自动驾驶“跨化身”!Sensor2Sensor用4D高斯泼溅+扩散模型,把网络行车记录仪变成高精度LiDAR真数据
- 2026-06-06 23:18:10
开篇总结
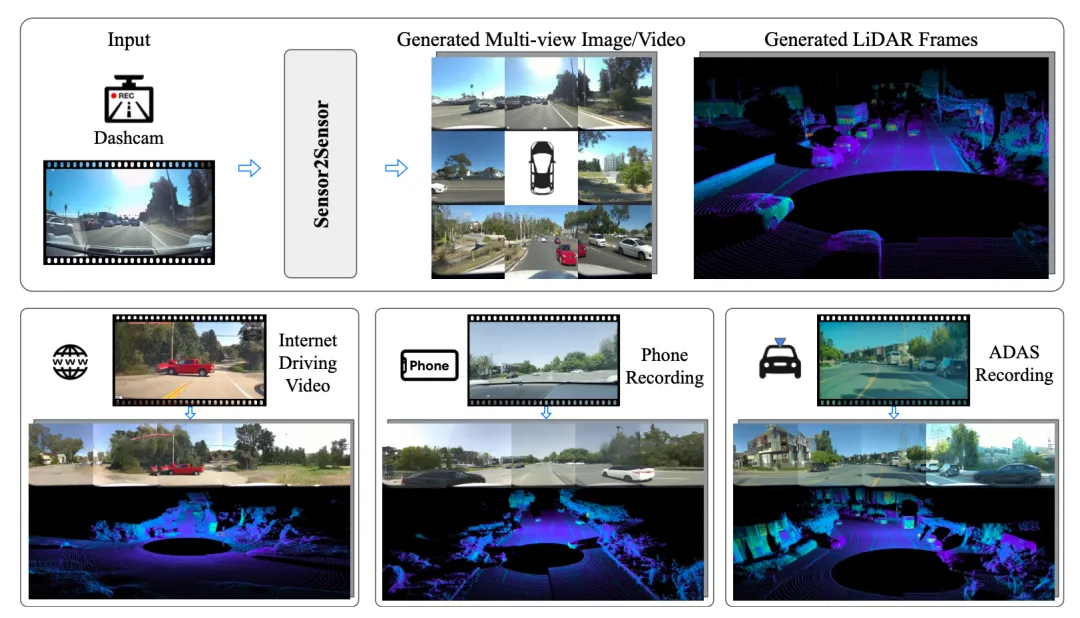
这篇由 Waymo、谷歌 DeepMind、约翰斯·霍普金斯大学以及华盛顿大学等顶尖团队联合发布的最新论文,提出了一个名为Sensor2Sensor (S2S)的创新生成式范式 。它首次实现了将网络上随处可见的单目行车记录仪视频或手机录像,跨化身(Cross-Embodiment)转换为目标无人车专属的 360° 多视角视频以及高精度 LiDAR(激光雷达)点云日志。
它的重要性在于,彻底打破了自动驾驶领域最头疼的“数据长尾效应”与“硬件不兼容”的双重桎梏,让海量的互联网公开驾驶视频直接变为高价值的无人车仿真与验证资产 。
值不值得读
推荐指数
⭐⭐⭐⭐⭐(5颗星,自动驾驶与生成式AI跨界必读)
适合
✓ 自动驾驶感知与仿真方向的研究者(研究生/博士生/企业研发人员)
✓ 世界模型(World Models)与跨模态生成(Diffusion/4DGS)的研究学者
✓ 关注具身智能(Embodiment)数据飞轮的数据运营与产品专家
预计阅读时间
原论文:约 2 ~ 3 小时(数学推导少,重点在系统架构设计与工程落地验证)
导读版:约 8 分钟
论文的价值
核心痛点:昂贵的“长尾路测”与无法复用的“野数据”
做自动驾驶的研究者都知道,想要让算法更安全,就必须用海量的“极端罕见场景(长尾场景)”去训练和验证它,比如夜间碰擦、突发车祸等 。
目前各大自动驾驶大厂(如 Waymo)主要靠自己的车队去路上“硬跑”来碰运气收集数据,不仅成本高昂,效率还极低 。相反,互联网上或者第三方卡车司机的行车记录仪(Dashcam)里其实充斥着这类惊险的长尾视频 。但尴尬的是,这些视频都是单目、二维、低清的,而你的无人车需要的是围绕车身 8 个摄像头的 360° 环视和 3D 激光雷达点云(LiDAR) 。这种硬件配置的巨大差异,在学术界被称为“化身差距”(Embodiment Gap)。
为什么作者要研究这个问题?
作者希望能打造一台“数据转换机” 。只要喂给它一段普通人手机拍的或记录仪录下的惊险车祸视频,它就能自动“脑补”出当时如果是一辆搭载了先进全套传感器的 Waymo 自人车开在现场,其各个角度的摄像头和车顶的激光雷达应该扫描到什么样的数据 。这样一来,全球数十亿小时的行车记录视频,瞬间都变成了无人车的免费“补品” 。
EasyReader AI论文导读示例
研究目的:
开发一种跨化身的传感器转换模型(Sensor2Sensor),将无结构、不连续的单目第三方视频,生成空间和时间一致的、特定于目标车辆硬件的多视角图像及 LiDAR 点云,以最大化复用现实世界的长尾数据 。
研究方法:
创新点:
概念创新:首次提出“跨化身传感器转换(Cross-Embodiment Sensor Conversion)”概念,区别于以往单纯的“世界大模型未来预测”,更强调格式转换与物理对齐 。
架构创新:巧妙地将第九个视角(即输入的第三方记录仪)作为已知、无噪声的条件输入(Conditional View),通过视点拼接引导其余八个视角的协同生成 。
实用性验证:生成的 LiDAR 数据能直接在未微调的现成点云检测和图像分割模型上跑出优异成绩,物理真实度极高 。
如果你只看10分钟
如果你时间紧迫,只想快速get这篇论文的精华,建议采取以下“特快路线”:
最值得看的章节:
第 3 章节(Method):尤其是Figure 3的系统架构图 。花 5 分钟理解作者是如何利用“第 9 视角掩码”做条件扩散,以及如何通过 VAE 把 3D 激光雷达点云压成二维“Spin Images(旋转图像)”来做扩散的 。这是整篇论文的工程精华。
第 4.5 章节(Generalization)与 Figure 8:直接看它处理“互联网野视频(如夜间真实车祸)”的效果 。这一节的定量人类评估和定性图能让你直观感受到这个大模型到底有多震撼 。
可以快速通过的部分:
第 2 章节(Related Works):除非你想扩充自己的文献库,否则可以全跳过 。
第 3.2.2 节关于 LiDAR 归一化的具体数学公式(如公式 1):只要知道它是用 L1 和 LPIPS 损失训练的即可,不必纠结细节 。
阅读顺序建议:
先看Figure 1理解输入输出 -> 读3.1 节明白成对数据是怎么用 4DGS 伪造出来的 -> 啃Figure 3 + 3.2.3 节看核心跨传感器融合 -> 最后直接翻到第 4.7 章节(Downstream Tasks)看看下游感知模型对生成数据的真实反馈 。
总结
这篇论文非常具有远见,它表明自动驾驶的数据竞争正在从“比谁的车队大、谁跑的里程多”,卷向“比谁能把全网已有的免费视频利用得更彻底” 。
谁应该继续阅读原论文:如果你正在做自动驾驶仿真、世界模型、扩散模型跨模态融合,或者正为训练数据不足而掉头发的同学,强烈建议去啃一遍原论文的 Method 和补充材料 。
谁只看导读即可:如果你是高层主管、产品运营,或者只是想追踪 AI 在工业界落地的最新技术趋势,那么看完本文及 EasyReader 的核心亮点拆解,就已经完全足够你在组会上跟团队高谈阔论了。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2026款极氪9X,豪华SUV买家看这3处
- 从"完全自动驾驶"到"辅助驾驶":花6万4买的功能,悄悄改了名
- WEY SUV伊朗自驾,3个场景看懂国产车出海
- 当AI学会操作电脑:我们离自动驾驶又近了几步?
- 比亚迪宋PRO 10万级家用SUV值在哪
- 95%的人都在被“自动驾驶”毁掉?
- 小米YU7 GT千匹SUV,性能溢价有看头
- 7.98万硬刚合资SUV,吉利ICON凭啥还香?
- 到店探车|豪华轿车新选36C,预售价18.99万元起,就能拿下的奔驰血统掀背车
- 678️需要检车的朋友,面包车,小轿车,大小货车,自卸车,后八轮,前四后八翻斗车,半挂车,下灰车等检车约起,保险续保,过户,
