AAAI 2025|自动驾驶轨迹预测别再“只会本地开”!浙大团队STraj让模型跨城市也能稳住
- 2026-06-09 11:41:23

⚠️ 自动驾驶的真实尴尬:模型在一个城市训练好,换个城市就掉性能
自动驾驶轨迹预测,听起来像是一个很明确的问题:
给定车辆、行人、骑行者过去几秒的运动轨迹,再结合地图和周围交通参与者信息,预测他们未来会怎么走。
但真正进入真实世界后,问题远没有这么简单。
因为不同城市的道路形态、车流密度、车道结构、交互模式差异非常大。一个在 Pittsburgh 训练好的轨迹预测模型,到了 Miami 可能就不适应了。不是模型突然不会预测,而是它学到的交通分布和新城市的交通分布不一样。
这就是论文里强调的核心问题:
Cross-Geography Gap,跨地理域差异。
自动驾驶不是只在一个城市跑 demo。真正落地时,模型必须面对不同城市、不同道路结构、不同交通参与者密度。可现实是,很多轨迹预测模型在源城市表现不错,一旦迁移到目标城市,性能会明显下降。
AAAI 2025 论文 STraj: Self-training for Bridging the Cross-Geography Gap in Trajectory Prediction 正是为了解决这个问题。
一句话概括:
STraj 想让轨迹预测模型不再“只会本地开”,而是能跨城市泛化。
🧠 本文核心思想:目标城市没有标签?那就用自训练生成“伪轨迹”来学
跨城市轨迹预测最大的难点是:
目标城市通常没有标注好的未来轨迹。
如果每到一个新城市都重新采集、清洗、标注大规模轨迹数据,成本会非常高。自动驾驶公司不可能每扩展一个城市就从零标注一次完整数据。
所以这篇文章走的是 Unsupervised Domain Adaptation,无监督域适应 路线。
也就是说:
源城市有标注数据。 目标城市没有标注数据。 模型要利用源城市标签和目标城市无标签数据,提升在目标城市上的轨迹预测能力。
STraj 的核心方法是自训练。
简单说,就是让模型先对目标城市样本生成伪标签,也就是 pseudo trajectories,然后用这些伪轨迹反过来监督模型继续训练。
但轨迹预测的伪标签不是普通分类标签。
分类任务里,伪标签可能只是一个类别,比如“车”或者“人”。 轨迹预测里,伪标签是一整条未来时间序列坐标。
这就更难。
因为伪轨迹可能方向对了但长度不对,也可能终点接近但中间过程完全不合理。如果直接拿低质量伪轨迹训练,模型会被带偏。
所以 STraj 的关键不是简单“生成伪标签”,而是:
生成更可靠的伪轨迹,更新更稳定的伪轨迹,再用伪轨迹去约束表示学习。
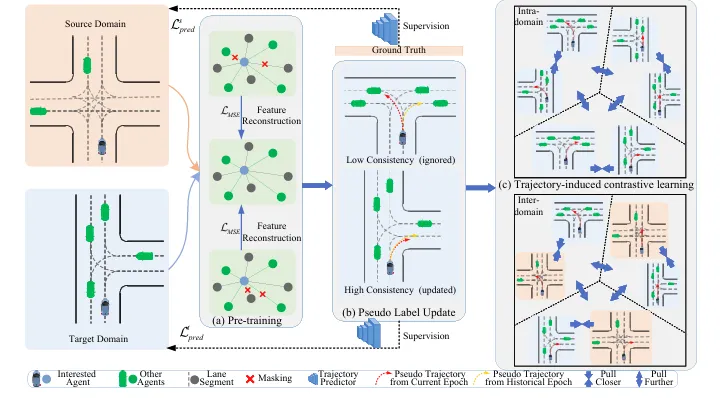
🔧 STraj三步走:生成、更新、利用伪轨迹
STraj 的整体框架可以概括为三步:
Pseudo label generation → Pseudo label update → Pseudo label utilization
也就是:
先生成伪标签, 再稳定更新伪标签, 最后充分利用伪标签。
这三步分别对应跨地理轨迹预测中的三个痛点。
1. 互补式 Agent-Map 增强:先让模型见过更多“城市变化”
第一步是伪轨迹生成。
如果源城市数据本身太单一,模型生成的初始伪标签质量就会很差。
比如 Pittsburgh 和 Miami 的 agent 数量分布、lane segment 数量分布明显不同。一个模型如果只在某种城市结构下训练,到了另一个城市就容易不适应。
所以 STraj 在预训练阶段提出了 complementary agent and map augmentations。
它不是简单随机遮挡,而是从两个视角做互补增强:
一方面对周围交通参与者 agent 进行增强; 另一方面对地图 lane segment 进行增强。
更关键的是,它不是粗暴随机 mask,而是根据距离设计弱增强和强增强。近处 agent 和 lane 通常对目标车未来轨迹更重要,远处信息相对次要。STraj 利用这种空间关系做 weighted random masking,让模型在训练时见到更多变化场景,同时避免把关键信息一次性遮掉太多。
这一步的作用可以理解为:
先训练一个更抗城市差异的轨迹预测器,让它生成的初始伪轨迹别太离谱。
2. 伪轨迹更新:不是所有伪标签都能信,只信“前后一致”的轨迹
第二步是伪标签更新。
这是 STraj 里非常重要的设计。
轨迹预测的伪标签会随着训练 epoch 不断变化。一个目标车辆在第 3 个 epoch 预测出的未来轨迹,可能和第 10 个 epoch 预测出的未来轨迹不完全一样。
如果模型每一轮都盲目相信当前伪标签,训练会很不稳定。
STraj 的思路是:
看当前伪轨迹和历史伪轨迹是否一致。
如果一条伪轨迹在不同训练阶段都比较一致,说明模型对这个样本的判断比较稳定,可以拿来监督训练。
如果当前伪轨迹和历史伪轨迹差异很大,那就说明它不可靠,应该暂时忽略。
论文中用整条未来时间序列轨迹的 cosine similarity 来衡量一致性,而不是只看终点。这一点很关键。
因为轨迹不是一个点,而是一段运动过程。
只看终点可能会误判。两条轨迹终点接近,但中间路径可能完全不同;而自动驾驶真正关心的是整个运动过程是否合理。
所以 STraj 选择高一致性、高置信度的伪轨迹作为更新结果,并用一致性程度给目标域预测损失加权。
可以理解为:
越稳定的伪轨迹,监督权重越高;越不稳定的伪轨迹,暂时别信。
这比直接使用全部伪标签要稳得多。
3. 轨迹诱导对比学习:让“走法相似”的车靠近,“走法不同”的车分开
第三步是伪轨迹利用。
STraj 不只是用伪轨迹做监督,还进一步提出了 trajectory-induced contrastive learning,轨迹诱导对比学习。
为什么需要这一步?
因为跨城市场景中,agent 表示会受到周围车辆数量、车道结构、地图复杂度的影响。不同城市的交通分布不同,模型学到的 agent representation 也会产生偏差。
但轨迹预测真正应该关注的是:
未来运动意图相似的 agent,表示应该更接近;未来运动意图不同的 agent,表示应该更分离。
比如同样是车辆:
直行、左转、右转的未来轨迹显然不同。 即使它们都属于 vehicle 类别,也不应该被简单拉到一起。
所以 STraj 用生成的伪轨迹来判断正负样本。
未来轨迹相似的 agent 被视作正样本,表示拉近; 未来轨迹差异明显的 agent 被视作负样本,表示推远。
而且它同时做 intra-domain 和 inter-domain contrastive learning,也就是既在同一城市内部做对比,也在不同城市之间做对比。
这一步的核心价值是:
让模型不再只按城市分布学表示,而是按真实运动模式学表示。
📊 实验结果:跨城市迁移,STraj稳稳超过多个基线
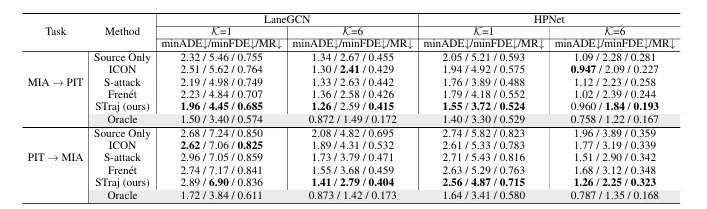
论文在 Argoverse 1 数据集上做实验,重点评估 Miami 和 Pittsburgh 之间的跨地理迁移。
任务包括:
Miami → Pittsburgh Pittsburgh → Miami
评估指标是轨迹预测常用的 minADE、minFDE 和 MR。
结果很明显:STraj 在大多数跨地理任务中超过 Source Only、ICON、S-attack 和 Frenét 等方法。
以 MIA → PIT、LaneGCN、K=1 为例,Source Only 的 minADE/minFDE/MR 是:
2.32 / 5.46 / 0.755
STraj 提升到:
1.96 / 4.45 / 0.685
这意味着 STraj 在跨城市场景下显著降低了平均轨迹误差、终点误差和 miss rate。
更重要的是,STraj 不是只绑定一个模型。论文同时在 LaneGCN 和 HPNet 上验证,说明它具有一定 plug-and-play 能力。
这点很重要。
因为自动驾驶轨迹预测模型更新很快。如果一个方法只能适配单一 backbone,实用性会受限。而 STraj 的定位是一个自训练 pipeline,可以接到已有轨迹预测器上,并且推理阶段不增加额外计算负担。
🎯 这篇文章真正的价值:自动驾驶预测不能只在“本地数据”上刷分
过去很多轨迹预测论文关注的是模型结构本身:
更强的 GNN。 更复杂的 Transformer。 更细的地图编码。 更好的多模态轨迹生成。
这些当然重要。
但 STraj 抓住的是另一个更现实的问题:
模型能不能跨城市泛化?
一个自动驾驶预测模型,如果只在训练城市好用,换一个城市就掉性能,那它离真实部署还有距离。
因为真实世界不是单一数据集。 不同城市有不同车流、路口、车道结构、交通习惯和道路拓扑。
所以 STraj 的意义在于,它把轨迹预测问题从“单域精度提升”,推进到了“跨地理泛化能力提升”。
这比单纯在一个 benchmark 上刷更低误差更接近真实落地需求。
🚀 科研启示:轨迹预测下一步要卷“跨域能力”
STraj 给自动驾驶轨迹预测带来几个很清晰的启示。
第一,未来轨迹预测不能只报告单城市、单数据集上的结果。跨城市、跨区域、跨交通分布的泛化能力会越来越重要。
第二,伪标签方法不能照搬图像任务。轨迹预测的伪标签是一整段时间序列,必须考虑轨迹一致性、方向、运动过程,而不是只看一个类别或终点。
第三,轨迹表示学习应该围绕运动模式,而不只是类别或场景。直行、左转、右转这些未来意图,比“都是车”这种类别标签更关键。
第四,真正实用的跨域方法,最好不要增加推理负担。STraj 的一个优势是作为 plug-and-play module,在推理阶段不引入额外计算复杂度,这对自动驾驶车端部署很重要。
📌 一句话总结
这篇 AAAI 2025 论文的核心意义可以概括为:
它让自动驾驶轨迹预测从“单城市表现好”,走向“跨城市也能泛化”。
传统轨迹预测模型的问题是:
在一个城市训练得很好,换一个地理场景就容易掉性能。
STraj 的解法是:
用互补式 agent-map 增强生成更可靠伪轨迹,用一致性策略更新伪轨迹,再用轨迹诱导对比学习缓解跨城市表示偏差。
它不是简单换一个更大的预测模型,而是提出了一套跨地理自训练框架。
未来自动驾驶真正需要的,不只是更强的预测器。
而是:
换一个城市,也能预测得稳。
#AAAI2025 #自动驾驶 #轨迹预测 #STraj #无监督域适应 #SelfTraining #TrajectoryPrediction #AutonomousDriving #浙江大学 #跨城市泛化 #科研干货
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 全新奔驰纯电GLC SUV ,静候懂生活的你
- 13-16万德系SUV怎么选?探歌、途岳、柯珞克,三台车一次说清楚
- 华为乾崑全栈赋能,奕境X9旗舰大六座SUV首发,奶爸视角实测体验
- 大众电动SUV,买前先看3个电池权限
- 这台国产智能SUV,越开越喜欢
- 买SUV我推荐这6款,都是国货之光代表,质量品控丝毫不输合资车
- 比亚迪大型SUV即将上市!预售25万可选纯电/插混,综合续航1430Km
- 全球前五、中国第一!压轴登场的王炸SUV
- 12万级家用SUV卷成这样?老刘聊透零跑C10:很容易上头,但真掏钱一定要冷静
- 奥迪这款中大型SUV售价亲民,可选大七座布局,搭载3.0T轻混+四驱
