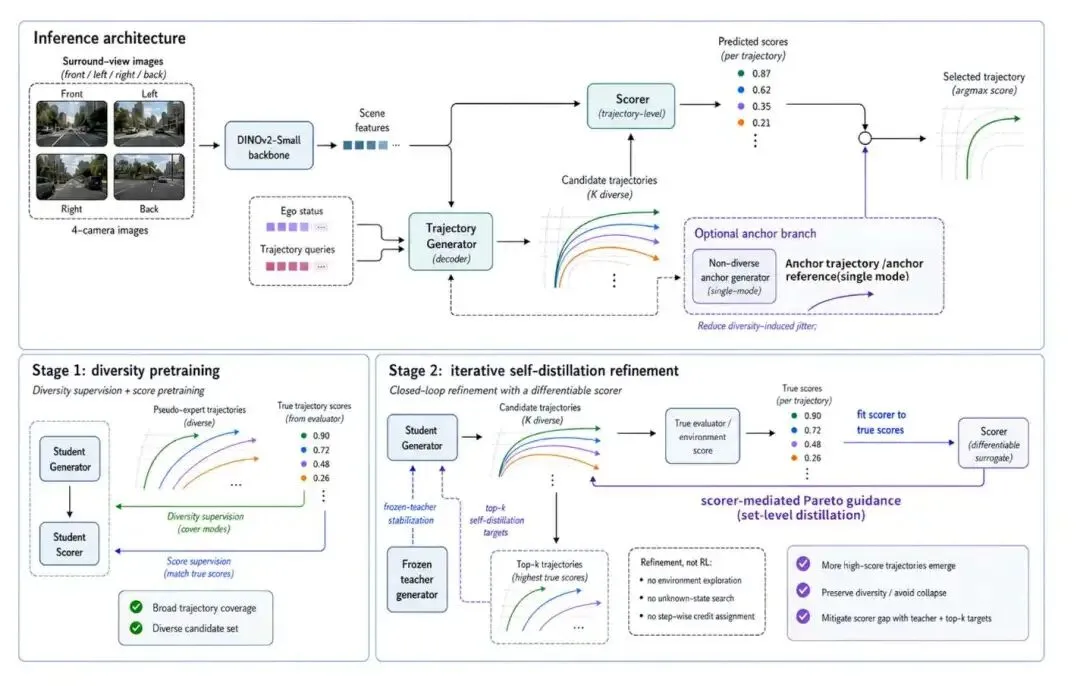
图1 | CLOVER (生成器-打分器) 闭环评估架构蓝图注:传统的规划器仅从开环数据中学习单一输出。而 CLOVER 将系统解耦为一个轻量级的轨迹生成器(Generator)和一个轨迹级打分器(Trajectory-level Scorer)。生成器负责撒网提供多样化的候选轨迹,打分器则预测各项规划指标的分数来进行严格的降维打分与排名。
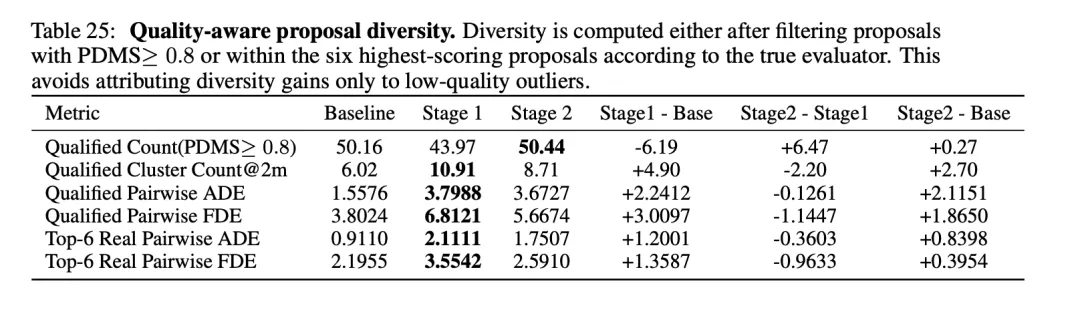
图2 | 高质量候选轨迹的多样性覆盖对比资料来源:论文 Table 25。在面对复杂路况时,基线模型(Baseline)的提议轨迹死死挤在一个极其“狭窄的模式(Narrow mode)”中;而搭载了 CLOVER 架构后,模型在 Qualified Pairwise ADE/FDE 等多样性指标上实现了成倍的暴涨,能够持续覆盖更广泛、可行且高分的候选轨迹空间。
📑 核心信息提炼
文献题目: CLOVER: Closed-Loop Value Estimation & Ranking for End-to-End Autonomous Driving Planning(《CLOVER:用于端到端自动驾驶规划的闭环价值评估与排名》)
作者团队: Sining Ang, Yuguang Yang, Canyu Chen, Yan Wang 等(中国科学技术大学自动化系,清华大学智能产业研究院 AIR,北京航空航天大学)
发表平台: arXiv(2026年5月15日)
核心数据/指标:
- 多样性断层领先:在质量感知的候选轨迹多样性测试中,CLOVER 的合格成对 ADE (Qualified Pairwise ADE) 从基线的 1.5576 飙升至 3.6727,提升了 2.1151。
- 高分聚类覆盖:合格聚类数量 (Qualified Cluster Count@2m) 从基线的 6.02 提升至 8.71,展现出极强的可行解搜索能力。
核心发现/战绩:
- 一针见血地指出了端到端规划器中存在的“训练-评测不匹配”问题,即接近人类日志的轨迹未必合法,合法的轨迹未必贴近日志。
- 证实了传统的候选提议(Proposals)往往高度集中在狭窄的众数附近,而 CLOVER 能够一致性地覆盖更广泛且高分的可行候选集。
核心创新点:
- 生成器-打分器架构:提出一种轻量级公式,生成多样化轨迹并通过预测规则子分数(Sub-scores)进行排名。
- 闭环价值评估:将原本只在评测阶段使用的安全、进度等规则奖励,前置到推理甚至训练循环中。
核心主题: 端到端自动驾驶 (End-to-End Autonomous Driving), 规划 (Planning), 闭环价值评估 (Closed-Loop Value Estimation), 生成器-打分器 (Generator-Scorer), 模仿学习悖论 (Imitation Learning Mismatch)
核心受众: 自动驾驶规控工程师、端到端大模型架构师、具身智能决策研究员
❓ 行业发展的 4 大“核心痛点”
- “训练与评测撕裂”的底层死锁: 模型在训练时用的是 L2 距离去拟合人类的一条历史轨迹,但最终上车测试时,却要用安全性、通行效率等复杂的规则逻辑来打分。目标函数的脱节导致模型根本不知道什么是“真正的好开”。
- 单模态模仿的“狭窄死胡同”: 基于纯模仿学习的模型极其缺乏想象力。在遇到需要绕行或紧急避让的边缘场景时,其生成的候选轨迹全部集中在一个极其狭窄的模式周围,缺乏探索其他更优解的能力。
- 开环提议(Proposal)覆盖率灾难: 现有的 Proposal-selection 规划器,其性能的上限完全被“候选集是否包含正确答案”所锁死。如果基础提议本身就缺乏多样性,后端的评测器再强也无济于事。
- 打分器(Scorer)缺乏真实物理映射: 许多系统的轨迹排序依赖隐式特征拼接,缺乏预测“规划指标子分数(planning-metric sub-scores)”的能力,导致排名缺乏物理与规则层面的可解释性。
🔧 核心真相:终极拆解“CLOVER 的四大架构逻辑”
1. 范式真相:用“生成与打分”解耦,终结纯粹的模仿学习
- CLOVER 彻底抛弃了让单一网络直接吐出最终轨迹的幻想,而是将其解耦为一个轻量级的轨迹生成器(Generator)和一个轨迹级打分器(Trajectory-level Scorer)。
- 这意味着模型可以先“大胆假设”(生成多样性轨迹),再“小心求证”(闭环规则打分),极大提升了规划的安全下限。
2. 生成真相:突破单一均值,海量多样性采样
- 针对基线模型候选轨迹死死抱团(狭窄模式)的缺陷,CLOVER 的生成器被专门优化以提供超越单一轨迹模仿(single-trajectory imitation)的支持广度。
- 它能够持续生成一系列不仅在空间上分散,且在物理动力学上切实可行的替代路径。
3. 评估真相:将下游“马后炮”规则,前置为闭环价值
- 自动驾驶不仅需要像人,更需要守规矩。CLOVER 的核心奥义是将安全性(Safety)、可行性(Feasibility)、进度(Progress)和舒适度(Comfort)这些原属于评测后端的标尺,直接融合进闭环的价值评估体系中。
4. 排名真相:用显式的子分数(Sub-scores)硬控轨迹优先级
- 打分器(Scorer)在推理时,并不是输出一个抽象的黑盒概率,而是精确预测各项规划指标的子分数(planning-metric sub-scores)。
- 这使得最终被挑选(Ranking)出的轨迹,不仅拥有最合理的几何外观,更在底层的交通规则和舒适度逻辑上做到了理论最优。
📊 关键内容与数据看板
表1:端到端自动驾驶规划范式演进对比
| | | | |
|---|
| 开环行为克隆 (Open-loop BC) | | | | |
| 启发式重采样打分 | | | | |
| [Ours] CLOVER 框架 | 本论文方案 | 多样化生成 + 闭环多维子分数预测 | 覆盖广泛且高分可行 | 极强(原生融合安全/舒适/进度等指标) |
表2:质量感知的候选轨迹多样性极限评测(Quality-aware Proposal Diversity)
| | | | |
|---|
| 合格成对 ADE (Qualified Pairwise ADE) | | | 3.6727 | + 2.1151 (实现翻倍级提升) |
| 合格成对 FDE (Qualified Pairwise FDE) | | | 5.6674 | + 1.8650 |
| 合格聚类数量 (Qualified Cluster Count@2m) | | | 8.71 | + 2.70 |
注:为了避免将低质量的离谱轨迹也算作多样性,评测是在过滤了 PDMS>0.8 的高质量提案后进行的。这证明 CLOVER 增加的多样性是“真正有用且合法”的高分轨迹。
💬 深度 Q&A
- Q1:既然模仿人类司机(Behavior Cloning)已经能让车开起来了,为什么还要大费周章去搞这套复杂的“生成-打分”闭环?A: 因为“会开”和“开得安全合法”是两码事。纯模仿学习存在严重的“训练-评测不匹配”。人类司机的轨迹只是无数种可行解中的一个,甚至有时候带点违规擦边。如果模型只死记硬背这条轨迹,一旦遇到微小的环境扰动,它不仅拿不出替代方案,还极容易发生碰撞。CLOVER 的闭环打分机制,就是要用冰冷的物理规则(安全、舒适)给模仿学习兜底。
- Q2:CLOVER 生成的轨迹“多样性”提升,会不会反而导致车子在路上“画龙”或犹豫不决?A: 恰恰相反。数据看板清晰表明,CLOVER 提升的是“质量感知的多样性(Quality-aware proposal diversity)”。这意味着它铺开的每一条备选路线,都是经过内部安全和可行性把关的“高分答案”。在突发拥堵或前车急刹时,这种宽广的备选池(wider set of feasible candidates)能让系统瞬间切入最优避让路线,而不是在唯一的狭窄模式里卡死。
- Q3:这种“生成+排名”的架构,在真实车端的实时性表现如何?A: CLOVER 采用的是一种“轻量级(lightweight)”的生成器-打分器公式。端到端的特征提取骨干网络是共享的,后端的轨迹生成头和打分多层感知机(MLP)开销极小。这种“快生慢选”的策略,在保证极高安全性上限的同时,完全能 hold 住真实车端的实时性要求。
🎯 深度点评
- 核心贡献: 清华 AIR 与中科大的这项研究,直击了阻碍端到端大模型真正上路的最核心命门——开环拟合与闭环物理规则的断裂。CLOVER 通过优雅的 Generator-Scorer 架构,成功将人类世界不可或缺的交通法则,重新内化进了深度学习的端到端黑盒中,为自动驾驶重构了规划评估的新基准。
- 亮点总结:① 清醒的解耦美学:彻底认清了单一轨迹模仿的局限,用轻量级的多发单收架构重塑了端到端规划。 ② 硬核的规则量化:逼迫打分器显式输出各项规则维度的子分数(Sub-scores),让每一次转向都有规可依。 ③ 数据工程的胜利:在高质量过滤的前提下实现了轨迹多样性的翻倍,大幅拓宽了自动驾驶的安全边界。
- 不足与局限:① 将多维规划指标(如安全与舒适之间)融合成统一的打分奖励,其权重调参在复杂城市博弈路段(如无保护左转)仍面临极高的工程平衡挑战。 ② 面对长时序(如预测未来 5 秒以上)的轨迹评估,打分器对未来动态障碍物意图的依赖度极高,若感知预测模块出现幻觉,闭环评估同样会失效。
🌟 总结金句
自动驾驶的终局绝不是去完美复刻人类司机的单一轨迹残影,而是在多维价值的闭环评估中,为每一次前行寻找物理与规则的全局最优解。
📌 互动引导
面对端到端自动驾驶(E2E AD)走向规模化量产的最后一公里,您更倾向于哪种技术演进路线?
✅ A. 坚决死磕纯模仿学习,只要喂入的数据集足够大,Scaling Law 就能解决一切 Edge Case!
✅ B. 类似 CLOVER 的闭环重排序架构,黑盒生成 + 白盒规则打分,用物理法则给 AI 兜底!
✅ C. 放弃黑盒,回归传统模块化规控(Planning & Control),大模型只做环境感知!
✅ D. 别卷端到端了,快给我推送最新的飞行汽车研究吧!
欢迎在评论区留下你的真知灼见! 👇
🧩 研究方向展望
针对冲刺 CVPR / ICCV / ICLR 等顶级会议的自动驾驶、具身决策与强化学习研究者,基于本论文提供以下延伸思路:
- 基于扩散流(Diffusion Models)的高保真多样性轨迹生成器: 将 CLOVER 框架中的传统生成器升级为基于条件流匹配(Conditional Flow Matching)或去噪扩散模型(DiT)的轨迹生成引擎。利用连续空间的扩散机制,在保证生成轨迹物理平滑性的同时,进一步压榨出符合多模态意图分布的极端边缘场景解,适合投递
CVPR 或 NeurIPS。 - 面向博弈场景的大语言模型(LLM)常识驱动打分器: 针对 CLOVER 打分器仍依赖硬编码规划指标的问题。探索将轻量级 VLM(视觉语言模型)作为辅助 Scorer,在面对中国式过马路或复杂环岛等极度需要“社会博弈常识”的场景时,引入文本思维链(CoT)子分数,实现“物理规则 + 社会常识”的双重闭环重排序,适合投递
ICLR。 - 基于自适应离线强化学习(Offline RL)的生成器闭环微调: 借鉴 RLHF 的思路,不仅让 Scorer 用于推理时的重排序,更将其作为奖励模型(Reward Model),对前端的轨迹生成器进行离线强化学习(如 DPO 算法)微调。通过闭环价值梯度的反向传播,从根本上纠正生成器在面对 OOD(分布外)场景时产生的违规轨迹分布,适合投递
ICML 或 CoRL。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
