自动驾驶遇上积水路面:FRED 数据集做了什么,为什么值得关注?
- 2026-06-06 12:51:57

点击下方卡片关注我们,点亮星标⭐,优质好文第一时间送达^_^
Click on the card below to follow US

>>>戳我一下,加入智驾机器人学习交流群✨
自动驾驶系统怕什么?
很多人会想到行人横穿、复杂路口、夜间驾驶、雨雪天气。但还有一种场景很容易被低估:路面积水,尤其是被洪水淹没的道路。
对人类司机来说,前方一片水面往往意味着“减速、绕行、判断深浅”。但对自动驾驶车辆而言,这并不是一个简单的视觉问题。水面会反光,会随光照、天空、树影、道路材质变化而呈现完全不同的外观;激光雷达打到水面时,也可能出现信号缺失、回波异常等情况。换句话说,摄像头不一定看得准,LiDAR 也不一定扫得清。
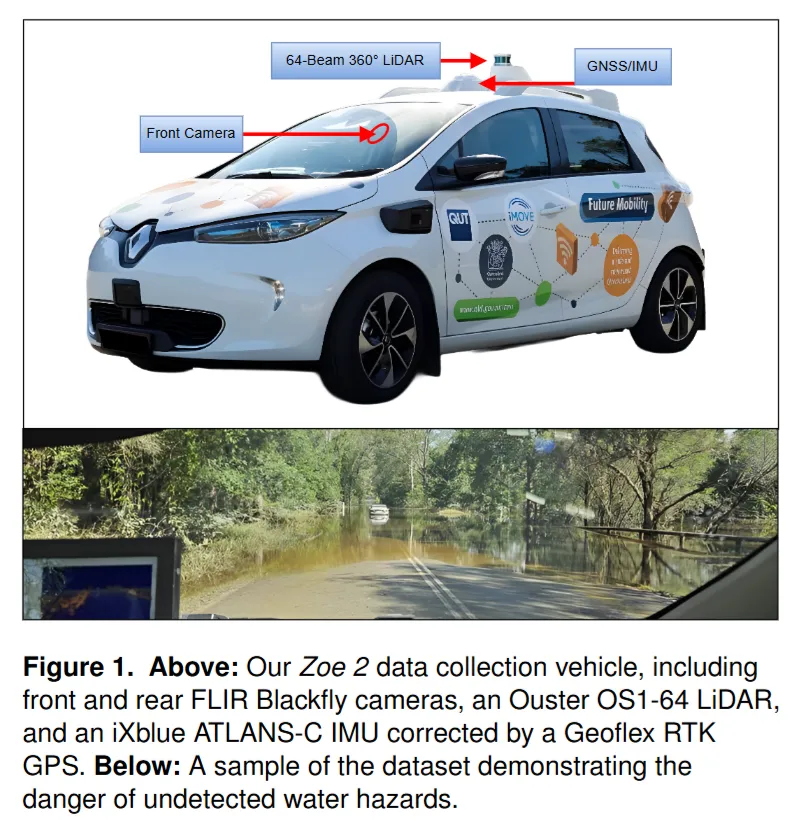
论文 《FRED: A Multi-Modal Autonomous Driving Dataset for Flooded Road Environments》 正是围绕这一问题展开。作者提出了一个面向积水道路场景的多模态自动驾驶数据集:FRED,即 Flooded Road Environments Dataset。
这篇文章的核心贡献并不是提出一个新的模型,而是补上了一个自动驾驶研究里长期缺失的基础设施:真实洪水/积水道路环境下,可用于感知、定位和传感器融合研究的数据集。

在自动驾驶感知任务中,车辆需要知道哪里可以走,哪里不能走。道路、车道线、车辆、行人、交通标志,这些对象已经有大量数据集和算法研究支撑。
但水面不太一样。
它既不是传统意义上的障碍物,也不是普通道路区域。浅水坑可能还能通过,深水区域则可能导致车辆熄火、失控,甚至危及乘客安全。更麻烦的是,水面在传感器中的表现非常不稳定。
从图像角度看,水面可能像镜子一样反射天空和树木,也可能因为浑浊、阴影、波纹而与普通路面混在一起。从 LiDAR 角度看,水面对激光束的反射并不稳定,常常会造成点云缺失。也就是说,一个积水区域在摄像头里“不像障碍物”,在 LiDAR 里又可能“没有足够点”。
这就使得水害检测成为自动驾驶感知中一个很棘手的长尾问题。
过去也有一些与水面检测相关的数据集,比如 Puddle-1000、Night-Puddle、Semantic Spray++ 等,但它们要么主要是图像数据,要么可访问性受限,要么并不专门覆盖真实洪水道路场景。FRED 的意义就在于,它把问题进一步推向了真实自动驾驶传感器栈:摄像头、LiDAR、GNSS/IMU、干湿两种状态、语义标注、定位评测,都放在同一个数据集中。

FRED 数据集来自澳大利亚布里斯班附近 2025 年一次主要洪水事件后的道路环境。作者使用一辆改装后的 Renault Zoe 自动驾驶测试车进行采集,车辆被称为 Zoe 2。
数据一共覆盖 5 个地点:
Mount Cotton Cambogan Holmview Pullenvale Dairy Creek
这些地点并不是简单重复的“有水路面”,而是尽量覆盖不同类型的水害环境。论文图 2 展示了几个典型例子:Mount Cotton 更接近水坑/积水路面,Cambogan、Dairy Creek、Holmview 包含更明显的洪水道路,Pullenvale 则是有流动水穿过道路的场景。
更重要的是,作者不仅采集了“有水”的场景,还在洪水消退、道路恢复后重新回到相同地点,采集了对应的“干燥道路”序列。这一点很关键,因为它让研究者不仅可以训练积水检测模型,还能研究同一地点在干湿状态变化下的定位、匹配和地图构建问题。
论文中提到,FRED 总共包含约 5340 个数据样本,每个样本都来自自动驾驶车辆上的多传感器系统。



FRED 的一个突出特点是“多模态”。它不是只给一批图片和标签,而是提供了更接近真实自动驾驶系统的数据组合。
论文表 2 给出了更具体的参数。相机分辨率为 1920×1200,约 2.3MP,帧率 30Hz;LiDAR 为 64 线 360°,约 10Hz,每秒约 65 万点;IMU 为 200Hz,并结合 RTK GNSS 提供厘米级定位能力。
这套配置的价值在于,它允许研究者同时做几类事情:
一是基于图像做水害语义分割;二是基于 LiDAR 分析水面对点云的影响;三是做相机与 LiDAR 的融合检测;四是利用 GNSS/IMU 做地图构建、轨迹对齐和定位评估。
很多水面检测数据集只能支持第一类任务,而 FRED 明显想把研究空间扩展到完整自动驾驶系统层面。

为了方便不同研究者使用,FRED 提供了两种数据格式。
第一种是 KITTI-style 格式。这类格式对自动驾驶研究者比较友好,因为 KITTI 数据集长期是自动驾驶感知和定位研究中的标准参考。FRED 在 KITTI-style 格式中,将不同传感器的数据放到不同文件夹下,比如:
front-imgs back-imgs front-labels back-labels imu ouster utm
图像以 PNG 形式保存,点云以 .bin 文件保存,IMU/GNSS 信息以文本形式保存。数据从原始记录中以约 10Hz 采样出来,并使用统一计算机时间戳进行对齐。
第二种是 native RTMaps 格式。RTMaps 是车辆采集时使用的软件环境,可以直接回放车辆传感器数据。但它需要许可,不一定适合所有研究者。因此,作者同时保留原始 RTMaps 格式和更通用的 KITTI-style 格式,兼顾可复现性和易用性。
论文图 3 展示了 FRED 的目录组织方式:先按道路状态分为 dry 和 flooded,再按格式、地点、采集时间组织序列。

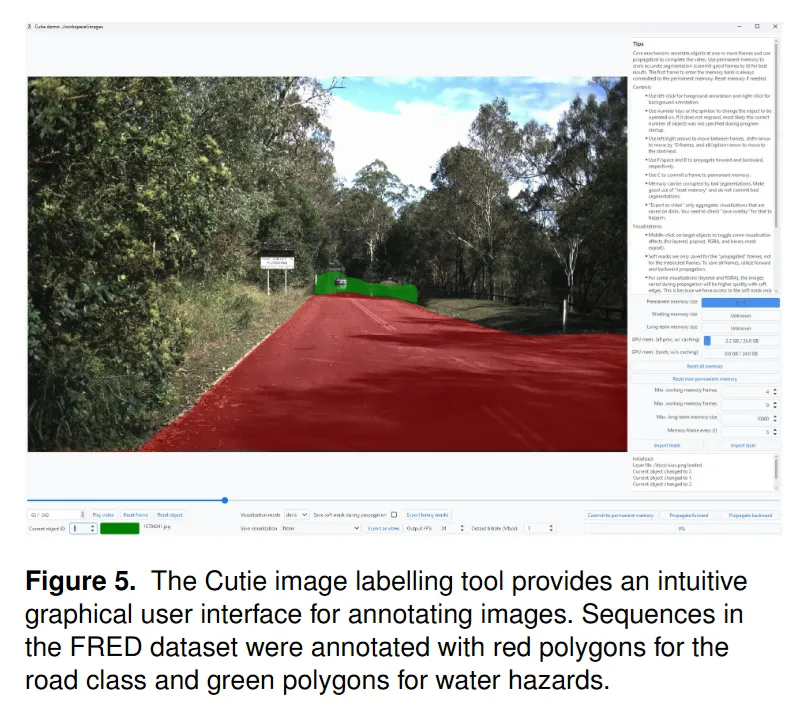
FRED 的语义标注主要面向前视相机图像,并集中在 flooded 序列中。
作者使用了 Cutie 视频目标分割工具进行辅助标注。具体做法是先利用视频分割模型在连续帧之间传播标签,再由人工检查和修正,保证标注质量。论文图 5 中可以看到标注界面,红色区域代表道路,绿色区域代表水害。
点云方面,FRED 没有直接提供完整的点云语义标签。原因也很现实:LiDAR 在水面上经常没有稳定回波,很多水面区域本身就缺点。强行给所有点云做标签并不可靠。
不过,作者在开发工具包中提供了点云投影到图像平面的功能。研究者可以将 LiDAR 点投影到相机图像上,再根据对应像素的语义标签给点云赋值。论文图 6 展示了这种基于图像标签迁移到点云的方式。

这是一种比较务实的处理:不假装点云标签完美存在,而是提供工具,让研究者根据任务需求自行生成可用标签。

FRED 还提供了一个 Python 开发工具包,用来加载、处理、可视化和评估数据。
工具包支持的功能包括:
将 LiDAR 点云投影到图像上 用距离、强度或语义标签给点云着色 可视化图像语义标注 查找干湿序列中相同位置的图像 绘制不同序列的 UTM 轨迹 尝试对水面造成的点云缺失区域做地面投影补全
论文图 7 到图 11 展示了这些工具的效果。比如图 7 展示了点云投影到图像后,可以按照距离、反射强度或语义类别进行着色;图 8 展示了如何在 flooded 和 dry 序列中寻找同一地点的图像;图 10 展示了不同序列的轨迹对齐情况;图 11 则展示了对水面缺失点云区域的实验性补全。

这些工具很重要。因为一个数据集如果只有原始文件,没有配套工具,实际使用门槛会很高。FRED 把传感器融合、标注可视化、定位评估等常用操作预先封装,能让研究者更快进入具体问题。

为了说明 FRED 的研究价值,作者首先评估了图像语义分割任务,重点看模型能否识别道路上的水害区域。
他们测试了几类方法:
评估指标是语义分割常用的 IoU / mIoU。简单说,IoU 衡量预测区域和真实标注区域重叠得有多好,越接近 1 越好。
从论文表 3 的结果看,现有方法在 FRED 上表现并不理想。不同地点之间差异明显,而且不少模型在某些场景几乎失效。

这里有两个值得注意的现象。
第一,模型对场景变化非常敏感。DeepLab V3 RAU 在 Mount Cotton 上表现很好,但在其他地点下降明显。V-Flood 在 Dairy Creek 上较好,但整体也不稳定。
第二,已有模型在真实道路积水场景中的泛化能力不足。这些方法在原始论文或原始应用场景中可能有不错表现,但到了 FRED 中,面对更复杂的道路、光照、阴影、水体形态,性能下降明显。
论文图 13 展示了几种模型的分割效果。作者认为 V-Flood 和 DeepLab V3 RAU 相对更有潜力,而 GA-Nav 和 YOLOv8 在这个任务上的泛化较差。
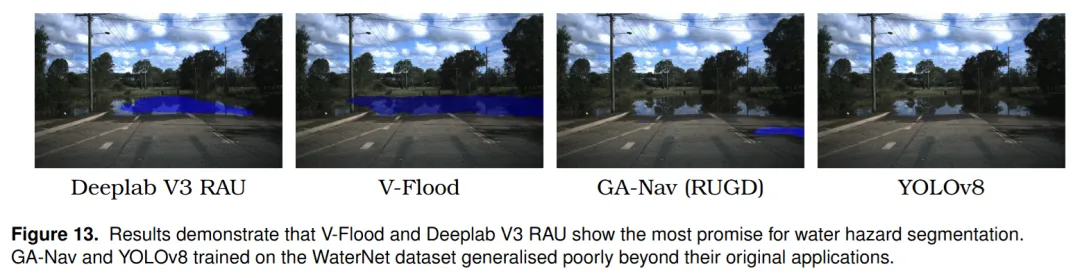

对自动驾驶来说,发现水害并不是“到跟前看清楚”就够了。
车辆需要提前发现前方危险,才能有足够距离减速、停车或绕行。因此,远距离水害检测非常关键。
论文图 14 展示了一个典型问题:DeepLab V3 RAU 在近距离时能较好分割水害区域,但在中等距离下,对前方积水的识别明显不足。

这说明水害检测不能只看平均指标,还要关注检测距离。一个模型如果只能在车辆快要进入积水时才识别出来,在真实自动驾驶系统中仍然不够安全。

另一个问题是误报。
如果模型把阴影、路面纹理、反光区域误认为积水,车辆可能会突然减速或制动。这类现象在自动驾驶里通常被称为 phantom braking,也就是“幽灵刹车”。

论文图 15 展示了两个误报案例。阴影和不均匀路面会让模型误判为水害区域。对于实际部署来说,这同样危险:漏检可能让车冲进积水,误检则可能造成不必要的急刹,影响后车和乘客安全。
所以,FRED 的价值不仅在于提供“有水”的样本,也在于提供复杂背景下的负样本和干湿对照,让研究者能够同时优化漏检和误检。

除了水害分割,论文还评估了 Visual Place Recognition,视觉地点识别,简称 VPR。
VPR 的任务是:给定一张当前图像,在已有地图或参考图像库中找到最相似的位置。它常用于视觉定位、回环检测和 SLAM。
作者测试了多种近年来常见的 VPR 描述子,包括:
BoQ Clique Mining CosPlace CricaVPR EigenPlaces MixVPR SALAD SuperVLAD
实验设计也很直接:用干燥道路序列建立参考库,再分别用 dry 和 flooded 序列作为查询,观察水害是否会影响地点识别。评价指标为 Recall@1,也就是最相似的第一张参考图是否就是正确地点。
结果很有意思。
在 dry 查询序列中,所有方法几乎都达到 100% Recall@1。这说明在同一天、短序列、相同地点条件下,现有 VPR 方法可以很好地完成匹配。
但换成 flooded 查询序列后,性能普遍下降。论文表 4 显示,多数描述子的平均下降幅度在 5% 到 8% 左右,而 CricaVPR 下降约 18%。
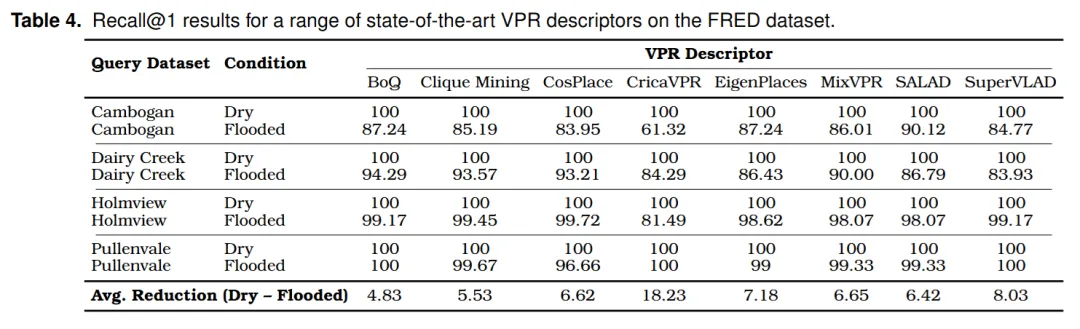
不同地点的影响也不一样。Pullenvale 的性能下降很小,因为水害对画面外观改变相对有限;Cambogan 的下降更明显,因为道路被洪水改变得更彻底。论文图 16 对比了这两个地点,也直观说明了水害对视觉外观的影响程度。

这说明积水道路不仅影响“哪里有水”的感知任务,也会影响“我在哪里”的定位任务。对于自动驾驶系统来说,这两个问题都很关键。

1. 第一个专门面向积水道路的多模态自动驾驶数据集
FRED 不是普通雨天数据,也不是单张水坑图片集合,而是围绕真实道路水害场景采集的完整自动驾驶数据集。它包含摄像头、LiDAR、GNSS/IMU,并覆盖多个地点和多种积水形态。
2. 同一地点提供 dry / flooded 对照
干湿两种状态的采集非常重要。它让研究者可以分析同一地点在洪水前后视觉外观、点云结构和定位结果的变化,也方便开展地图辅助检测和长期定位研究。
3. 提供水害语义标注与点云投影工具
FRED 提供前视图像语义标注,并允许通过投影方式把图像标签迁移到点云。这样既服务图像分割,也为相机-LiDAR 融合研究留下空间。
4. 证明现有方法仍有明显短板
通过语义分割和 VPR 两类实验,论文证明:现有模型在真实积水道路环境下并不稳健。远距离检测、误报控制、跨地点泛化、洪水条件下视觉定位,都是后续值得重点研究的问题。

FRED 这篇论文给人的最大感受是:自动驾驶的难题,很多时候并不是“又一个模型结构”能解决的,而是需要先把真实世界中那些少见、危险、复杂的场景系统性地记录下来。
积水道路就是这样的场景。
它不像行人、车辆、车道线那样在主流数据集中大量出现,却在极端天气和灾害环境中非常关键。对于自动驾驶、无人配送、矿区车辆、灾后救援机器人来说,识别道路积水并安全处理,都是不可回避的问题。
FRED 的出现,至少为这个方向提供了一个更完整的起点。它让研究者能够不再只依赖零散图片或难以访问的数据,而是在一个多传感器、带定位、带干湿对照、带标注和工具包的数据集上系统评估方法。
从论文实验结果看,当前方法离“可靠处理积水道路”还有距离。模型可能看不见远处的水,也可能把阴影当成水;视觉定位系统在洪水改变道路外观后,也会出现性能下降。
但这恰恰说明 FRED 的价值:它不是为了证明某个方法已经解决问题,而是把问题更清楚地暴露出来。

自动驾驶要走向真实世界,就必须面对真实世界的不完美。
晴天、白天、道路清晰的场景固然重要,但真正决定系统安全边界的,往往是雨后积水、道路被淹、阴影反光、传感器失效这些长尾情况。
FRED 数据集把“积水道路”从一个容易被忽略的边缘问题,推进成一个可以被系统研究、量化评估和持续改进的开放任务。
对于自动驾驶感知、传感器融合、视觉定位和机器人安全导航研究来说,这篇工作值得关注。
参考资料
论文标题: FRED: A Multi-Modal Autonomous Driving Dataset for Flooded Road Environments 中文译名: FRED:面向积水道路环境的多模态自动驾驶数据集 作者: Connor Malone、Sébastien Demmel、Sébastien Glaser


智驾 & 机器人学习交流圈

学
起
来



收藏

点赞

在看

收藏

点赞

在看
(1)自动驾驶可指导方向:CUDA编程,高性能计算HPC,CV/感知算法,端到端自动驾驶,决策规划,显著性分析,图像分割,LLM,自动驾驶,雷达感知,自动驾驶感知,毫米波雷达,深度学习,滤波算法,预期功能安全,自动驾驶基础共性技术研究,自动驾驶模拟仿真技术研究,自动驾驶安全性设计及验证,仿真与测试,场景生成,强化学习,预期功能安全,自动驾驶点云处理,行为识别,目标检测,视觉感知,BEV感知,边缘计算,数据处理,驾驶行为研究,点云,多模态,自动驾驶决策规划,英伟达平台模型部署优化,自动驾驶安全方向等。
(2)机器人可指导方向:机器人路径规划及算法,AI 集中在ROS机器人和CV NLP,计算机视觉,机器学习,机器人,三维视觉, 图像融合 ,图像理解 ,机器人算法,SLAM,点云处理,信号处理,具身智能,智能控制,机器人柔顺控制,分数阶控制,自适应反步,产业机器人,电力检测机器人,海洋机器人,进化计算,移动机器人定位导航,位姿估计,轮式机器人,仿生足式机器人,机器人感知,语义分割,深度学习,机器视觉,工业机器人,移动机器人,机器人模仿学习,控制算法设计,多模态智能等。
我们专注自动驾驶和机器人等前沿领域,提供选题创新性评估、实验设计、论文写作与顶级会议/期刊投稿指导。团队源自全球顶尖实验室及企业研究院,强化创新点与工程实现,不仅保证论文产出,更传授科研思维与方法,助你掌握独立发表高水平论文的能力。提供专利挖掘、技术交底书撰写、国内外专利申请(发明专利/实用新型)全流程服务。结合产业需求,强化权利要求的保护范围与商业价值,助力成果转化与竞争力提升。




