2025年底,久未露面的苏箐现身地平线技术生态大会。刚从工程模式切换过来的苏博士不吝对特斯拉的赞美之情,表示特斯拉率先垂范的端到端是近几年来自动驾驶领域唯一的「真范式革命」,并断言未来三年很难再现范式新突破。
今年3月,晚点Auto团队拿这个话题问文远知行CEO韩旭,韩旭给出的回答很干脆:“我不觉得现在一段式端到端+世界模型就是终局,技术具有强大的不可预测性。”两位大佬打起了擂台,但在作为端水大师的我看来,他们的观点或许并不矛盾:三年时间,端到端范式足以推动行业走到L4初期阶段,三年后,L4向L5的终极跨越或许需要新的范式出现。
既然如此,那么问题来了,如果只有端到端才算范式革命,何以在车企的发布会和访谈里,端到端的热度被VLA、世界模型、基础模型这些新词抢了风头?这些新的技术名词到底意味着什么?在统一的端到端范式下,竞争的真正战场又在哪里呢?
抑郁症被特斯拉治愈了一大半的苏博士说得对,从规则驱动的分模块到数据驱动的端到端,是自动驾驶领域近年来唯一的一次范式革命。之后的一切(VLM、VLA、世界模型、基础模型)都是在同一范式下,由每一步的工程缺陷驱动的能力增强。
犹记得2025年,行业曾经有过一场轰轰烈烈的技术路线之争。小鹏和理想选择了VLA路线,强调语言理解让系统能推理,华为和蔚来选择了(车端)世界模型路线,强调空间预测让系统更安全。两边的支持者各执一词,吵得锣鼓喧天,但从范式的角度审视,这四个头部玩家的模型架构底子都是端到端+Transformer,差异只是能力侧重不同:VLA重在语言智能,世界模型重在空间智能。可以认为,这不是范式差异,而是同一范式下的能力侧重差异。
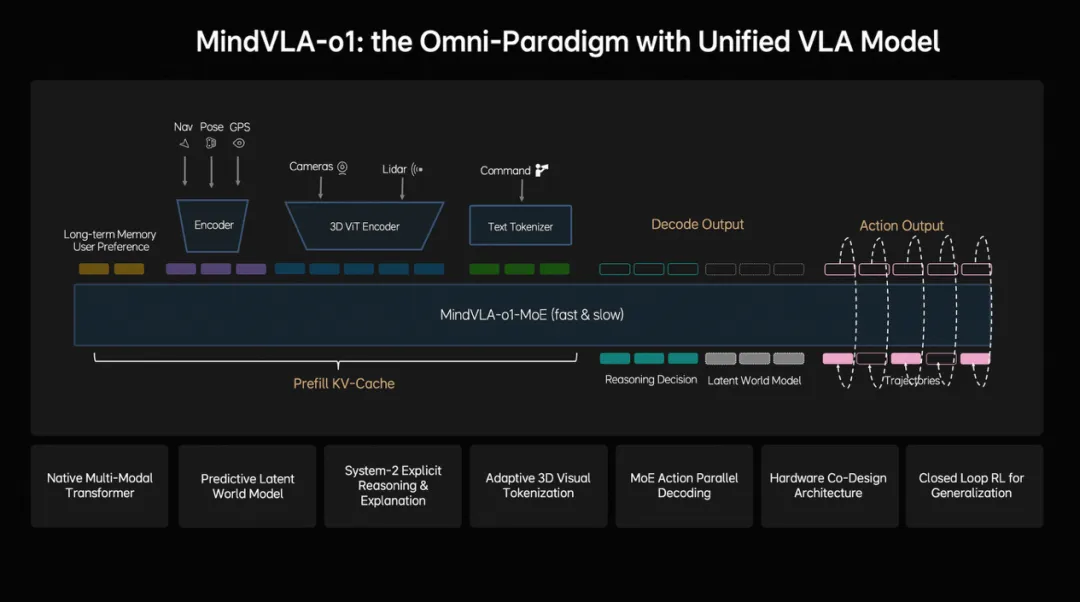
争论的消解来得也很快。25年11月,小鹏推出二代VLA,表示“也是世界模型”,2026年3月,理想汽车发布Mind VLA-o1基座模型,内置预测式隐世界模型。从此,VLA和世界模型不是非此即彼的选择题,而是同一个基础模型里的两种能力。瞧,这架白吵了!
图片来源:理想汽车
VLA和世界模型之争已经消解,但这场争论背后有一个更大的问题:从端到端到VLA再到世界模型再到基础模型,这条线到底是怎么走过来的?其实,自动驾驶算法的演进,是一条由工程缺陷驱动的连续进化路线。虽然每一步都没有跳出端到端的范式框架,但都解决了上一步的实际问题。
这条线始于2023-2024年的端到端范式革命,由特斯拉FSD V12打样,本土车企全面跟进。架构从模块化规则切换到统一神经网络,这是真正的范式跃迁。紧接着,因为纯视觉端到端缺乏推理能力,行业在2024年引入了VLM,带来了语言智能和系统2慢思考。但VLM只能提供建议,不直接参与动作,于是2025年,VLA登场,语言模态开始直接参与动作输出。不过,VLA缺乏对未来物理世界状态的预测能力,于是,华为、蔚来们集中展示世界模型,加入了空间智能。
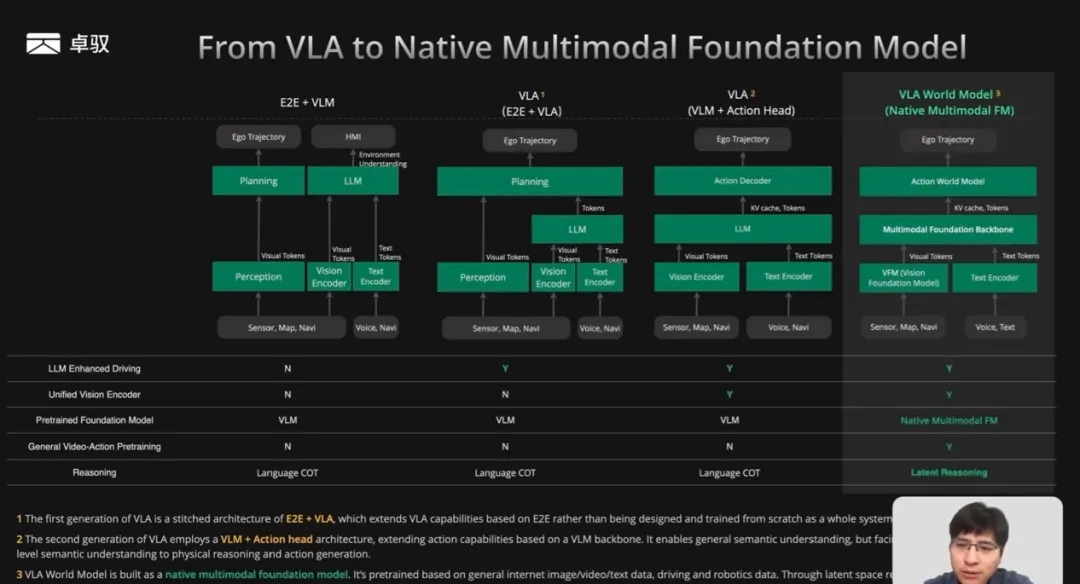
时间来到2026年,旨在将分散的能力统一到一个通用底座的基础模型又成了新的工程焦点。可能有的小伙伴还没大听说过基础模型的概念,您可以从基础模型=VLA+世界模型这个公式上自行品味一番。
图片来源:卓驭科技
这告诉我们几个关键的事实。传统端到端->VLM->VLA/世界模型->基础模型的一路跃迁,每一步都是由上一步的真实工程缺陷驱动的。每一步虽然都是“在端到端范式内的能力扩展”,但其工程增量都是真实的、有价值的。
所以,这不是跳跃式的范式切换,而是由工程缺陷驱动的连续能力增强。就像智能手机从单摄到多摄一样,虽然体验在变,但其核心的“以计算弥补物理限制,以算法定义成像上限”的核心范式没变。自动驾驶从传统端到端方案一路演进到基础模型的逻辑与此异曲同工,都是在既有的框架下,通过引入更强大的“大脑”去解决原有工程方案无法处理的长尾问题,从而实现能力的连续增强。
范式革命只有一次,能力增强永无止境。但不管能力组件怎么叠加,端到端的核心承诺始终是数据驱动模型迭代。这个承诺兑现的前提,是背后有一套高效的数据闭环体系。范式趋同之后,竞争的决胜点就在这里。
当端到端成为行业共识、VLA和世界模型在基础模型中合流之后,真正的差异化竞争不在算法路线选择,而在数据闭环体系,训练、测试、评估三个环节的效率,这三者的结合,构成了真正的工程壁垒。
文远知行CEO韩旭在采访中曾表达过一个类似的观点:别管是端到端还是VLA,关键是看你能把它发挥到什么程度。就像武林高手过招,招式本身固然重要,但内功深浅才是决定胜负的关键。而数据闭环,就是自动驾驶公司的“内功”。
先说训练。端到端范式的核心是数据驱动,模型能力上限取决于训练数据的质量和覆盖度。关于数据从何而来,行业正在形成两条互补的管道。
第一条管道来自真实路采,核心优势在于其具有不可替代的真实性壁垒,不存在sim2real鸿沟,模型学到的东西和现实世界之间没有认知偏差。而且,真实的世界永远比想象更加魔幻,有些极端罕见的场景在合成数据中很难完美模拟,但在真实路采中可能偶然被捕捉到。这条线上的标杆是显眼包特斯拉,它依托近千万辆在全球道路上行驶的量产车,通过规模和时间构成了最庞大的驾驶数据资产,构建了行业最高的真实路采壁垒,以至于华为都点赞遥遥领先。
第二条管道来自合成数据,用于高效地补齐长尾场景。真实路采数据确实够真实,但其问题很明显,捕捉长尾场景数据的效率太低。长尾场景在自然驾驶中出现的概率极低,“等路上出事”的被动采集远远不够。文远知行、小鹏、理想等各路玩家给出的解法是,以云端世界模型针对性地生成与模型当前能力缺陷相对应的高价值数据。这不是随机生成海量场景,而是“模型哪里弱就生成哪里”的定向数据增强。
图片来源:文远知行
合成数据的优势是效率高、可控性强,但局限是存在sim2real鸿沟。所以,两条管道的关系是互补,真实路采提供“想不到的场景”,合成数据提供“想得到但遇不到的场景”,两者相辅相成,缺一不可。
两条数据管道解决了“拿什么练”的问题。练完之后,怎么验证模型能力?当然是靠测试。训练完的模型必须经过大规模验证才能部署,但是,传统实车测试效率极低,成本极高,覆盖度受限,云端仿真正在解决这三个痛点。
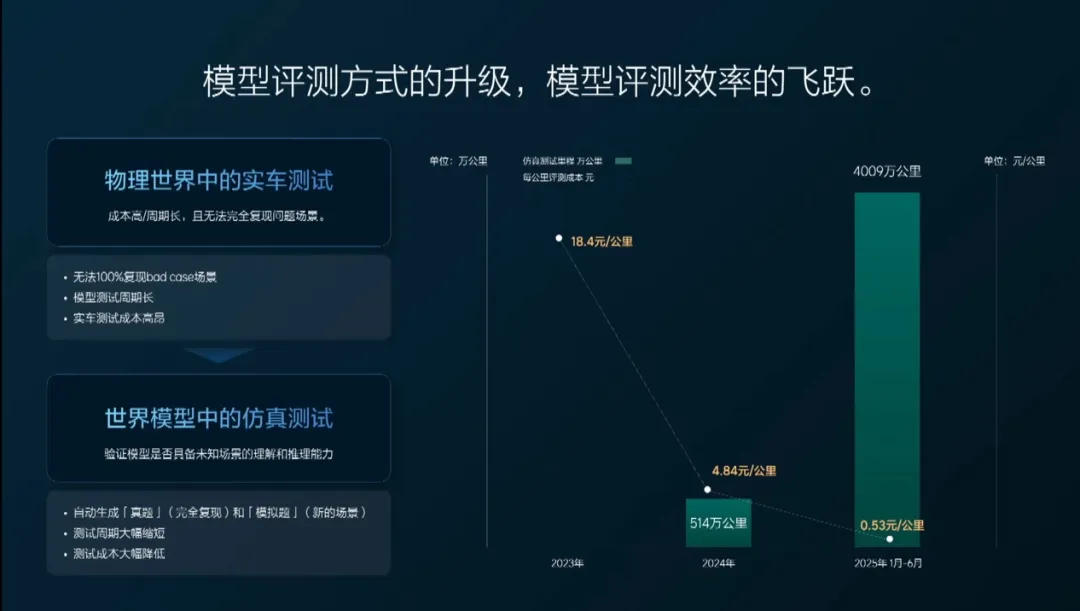
首先是效率优势,基于云端世界模型,可以大规模并行运行地跑成千上万个测试场景,节省了大量的时间;其次是成本优势,在虚拟环境中可以大规模验证高难度场景,大幅度降低了测试的成本和危险性。最后,基于世界模型构建虚拟场景,可以无限生成场景变体,这就极大地提高了测试场景的覆盖度。
理想汽车基于世界模型打造了云端仿真测试体系后表示,在升级模型的评测方式后,25年上半年仿真测试里程大幅提升到4009万公里,每公里的评测成本从23年的18.4元每公里锐减到了0.53元每公里。
图片来源:理想汽车
数据采集和生成解决“练什么”,实车和云端测试解决“练得对不对”。还有一个环节就是,怎么精确地知道“比上一版好了多少、好在哪里、差在哪里”?这就是评估。特斯拉表示,这是数据闭环中最难的环节。
图片来源:特斯拉
特斯拉自动驾驶负责人在25年的ICCV会议上明确表示,在训练、测试、评估三个环节中,评估是最难的。评估为什么难?原因主要在于驾驶场景没有标准答案。同一个路口,老司机可能选择稳健跟车,年轻司机可能选择果断变道,两种决策都可能合理。“轨迹偏差”指标无法捕捉决策质量的差异,“接管率”指标又受用户行为影响不够客观。
模型越来越大、场景越来越复杂,传统评估方法已经跟不上模型能力的增长速度了。谁能建立更精确、更自动化的评估体系,谁就能更快地判断模型迭代的方向对不对。在这次的GTC大会上,元戎启行发布了一个(非主流定义的)基座模型,专门设计了独立的评估模块,就是希望通过大模型的能力提高评估的准确度和速度。
训练解决“拿什么练”,测试解决“练得对不对”,评估解决“好多少”,三个环节构成的数据闭环速度,才是范式趋同之后真正的工程壁垒。
再回到开篇苏箐和韩旭的两个判断。苏博士划定了当下:端到端是范式,未来三年行业都会在这个范式内深耕。韩旭指向了未来:技术有不可预测性,L4之后可能有新范式。两个判断都对,只是时间尺度不同而已。
当下能确定的,是范式已经确立,算法路线之争正在消解。真正的竞争,已经转移到数据闭环的效率比拼上。当所有人的算法架构都基于Transformer,都用端到端,都往基础模型走时,谁能更快地发现问题、生成数据、测试验证、评估迭代,谁就能在智能驾驶的马拉松中跑得更远。
这一次,不再有“谁对谁错”的争论,而是一场关于“谁快谁慢”的竞赛。而竞赛的裁判,不是技术路线,是数据闭环的效率本身。范式变革只有一次,但数据闭环的建设没有终点,接着卷吧!